 电子发烧友App
电子发烧友App


1
引言
先给大家先算个账:假设我要 GPT4 Turbo 帮我总结一篇 5000 字的文章,生成的总结是 500 个汉字,总共需要多少钱?这是一道数学题。
已知条件是:
一个汉字约等于 2 个 token
OpenAI GPT 4 Turbo 的价格是:输入$0.01/K token,输出$0.03/K token
解答:
总结 5000 字的文章总金额 = 0.01 输入 token 数/1000 + 0.03 输入 token 数/1000 = $0.13,也就是 9 毛钱。
如果按照我每天 10 篇文章的阅读量,每年要 9365 = 3285 元,这个数字对我来说还是太贵了(也许某些媒体机构可能会使用)。
看来要大规模应用 LLM,降低算力成本也是首要任务,这个话题非常广泛,比如:
做模型的人可以思考怎么在模型侧降低预训练成本
以上两者让科学家们去搞,那么做 AI 应用的是不是没有办法呢,也不全是,所以就构成了这篇文章的副标题:
作为 AI 应用开发者,目前以及未来有什么方法降低算力成本?
目前这方面的探讨不多,大家多多指正。按照之前一篇讲大模型 AI 应用架构中提到的四层结构,我认为AI 应用开发人员的降本方式集中在模型的选择和应用层的使用上。
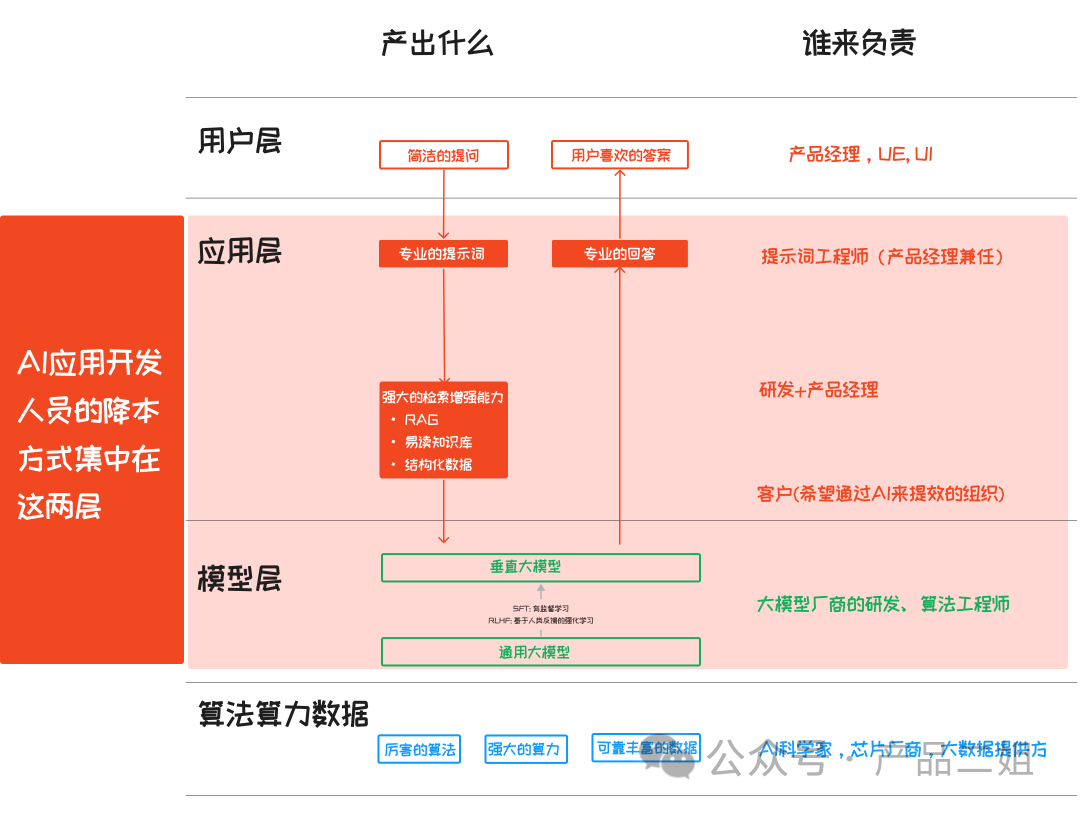
这一篇我们来讲模型层的成本计算,应用层的下一篇来讲。
2
AI 应用降本之“大模型选择”
先说结论:
1.大概率来说,模型的定价和模型参数量、训练数据的 token 量成正比。所以模型参数量越小,训练数据的 token 量越小,成本越低。
2.参数量小,并不意味着模型能力也会低。评估小模型是否适用于你的场景,一看机构评测,二看垂直度,三亲手实验。
3.训练数据的 token 量越小,也并不意味着模型能力低。训练数据的质量比数量更重要,使用时要考察数据质量和数据垂直度。
4.可以尝试采用“联邦小模型”的方式,在应用侧做好分发,从而达到”花小模型的钱,享大模型的福”。
我们一个个来看。
3
模型消耗的重要因素:算力成本计算公式
注:这一部分的计算量有点大,不过都是加减乘除,大家轻松看待。
首先对于模型厂商来说:模型算力成本 = 预训练成本 + 推理成本 。
3.1
预训练成本
即训练一个模型所需成本,按照过去 openAI 的节奏是每半年训练一次。预训练成本计算如下:
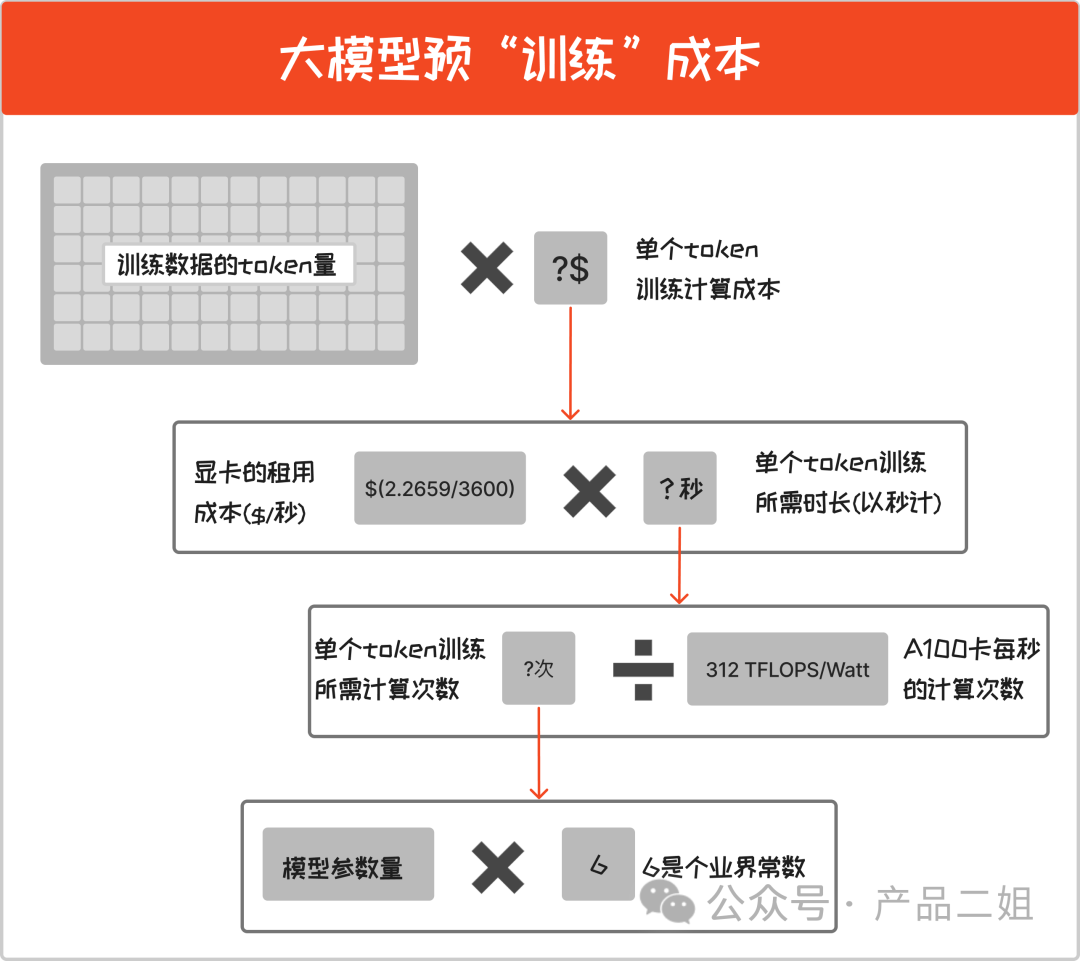
预训练成本 = ( 模型参数量 6 /A100 卡每秒的计算次数) 显卡的租用成本 训练数据的 token 量
在这里有两个两个常量:
A100 卡每秒的计算次数 = 312 TFLOPS/Watt (官方公布,每秒可以进行 312T 次浮点数计算)
显卡租用成本:暂时以微软 Azure 云上公布的 Nvdia A100 的三年期租用价格$2.2659/小时计算,本文按秒来计算,就是每秒租用价格为$(2.2659/3600) (参考 https://azure.microsoft.com/en-us/pricing/details/virtual-machines/linux/#pricing)
常量之外,还有两个变量,他们与预训练成本成正比:
模型参数量
训练数据的 token 量
拿 openAI 的模型举个例子大家感受一下(考虑到这里的显卡成本是按照租用成本来计算的,openAI 作为显卡消耗大户,咱们可以直接打个五折):
GPT3 的参数量是 175B,训练数据的 token 量 500B,约 105 万美元*5 折,约 372.75 万元。
GPT4 的参数量是 1800B,训练数据的 token 量 13T, 费用是 GPT3 的 280 倍,约 1.45 亿美元,人民币 10 亿元。
GPT4 Turbo 的参数量是 8*222B ,训练数据的 token 量 13T,费用与 GPT4 差不多。
注:GPT4 和 GPT4 Turbo 的参数量和训练数据 token 量均为坊间普遍传闻,并未得到 openAI 证实。
预训练成本算出来之后,我们看看算力成本的另外一项:推理成本。
3.2
推理成本
即每次用户问答时消耗的算力成本,是按用量来消耗的,我们就按照 open AI 的定价单位:每千个 token 来算。
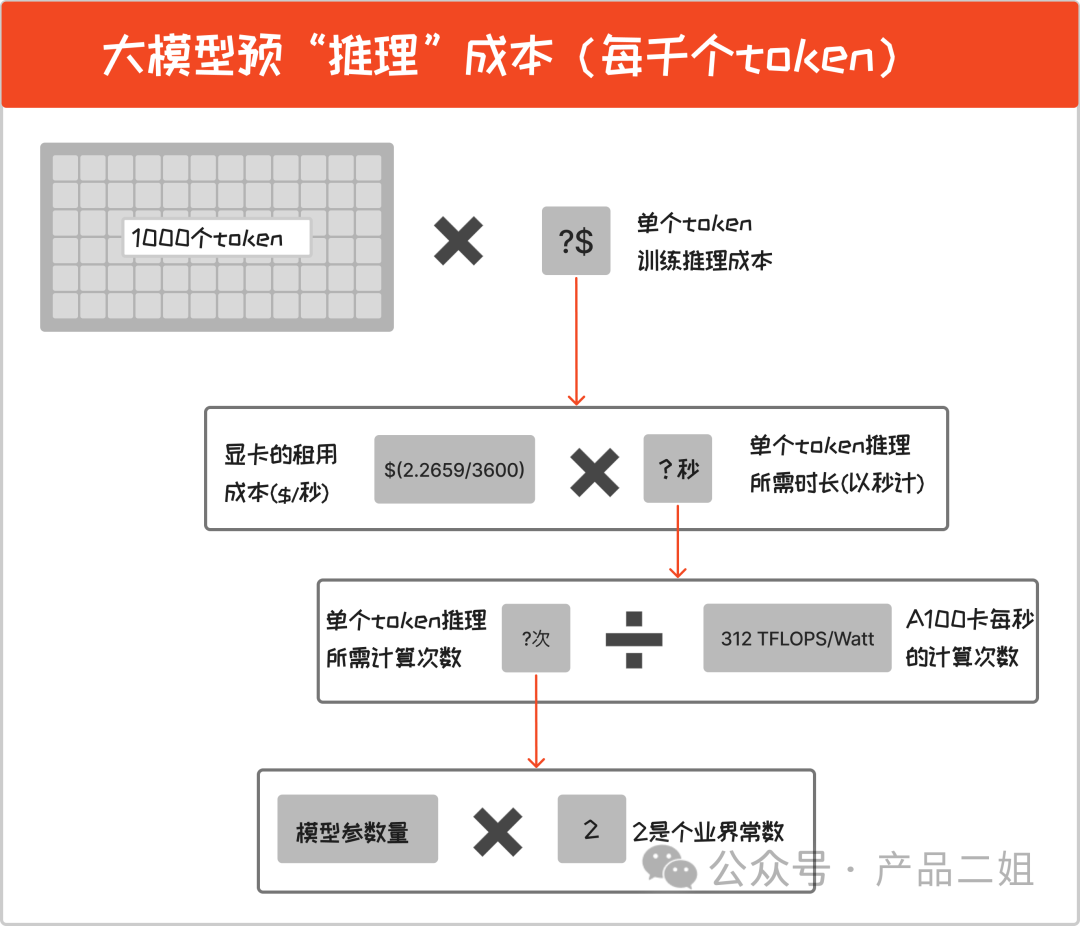
每千个 token 推理成本 = 1000( 模型参数量2 /A100 卡每秒的计算次数)显卡的租用成本
推理成本仅与模型参数量成正比,拿 OpenAI 最新的 GPT4 Turbo 模型举例:
GPT4 Turbo 的参数量是 8222B,按照上述公式计算,每千个 token 推理成本 = $0.0071656。
到这里大家可能会好奇:openAI 到底要有多少使用量、多少用户才能收回成本?这个问题我放在文末。我们先来总结一下这一部分的核心:
模型的算力成本与模型参数量和所使用训练数据使用的 token 量成正比,大概率来说(因为定价不一定总是以成本为标准):
模型参数量越少,成本越低
训练数据的 token 数量越少,成本越低
但是模型参数量变小了,训练数据的 token 数量越少,是不是意味着效果也会变差?当然不是,比如 9 月份发布的 Mistral 7B,只有 70 亿参数,就能匹敌 Llama 1 34B(拥有 340 亿参数)。当然,目前来说,GPT4 Turbo 是公认的一骑绝尘,但在 GPT4 之下:
没有最大的模型,只有最合适的模型。
因为从产品角度,我们有时并不需要模型有那么多的参数量,也不需要模型训练那么多数据,这时候我们就需要评估:
参数量小的模型能不能满足我们的使用场景?
预训练数据量低的模型能不能满足我们的使用场景?
引出接下来的话题。
4
如何评估小模型能不能满足我们的使用场景
首先个人认为当前情况下这个评测仅在你无法使用 GPT4 的时候有意义。同等能力下,优先使用参数小的模型。评测大体可以做以下几步操作:
先看评测机构的结果,各自都有不同的方法。早些时候我在知乎上有一篇《大模型技术哪家强,找对机构看排行》,里面提到一些机构,当然现在也诞生了很多新的评测机构,大家可以参考。
结合你自己的使用场景,比如注重推理,还是注重表达来选择。
最后亲手去根据自己的场景做实验,说白了,就是同样的提示词,你需要测哪个模型的效果最符合你的诉求,这一块也有方法,我们留在以后讨论。
值得借鉴的是,周末在听知乎张俊林老师的访谈中提到:“ 在学术研究上,目前小模型的语言表达能力和知识获取的能力上已经可以和大模型匹敌,在推理能力上会弱,但目前也有途径来解决,我们有望在今年解决。”
Mixrel 7B 就是一个很好的例子。再看看另外一个话题:预训练数据量对模型的影响。
5
预训练数据量低会对模型有哪些影响
目前看起来,训练数据的质量比数量更重要。对于大模型厂商来说,如何从繁多的数据中拿到高质量的训练数据是他们降低成本的重要工作。
另外一方面,以垂直领域数据作为训练数据,也会诞生出很多垂直领域的模型。这些模型从预训练(而不是 SFT 微调)数据上就开始垂直化。比如 Bloomberg 训练出来的金融大语言模型(LLM for Finance,参数量为 500 亿),使用了包含 3630 亿 token 的金融领域数据集以及 3450 亿 token 的通用数据集。
对于 AI 应用开发者来说,可以从垂直度和数据量大小两方面考虑。
除此之外,张俊林老师也脑暴了另外一种省钱的方式:”联邦小模型“(不用去百度,这是我起的名字),不妨也放在这里也来讨论一下。
6
未来会有联邦小模型吗?
我所指的”联邦小模型“是在应用层,未来如果有不同能力的模型,比如有的模型擅长表达,有的擅长推理,那么在应用层可以按照场景将问题分发给不同的模型,从而达到”花小模型的钱,享大模型的福”的效果。
以上就是我理解中的在模型层可以做的降低成本的方法,但目前在这方面的实践行业内都比较少,毕竟没有那么多卡和经历去评测所有的模型,也欢迎大家一起讨论。
最后解答一下大家可能好奇的问题:OpenAI 现在能收回算力成本吗?
7
附加题:OpenAI 能收回算力成本吗
7.1
openAI 的算力成本
我们以 openAI 每半年进行一次训练为假设条件,看看 OpenAI 每个月的算力成本。
openAI 每月的算力成本= 预训练成本/6 个月 + 每月 token 消耗量(千)*每千个 token 推理成本
也就是:
openAI 每月的算力成本= 1.45 亿/6 + 每月 token 消耗量(千)0.007
7.2
方法一:假设 openAI 只有 Token 用量收费项目,每月卖出多少 Token 能收回成本
目前 openAI GPT4 Turbo 的官方报价如下图:
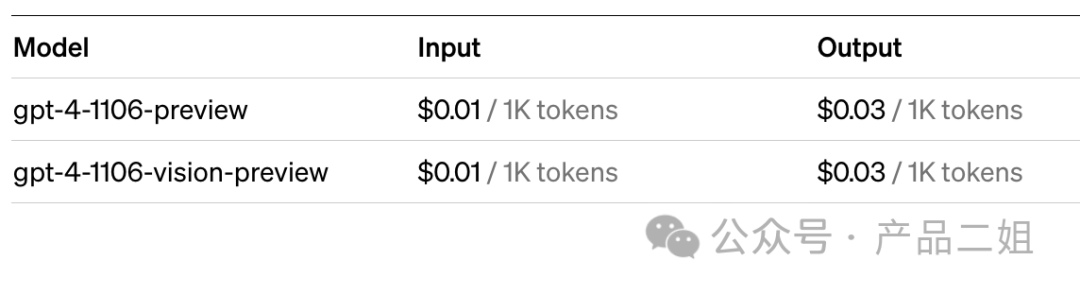
拍脑袋假设用户的 Input 和 Output 比例为 1:1,那么平均价格就是$0.02/千 Token,推理成本(0.00716567)仅占其中的 36%,要想收回“训练”成本 1.45 亿美元,就靠价格中的另外 64%了。
按照目前的定价,我们可以得出:
openAI 每月的收入 = (每月 token 消耗量(万亿)2)千万
结合 “openAI 每月的算力成本 = 2.4 千万 + (每月 token 消耗量(万亿)0.7)千万”,放在坐标系里:OpenAI 按量使用每月卖出 1.85 万亿 token 方可回本。
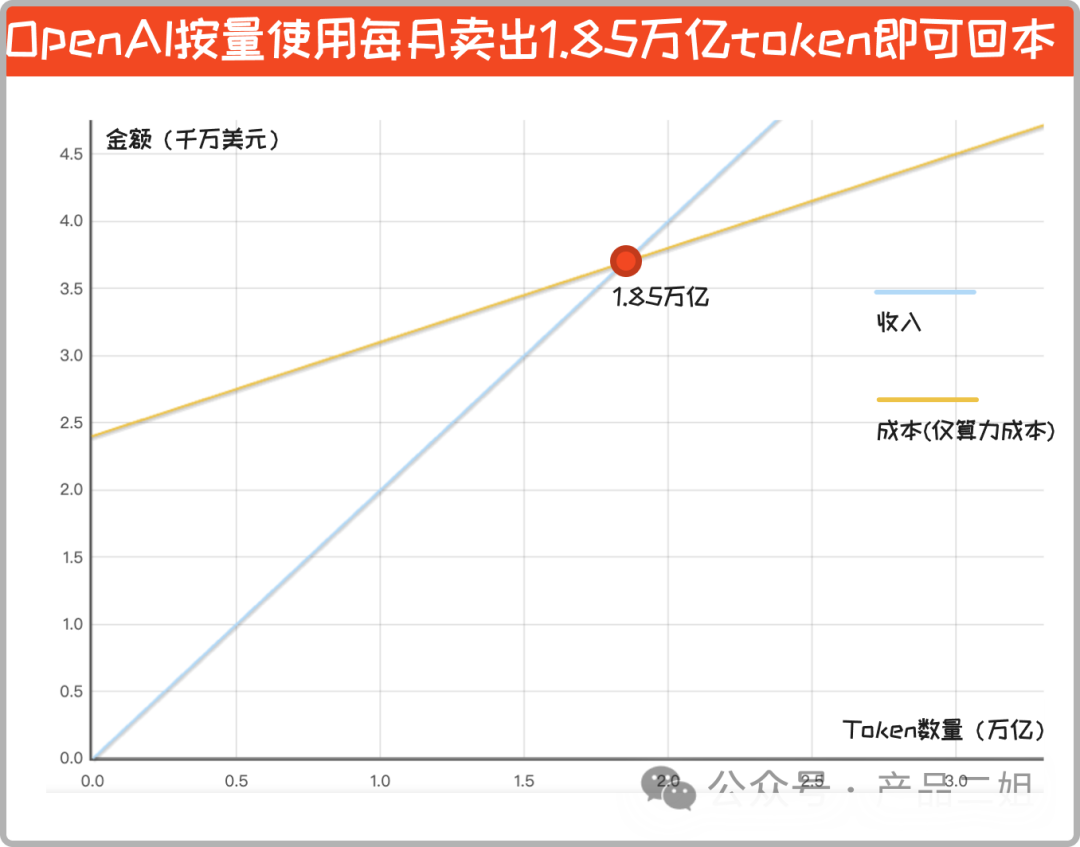
假设有一千万个用户,每个用户每天要消耗:6154 个 Token,相当于问答产生 6154/1.3 = 4733 个单词,这个要求应该不算高。
7.3
方法二:假设 openAI 只有 chatPLUS 会员订阅收费,卖出多少用户能收回成本。
OpenAI 的收入 = 用户数$ 20 = (2用户数(千万))亿美元
如果每个用户都物尽其用,按照 openAI 官方回复:ChatPlus 会员每三个小时最多问 40 个问题,我参照我自己的使用情况:
平均每个英文问题约消耗 500 个单词(约等于 500 个 token)。
醒着的 9 个小时最多问 120 个问题,
那么每月总共使用 30120 500 = 180(万)个 token。
OpenAI 每月算力成本 = 1.45 亿/6 + 每月 token 消耗量(千) 0.007
=(0.24 + 用户数(千万)平均每人每月 token 消耗量(万) 0.007)亿美元
放在坐标系里是这样的:
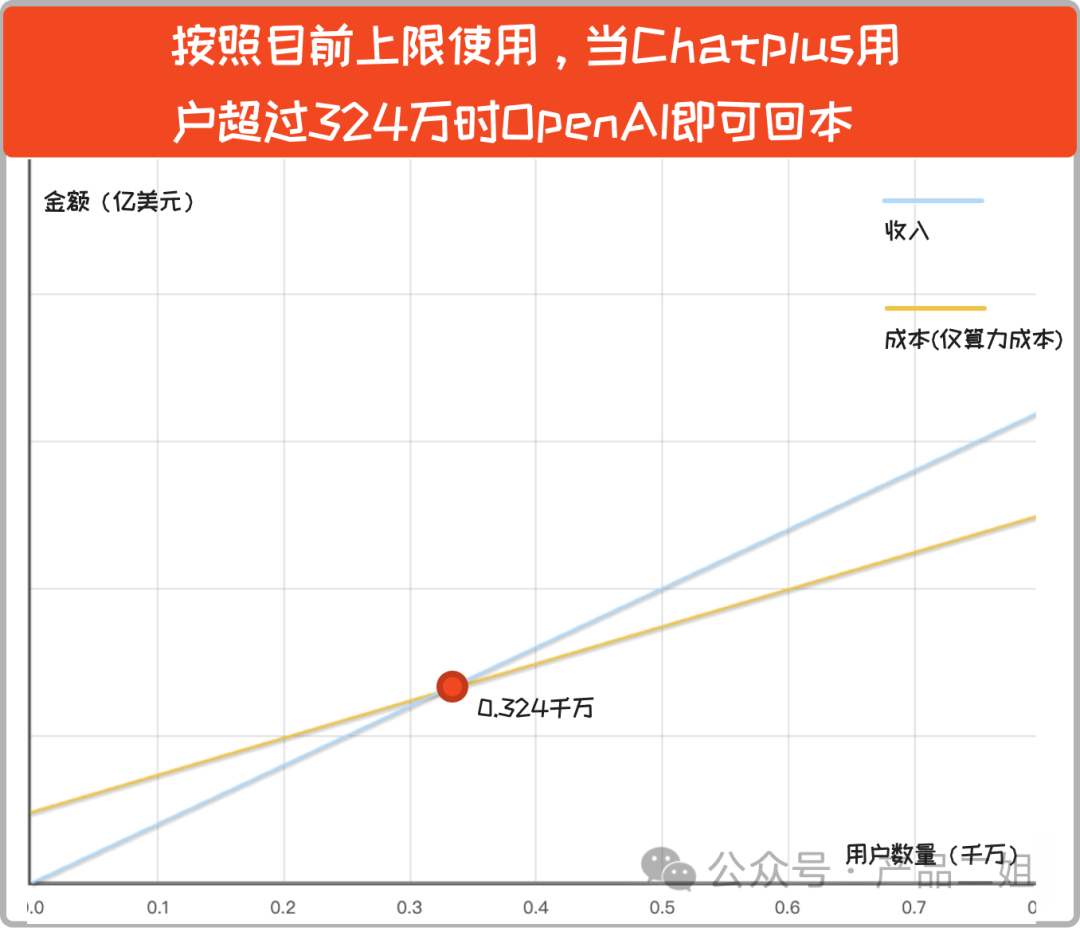
即使每个 Plus 用户都物尽其用,只要用户数量超 324 万后,OpenAI 就开始盈利。
实际上,坊间流传 Plus 会员平均每天的 token 数量可能在 6700 左右(我个人觉得评估偏低),如果是这样的话,用户数只要超过 129 万,就可以实现盈利。
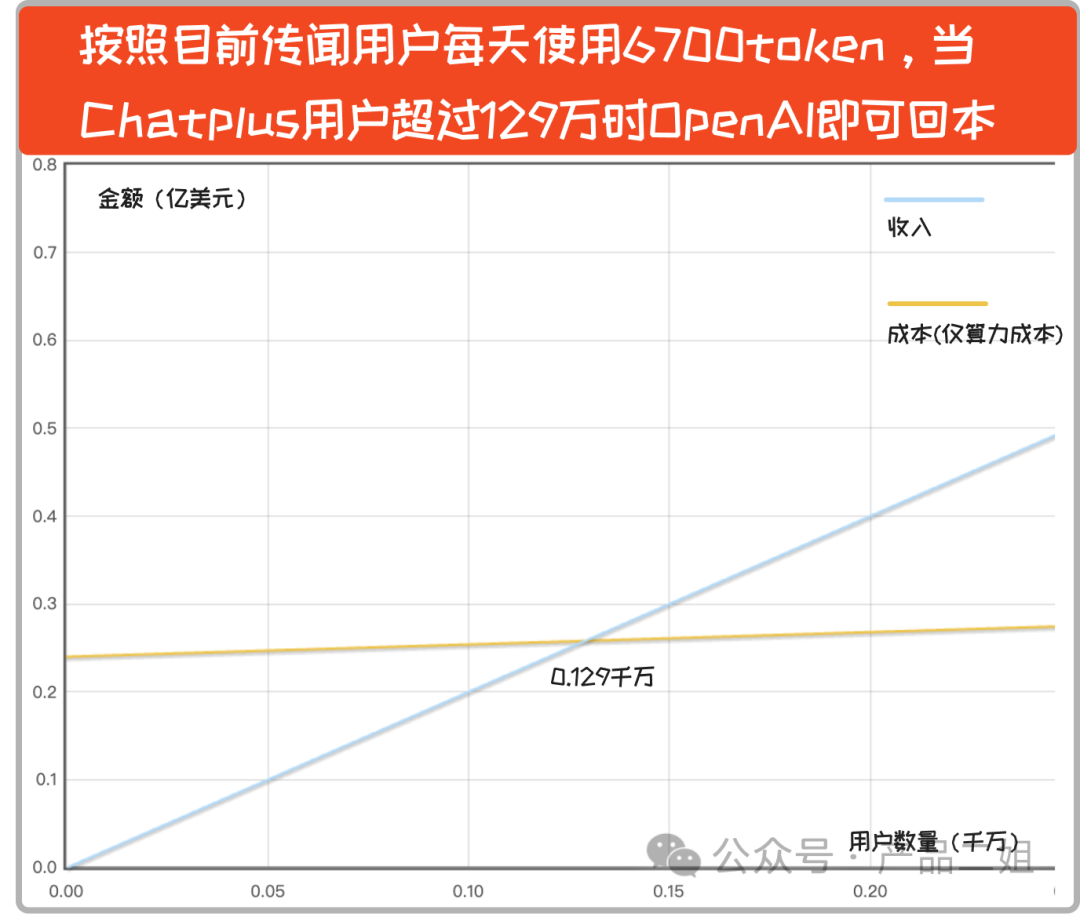
再次重申,以上成本不包含人力成本(目测怎么也有几个亿美元吧)
这一通计算下来,感觉 OpenAI 的定价目前也还算合理,也反映出来模型成本估算的方式也算正确。
如果未来 OpenAI 成为 Google 级的超十亿大应用,加上算力成本下降(芯片、数据、模型优化等方式),还有很大的降价空间,比如说降低到目前的千分之一。我们期待这一天的到来。
审核编辑:黄飞





















 工商网监
工商网监
评论