 电子发烧友App
电子发烧友App


多年前,谷歌(Google)凭借AlphaGo的惊艳表现在全球掀起了一波人工智能(AI)浪潮。但近一年来在OpenAI ChatGPT所引发的AI新浪潮中,谷歌被压着打了一年,急需一款现象级的AI产品来证明自己的实力。
自 ChatGPT 发布以来,人们一直对谷歌声称的竞品 Gemini 模型的能力非常好奇,这款大模型早在今年 3 月就有了风声,5 月的 I/O 大会上进入“即将推出”的状态。
但在11月时曾有(假)消息称,谷歌的大模型发布时间被推迟到了2024年1月,原因是“发现该AI模型不能可靠地处理一些非英语查询”, 而对多种语言的支持对Gemini的全球成功至关重要。
虚晃一枪,还是发布了
12月7日凌晨,谷歌终于发布了自家“原生多模态”(natively multimodal)大模型Gemini。谷歌 CEO 桑达尔・皮查伊(Sundar Pichai)官宣 Gemini 1.0 版正式上线,并表示这是“谷歌迄今为止最大、能力最强的AI模型”。
这样看来,谷歌是懂放烟幕弹和玩惊喜的。Sundar Pichai在Gemini的官宣博客中写道:
“在许多领先的基准测试中都具有最先进的性能。谷歌的第一个版本 Gemini 1.0 针对不同尺寸进行了优化:Ultra、Pro 和 Nano。这些是 Gemini 时代的第一个模型,也是谷歌今年早些时候成立 Google DeepMind 时的愿景的首次实现。这个模型的新时代代表了谷歌作为一家公司所做出的最大的科学和工程努力之一。我对未来以及双子座将为世界各地的人们带来的机会感到由衷地兴奋。”
Gemini和ChatGPT有什么不同
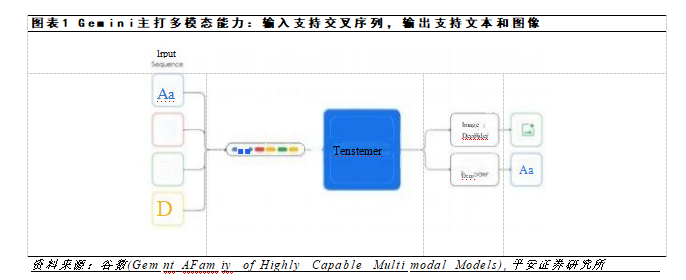
所谓多模态大模型,就是和市面上现有大模型相比,可以归纳并流畅地理解、操作以及组合不同类型的信息,包括文本、代码、音频、图像和视频。在灵活度上,从数据中心到移动设备上,它都能够运行,而不需要额外的专门处理或转换。
如果要问Gemini和GPT-4有什么不同,可以将GPT-4比作一个诗人,他不仅擅长写诗,还会画画,但写诗是他的职业,画画只是他的副业。GPT-4能处理文字(写诗)和图片(画画),但它主要还是以文字处理为强项。
而具有“原生多模态能力”的Gemini则是一个诗人、画家“双料人才”,他在写诗和画画方面同样出色,没有哪一方面比另一方面弱。Gemini能够同时处理文字和图片,并且在这两个方面都做得很好,没有主次之分。
在Gemini发布之前,谷歌在生成式AI和大语言模型(LLM)方面主推的两款模型PaLM 2和LaMDA,在用户当中收获的评价一直不高,相对于业界领军的GPT-4差距很大。
而这次对于Gemini,谷歌的评价是:“比市面上所有人工智能系统都更强大,连ChatGPT创造者OpenAI开发的技术都要甘拜下风。”
据悉,Gemini也是谷歌大脑(Google Brain)和DeepMind合并组建Google DeepMind之后的首个重要产品。有了AlphaGo战胜人类围棋世界冠军的先例,人们已经不把AI在某些领域超越人类当成是新鲜事了,但在ChatGPT带来的AGI、强人工智能“威慑”下,任何被称为超越人类的AI,多多少少都会引发关注。
首个在MMLU测评上超过人类专家的大模型
MMLU(大规模多任务语言理解)是一个结合了数学、物理、历史、法律、医学和伦理学等57个科目的测试集。相比于其他测试集,MMLU的广泛性和深度更强,它通过大量和多样的任务来测试AI模型在理解自然语言方面的能力,特别是在复杂和多变的真实世界场景中的表现。这使得MMLU成为一个极具挑战性的评测框架,可以全面地评估和推动大型语言模型的发展。

GPT-4与Gemini在MMLU测试集的对比
这个框架通常包括数以千计的不同任务,涵盖广泛的主题和挑战。MMLU 的目的是提供一个全面且多样化的方法,测试和评估语言模型在各种复杂和现实世界场景中的表现。其中的测试任务可能包括理解笑话、回答有关世界历史的问题、解释科学现象等众多更接近于人类知识、常识和理解能力的项目。
Gemini Ultra是首个在MMLU测评上超过人类专家的大模型,取得90.0%的成绩。作为对比,人类专家的成绩为89.8%,GPT-4为86.4%。
谷歌在官方博客中称:Gemini利用MMLU基准方法使Gemini能够利用其推理能力在回答难题之前更仔细地思考,从而比仅使用第一印象有显着改进。
LLM的主流评测数据集包括GLUE、SuperGLUE、SQuAD、CommonsenseQA、CoQA、LAMBADA等。通常用于评估模型在语言理解、推理、阅读理解和常识推理等方面的能力。
Gemini Ultra在LLM研发中使用的32个多模态基准中取得30个SOTA(当前最优效果),几乎全方位超越GPT-4。

在包括文本和编码在内的一系列基准测试中, Gemini 的性能都超过了当前最先进的水平
除此之外,Gemini Ultra 还在新的MMMU(专家 AGI 的大规模多学科多模式理解和推理)基准测试中取得了59.4%的最先进分数,该基准测试由跨越不同领域、需要深思熟虑的推理的多模态任务组成。
测试结果显示,Gemini Ultra 的性能优于之前最先进的模型,无需从图像中提取文本以进行进一步处理的对象字符识别 (OCR) 系统的帮助。这些基准凸显了双子座天生的多模态性,并表明了双子座更复杂推理能力的早期迹象。

Gemini在文本和编码等一系列基准测试中的表现
能帮助码农和学生解决大量问题
据介绍,Gemini经训练后,能展现出更像人类的行事方式。“Gemini可以像我们一样,理解我们周围的世界。”谷歌DeepMind CEO Demis Hassabis表示。
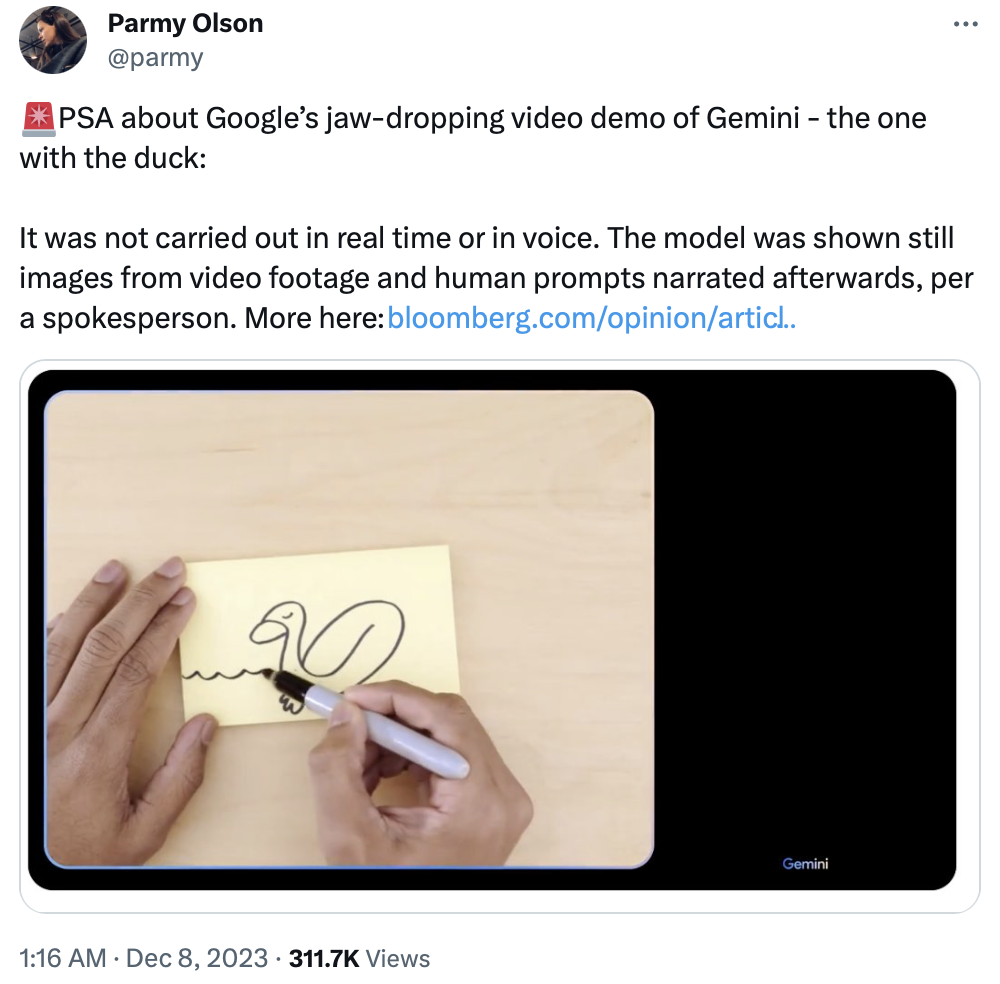
在发布会上的一段演示视频中,一个男子做出后仰并躲避的慢动作,AI马上猜出:这是表演《黑客帝国》中“子弹时间”的场景。
当人类拿起画笔在一张纸上勾勒出一只鸭子,并为它涂上了蓝色。这次AI说道:“这可不是鸭子常见的颜色。”
三个空杯并排放在桌子上,一张蓝色纸团被塞进其中一个杯子里,在人类一番眼花缭乱的操作后,AI准确地猜出:“纸团在最左边的杯子里!”
上传食材图像和语音输入,AI不仅可以指导你做菜,还能在不同阶段提出相应的建议。
在视频演示完后,谷歌 DeepMind产品副总裁Eli Collins表示,“我们离新一代人工智能模型的愿景越来越近了。这是谷歌迄今为止功能最强大、最通用的大模型。”
编程是大模型衡量能力的重要维度,也是很多码农的刚需。Gemini Ultra 在多个编码基准测试中表现出色,包括 HumanEval(用于评估编码任务性能的重要行业标准)和 Natural2Code(谷歌内部数据集),该数据集使用作者生成的源代码而不是基于网络的信息。
两年前,谷歌推出了 AlphaCode,这是第一个在编程竞赛中达到竞争性水平的人工智能代码生成系统。基于Gemini,谷歌本次还推出了更先进的编程系统AlphaCode 2,它能理解、解释并生成 Python、Java、C++ 和 Go 等编程语言的高质量代码。
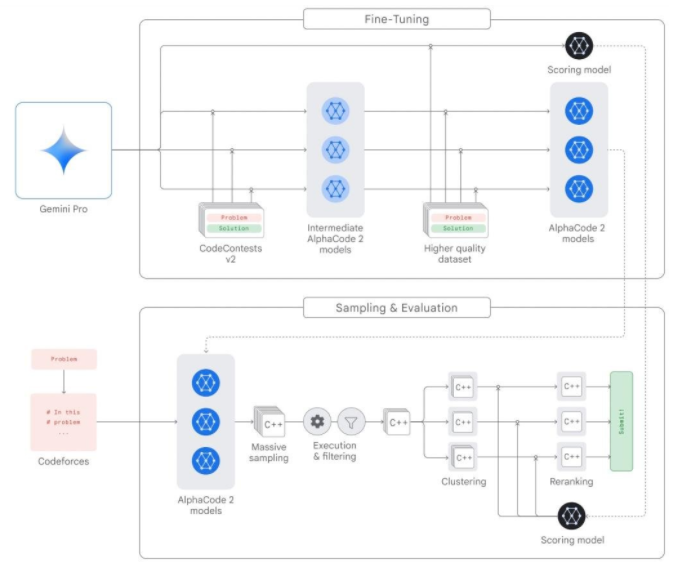
和上一代产品AlphaCode相比,AlphaCode 2解决的问题数量几乎是原来的两倍,其表现优于85%的竞赛参与者,AlphaCode的这一比例接近50%。如果程序员通过为代码示例定义某些属性来与AlphaCode 2协作,它的性能还会更好。
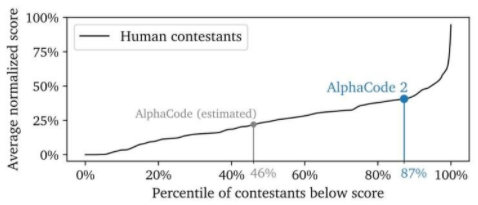
Gemini还擅长解决一些超出编程范围、涉及复杂数学和理论计算机科学的编程竞赛问题。以解题为例,利用Gemini的多模态推理能力,AI能够读懂字迹凌乱的手写内容,正确理解问题的表述,还能够把问题和解决方案都转换为数字排版,识别出人类在解决问题时出错的具体推理步骤,并一步步给出问题的正确解决方案。

例如一位老师画了一个滑雪者从斜坡上下来的物理问题,而一位学生则提出了一个解决方案来计算滑雪者在斜坡底部的速度。利用Gemini的多模态推理能力,该模型能够读懂凌乱的笔迹,正确理解问题的表述,将问题和解决方案都转换为数学公式,识别出学生在解决问题时出错的具体推理步骤,然后给出问题的正确解决方案。
三大版本,各有所长
本次发布包含三个版本:
Ultra是性能最强的模型,适用于高度复杂的任务,在云上运作;
Pro是可扩展各种任务的最佳通用模型;
Nano是针对端侧设备的小模型,比如在手机、家电等各类消费设备上跑。Nano还细分了两种型号尺寸:Nano-1(18 亿参数)和 Nano-2(32.5 亿参数),分别针对低内存和高内存设备。
其中,Gemini Pro和Gemini Nano已分别在聊天机器人Bard和智能手机Pixel 8 Pro上集成,最强大的Gemini Ultra则将在明年发布。届时其Ultra模型将用于推出聊天机械人的强化版“Bard Advanced”,最初仅向测试受众提供。
谷歌表示,他们还要先给客户、开发者、合作伙伴以及安全和责任专家进行早期实验和反馈,预计在2024年初,Ultra版本会先向开发者和企业客户提供服务。
从发布之日起,Bard 将使用 Gemini Pro 的微调版本来执行更高级的推理、规划、理解等。这是 Bard 自推出以来最大的升级,集成Gemini Pro之后,已经在超过170个国家和地区提供英语服务。
谷歌还根据许多行业标准基准,对Pro版本进行了测试。结果显示,在8个基准测试中的6个里,Gemini Pro的表现优于 GPT-3.5。为了展现升级后的Bard有多强,谷歌甚至请了一个油管(Youtube)教育博主Mark Rober,全程使用Bard作为辅助工具,从零开始画图纸,最后真的造出了一架巨大的纸飞机!
虽然能力最弱,但Gemini Nano反倒因为使用前景明确最受关注。根据介绍,Pixel 8 Pro的用户已经可以使用录音app来实现“总结录音内容”的功能,并对WhatsApp等信息服务提供推荐自动回覆文字功能。Pixel 8 Pro 也是为Gemini Nano设计的首款谷歌智能手机,很多功能不用联网,就能直接调用。
在接下来的几个月中,Gemini 将出现在谷歌更多的产品和服务中,例如搜索、广告、Chrome 和 Duet AI。
强大的原因之一:专用 TPU 训练
谷歌表示,Gemini强于竞争对手的原因之一,是其强大的计算能力。
据悉谷歌使用内部设计的张量处理单元 TPUs v4 和 v5e 在AI优化基础设施上对 Gemini 1.0 进行了大规模训练,并将其设计为最可靠、可扩展的训练模型和最高效的服务模型。
在 TPU 上,Gemini 的运行速度明显快于早期规模较小、能力较弱的模型。这些定制设计的 AI 加速器是谷歌人工智能产品的核心,这些产品为搜索、YouTube、Gmail、谷歌地图、Google Play 和 Android 等数十亿用户提供服务。它们还帮助世界各地的公司经济高效地训练大规模人工智能模型。
在训练优化方面,Gemini增加了对模型并行性和数据并行性的利用,并对网络延迟和带宽进行了优化。Gemini还使用了Jax和Pathways编程模型,为复杂的数学运算(如在机器学习中常见的运算)提供了优化的支持。
Jax特别适用于高效地执行大规模的数组运算。Pathways指用于管理和协调大规模训练任务的编程模型或框架。通过使用这些工具,Gemini模型的开发者可以使用单个Python进程来协调整个训练过程,这样可以简化开发和训练工作流,同时利用Jax和Pathways的高效性能。
发布会上,谷歌同时发布了迄今为止最强大、最高效、可扩展的 TPU 系统 —Cloud TPU v5p,称训练速度比前代快2.8倍,专为训练尖端的人工智能模型而设计。新一代 TPU 将加速 Gemini 的发展,帮助开发人员和企业客户更快地训练大规模生成式 AI 模型,让新产品和新功能更快地与客户见面。
竞争者们也没闲着
外媒称,谷歌的Gemini旨在与ChatGPT背后的开发商OpenAI在对话式人工智能领域展开竞争。通过发布Gemini,谷歌不仅希望能与ChatGPT相媲美,还希望能超越它们,提供更无缝、更自然的对话。
虽然这次被cue,OpenAI这边其实一直也没闲着。据 The Information 今年9月报道,OpenAI 正在开发一款名为 Gobi 的多模态大模型,对标的正是谷歌Gemini。不过目前关于这款大模型产品的具体信息尚不确认,OpenAI 原本希望可以在谷歌Gemini发布之前推出,但很明显被“宫斗”耽误了。
另外就在谷歌发布Gemini之前,微软刚刚宣布了旗下AI助手Copilot重大升级,将接入OpenAI的最新模型GPT-4 Turbo。
Gemini的发布掀起了多模态领域的冰山一角,这类领域目前还在技术探索初期,技术路径还未确定。比起大语言模型,多模态模型增加了音频、视频、图片这些数据,训练难度也更大。
但为什么巨头们还要做?据思科的年度互联网报告——视频已经占据互联网超过80%的流量。在视频内容已经称为信息时代主流的时候,单纯只有文字和图片的大模型显然是不够的。
虽然目前看起来, Google Gemini在“跑分”上更胜一筹,但接下来,更重要的是各家大模型在实际应用中的比拼。其中AI安全是最近的热门话题,也是谷歌本次重点强调的。
谷歌基础设施与系统副总裁Amin Vahdat表示,Gemini在开发的各个阶段都会考虑潜在的风险,并努力进行测试和降低这些风险。
他透露,Gemini的安全评估包括偏见和毒性评估,并应用了 Google Research 的对抗性测试技术,帮助在部署 Gemini 之前检测关键的安全问题。
例如,为了在 Gemini 的训练阶段诊断内容安全问题,并确保其输出符合政策,谷歌团队使用了一些基准测试,例如真实毒性提示(Real Toxicity Prompts),这是一套由 Allen Institute of AI 的专家开发的基准测试,包含了从网络上提取的 10 万条具有不同程度毒性的提示。
此外,为了减少伤害,团队还构建了专门的安全分类器来识别、标记和筛选涉及暴力或负面刻板印象等方面的内容。“此外,我们正继续解决模型面临的已知挑战,例如事实性、基础、归因性以及协作性。”
谷歌没有透露未来是否会专门为Gemini定制应用程序,但高管对记者表示,更加希望看到用户在这种技术的基础上创建更多的应用程序。
谷歌透露,从 12 月 13 日开始,开发者和企业客户可以通过 Google AI Studio 或Google Cloud Vertex AI中的 Gemini API 获取 Gemini Pro。
审核编辑:黄飞






















 工商网监
工商网监
评论