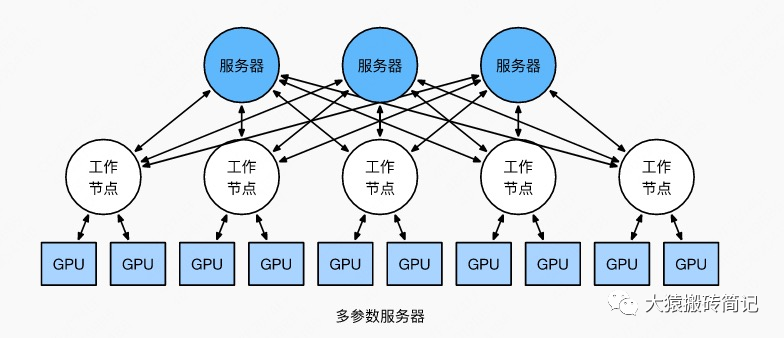
电子发烧友网报道(文/李弯弯)在深度学习中,经常听到一个词“模型训练”,但是模型是什么?又是怎么训练的?在人工智能中,面对大量的数据,要在杂乱无章的内容中,准确、容易地识别,输出需要的图像/语音
2022-10-23 00:19:00 24277
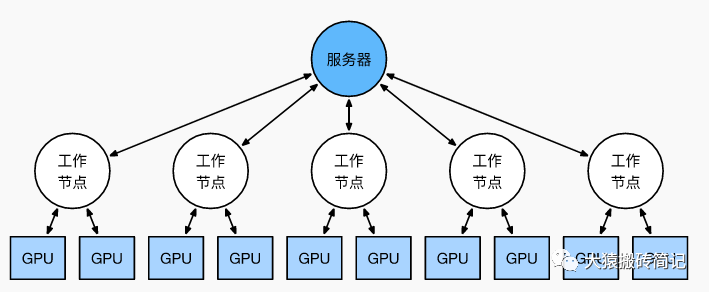
24277 分布式深度学习框架中,包括数据/模型切分、本地单机优化算法训练、通信机制、和数据/模型聚合等模块。现有的算法一般采用随机置乱切分的数据分配方式,随机优化算法(例如随机梯度法)的本地训练算法,同步或者异步通信机制,以及参数平均的模型聚合方式。
2018-07-09 08:48:2213609 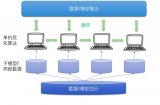
随着预训练语言模型(PLMs)的不断发展,各种NLP任务设置上都取得了不俗的性能。尽管PLMs可以从大量语料库中学习一定的知识,但仍旧存在很多问题,如知识量有限、受训练数据长尾分布影响鲁棒性不好
2022-04-02 17:21:438765 NLP领域的研究目前由像RoBERTa等经过数十亿个字符的语料经过预训练的模型汇主导。那么对于一个预训练模型,对于不同量级下的预训练数据能够提取到的知识和能力有何不同?
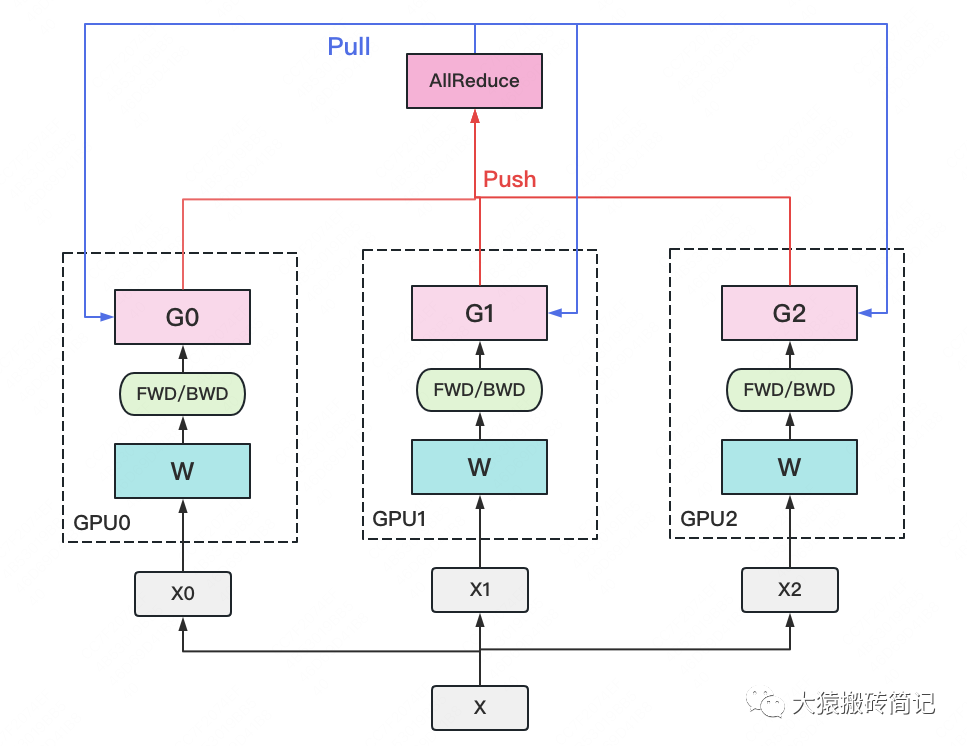
2023-03-03 11:21:511339 在之前的内容中,我们已经介绍过流水线并行、数据并行(DP,DDP和ZeRO)。 今天我们将要介绍最重要,也是目前基于Transformer做大模型预训练最基本的并行范式:来自NVIDIA的张量模型
2023-05-31 14:38:231605 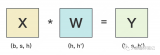
为什么?一般有 tensor parallelism、pipeline parallelism、data parallelism 几种并行方式,分别在模型的层内、模型的层间、训练数据三个维度上对 GPU 进行划分。三个并行度乘起来,就是这个训练任务总的 GPU 数量。
2023-09-15 11:16:2112112 
请问multisim中没有DP9503B这个芯片的模型,需要怎么找啊?这个芯片是一款非隔离LED恒流驱动芯片。
2024-01-09 11:54:49
并行编程模型是并行计算,尤其是并行软件的基础,也是并行硬件系统的导向,在面临多核新挑战的情况下,什么样的并行编程模型在未来能成为主流,还很难说。至少到目前,还处于百家争鸣的时代,很多模型提出,很多在应用,下面我们简单介绍一下当前的并行编程模型现状。
2019-07-11 08:03:33
数据采集编程指南 上篇.pdf
2015-12-12 21:02:50
训练好的ai模型导入cubemx不成功咋办,试了好几个模型压缩了也不行,ram占用过大,有无解决方案?
2023-08-04 09:16:28
CV之YOLOv3:深度学习之计算机视觉神经网络Yolov3-5clessses训练自己的数据集全程记录
2018-12-24 11:51:47
CV之YOLO:深度学习之计算机视觉神经网络tiny-yolo-5clessses训练自己的数据集全程记录
2018-12-24 11:50:57
Django之模型(二)
2020-05-29 10:01:49
工具篇Flair之训练模型教程
2020-04-27 14:03:05
),其中y取值1或-1(代表二分类的类别标签),这也是GBDT可以用来解决分类问题的原因。模型训练代码地址 https://github.com/qianshuang/ml-expdef train
2019-01-23 14:38:58
连接器)。外部以太网链路可以连接到任何交换层次结构。Suchconfiguration可以进行优化,以大规模实现textra大型模型并行性,并可以轻松处理数据并行性或模型和数据并行性的组合。
GAUDI
2023-08-04 06:06:14
TensorFlow笔记(4)——优化手写数字识别模型之代价函数和拟合
2019-10-21 10:39:55
会得到添加了高斯噪声的新图像。高斯噪声也称为白噪声,是一种服从正态分布的随机噪声。 在深度学习中,训练时往往会在输入数据中加入高斯噪声,以提高模型的鲁棒性和泛化能力。 这称为数据扩充。 通过向输入数据添加
2023-02-16 14:04:10
本教程以实际应用、工程开发为目的,着重介绍模型训练过程中遇到的实际问题和方法。在机器学习模型开发中,主要涉及三大部分,分别是数据、模型和损失函数及优化器。本文也按顺序的依次介绍数据、模型和损失函数
2018-12-21 09:18:02
简单来说:所谓模型就是一个滤波器,训练的权重就是滤波系数,输入经过滤波器后得到一个输出。所以嵌入式AI部署一般就是解析模型得到“滤波系数”,输入信号进行一系列类似"滤波&
2023-08-18 07:01:53
labview数据采集图解数据采集图解 模拟量到数字量的转换:为了使计算机能够处理或存储信号,将模拟电压或电流转换为数字信息数字量到模拟量的转换:将数字信息转换为模拟电压或电流,使计算机能够控制设备
2008-08-03 20:03:55
能否直接调用训练好的模型文件?
2021-06-22 14:51:03
准备开始为家猫做模型训练检测,要去官网https://maix.sipeed.com/home 注册帐号,文章尾部的视频是官方的,与目前网站略有出路,说明训练网站的功能更新得很快。其实整个的过程
2022-06-26 21:19:40
多种形式和任务。这个阶段是从语言模型向对话模型转变的关键,其核心难点在于如何构建训练数据,包括训练数据内部多个任务之间的关系、训练数据与预训练之间的关系及训练数据的规模。
奖励建模阶段的目标是构建一个文本
2024-03-11 15:16:39
用于训练模型,如下图所示:我选择的方式为上传本地图片的方式,选项选择如下:上传图片后,我们需要对图片进行标记,操作则需要点击下图所示的 查看与标注第四步:在创建数据集完成后,就是模型训练,我们进入模型
2021-03-23 14:32:35
(三)使用YOLOv3训练BDD100K数据集之开始训练
2020-05-12 13:38:55
我正在尝试使用自己的数据集训练人脸检测模型。此错误发生在训练开始期间。如何解决这一问题?
2023-04-17 08:04:49
医疗模型人训练系统是为满足广大医学生的需要而设计的。我国现代医疗模拟技术的发展处于刚刚起步阶段,大部分仿真系统产品都源于国外,虽然对于模拟人仿真已经出现一些产品,但那些产品只是就模拟人的某一部分,某一个功能实现的仿真,没有一个完整的系统综合其所有功能。
2019-08-19 08:32:45
问题最近在Ubuntu上使用Nvidia GPU训练模型的时候,没有问题,过一会再训练出现非常卡顿,使用nvidia-smi查看发现,显示GPU的风扇和电源报错:解决方案自动风扇控制在nvidia
2022-01-03 08:24:09
CV:基于Keras利用训练好的hdf5模型进行目标检测实现输出模型中的脸部表情或性别的gradcam(可视化)
2018-12-27 16:48:28
CV之CNN:基于Keras利用cv2建立训练存储CNN模型(2+1)并调用摄像头进行实时人脸识别
2018-12-26 11:09:16
CV:基于Keras利用CNN主流架构之mini_XCEPTION训练情感分类模型hdf5并保存到指定文件夹下
2018-12-26 11:08:26
我正在尝试使用 eIQ 门户训练人脸检测模型。我正在尝试从 tensorflow 数据集 (tfds) 导入数据集,特别是 coco/2017 数据集。但是,我只想导入 wider_face。但是,当我尝试这样做时,会出现导入程序错误,如下图所示。任何帮助都可以。
2023-04-06 08:45:14
`如何正确理解功率MOSFET的数据表(上篇).`
2012-08-13 14:24:17
工作探索了如何在小型数据集上从头开始训练ViT。也有工作在探索如何在24小时内对文本数据训练BERT模型,但它使用8个GPU的服务器,而作者将自己限制在单个GPU。Primer建议寻找
2022-11-24 14:56:31
想好做什么样的。【背景是切割垫,每一小格是1cmX1cm的方块,方便大家比较大小。】火车模型教程开始:这些是主要的材料 自制遥控火车模型的教程图解取一小块PVC管槽,用铁尺和笔刀将其两边切整齐,在距其中
2012-12-29 15:03:47
),其中y取值1或-1(代表二分类的类别标签),这也是GBDT可以用来解决分类问题的原因。模型训练代码地址 https://github.com/qianshuang/ml-expdef train
2019-01-25 15:02:15
概述:DDP3310B是Micronas公司出品的一款用于CRT彩电中的视频解码处理芯片,其具备视频处理、偏转处理等功能。DDP3310B采用68引脚PLCCK封装工艺。
2021-04-08 07:45:45
目前官方的线上模型训练只支持K210,请问K510什么时候可以支持
2023-09-13 06:12:13
Mali T604 GPU的结构是由哪些部分组成的?Mali T604 GPU的编程特性有哪些?Mali GPU的并行化计算模型是怎样构建的?基于Mali-T604 GPU的快速浮点矩阵乘法并行化该如何去实现?
2021-04-19 08:06:26
proteus中有仿真模型的并行插口怎么绘制?
2019-04-23 20:14:43
算法隐含并行性的物理模型:利用物理学原理对算法的隐含并行性进行了分析,提出算法的不确定性和高熵态是隐含并行性出现的根源,但算法的隐含并行性会导致算法结果的不确定
2009-10-21 08:23:07 10
10 什么是声卡DDP电路/声卡杜比定逻辑技术
DDP电路:DDP(Double Detect and Protect:二重探测与保护),它可以使Space对输入的信号不再重复处
2010-02-05 11:34:55558 LabVIEW数据采集编程指南【上篇】,之前有一篇中篇。记得一起看
2016-03-14 15:46:000 为针对受限玻尔兹曼机处理大数据时存在的训练缓慢、难以得到模型最优的问题,提出了基于CJPU的RBM模型训练并行加速方法。首先重新规划了对比散度算法在CJPU的实现步骤;其次结合以往CJPU并行方案
2017-11-07 14:38:4612 针对大容量固态存储器中数据错“位”的问题,目前大多采用软件ECC 模型进行检错和纠错,但这势必会极大地影响存储系统的读写性能。基于ECC校验原理,提出一种并行硬件ECC 模型,并采用FPGA 实现。仿真分析和实验结果表明:该模型不仅具有良好的纠错能力,而且显著地提高了存储系统的读写性能。
2017-11-18 10:32:515229 
发电机模型制作图解
2018-09-17 10:47:0011723 具体来说,就是对于每个workload(模型、训练算法和数据集),如果我们在刚开始的时候增加batch size,模型所需的训练步骤数确实会按比例逐渐减少,但越到后期,步骤数的减少量就越低,直到
2018-11-29 08:57:262778 
深度学习模型和数据集的规模增长速度已经让 GPU 算力也开始捉襟见肘,如果你的 GPU 连一个样本都容不下,你要如何训练大批量模型?通过本文介绍的方法,我们可以在训练批量甚至单个训练样本大于 GPU
2018-12-03 17:24:01668 神经网络训练硬件具备越来越强大的数据并行化处理能力。基于 GPU 或定制 ASIC 的专门系统辅以高性能互连技术使得能够处理的数据并行化规模前所未有地大,而数据并行化的成本和收益尚未得到深入研究
2018-12-19 10:39:213273 
正如我们在本文中所述,ULMFiT使用新颖的NLP技术取得了令人瞩目的成果。该方法对预训练语言模型进行微调,将其在WikiText-103数据集(维基百科的长期依赖语言建模数据集Wikitext之一)上训练,从而得到新数据集,通过这种方式使其不会忘记之前学过的内容。
2019-04-04 11:26:2623192 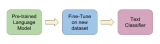
自然图像领域中存在着许多海量数据集,如ImageNet,MSCOCO。基于这些数据集产生的预训练模型推动了分类、检测、分割等应用的进步。
2019-08-20 15:03:161871 生成的数据生成准确的预测。这些新数据示例可能是用户交互、应用处理或其他软件系统的请求生成的——这取决于模型需要解决的问题。在理想情况下,我们会希望自己的模型在生产环境中进行预测时,能够像使用训练过程中使用
2020-04-10 08:00:000 成功训练计算机视觉任务的深层卷积神经网络需要大量数据。这是因为这些神经网络具有多个隐藏的处理层,并且随着层数的增加,需要学习的样本数也随之增加。如果没有足够的训练数据,则该模型往往会很好地学习训练数据,这称为过度拟合。如果模型过拟合,则其泛化能力很差,因此对未见的数据的表现很差。
2020-05-04 08:59:002727 本文把对抗训练用到了预训练和微调两个阶段,对抗训练的方法是针对embedding space,通过最大化对抗损失、最小化模型损失的方式进行对抗,在下游任务上取得了一致的效果提升。 有趣的是,这种对抗
2020-11-02 15:26:491802 
BERT的发布是这个领域发展的最新的里程碑之一,这个事件标志着NLP 新时代的开始。BERT模型打破了基于语言处理的任务的几个记录。在 BERT 的论文发布后不久,这个团队还公开了模型的代码,并提供了模型的下载版本
2020-11-24 10:08:223200 导读:预训练模型在NLP大放异彩,并开启了预训练-微调的NLP范式时代。由于工业领域相关业务的复杂性,以及工业应用对推理性能的要求,大规模预训练模型往往不能简单直接地被应用于NLP业务中。本文将为
2020-12-31 10:17:112217 
。但是不同的是,因为IPT是同时训练多个task,因此模型定义了多个head和tail分别对应不同的task。
2021-03-03 16:05:543903 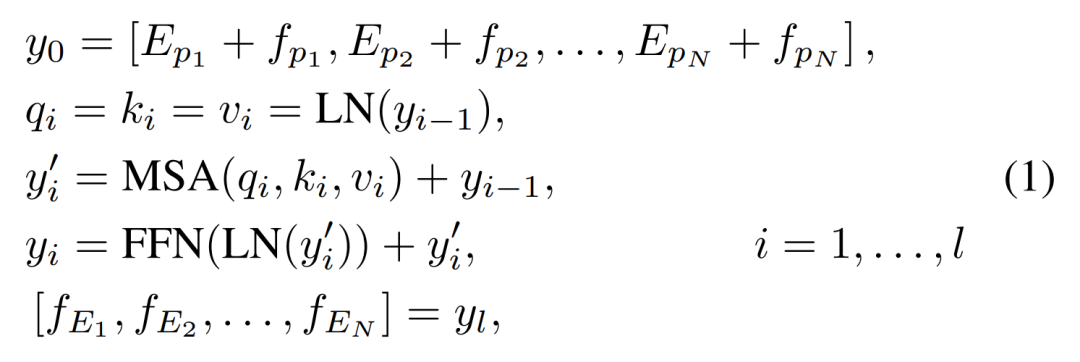
为提高卷积神经网络目标检测模型精度并增强检测器对小目标的检测能力,提出一种脱离预训练的多尺度目标检测网络模型。采用脱离预训练检测网络使其达到甚至超过预训练模型的精度,针对小目标特点
2021-04-02 11:35:5026 在某一方面的智能程度。具体来说是,领域专家人工构造标准数据集,然后在其上训练及评价相关模型及方法。但由于相关技术的限制,要想获得效果更好、能力更强的模型,往往需要在大量的有标注的数据上进行训练。 近期预训练模型的
2021-09-06 10:06:533351 
大模型的预训练计算。 上篇主要介绍了大模型训练的发展趋势、NVIDIA Megatron的模型并行设计,本篇将承接上篇的内容,解析Megatron 在NVIDIA DGX SuperPOD 上的实践
2021-10-20 09:25:432078 NLP中,预训练大模型Finetune是一种非常常见的解决问题的范式。利用在海量文本上预训练得到的Bert、GPT等模型,在下游不同任务上分别进行finetune,得到下游任务的模型。然而,这种方式
2022-03-21 15:33:301843 “强悍的织女模型在京东探索研究院建设的全国首个基于 DGX SuperPOD 架构的超大规模计算集群 “天琴α” 上完成训练,该集群具有全球领先的大规模分布式并行训练技术,其近似线性加速比的数据、模型、流水线并行技术持续助力织女模型的高效训练。”
2022-04-13 15:13:11783 由于乱序语言模型不使用[MASK]标记,减轻了预训练任务与微调任务之间的gap,并由于预测空间大小为输入序列长度,使得计算效率高于掩码语言模型。PERT模型结构与BERT模型一致,因此在下游预训练时,不需要修改原始BERT模型的任何代码与脚本。
2022-05-10 15:01:271173 CLIP是近年来在多模态方面的经典之作,得益于大量的数据和算力对模型进行预训练,模型的Zero-shot性能非常可观,甚至可以在众多数据集上和有监督训练媲美。
2022-10-13 09:13:043675 电子发烧友网报道(文/李弯弯)在深度学习中,经常听到一个词“模型训练”,但是模型是什么?又是怎么训练的?在人工智能中,面对大量的数据,要在杂乱无章的内容中,准确、容易地识别,输出需要的图像/语音
2022-10-23 00:20:037253 为了解决这一问题,本文主要从预训练语言模型看MLM预测任务、引入prompt_template的MLM预测任务、引入verblize类别映射的Prompt-MLM预测、基于zero
2022-11-14 14:56:342497 可以访问预训练模型的完整源代码和模型权重。 该工具套件能够高效训练视觉和对话式 AI 模型。由于简化了复杂的 AI 模型和深度学习框架,即便是不具备 AI 专业知识的开发者也可以使用该工具套件来构建 AI 模型。通过迁移学习,开发者可以使用自己的数据对 NVIDIA 预训练模型进行微调,
2022-12-15 19:40:06722 在应用程序开发周期中,第一步是准备和预处理可用数据以创建训练和验证/测试数据集。除了通常的数据预处理外,在MAX78000上运行模型还需要考虑几个硬件限制。
2023-02-21 12:11:44903 BERT类模型的工作模式简单,但取得的效果也是极佳的,其在各项任务上的良好表现主要得益于其在大量无监督文本上学习到的文本表征能力。那么如何从语言学的特征角度来衡量一个预训练模型的究竟学习到了什么样的语言学文本知识呢?
2023-03-03 11:20:00911 每个单词都依赖于输入文本与之前生成的单词。自回归生成模型只建模了前向的单词依赖关系,依次生成的结构也使得自回归模型难以并行化。目前大部分预训练生成模型均采用自回归方式,包括GPT-2,BART,T5等模型。
2023-03-13 10:39:59910 预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用需求进行自定义。 如果要教一个刚学会走路的孩子什么是独角兽,那么我们首先应
2023-04-04 01:45:021025 和充沛优质的硬件资源 算法的迭代创新 在大模型训练这个系列里,我们将一起探索学习几种经典的分布式并行范式,包括 流水线并行(Pipeline Parallelism),数据并行(Data
2023-05-25 11:41:21625 
预训练 AI 模型是为了完成特定任务而在大型数据集上训练的深度学习模型。这些模型既可以直接使用,也可以根据不同行业的应用需求进行自定义。
2023-05-25 17:10:09595 实验室在 SageMaker Studio Lab 中打开笔记本
为了预训练第 15.8 节中实现的 BERT 模型,我们需要以理想的格式生成数据集,以促进两项预训练任务:掩码语言建模和下一句预测
2023-06-05 15:44:40442 前文说过,用Megatron做分布式训练的开源大模型有很多,我们选用的是THUDM开源的CodeGeeX(代码生成式大模型,类比于openAI Codex)。选用它的原因是“完全开源”与“清晰的模型架构和预训练配置图”,能帮助我们高效阅读源码。我们再来回顾下这两张图。
2023-06-07 15:08:242186 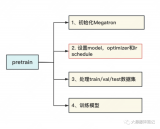
使用原始的 Megatron-LM 训练 GPT2 设置训练数据 运行未修改的Megatron-LM GPT2模型 开启DeepSpeed DeepSpeed 使用 GPT-2 进行评估 Zero
2023-06-12 10:25:331841 
文章称,他们从许多来源收集了大量有关 GPT-4 的信息,包括模型架构、训练基础设施、推理基础设施、参数量、训练数据集组成、token 量、层数、并行策略、多模态视觉适应、不同工程权衡背后的思维过程、独特的实现技术以及如何减轻与巨型模型推理有关的瓶颈等。
2023-07-12 14:16:57402 
大型语言模型如 ChatGPT 的成功彰显了海量数据在捕捉语言模式和知识方面的巨大潜力,这也推动了基于大量数据的视觉模型研究。在计算视觉领域,标注数据通常难以获取,自监督学习成为预训练的主流方法
2023-07-24 16:55:03272 
模型训练是将模型结构和模型参数相结合,通过样本数据的学习训练模型,使得模型可以对新的样本数据进行准确的预测和分类。本文将详细介绍 CNN 模型训练的步骤。 CNN 模型结构 卷积神经网络的输入
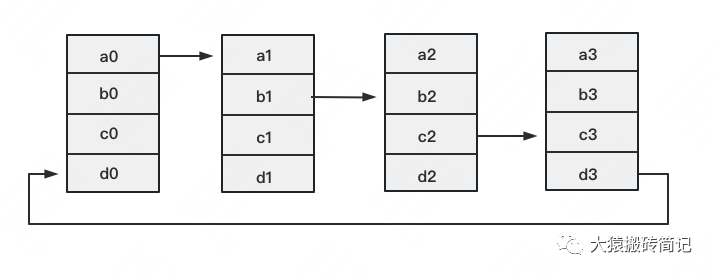
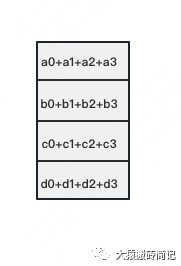
2023-08-21 16:42:00885 数据并行是最常见的并行形式,因为它很简单。在数据并行训练中,数据集被分割成几个碎片,每个碎片被分配到一个设备上。这相当于沿批次(Batch)维度对训练过程进行并行化。每个设备将持有一个完整的模型副本,并在分配的数据集碎片上进行训练。
2023-08-24 15:17:28537 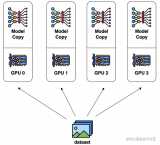
在《英特尔锐炫 显卡+ oneAPI 和 OpenVINO 实现英特尔 视频 AI 计算盒训推一体-上篇》一文中,我们详细介绍基于英特尔 独立显卡搭建 YOLOv7 模型的训练环境,并完成了 YOLOv7 模型训练,获得了最佳精度的模型权重。
2023-08-25 11:08:58819 
流浪者缓解PyTorch DDP的层次SGD
2023-08-31 14:27:11290 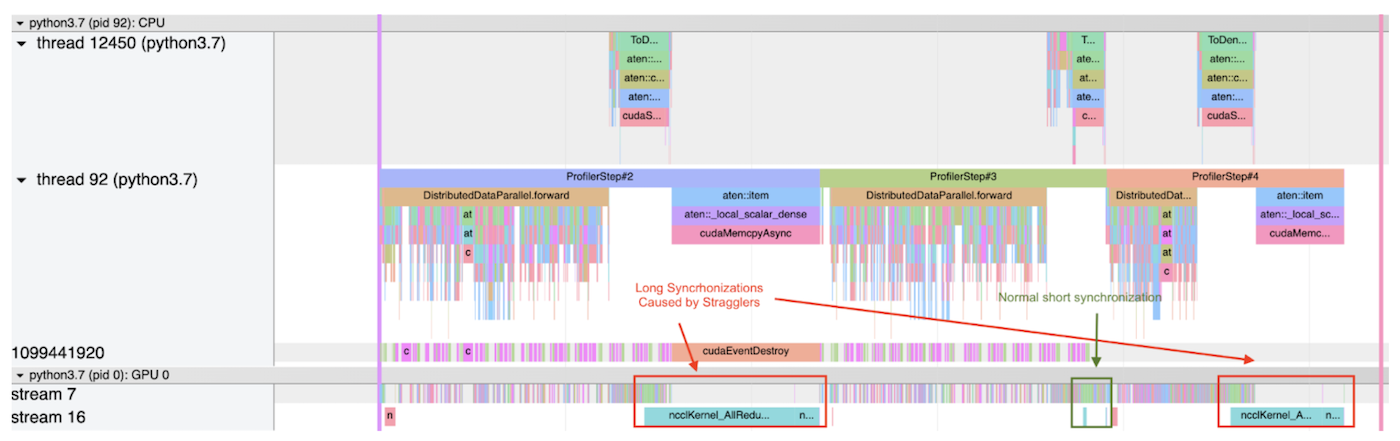
生成式AI和大语言模型(LLM)正在以难以置信的方式吸引全世界的目光,本文简要介绍了大语言模型,训练这些模型带来的硬件挑战,以及GPU和网络行业如何针对训练的工作负载不断优化硬件。
2023-09-01 17:14:561046 
model 训练完成后,使用 instruction 以及其他高质量的私域数据集来提升 LLM 在特定领域的性能;而 rlhf 是 openAI 用来让model 对齐人类价值观的一种强大技术;pre-training dataset 是大模型在训练时真正喂给 model 的数据,从很多 paper 能看到一些观
2023-09-19 10:00:06506 
NVIDIA Megatron 是一个基于 PyTorch 的分布式训练框架,用来训练超大Transformer语言模型,其通过综合应用了数据并行,Tensor并行和Pipeline并行来复现 GPT3,值得我们深入分析其背后机理。
2023-10-23 11:01:33826 
Parallel,简称DDP),它也仅仅是能将数据并行,放到各个GPU的模型上进行训练。 也就是说,DDP的应用场景在你的模型大小大于显卡显存大小时,它就无法使用了,除非你自己再将模型参数拆散分散
2023-10-30 10:09:45951 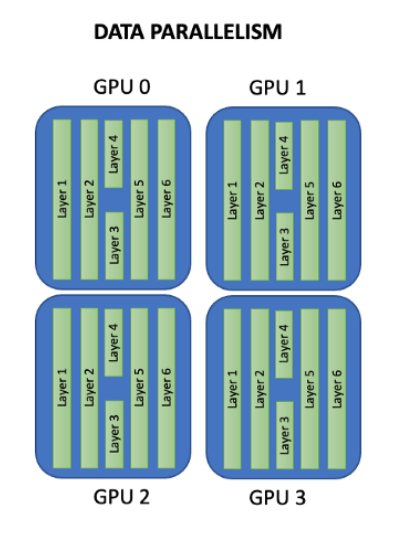
如果我们使用的 数据集较大 ,且 网络较深 ,则会造成 训练较慢 ,此时我们要 想加速训练 可以使用 Pytorch的AMP ( autocast与Gradscaler );本文便是依据此写出
2023-11-03 10:00:191054 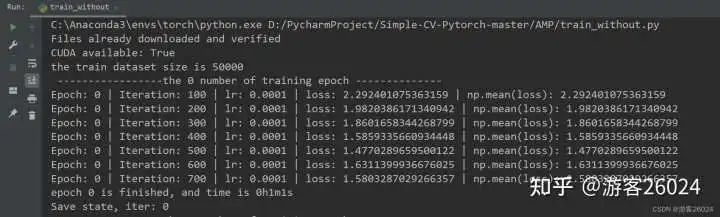
算法工程、数据派THU深度学习在近年来得到了广泛的应用,从图像识别、语音识别到自然语言处理等领域都有了卓越的表现。但是,要训练出一个高效准确的深度学习模型并不容易。不仅需要有高质量的数据、合适的模型
2023-12-07 12:38:24547 
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现圆检测与圆心位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上训练,生成一个自定义的圆检测与圆心定位预测模型
2023-12-21 10:50:05529 
Hello大家好,今天给大家分享一下如何基于深度学习模型训练实现工件切割点位置预测,主要是通过对YOLOv8姿态评估模型在自定义的数据集上训练,生成一个工件切割分离点预测模型
2023-12-22 11:07:46259 
谷歌在模型训练方面提供了一些强大的软件工具和平台。以下是几个常用的谷歌模型训练软件及其特点。
2024-03-01 16:24:01184
 电子发烧友App
电子发烧友App

















 工商网监
工商网监
评论