 电子发烧友App
电子发烧友App


随着摩尔定律的放缓,在相同的技术工艺节点上开发能够提升芯片性能的其他技术变得越来越重要。在这项研究中,英伟达使用深度强化学习方法设计尺寸更小、速度更快和更加高效的算术电路,从而为芯片提供更高的性能。
大量的算术电路阵列为英伟达GPU提供了动力,以实现前所未有的AI、高性能计算和计算机图形加速。因此,改进这些算术电路的设计对于提升 GPU 性能和效率而言至关重要。
如果AI学习设计这些电路会怎么样呢?在近期英伟达的论文《PrefixRL: Optimization of Parallel Prefix Circuits using Deep Reinforcement Learning》中,研究者证明了AI不仅可以从头开始设计这些电路,而且AI设计的电路比最先进电子设计自动化(EDA)工具设计的电路更小、更快。

论文地址:https://arxiv.org/pdf/2205.07000.pdf
最新的英伟达Hopper GPU架构中拥有近13000个AI设计的电路实例。下图1左PrefixRL AI设计的64b加法器电路比图1右最先进EDA工具设计的电路小25%。

电路设计概览
计算机芯片中的算术电路是由逻辑门网络(如NAND、NOR和XOR)和电线构成。理想的电路应具有以下属性:
小:更小的面积,更多电路可以封装在芯片上;
快:更低的延迟,提高芯片的性能;
更低功耗。
在英伟达的这项研究中,研究者关注电路面积和延迟。他们发现,功耗与感兴趣电路的面积密切相关。电路面积和延迟往往是相互竞争的属性,因此希望找到有效权衡这些属性的设计的帕累托边界。简言之,研究者希望每次延迟时电路面积是最小的。
因此,在PrefixRL中,研究者专注于一类流行的算术电路——并行前缀电路。GPU中的各种重要电路如加速器、增量器和编码器等都是前缀电路,它们可以在更高级别上被定为为前缀图。
那么问题来了:AI智能体能设计出好的前缀图吗?所有前缀图的状态空间是很大的O(2^n^n),无法使用蛮力方法进行探索。下图2为具有4b电路实例的PrefixRL的一次迭代。
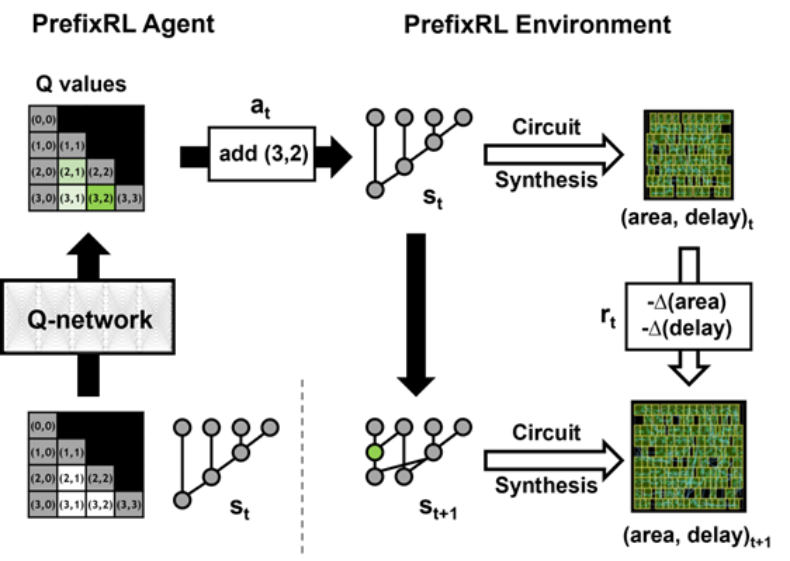
研究者使用电路生成器将前缀图转换为一个带有电线和逻辑门的电路。接下来,这些生成的电路通过一个物理综合工具来优化,该工具使用门尺寸、复制和缓冲器插入等物理综合优化。
由于这些物理综合优化,最终的电路属性(延迟、面积和功率)不会直接从原始前缀图属性(如电平和节点数)转换而来。这就是为什么AI智能体学习设计前缀图但又要对从前缀图中生成的最终电路的属性进行优化。 研究者将算术电路设计视为一项强化学习(RL)任务,其中训练一个智能体优化算术电路的面积和延迟属性。对于前缀电路,他们设计了一个环境,其中RL智能体可以添加或删除前缀图中的节点,然后执行如下步骤:
前缀图被规范化以始终保持正确的前缀和计算;
从规范化的前缀图中生成电路;
使用物理综合工具对电路进行物理综合优化;
测量电路的面积和延迟特性。
在如下动图中,RL智能体通过添加或删除节点来一步步地构建前缀图。在每一步上,该智能体得到的奖励是对应电路面积和延迟的改进。

原图为可交互版本
完全卷积Q学习智能体
研究者采用Q学习(Q-learning)算法来训练智能体电路设计。如下图3所示,他们将前缀图分解成网格表示,其中网格中的每个元素唯一地映射到前缀节点。这种网格表示用于Q网络的输入和输出。输入网格中的每个元素表示节点是否存在。输出网格中的每个元素代表添加或删除节点的Q值。
研究者采用完全卷积神经网络架构,因为Q学习智能体的输入和输出都是网格表示。智能体分别预测面积和延迟属性的Q值,因为面积和延迟的奖励在训练期间是单独可观察的。
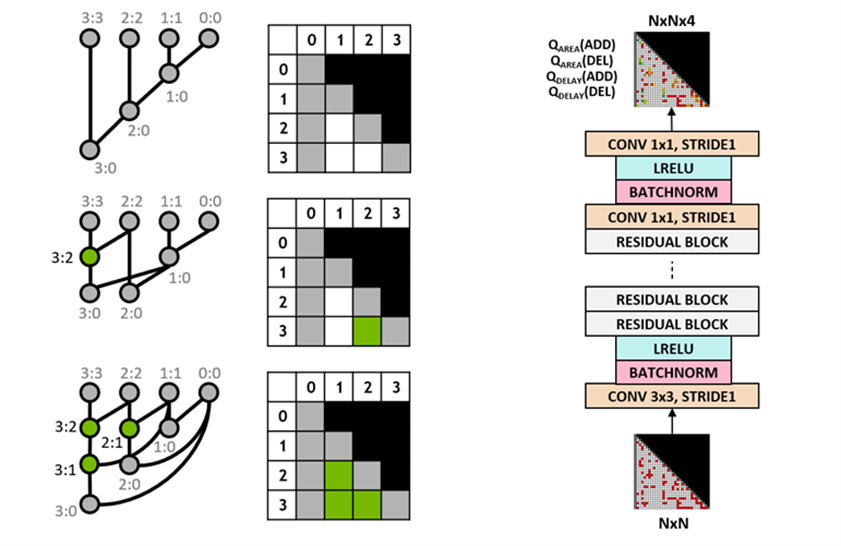
图3:4b前缀图表示(左)以及完全卷积Q学习智能体架构(右)。
Raptor进行分布式训练
PrefixRL需要大量计算,在物理模拟中,每个GPU需要256个CPU,而训练64b任务则需要超过32000个GPU小时。此次英伟达开发了一个内分布式强化学习平台Raptor,该平台充分利用了英伟达硬件优势,从而可以进行这种工业级别的强化学习(如下图4)。
Raptor能够提高训练模型的可扩展性和训练速度,例如作业调度、自定义网络和GPU感知数据结构。在PrefixRL的上下文中,Raptor使得跨CPU、GPU和Spot实例的混合分配成为可能。
这个强化学习应用程序中的网络是多种多样的,并且受益于以下几点:
Raptor在NCCL之间切换以进行点对点传输,从而将模型参数直接从学习器GPU传输到推理GPU;
Redis 用于异步和较小的消息,例如奖励或统计信息;
对于JIT编译的RPC,用于处理大容量和低延迟的请求,例如上传经验数据。
最后,Raptor提供了GPU感知数据结构,例如具有多线程服务的重放缓冲器,以接收来自多个worker的经验,并行批处理数据并将其预先载入到GPU上。
下图4显示PrefixRL框架支持并发训练和数据收集,并利用NCCL有效地向参与者(下图中的actor)发送最新参数。
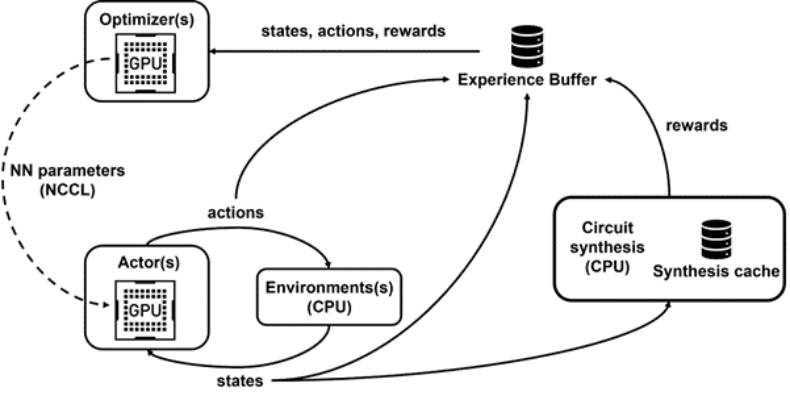
图4:研究者采用Raptor进行解耦并行训练和奖励计算,以克服电路合成延迟。
奖励计算
研究者采用权衡权重w (范围为[0,1])来组合区域和延迟目标。他们训练具有不同权重的各种智能体以获得帕累托边界,从而平衡面积、延迟之间的权衡。
RL环境中的物理综合优化可以生成各种解决方案来权衡面积和延迟。研究者使用与训练特定智能体相同的权衡权重来驱动物理综合工具。
在奖励计算的循环中执行物理综合优化具有以下优点:
RL智能体学习直接优化目标技术节点和库的最终电路属性;
RL智能体在物理综合过程中包含目标算法电路的周边逻辑,从而共同优化目标算法电路及其周边逻辑的性能。
然而,进行物理综合是一个缓慢的过程(64b加法器~35秒),这可能大大减慢RL的训练和探索。
研究者将奖励计算与状态更新解耦,因为智能体只需要当前的前缀图状态就可以采取行动,而不需要电路合成或之前的奖励。得益于Raptor,他们可以将冗长的奖励计算转移到CPU worker池中并行执行物理综合,而actor智能体无需等待就能在环境中执行。
当CPU worker返回奖励时,转换就可以嵌入重放缓冲器。综合奖励会被缓存,以避免再次遇到某个状态时进行冗余计算。
结果及展望
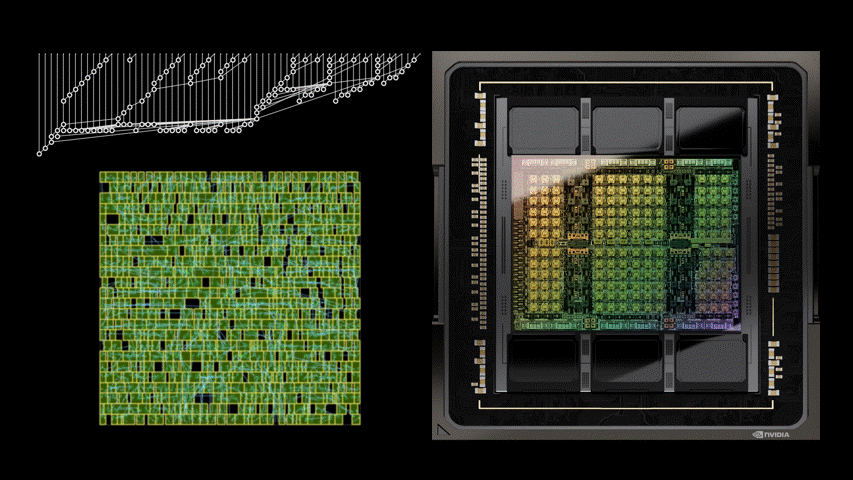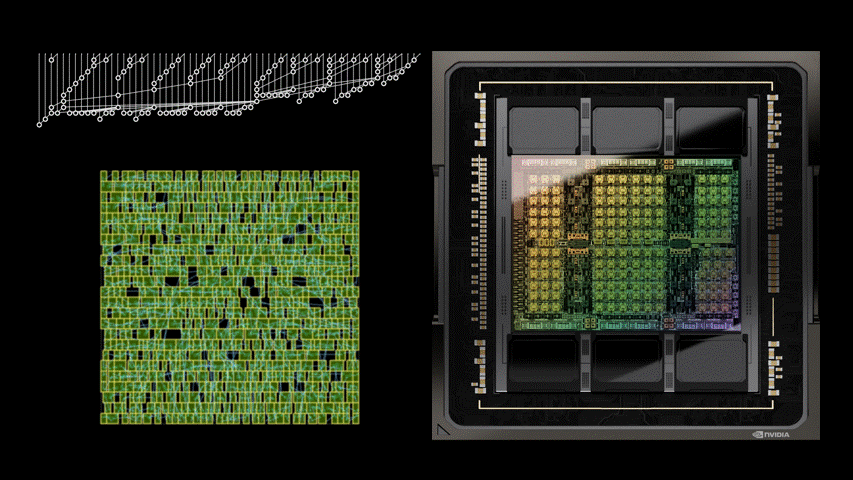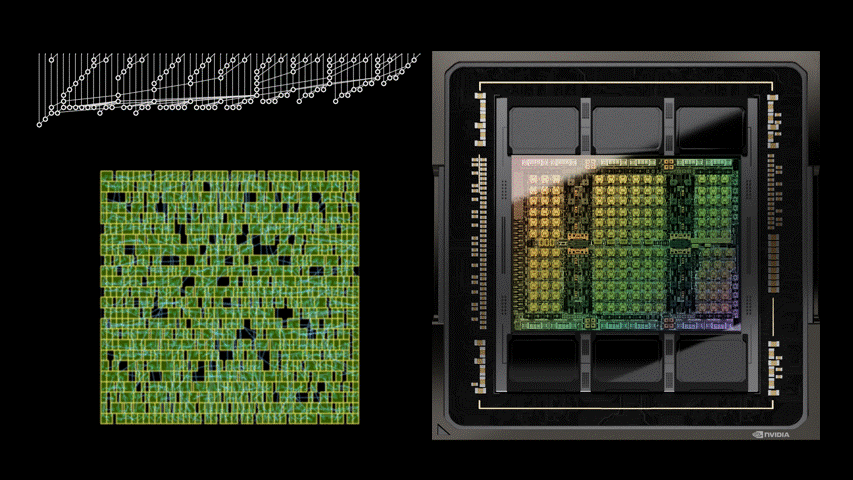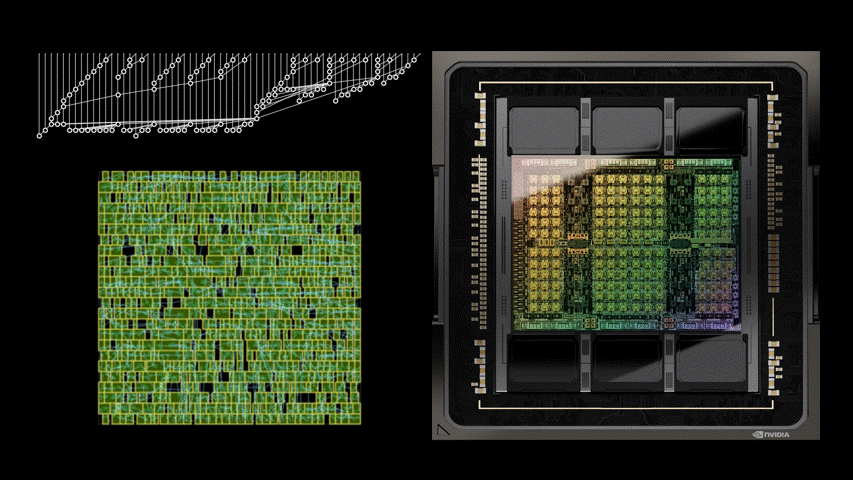
下图5展示了使用PrefixRL设计的64b加法器电路、以及来自最先进EDA工具的帕累托支配加法器电路的面积和延迟情况。
最好的PrefixRL加法器在相同延迟下实现的面积比EDA工具加法器低25%。这些在物理综合优化后映射到Pareto最优加法器电路的前缀图具有不规则的结构。
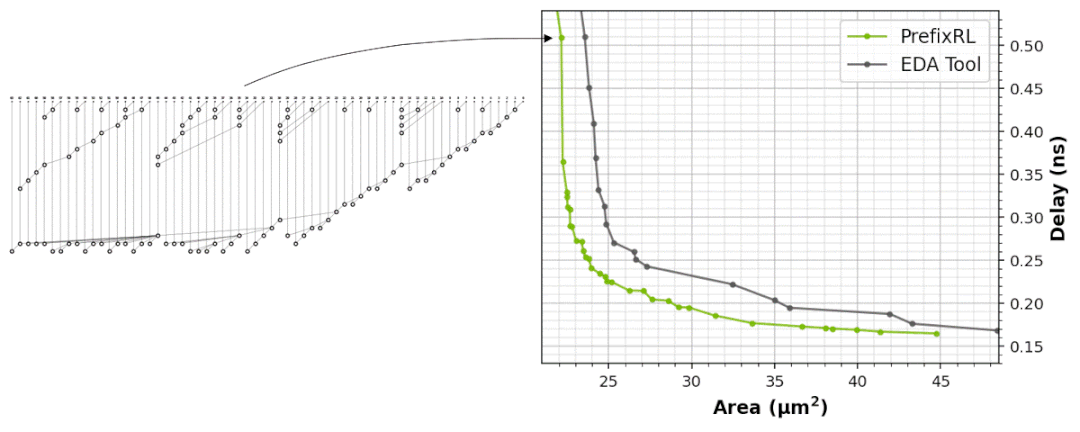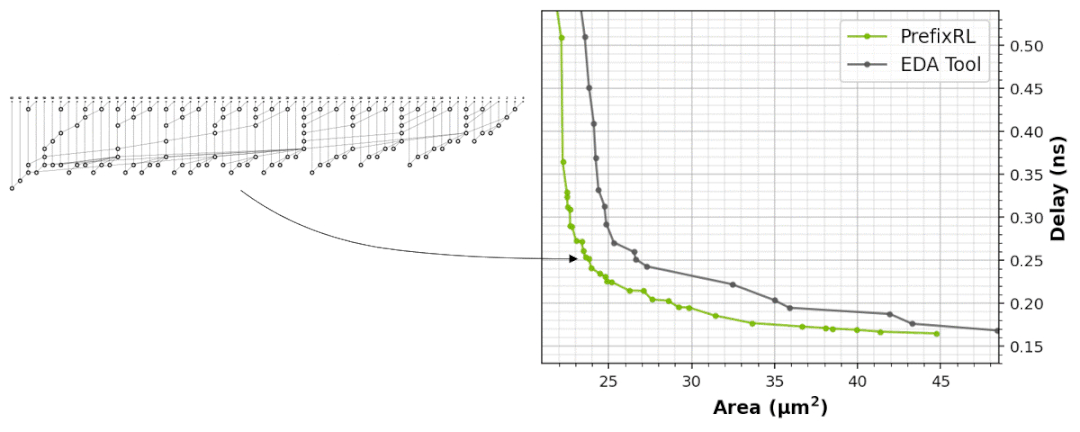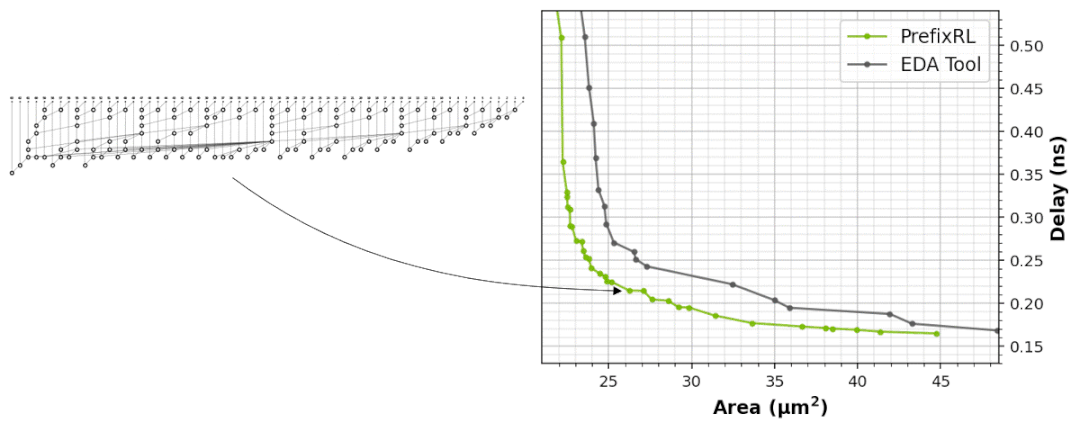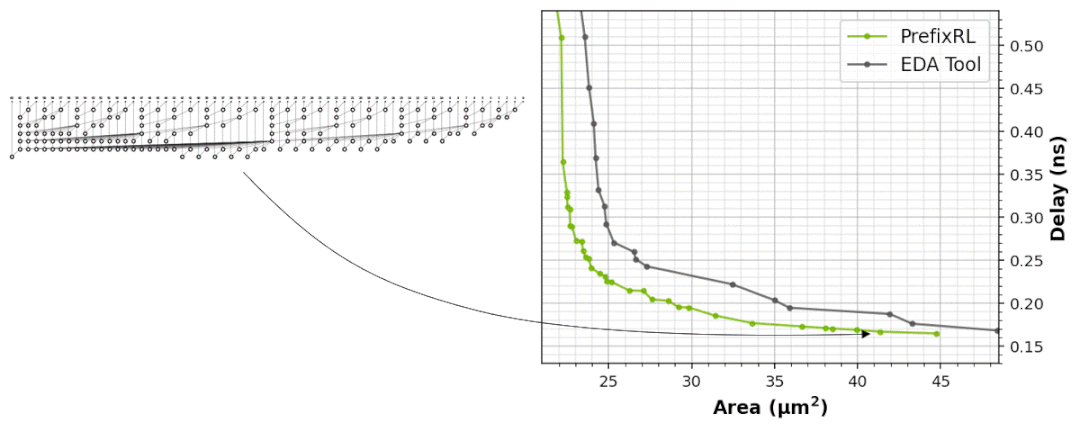
图5:PrefixRL设计的算术电路比最先进的EDA工具设计的电路更小和更快。(左)电路架构;(右)对应的64b加法器电路特性图
据了解,这是首个使用深度强化学习智能体来设计算术电路的方法。英伟达构想了一种蓝图:希望这种方法可以将AI应用于现实世界电路设计问题,构建动作空间、状态表示、RL 智能体模型、针对多个竞争目标进行优化,以及克服缓慢的奖励计算过程。
审核编辑:黄飞



























 工商网监
工商网监
评论