 电子发烧友App
电子发烧友App


1
概述
语音识别技术,是将语音信号转换为文本内容的技术。目前比较流行的语音识别技术主要有两种。一种是基于Kaldi的传统语音识别技术,另一种是目前流行的基于深度学习模型的端到端语音识别技术。Kaldi是一种大而全的语音识别处理框架,集成了数据预处理、特征提取、声学模型建模、语言模型建模、解码等,识别效果上能够满足大多数的语音识别场景。但是Kaldi是自成一体的框架,没有现在流行的pytorch、tensorflow框架的支持,需要开发者自行开发能应用到生产环境中的服务。基于深度学习模型的端到端语音识别框架是指将语音信号直接输入到深度学习模型中,通过端到端的方式进行语音识别,无需使用传统的声学模型和语言模型,常见的基于深度学习的端到端语音识别框架有很多,比如EspNet,WeNet等,这类语音识别框架有更通用的模型训练和部署框架支持,有着更好的识别性能和识别效果。
58自研语音识别引擎,最初是基于Kaldi框架进行开发,在自研初期上线了架构1.0版本,后续以降低机器资源、提升资源利用率、优化性能为目标进行了升级重构,上线了架构2.0版本。本文将介绍基于Kaldi的语音识别引擎的架构设计,介绍从架构1.0到2.0版本的优化历程。首先介绍业务背景,然后介绍Kaldi语音解码的优化,以及后端服务的各种优化,最后是优化取得的效果。
我们也在持续探索基于深度学习模型的端到端语音识别,尝试了ESPNet,WeNet等流行的端到端框架。在2021年12月引入了端到端WeNet语音识别(由出门问问和西北工业大学于2021年1月开源),经过持续的优化,WeNet解码服务在效果和性能上都超过了Kadli解码,在2022年8月份,我们在线上全量替换了Kaldi语音解码服务(WeNet端到端语音识别技术在58同城的大规模落地)。
2
背景
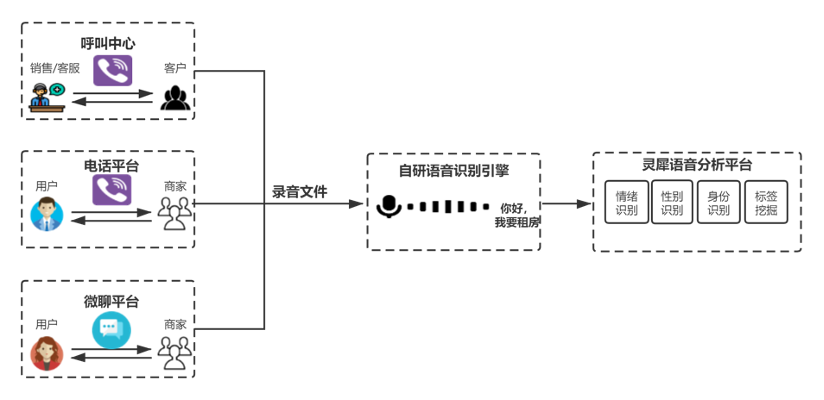
58同城是国内领先的生活分类信息网站平台,涉及业务有招聘、房产、车、本地生活服务(黄页)等。语音是平台上商家、用户、销售、客服之间沟通的主要媒介。
58平台上的B端商家和C端用户会使用电话、微聊进行语音沟通,同时58呼叫中心支撑着数千名销售、客服人员工作,年通话时长数百万小时。这些场景下产生了海量的语音数据,这些语音数据经过语音识别转为文字之后,对于语音质检、信息治理和用户画像等任务有巨大的价值。此外,AI Lab团队研发了可以提高人效的语音外呼机器人,典型应用为销售机器人“黄页销售智能外呼助手”和面试机器人“神奇面试间”。
3
架构1.0
3.1 架构1.0的背景
我们从2019年12月开始语音识别引擎的自研工作(3人半年打造语音识别引擎——58同城语音识别自研之路),业务方采购的是第三方的语音识别引擎,采购费用昂贵,采购合同即将在半年后到期。最终提前一个月上线切换到自研语音识别引擎。
语音识别系统通用处理流程是:客户端发送音频文件或者音频流,服务端在接收后进行格式、采样率等转换,以及声道分离、说话分离,转换为多个人声片段,再由解码器对人声片段进行解码,输出转写结果。一个语音识别系统的重点和关键点就是在尽量低资源(CPU/GPU)占用的情况下,能较大吞吐、较低延迟、较可靠的处理海量的音频输入,并保持较高的转写准确率。
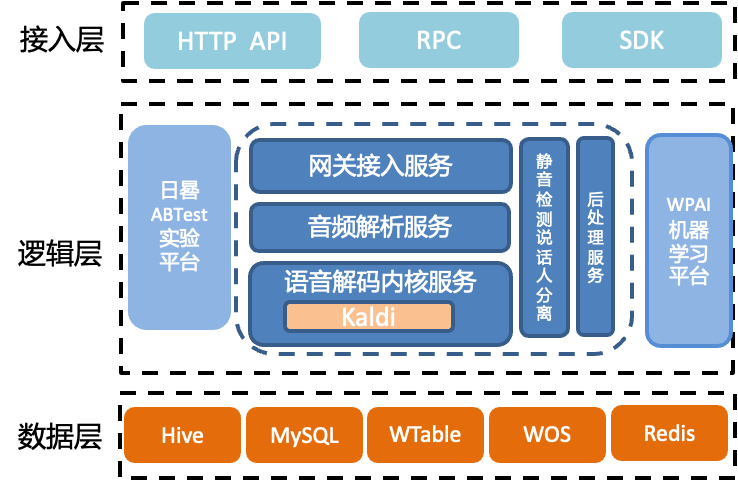
架构1.0系统,基于语音识别系统的通用流程建立,服务主要包括网关接入服务、音频解析服务、以及基于Kaldi的语音解码内核服务、静音检测和说话人服务、后处理服务等。各服务的主要功能:
网关接入服务,负责业务接入分发、鉴权和检测等功能。
音频解析服务,负责将音频做转换处理。语音解码内核服务负责将音频解码为文字。
静音检测和说话人服务,负责将人声片段分离出来,用于后续解码。
后处理服务,负责将转写后文字添加标点等处理任务。
语音解码内核服务,负责将音频片段转写为文本。
3.2 架构1.0的不足
架构1.0系统是在时间紧、任务重的情况下,满足了快速上线的需要,但也存在以下不足:
占用机器资源太高
机器资源利用率不均衡
系统整体耗时高
可靠性和扩展性不足
重构的目标主要是以下三个:
降低机器资源,节省成本
提高机器资源利用率
降低系统耗时、提升可靠性
4
架构2.0
针对架构1.0的不足,主要在以下两个大方向上进行优化:
1. 针对语音内核解码服务中,Kaldi并发解码支持不足、性能差的问题,进行了服务性能优化
2. 针对后端应用服务中的不足,进行了服务拆分和一系列的性能优化。
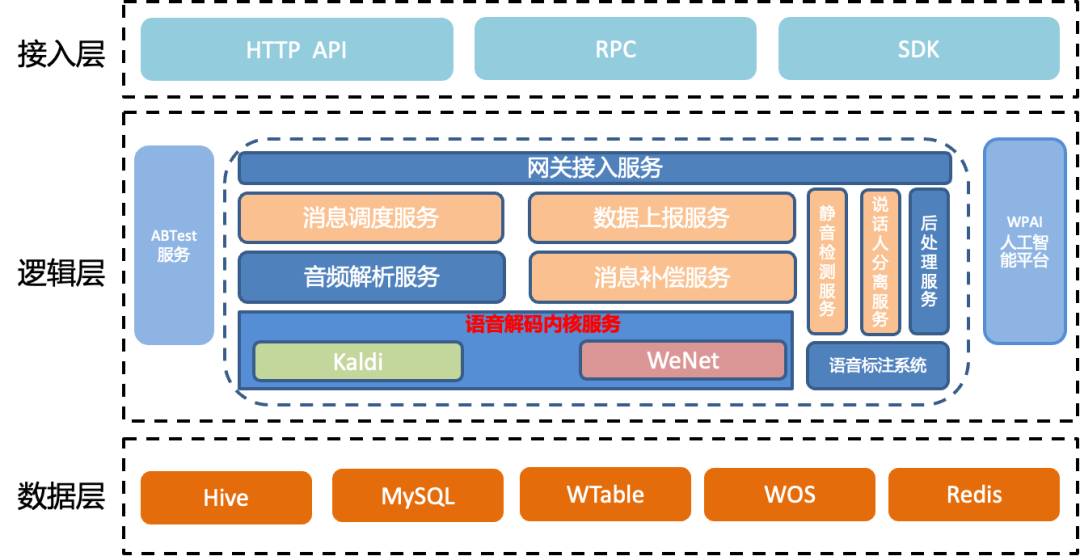
架构2.0对1.0架构中部分服务功能耦合的部分进行了拆分、对网关接入服务、音频解析、解码内核服务做了重构升级。
架构2.0的服务包括网关接入服务、消息调度服务、数据上报服务、音频解析服务、消息补偿服务、静音检测服务、说话人分离服务、以及语音解码内核服务等。其中新增了消息调度服务、数据上报服务、消息补偿服务。静音检测服务、说话人分离服务,是从之前静音检测和说话人分离服务拆分而来。对这几个服务的情况进行如下说明:
网关接入服务,负责业务接入分发、鉴权和检测等功能。将消息可靠性功能拆分为补偿服务,对服务的性能进行了优化
消息调度服务、数据上报服务,负责基于机器负载状态进行消息分发。
消息补偿服务,将消息补偿的部分消息可靠性保证的功能,从之前的服务中拆分,负责对不同业务提供不同个性化补偿策略。
静音检测服务、是从之前静音检测和说话人分离服务拆分而来,将之前同步的流程拆分,进行异步处理。
语音解码内核服务,负责将音频片段转写为文本。将语音解码内核服务优化为可以进行并发解码,处理并发请求。
4.1 Kaldi解码优化实践
Kaldi主要功能由c++开发完成,共有26万行代码。解码器是Kaldi中的核心组件,用于将声学特征序列转换为文本序列。Kaldi提供了一些解码器的接口,以及shell离线脚本demo。但是未提供生产级的服务。Kaldi原生解码的主要问题有:
4.1.1 无服务化支持
需要梳理调用关系,增加服务端、协议、客户端调用支持。我们将模型、解码器相关的接口抽象出来,封装为gRPC服务,服务接收音频数据、解码为文本转写结果。
4.1.2 无并发能力支持
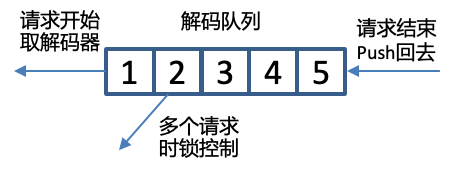
原生的解码器对并发请求的处理能力差。需要将服务的网络请求模型和解码器关联起来,使服务获取并发处理能力。我们的方案是服务启动时初始化足够的解码器数目到同步队列中,当服务请求线程到来时,从队列中取出解码器。当请求结束后,再放回队列中。
那么服务启动时初始化足够数目的解码器,这个数目是多少比较合适?服务初始的解码器数目,就是可以支持的最大并行解码的数目,这个数目越大,耗时越高、CPU/GPU的资源利用率越高。设置多少数目的解码器,取决对实时率、尾包延迟的性能要求、也取决于服务器的硬件性能。比如在一台CPU是Intel Xeon Silver 4210的物理机上,转写一个30s的音频,要求在2s内返回转写结果,系统最多能容忍32个解码器并行处理,或者正在实时转写的数据流,尾包延迟要求在100ms内,系统最多能容忍16个解码器并行处理。以定义好的性能数值为目标,从小到大的设置解码器数目进行测试,满足性能数值目标时,此时的数字就是服务需要初始化的解码器数目。
4.1.3 CUDA GPU解码支持不足
需要处理CUDA环境、模型、解码器的关系,对于非Exclusive模式有OOM异常风险。一个解码服务进程只能有一个模型对象进行初始化,CUDA环境和模型对象是一一映射关系,单卡绑定一个CUDA环境、一个模型对象。而模型对象和解码器之间是一对多的关系。
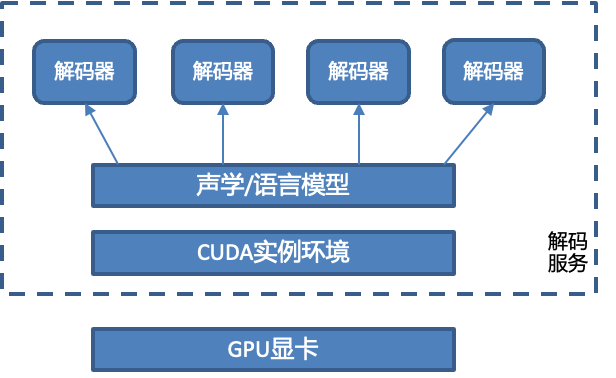
对于GPU解码需要注意多个并发请求时转写结果偶尔会出现乱码、错字等情况,这是由于在Kaldi CUDA接口中的转写回调函数在一个进程环境下只有一个,这里需要在回调函数处理转写结果时加锁、避免这些问题。
另外的一个问题是在GPU解码获取lattice回调结果时,有资源未清理的问题,会直接导致进程异常退出,这是由于在初始化时解码进程绑定了唯一id和cuda channel的关系,但是在解码结束时没有解绑导致的,这个问题我们发现后提交了PR就行了修复。
最终,解码服务的设计如下,基于Kaldi和CUDA环境,在离线环境中完成声学模型、语言模型的训练、添加相关的配置。在解码服务启动时,加载服务配置,加载离线训练的模型,初始化解码器同步队列,当有音频请求到来时,根据协议判断音频请求的开始和结束状态,从队列中加载解码器,转写出结果后,返回给服务的调用方。
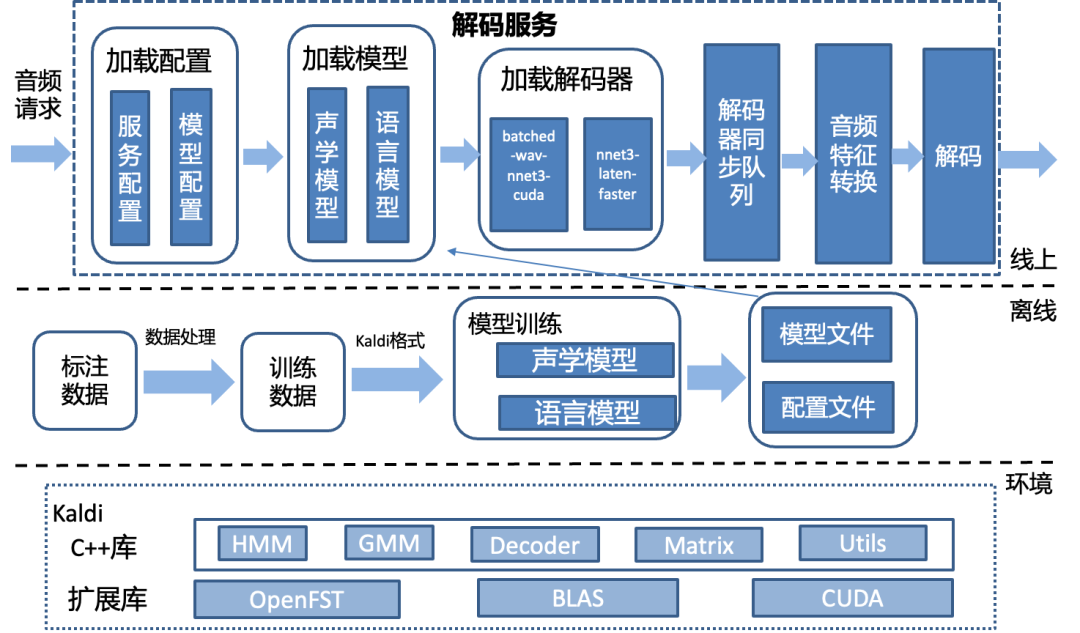
4.2 后端应用服务的优化
除了在语音解码服务上的优化,在后端服务上我们也进行了一系列的优化,包含并发处理、多级缓存、I/O优化、GC优化、异步处理、分发效率优化等方面,大大的优化了系统的处理性能。具体的优化如下:
4.2.1 并发处理和两级缓存优化
在音频解析服务中,有很多音频解析、转换、分离、解码、组合的处理模块,处理链路长,而消息接收的效率、解析转换的效率、解码的效率是不同的。如果整个处理过程是单一的处理链条,由于模块间处理效率上的不匹配,会出现下游模块等待上游模块的情况,那么整体的处理效率就会受到影响。为了尽可能降低模块间的阻塞等待,可以将耦合度低的模块拆分出来,增加缓存单独并行处理,此时可以认为两个缓存下的模块是并行处理的链条,在处理效率上理论上大于等于单一链条的处理效率。在单一链条模块有阻塞等待情况时,甚至要远高于单一链条的处理效率。
将服务优化为设立二级缓存来缩短处理链条,同时两个缓存下的模块独立并行处理。二级缓存中的第一级在消息接收和解码转换之间,第二级在转换和解码之间,在两个不同分级之间,使用多线程批量处理提高吞吐能力。优化后相比优化前,TP999耗时降低了91%。
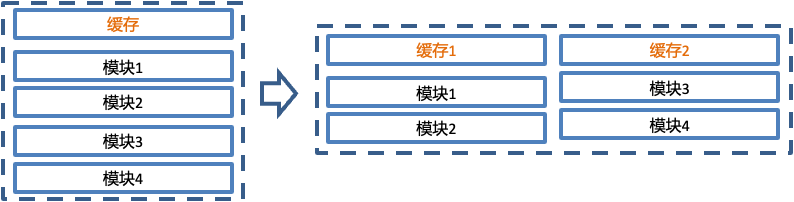
4.2.2 I/O优化
常说的I/O包含网络I/O、磁盘I/O、设备I/O等,由于I/O时通常会涉及到数据交换、系统内核态的切换,相应的就会增加系统的开销。我们本次I/O优化利用缓存、批量处理等手段来降低I/O,提升系统的性能。在服务中,涉及到多次磁盘I/O和网络I/O:
(1) 服务里包含对大量音频文件的读写操作,会产生多次的磁盘I/O读。通过使用缓存,以空间换时间的方式,将多次磁盘I/O读降低为通过一次I/O缓存全部数据,缺点是增加了内存,由于服务是Java服务,会相应的增加GC回收频率和停顿时长,那就还涉及到GC上的优化。
(2)服务里包含请求和响应相似的单独请求,涉及到大量的网络I/O。通过将这些相似请求进行合并,增加批量接口,进行批量请求,降低网络I/O次数。
整体上,优化后相比优化前,TP999耗时降低了10倍。
4.2.3 GC优化
系统中的上层处理服务是Java服务,Java服务由于垃圾回收的关系,会在回收期间暂停应用程序线程的执行(Stop-The-World),直到垃圾回收操作完成,毫无疑问这会降低系统性能。之前服务使用G1垃圾回收器,也进行了参数调优,比如增加堆内存、调整G1HeapRegionSize、MaxGCPauseMillis等,但是效果不是很理想。这是由于缓存音频数据导致服务的内存占用大,老年代对象较多,会频繁的进行Mixed GC和Full GC。服务中G1的回收频率5s左右,回收停顿的时间平均1.8s、最大停顿时间接近40s,拉低了服务整体处理性能。
ZGC在JDK11中首次发布,是一种低停顿时间、适合大堆内存的垃圾回收器,能在几毫秒到几十毫秒内完成垃圾回收。ZGC基于并发标记、并发转移、以及读屏障等技术,而且回收时仅需要扫描GC Roots, 使得STW的延迟非常低。通过将JDK版本升级到JDK11,使用ZGC回收器替换G1回收器后,GC回收频率控制在10~20s左右,回收停顿时间降低到10ms 以内。
4.2.4 分发效率优化
在之前的系统中,是基于不同业务场景的消息分发,对不同的业务场景实现消息隔离、资源隔离,在流量不高的情况下,这种实现方式简单、灵活。但在各业务流量增大,流量不均衡的情况下,会导致不同业务场景资源利用率不均衡、处理性能不均衡。
从基于业务场景的消息分发,修改为基于资源负载数据的消息分发。针对消息不同处理阶段,赋予不同的分发状态:接收状态、分发状态、处理状态、完成状态。根据这些状态和机器自身的负载数据,进行分发,尽可能的将消息发送到低利用率的机器上,以达到机器负载水平整体均衡的状态。优化后的实现方式,实现难度上有所增加,系统上有一个中心化的调度服务,根据收集到的数据分发调度。调度服务不但能实现基于负载的分发,也可以定向分发、或者延迟分发。
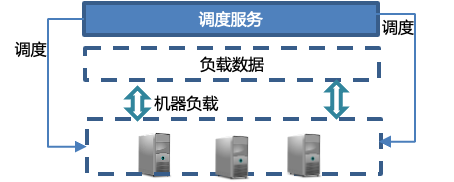
定向分发是对于某些业务场景,有特殊处理情况,可以将流量定向到某台机器、某个集群上去处理。延迟分发,是对于某些业务场景流量不规律,短时间的流量尖刺会发送大量请求,延迟分发对流量进行平滑、延迟处理,缓解对下游服务的处理负担。
4.2.5 异步化
如果在服务中存在一些耗时高的模块,但是和上下链的模块依赖度不高,和服务响应的关联度也不高,那么可以考虑将高耗时的模块异步处理,而快速返回低耗时模块的同步处理结果。
在网关接入服务中,就符合这些异步化处理的条件。存在一些高耗时模块,比如时长计算、音频下载分析等模块,而服务返回结果和这些高耗时模块也没有关联。其他功能模块和这个高耗时模块的依赖度也不高。如果服务采用同步处理,一方面服务的响应耗时会很高,另一方面会出现线程阻塞、请求排队的情况。采取的优化方案是将高耗时模块后置异步处理,而其它功能模块则同步处理,快速返回结果。优化上线后,将服务的TP999耗时从数百毫秒降低到了几十毫秒。
4.3 数据效果
从架构1.0升级到架构2.0后,在资源利用率、系统性能、系统可靠性上都得到了提升。GPU卡的最高利用率从45%提升到75%左右;GPU卡资源占用节省了62%;线上平均耗时降低了88%,TP999耗时降低了98%。
5
总结
本文介绍了基于Kaldi的语音识别引擎的后端架构设计,在前期人力少、排期紧、流量不大的情况下,快速了完成架构1.0的上线,满足了当时的业务转写需求。随着接入场景越来越多,流量越来越大,针对架构1.0的不足进行了重构和升级,重点针对基于Kaldi的内核解码服务的不足,进行了并发化改造优化,针对其它后端应用服务进行了拆分和性能优化,提升了GPU的利用率、以更低的资源占用处理更多的音频数据,系统的整体性能也有了较大幅度的降低,系统可靠性得到了更好的保证。
【作者简介】
王焱,58同城后端高级架构师,58同城TEG-AI Lab语音架构部负责人,主要负责语音识别、语音合成等语音技术的后端架构设计和开发工作。
编辑:黄飞














 工商网监
工商网监
评论