 电子发烧友App
电子发烧友App


计算机视觉中仍有许多具有挑战性的问题需要解决。然而,深度学习方法正在针对某些特定问题取得最新成果。
在最基本的问题上,最有趣的不仅仅是深度学习模型的表现;事实上,单个模型可以从图像中学习意义并执行视觉任务,从而无需使用专门的手工制作方法。
在这篇文章中,您将发现九个有趣的计算机视觉任务,其中深度学习方法取得了一些进展。
让我们开始吧。
概观
在这篇文章中,我们将研究以下使用深度学习的计算机视觉问题:
图像分类
具有本地化的图像分类
物体检测
对象分割
图像样式转移
图像着色
影像重建
图像超分辨率
图像合成
其他问题
注意,当涉及图像分类(识别)任务时,已采用ILSVRC的命名约定。虽然任务集中在图像上,但它们可以推广到视频帧。
我试图关注您可能感兴趣的最终用户问题的类型,而不是深度学习能够做得更好的学术问题。
每个示例都提供了问题的描述,示例以及对演示方法和结果的论文的引用。
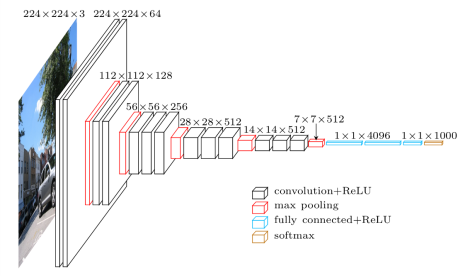
图像分类
图像分类涉及为整个图像或照片分配标签。
该问题也被称为“对象分类”,并且可能更一般地称为“图像识别”,尽管后一任务可以应用于与分类图像内容相关的更广泛的任务集。
图像分类的一些示例包括:
1、将X射线标记为癌症与否(二元分类)。
2、对手写数字进行分类(多类分类)。
3、为脸部照片指定名称(多类别分类)。
用作基准问题的图像分类的流行示例是MNIST数据集。

分类数字照片的流行真实版本是街景房号(SVHN)数据集。
有许多图像分类任务涉及对象的照片。两个流行的例子包括CIFAR-10和CIFAR-100数据集,这些数据集的照片分别分为10类和100类。
大规模视觉识别挑战赛(ILSVRC)是一项年度竞赛,其中团队在从ImageNet数据库中提取的数据上竞争一系列计算机视觉任务的最佳性能。图像分类方面的许多重要进步来自于发布在该挑战或来自该挑战的任务的论文,最值得注意的是关于图像分类任务的早期论文。例如:
使用深度卷积神经网络的ImageNet分类,2012。
用于大规模图像识别的非常深的卷积网络,2014。
围绕卷积更深入,2015年。
图像识别的深度残留学习,2015年。
具有本地化的图像分类
具有本地化的图像分类涉及为图像分配类标签并通过边界框(在对象周围绘制框)来显示图像中对象的位置。
这是一个更具挑战性的图像分类版本。
本地化图像分类的一些示例包括:
1.将X射线标记为癌症或在癌症区域周围画一个盒子。
2.在每个场景中对动物的照片进行分类并在动物周围画一个盒子。
用于具有定位的图像分类的经典数据集是PASCAL视觉对象类数据集,或简称为PASCAL VOC(例如VOC 2012)。这些是多年来在计算机视觉挑战中使用的数据集。
该任务可以涉及在图像中的同一对象的多个示例周围添加边界框。因此,该任务有时可称为“对象检测”。
用于本地化图像分类的ILSVRC2016数据集是一个流行的数据集,包含150,000张照片和1000种对象。
关于本地化图像分类的论文的一些例子包括:
选择性搜索对象识别,2013年。
用于精确对象检测和语义分割的丰富特征层次结构,2014年。
快速R-CNN,2015年。
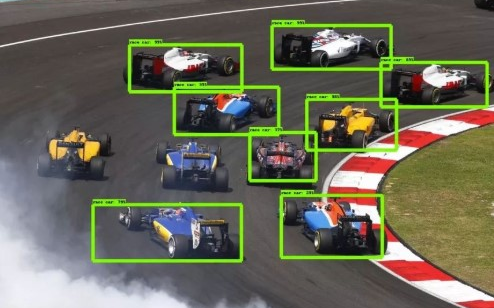
物体检测
物体检测是具有定位的图像分类的任务,尽管图像可能包含需要定位和分类的多个对象。
与简单的图像分类或具有定位的图像分类相比,这是一项更具挑战性的任务,因为在不同类型的图像中通常存在多个对象。
通常,使用并展示用于具有定位的图像分类的技术用于对象检测。
对象检测的一些示例包括:
绘制边界框并标记街道场景中的每个对象。
绘制边界框并在室内照片中标记每个对象。
绘制边界框并在横向中标记每个对象。
PASCAL Visual Object Classes数据集或简称PASCAL VOC(例如VOC 2012)是用于对象检测的常见数据集。
用于多个计算机视觉任务的另一个数据集是Microsoft的上下文数据集中的公共对象,通常称为MS COCO。
关于物体检测的论文的一些例子包括:
OverFeat:使用卷积网络的集成识别,本地化和检测,2014年。
更快的R-CNN:利用区域提案网络实现实时目标检测,2015年。
您只看一次:统一,实时对象检测,2015年。
对象分割
对象分割或语义分割是对象检测的任务,其中在图像中检测到的每个对象周围绘制线。图像分割是将图像分成段的更普遍的问题。
对象检测有时也称为对象分割。
与涉及使用边界框来识别对象的对象检测不同,对象分割识别图像中属于对象的特定像素。这就像一个细粒度的本地化。
更一般地,“图像分割”可以指将图像中的所有像素分割成不同类别的对象。
同样,VOC 2012和MS COCO数据集可用于对象分割。
KITTI Vision Benchmark Suite是另一种流行的对象分割数据集,提供用于自动驾驶车辆训练模型的街道图像。
关于对象分割的一些示例论文包括:
同步检测和分割,2014年。
用于语义分割的完全卷积网络,2015。
用于对象分割和细粒度本地化的超级列,2015。
SegNet:用于图像分割的深度卷积编码器 - 解码器架构,2016。
Mask R-CNN,2017年。
风格转移
风格转移或神经风格转移是从一个或多个图像学习风格并将该风格应用于新图像的任务。
该任务可以被认为是一种可能没有客观评价的照片滤波器或变换。
例子包括将特定着名艺术品(例如Pablo Picasso或Vincent van Gogh)的风格应用于新照片。
数据集通常涉及使用公共领域的着名艺术作品和标准计算机视觉数据集中的照片。
一些论文包括:
艺术风格的神经算法,2015。
使用卷积神经网络的图像样式转移,2016。
图像着色
图像着色或神经着色涉及将灰度图像转换为全色图像。
该任务可以被认为是一种可能没有客观评价的照片滤波器或变换。
例子包括着色旧的黑白照片和电影。
数据集通常涉及使用现有的照片数据集并创建模型必须学习着色的照片的灰度版本。
一些论文包括:
彩色图像着色,2016年。
让我们有颜色:全球和本地图像的联合端到端学习,用于同步分类的自动图像着色,2016。
深色着色,2016。
影像重建
图像重建和图像修复是填充图像的缺失或损坏部分的任务。
该任务可以被认为是一种可能没有客观评价的照片滤波器或变换。
示例包括重建旧的,损坏的黑白照片和电影(例如照片恢复)。
数据集通常涉及使用现有的照片数据集并创建模型必须学会修复的损坏版本的照片。
一些论文包括:
像素回归神经网络,2016年。
使用部分卷积的图像修复不规则孔,2018年。
使用具有带通滤波的深度神经网络进行高度可扩展的图像重建,2018年。
图像超分辨率
图像超分辨率是生成具有比原始图像更高分辨率和细节的图像的新版本的任务。
通常为图像超分辨率开发的模型可用于图像恢复和修复,因为它们解决了相关问题。
数据集通常涉及使用现有的照片数据集并创建缩小版照片,模型必须学会创建超分辨率版本。
一些论文包括:
使用生成对抗网络的照片真实单图像超分辨率,2017。
深拉普拉斯金字塔网络,快速准确的超分辨率,2017。
Deep Image Prior,2017。
图像合成
图像合成是生成现有图像或全新图像的目标修改的任务。
这是一个非常广泛的领域,正在迅速发展。
它可能包括图像和视频的小修改(例如图像到图像的翻译),例如:
更改场景中对象的样式。
将对象添加到场景中。
将面添加到场景中。
它还可能包括生成全新的图像,例如:
1、生成面孔。
2、生成浴室。
3、生成衣服。
一些论文包括:
用深度卷积生成对抗网络学习无监督表示,2015。
使用PixelCNN解码器生成条件图像,2016。
使用周期一致的对抗网络进行不成对的图像到图像转换,2017。
其他问题
还有其他重要且有趣的问题我没有涉及,因为它们不是纯粹的计算机视觉任务。
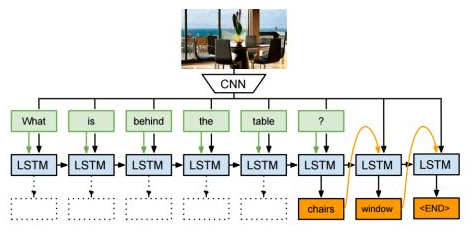
值得注意的例子是图像到文本和文本到图像:
1、图像字幕:生成图像的文本描述。
Show and Tell:神经图像标题生成器,2014。
2、图像描述:生成图像中每个对象的文本描述。
用于生成图像描述的深层视觉语义对齐,2015。
3、文本到图像:基于文本描述合成图像。
AttnGAN:使用注意生成对抗网络生成细粒度文本到图像,2017。
据推测,人们学会在其他模态和图像之间进行映射,例如音频。
总结
在这篇文章中,您发现了九种深度学习应用于计算机视觉任务。
编辑:黄飞

















 工商网监
工商网监
评论