 电子发烧友App
电子发烧友App


本文中,我们将研究扩散模型的理论基础,然后演示如何在PyTorch中使用扩散模型生成图像。 扩散模型的迅速崛起是机器学习在过去几年中最大的发展之一。在这篇文章中,你能了解到关于扩散模型的一切。
扩散模型是生成模型,在过去的几年里已经获得了显著的普及。仅在21世纪20年代发表的几篇开创性论文就向世界展示了扩散模型的能力,比如在图像合成方面击败GANs。以及DALL-E 2,OpenAI的图像生成模型的发布。
鉴于扩散模型最近的成功浪潮,许多机器学习从业者肯定对它们的内部工作原理感兴趣。在本文中,我们将研究扩散模型的理论基础,然后演示如何在PyTorch中使用扩散模型生成图像。
介绍
扩散模型是生成模型,这意味着它们用于生成与训练数据相似的数据。从根本上讲,扩散模型的工作原理是通过连续添加高斯噪声破坏训练数据,然后通过学习反转这个噪声过程来恢复数据。训练后,我们可以使用扩散模型通过简单地通过学习的去噪过程传递随机采样的噪声来生成数据。
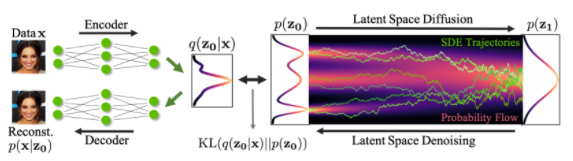
更具体地说,扩散模型是一种潜变量模型,它使用固定的马尔可夫链映射到潜在空间。该链逐步向数据中添加噪声,以获得近似后验值,其中为与x0具有相同维数的潜变量。在下面的图中,我们可以看到这样一个马尔可夫链。

最后,图像逐渐变为纯高斯噪声。训练扩散模型的目标是学习逆向过程,即训练。通过沿着这条链向后遍历,我们可以生成新的数据。
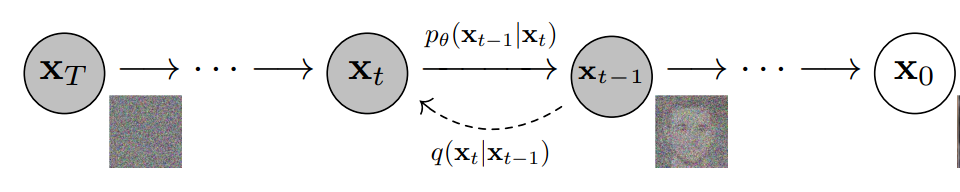
扩散模型的优点
如上所述,对扩散模型的研究近年来呈爆炸式增长。受非平衡热力学的启发,扩散模型目前可以生成State-of-the-Art 的图像质量。
除了顶尖的图像质量,扩散模型还带来了许多其他好处,包括不需要对抗性训练。对抗训练的困难是有据可查的。在训练效率的话题上,扩散模型还具有可伸缩性和并行性的额外好处。
虽然扩散模型似乎是凭空产生的结果,但有很多仔细和有趣的数学选择和细节为这些结果提供了基础,并且最佳实践仍在文献中不断发展。现在让我们更详细地看看支撑扩散模型的数学理论。
扩散模型——深入
如上所述,扩散模型由正向过程(或扩散过程)和反向过程(或反向扩散过程)组成,前者是对数据(通常是图像)进行逐步噪声化,后者是将噪声从目标分布转化回样本。
当噪声水平足够低时,正向过程中的采样链转换可以设置为条件高斯。将这与马尔可夫假设结合起来,就得到了正向过程的简单参数化:
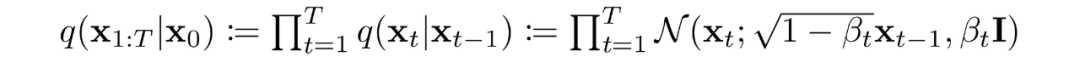
是一个方差策略(学习的或固定的),如果表现良好,确保对于足够大的T,几乎是一个各向同性的高斯噪声。

在马尔可夫假设下,潜变量的联合分布是高斯条件链变换的乘积
如前所述,扩散模型的“魔力”来自于反向过程。在训练过程中,模型学习这个扩散过程的反转,以生成新的数据。从纯高斯噪声开始,模型学习联合分布为:
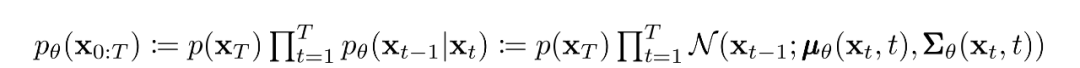
其中高斯变换的随时间变化的参数被学习到。特别要注意的是,马尔可夫公式断言,给定的反向扩散变换分布只依赖于前一个时间步(或下一个时间步,取决于你如何看待它):
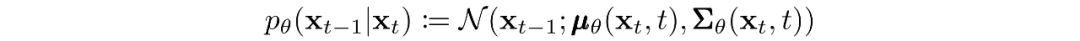
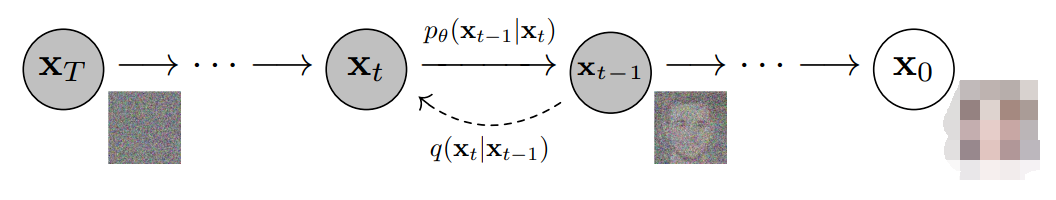
训练
扩散模型通过寻找反向马尔可夫变换来训练,使训练数据的似然性最大化。在实践中,训练等价于最小化负对数似然的变分上界。
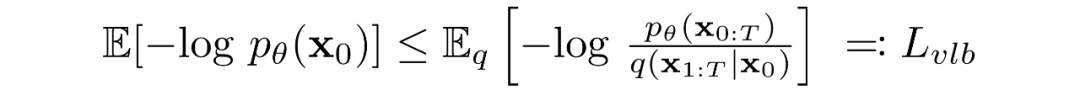
我们试图根据 Kullback-Leibler (KL) Divergences 重写。KL 散度是一种不对称统计距离度量,衡量一个概率分布 P 与参考分布 Q 的差异程度。我们感兴趣的是根据 KL 散度来重写,因为我们的马尔可夫链中的过渡分布是高斯分布,并且高斯分布之间的 KL散度具有封闭形式。
什么是KL散度?
连续分布的KL散度的数学形式:
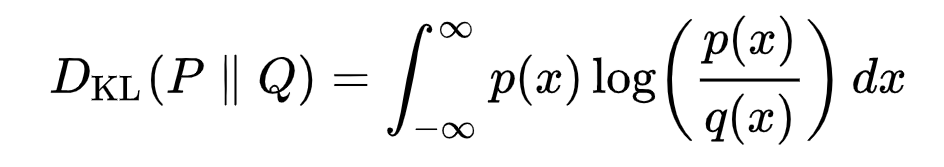
双杠表示该函数关于其参数不对称
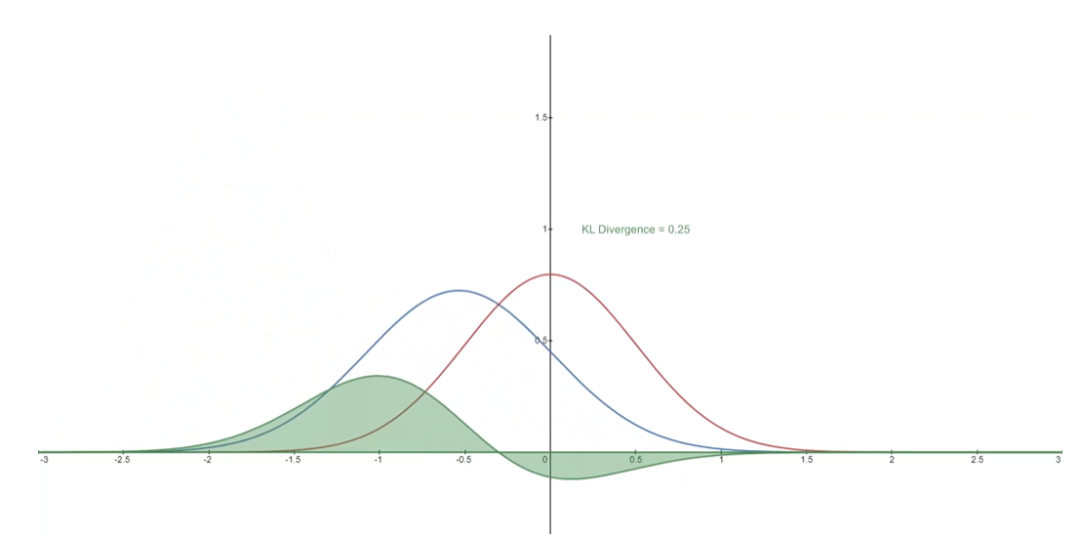
下面你可以看到分布 P(蓝色)与参考分布 Q(红色)的 KL 散度的变化。绿色曲线表示上述KL散度定义中积分内的函数,曲线下的总面积表示任意给定时刻P与Q的KL散度值。
将转换为KL散度的形式
如上所述,可以将重写成KL散度的形式:
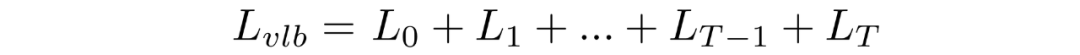
其中
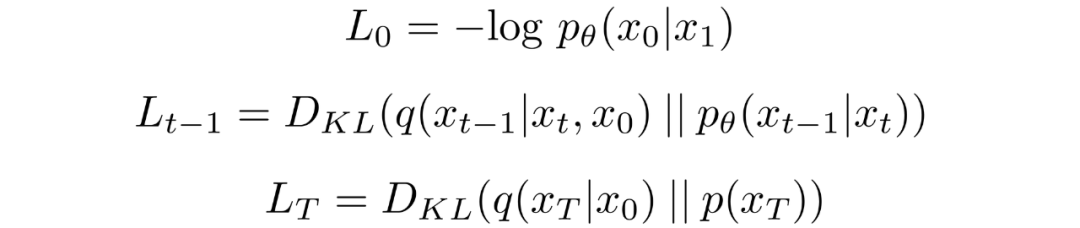
对中的后验的前向过程进行条件化会导致易于处理的形式,从而导致所有 KL 散度都是高斯分布之间的比较。这意味着可以使用封闭式表达式而不是蒙特卡罗估计来精确计算。
模型选择
建立了目标函数的数学基础后,我们现在需要就如何实施扩散模型做出几个选择。对于前向过程,唯一需要的是定义方差策略,其值在前向过程中通常会增加。
对于逆向过程,我们多选择高斯分布参数化/模型架构。请注意扩散模型提供的高度灵活性——我们架构的唯一要求是其输入和输出具有相同的维度。
我们将在下面更详细地探讨这些选择的细节。
前向过程和
如上所述,关于前向过程,我们必须定义方差策略。特别是,我们将它们设置为依赖时间的常数,而忽略了它们可以学习的事实。例如,从到可能使用线性策略,或者可能使用几何级数。
不管选择的特定值如何,方差策略是固定的这一事实导致了相对于我们的可学习参数集成为了一个常数,允许我们就训练而言忽略它。
反向过程和
现在我们讨论定义反向向过程所需的东西。回想一下,我们将逆马尔可夫转换定义为高斯:
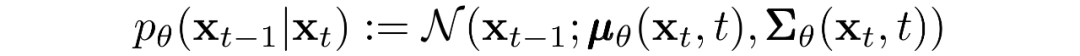
我们现在必须定义 或的函数形式。虽然有更复杂的方法来参数化,我们只需设置:
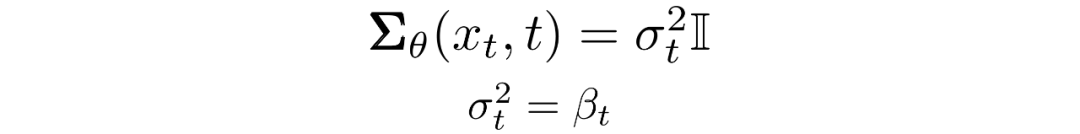
也就是说,我们假设多元高斯分布是具有相同方差的独立高斯分布的乘积,方差值可以随时间变化。我们将这些方差设置为我们的前向过程中的方差策略中的值。
给定了新的的形式,我们有:
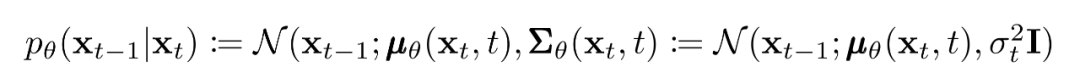
这就允许我们进行变换,将:
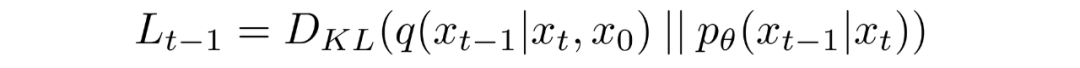
变换为:
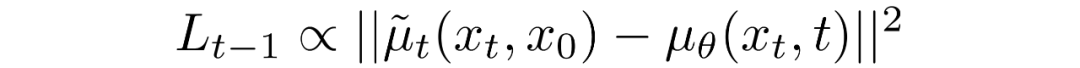
其中差分中的第一项是和的线性组合,它取决于方差策略。此函数的确切形式与我们的目的无关。
上述比例的意义在于最直接的对进行参数化,直接预测扩散的后验均值。重要的是,有学者发现训练来预测噪声,在任何给定时间步长的下都会产生更好的结果。特别地,让
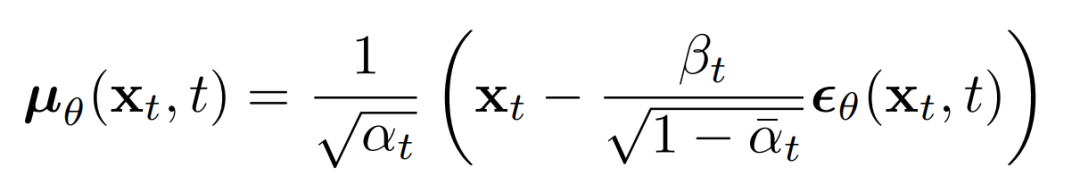
这里:
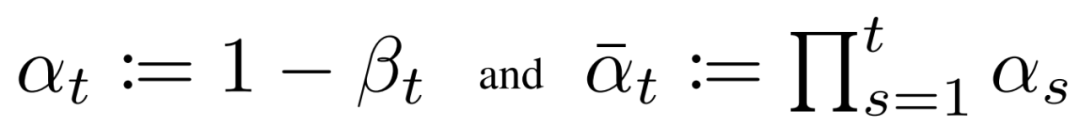
这可以导出下面的替代损失函数,有学者发现可以带来更稳定的训练和更好的结果:
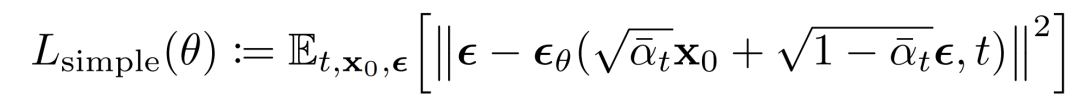
img
该学者还注意到这种扩散模型公式与得分匹配生成模型在基于Langevin 动力学的模型上的联系 。事实上,扩散模型和基于分数的模型似乎是同一枚硬币的两面,类似于基于波的量子力学和基于矩阵的量子力学的独立和同时发展,揭示了同一现象的两个等价公式。
网络结构
虽然我们的简化损失函数旨在训练模型,但我们仍未定义该模型的架构。请注意,模型的唯一要求是其输入和输出维度相同。
鉴于此限制,图像扩散模型通常使用类似 U-Net 的架构来实现。
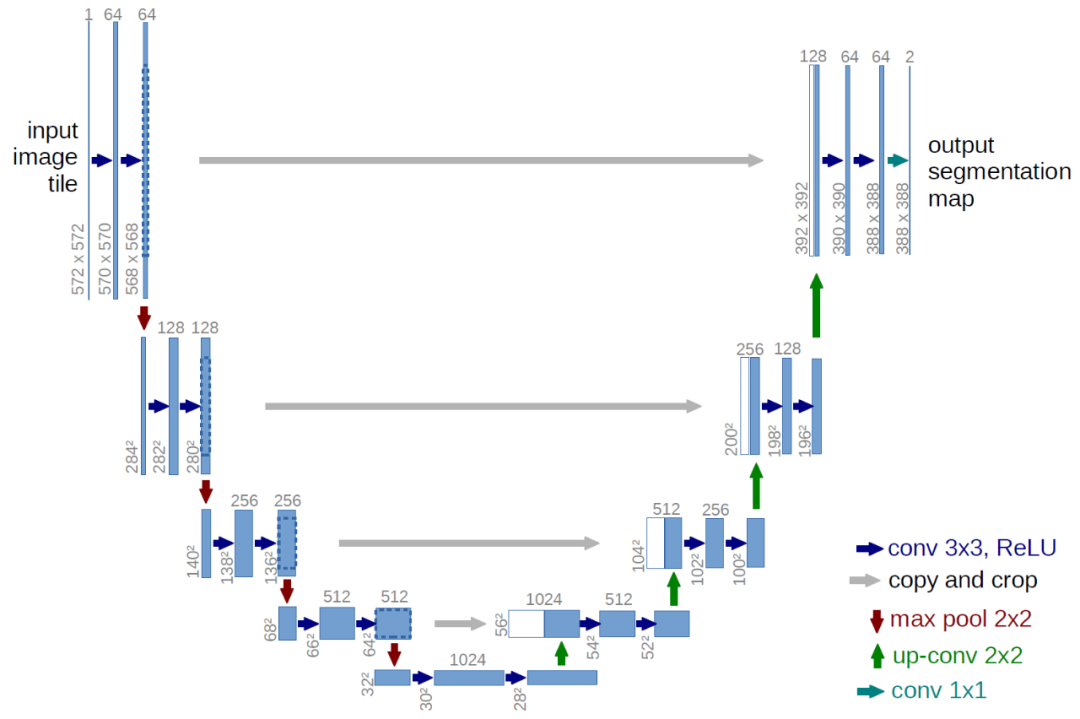
反向过程解码和
反向过程的路径由连续条件高斯分布下的许多变换组成。在反向过程结束时,回想一下我们正在尝试生成一个图像,它由整数像素值组成。因此,我们必须设计一种方法来获得所有像素中每个可能像素值的离散(对数)似然。
这样做的方法是将反向扩散链中的最后一个转换设置为独立的离散解码器。为了确定给定生成图像的可能性,我们首先在数据维度之间施加独立性:

其中D为数据的维数,上标i表示取一个坐标。现在的目标是在时刻t=1时,一个给定的像素的概率分布和轻微噪声图中的对应像素的相似程度:
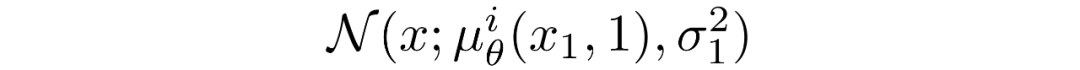
其中t=1 的像素分布源自下面的多元高斯分布,其对角协方差矩阵允许我们将分布拆分为单变量高斯分布的乘积,每个高斯分布对应数据的每个维度:
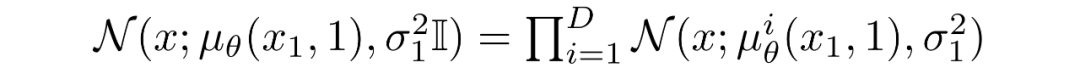
我们假设图像由 0,1,...,255(作为标准 RGB 图像)中的整数组成,这些整数已线性缩放到 [−1,1]。其中,对于给定的像素值 x,该像素值的连续变化范围是 [x−1/255,x+1/255]。给定中相应像素的单变量高斯分布,像素值 x 的概率是以 x为中心的 [x−1/255,x+1/255]范围内的单变量高斯分布下的面积区域。
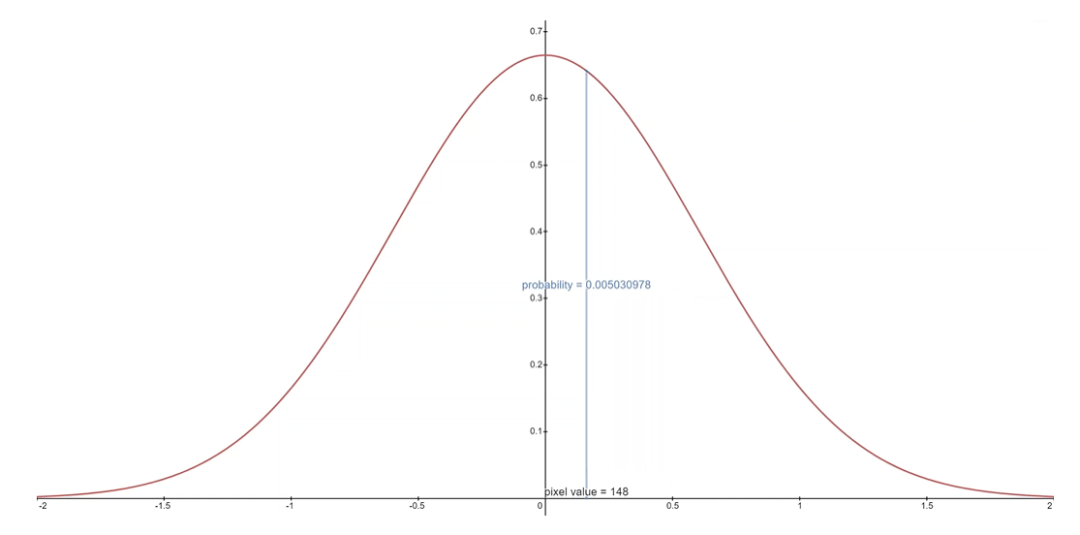
下面你可以看到每个范围中的面积及其均值为 0 高斯的概率,在这种情况下,对应于平均像素值为 255/2(半亮度)的分布。
对于每个像素,给定t=0时刻的像素值,就是简单的相乘就可以,这个过程可以用下面的式子表示:
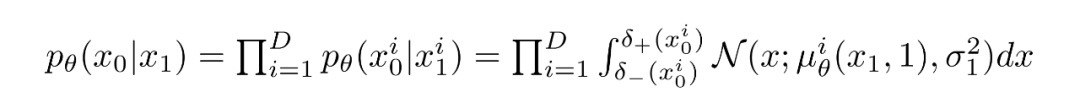
其中
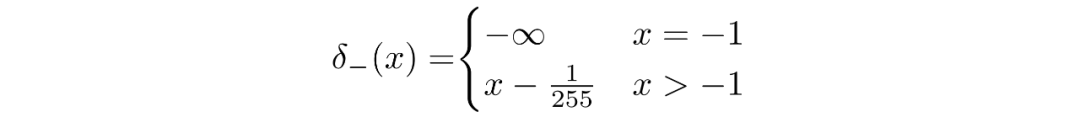
并且
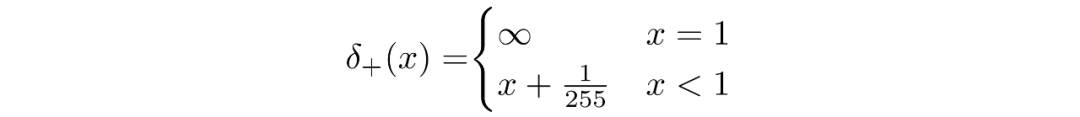
给定了的等式,我们可以计算出最终的的形式,并不是和KL散度一样的形式:
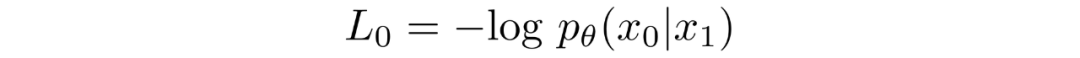
最终目标
如上一节所述,作者发现预测给定时间步长的图像产生了最好的结果。最终,他们使用以下目标:
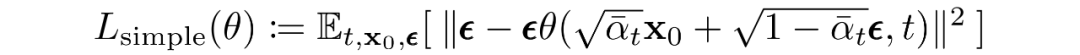
我们的扩散模型的训练和采样算法可见下图:

扩散模型总结
在本节中,我们详细探讨了扩散模型的理论。人们很容易陷入数学细节,因此我们在下面记录了最重要的要点,以便让我们从总体的角度来定位:
我们的扩散模型被参数化为马尔可夫链,这意味着我们的潜变量仅取决于之前(或之后)的时间步长。
马尔可夫链中的变换分布是高斯的,正向过程需要方差策略,逆向过程的参数是学习的。
扩散过程确保对于足够大的 T,渐近分布为各向同性高斯分布。
在我们的案例中,方差策略是固定的,但它也可以学习。对于固定策略,遵循几何级数可能比线性级数提供更好的结果。在任一情况下,序列中的方差通常随时间增加。
扩散模型高度灵活,允许使用输入和输出维度相同的任何架构。许多实现使用 U-Net-like架构。
训练目标是最大化训练数据的似然。这表现为调整模型参数以最小化数据负对数似然的变分上限。
由于我们的马尔可夫假设,目标函数中的几乎所有项都可以转换为 KL 散度。鉴于我们使用的是高斯分布,这些值变得可以计算,因此无需执行蒙特卡罗近似。
最终,使用简化的训练目标来训练预测给定潜变量的噪声分量的函数会产生最佳和最稳定的结果。
作为反向扩散过程的最后一步,离散解码器用于获取像素值的对数似然。
有了这个扩散模型的高级概述,让我们继续看看如何在 PyTorch 中使用扩散模型。
PyTorch中的扩散模型
虽然扩散模型还没有像机器学习中其他结构/方法那样有很多人的实现,但仍有可用的实现。在 PyTorch 中使用扩散模型的最简单方法是使用denoising-diffusion-pytorch包,它实现了本文中讨论的图像扩散模型。要安装软件包,只需在终端中键入以下命令:
pip install denoising_diffusion_pytorch
Minimal Example
为了训练模型生成图像,我们首先导入必要的包:
import torch from denoising_diffusion_pytorch import Unet, GaussianDiffusion
然后,我们定义网络结构,这里用U-Net,参数中的dim表示第一次下采样之前的特征图的数量,dim_mults参数提了每次下采样时,通道数的乘数。
model = Unet( dim = 64, dim_mults = (1, 2, 4, 8) )现在,网络结构定义好了,我们需要定义扩散模型本身,我们将U-Net模型作为参数输入到扩散模型中,还有其他几个参数,生成的图像的尺寸,扩散过程的步数,选择L1还是L2归一化。
diffusion = GaussianDiffusion( model, image_size = 128, timesteps = 1000, # number of steps loss_type = 'l1' # L1 or L2 )
现在,扩散模型定义好了,我们通过生成随机数据来训练,然后使用常用的流程来训练:
training_images = torch.randn(8, 3, 128, 128) loss = diffusion(training_images) loss.backward()
模型训练完成后,我们最终可以使用 diffusion 对象的 sample() 方法生成图像。这里我们生成 4 张图像,由于我们的训练数据是随机的,我们也只能得到噪声:
sampled_images = diffusion.sample(batch_size = 4)
在自定义数据集上训练
denoising-diffusion-pytorch 包还允许你在特定数据集上训练扩散模型。只需将下面的 Trainer() 对象中的 path/to/your/images 字符串替换为数据集目录路径,并将 image_size更改为适当的值。之后,只需运行代码来训练模型,然后像以前一样进行采样。请注意,PyTorch 必须在启用 CUDA 的情况下编译才能使用 Trainer 类:
from denoising_diffusion_pytorch import Unet, GaussianDiffusion, Trainer model = Unet( dim = 64, dim_mults = (1, 2, 4, 8) ).cuda() diffusion = GaussianDiffusion( model, image_size = 128, timesteps = 1000, # number of steps loss_type = 'l1' # L1 or L2 ).cuda() trainer = Trainer( diffusion, 'path/to/your/images', train_batch_size = 32, train_lr = 2e-5, train_num_steps = 700000, # total training steps gradient_accumulate_every = 2, # gradient accumulation steps ema_decay = 0.995, # exponential moving average decay amp = True # turn on mixed precision ) trainer.train()
下面你可以看到从多元高斯噪声到MNIST数字的渐进去噪,类似于反向扩散:

审核编辑:黄飞





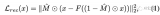
















 工商网监
工商网监
评论