 电子发烧友App
电子发烧友App


技术前沿:AICG——混合专家模型 (MoEs)
什么是混合专家模型?
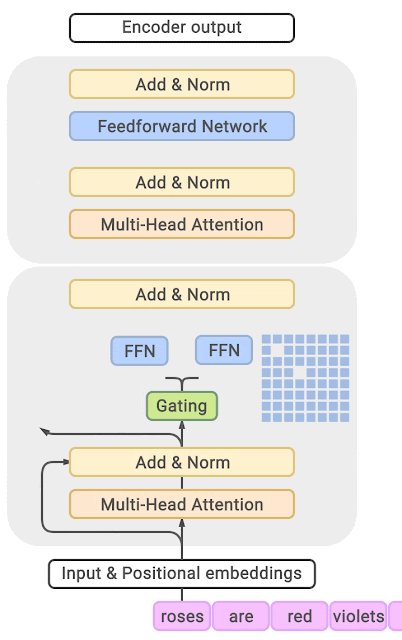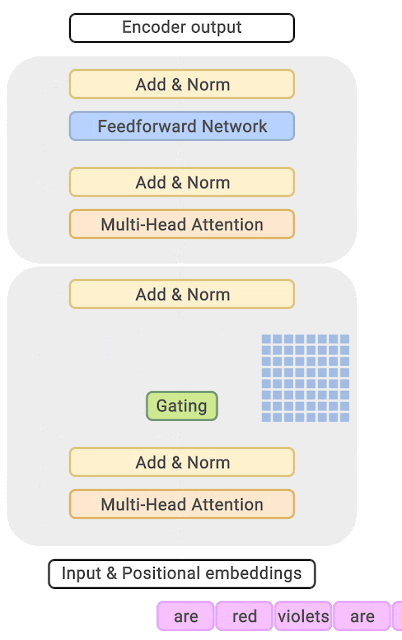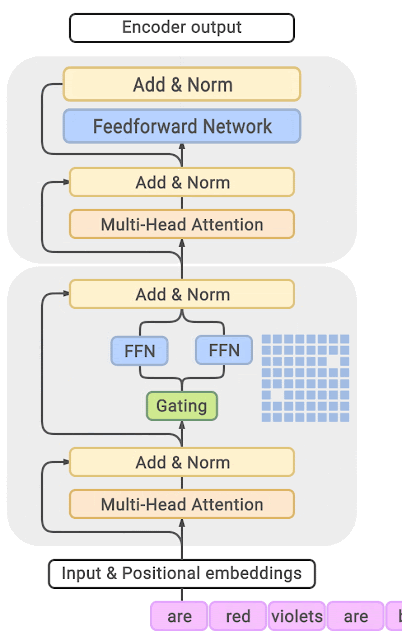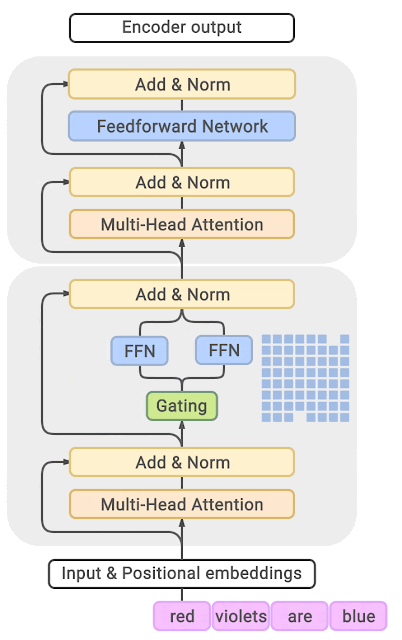
混合专家模型主要由两个关键部分组成:
稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
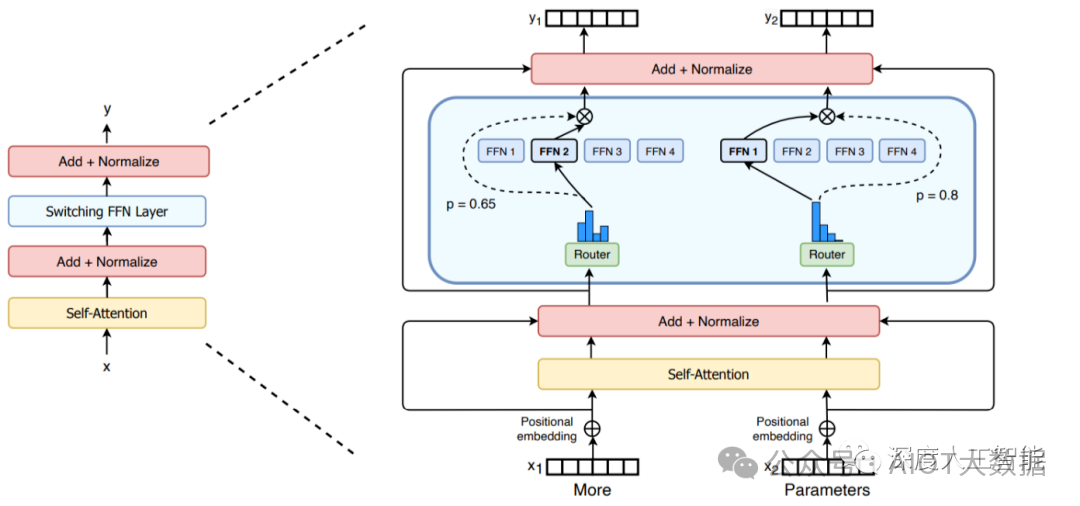
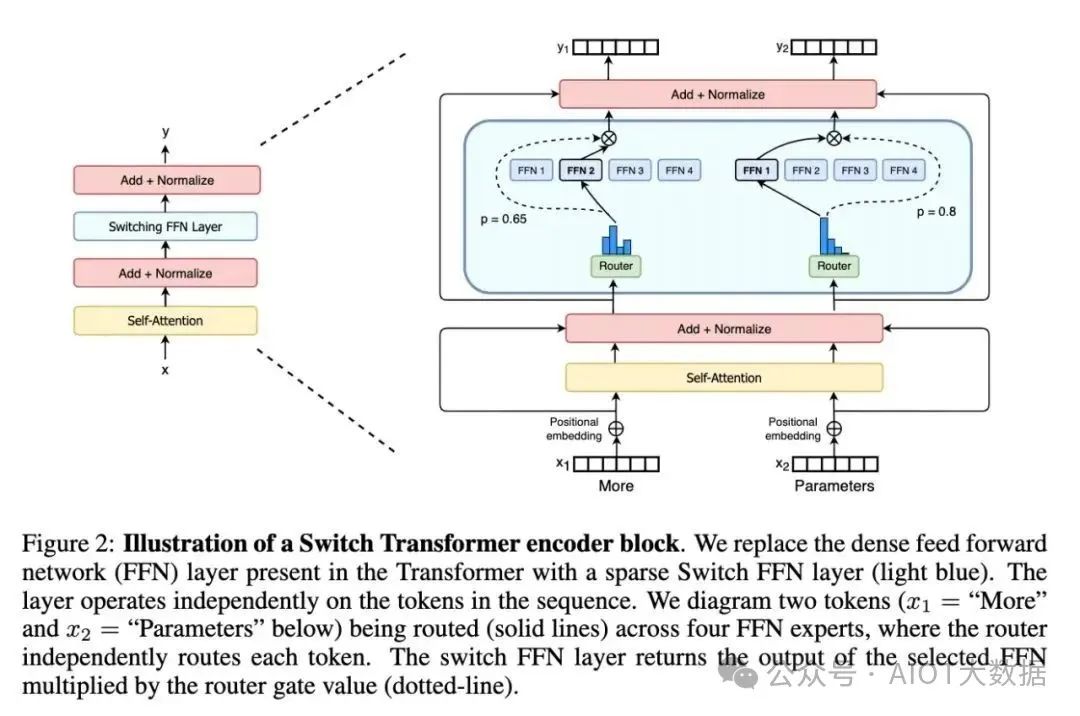
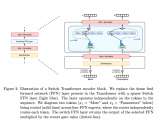
门控网络或路由: 这个部分用于决定哪些令牌 (token) 被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
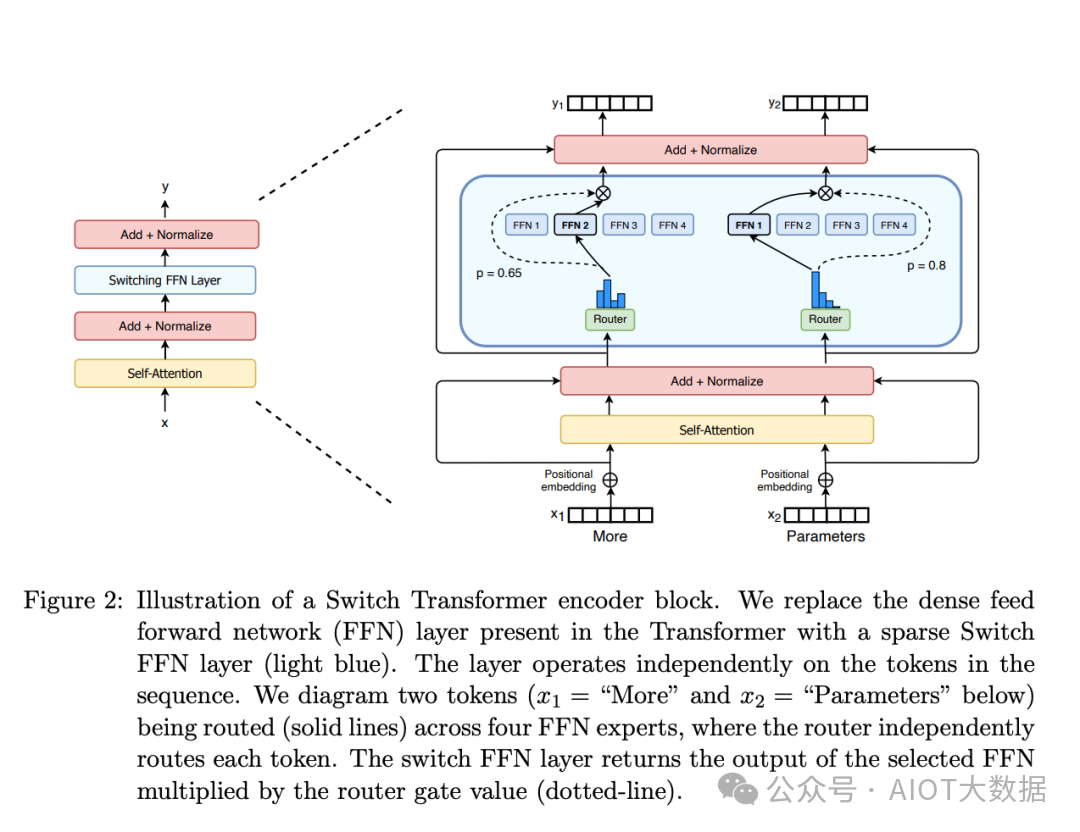
Switch Transformers paper 论文中的 MoE layer
总结来说,在混合专家模型 (MoE) 中,我们将传统 Transformer 模型中的每个前馈网络 (FFN) 层替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个门控网络和若干数量的专家。
尽管混合专家模型 (MoE) 提供了若干显著优势,例如更高效的预训练和与稠密模型相比更快的推理速度,但它们也伴随着一些挑战:
训练挑战: 虽然 MoE 能够实现更高效的计算预训练,但它们在微调阶段往往面临泛化能力不足的问题,长期以来易于引发过拟合现象。
推理挑战: MoE 模型虽然可能拥有大量参数,但在推理过程中只使用其中的一部分,这使得它们的推理速度快于具有相同数量参数的稠密模型。然而,这种模型需要将所有参数加载到内存中,因此对内存的需求非常高。以 Mixtral 8x7B 这样的 MoE 为例,需要足够的 VRAM 来容纳一个 47B 参数的稠密模型。之所以是 47B 而不是 8 x 7B = 56B,是因为在 MoE 模型中,只有 FFN 层被视为独立的专家,而模型的其他参数是共享的。此外,假设每个令牌只使用两个专家,那么推理速度 (以 FLOPs 计算) 类似于使用 12B 模型 (而不是 14B 模型),因为虽然它进行了 2x7B 的矩阵乘法计算,但某些层是共享的。
混合专家模型简史
混合专家模型 (MoE) 的理念起源于 1991 年的论文 Adaptive Mixture of Local Experts。这个概念与集成学习方法相似,旨在为由多个单独网络组成的系统建立一个监管机制。在这种系统中,每个网络 (被称为“专家”) 处理训练样本的不同子集,专注于输入空间的特定区域。那么,如何选择哪个专家来处理特定的输入呢?这就是门控网络发挥作用的地方,它决定了分配给每个专家的权重。在训练过程中,这些专家和门控网络都同时接受训练,以优化它们的性能和决策能力。
在 2010 至 2015 年间,两个独立的研究领域为混合专家模型 (MoE) 的后续发展做出了显著贡献:
组件专家: 在传统的 MoE 设置中,整个系统由一个门控网络和多个专家组成。在支持向量机 (SVMs) 、高斯过程和其他方法的研究中,MoE 通常被视为整个模型的一部分。然而,Eigen、Ranzato 和 Ilya 的研究 探索了将 MoE 作为更深层网络的一个组件。这种方法允许将 MoE 嵌入到多层网络中的某一层,使得模型既大又高效。
条件计算: 传统的神经网络通过每一层处理所有输入数据。在这一时期,Yoshua Bengio 等研究人员开始探索基于输入令牌动态激活或停用网络组件的方法。
这些研究的融合促进了在自然语言处理 (NLP) 领域对混合专家模型的探索。特别是在 2017 年,Shazeer 等人 (团队包括 Geoffrey Hinton 和 Jeff Dean,后者有时被戏称为 “谷歌的 Chuck Norris”) 将这一概念应用于 137B 的 LSTM (当时被广泛应用于 NLP 的架构,由 Schmidhuber 提出)。通过引入稀疏性,这项工作在保持极高规模的同时实现了快速的推理速度。这项工作主要集中在翻译领域,但面临着如高通信成本和训练不稳定性等多种挑战。
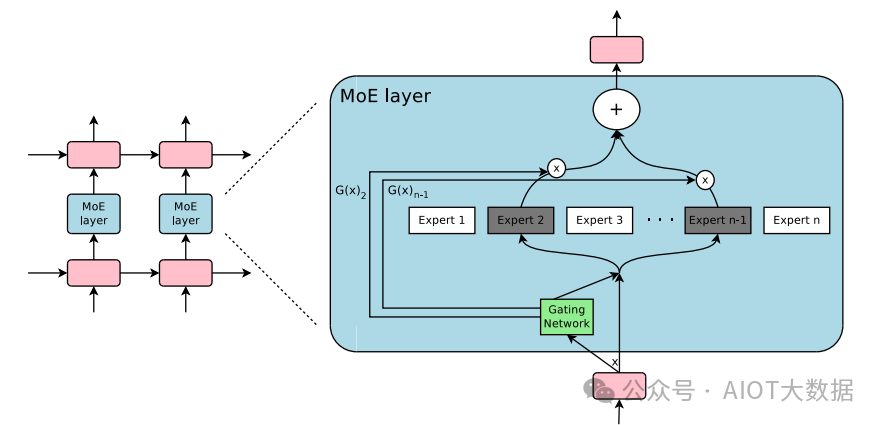
Outrageously Large Neural Network 论文中的 MoE layer
混合专家模型 (MoE) 的引入使得训练具有数千亿甚至万亿参数的模型成为可能,如开源的 1.6 万亿参数的 Switch Transformers 等。这种技术不仅在自然语言处理 (NLP) 领域得到了广泛应用,也开始在计算机视觉领域进行探索。
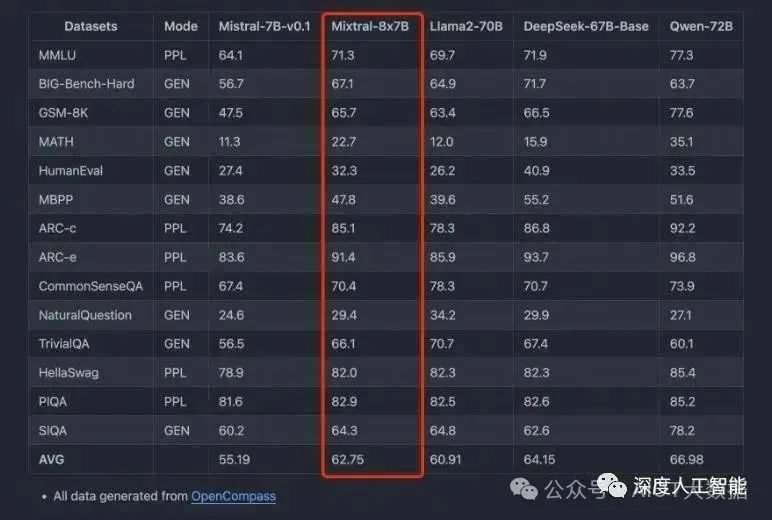
最近再次大火的原因,评测超Llama2,混合专家模型(MoE)会是大模型新方向吗?
先是 Reddit 上一篇关于 GPT-4 结构的猜测帖,暗示了 GPT-4 可能是由 16 个子模块组成的专家模型(MoE)的混合体。据说,这 16 个子模块中的每一个 MoE 都有 1110 亿个参数(作为参考,GPT-3 有 1750 亿个参数)。尽管不能 100% 确定,但 GPT-4 是一个 MoE 组成的集群这个事很可能是真的。
然后是法国 AI 公司 MistralAI 发布了全球首个基于混合专家技术的大模型 Mistral-8x7B-MoE,是 8 个 70 亿参数规模大模型的混合。
主要特点如下:
它可以非常优雅地处理 32K 上下文数据;
除了英语外,在法语、德语、意大利语和西班牙语表现也很好;
在代码能力上表现很强;
指令微调后 MT-Bench 的得分 8.3 分(GPT-3.5 是 8.32、LLaMA2 70B 是 6.86);
Mistral-7B×8-MoE 是首个被证明有效的开源的 MoE LLM,相比于早期的 Switch Transformer、GLaM 等研究,Mistral-7B×8-MoE 证明了 MoE 真的可以落地,且效果远好于相同激活值的 Dense 模型。
而在最近的一个评测中,Mistral-8x7B-MoE 经过微调后的表现超过了 Llama2-65B。
到底什么是 MoE,可以参见 Hugging Face 官方对 MoE 的详细技术解读。
01、MoE 的前世今生
混合专家模型(MixtureofExperts:MoE)的思想可以追溯到集成学习,集成学习是通过训练多个模型(基学习器)来解决同一问题,并且将它们的预测结果简单组合(例如投票或平均)。集成学习的主要目标是通过减少过拟合,提高泛化能力,以提高预测性能。常见的集成学习方法包括 Bagging,Boosting 和 Stacking。
集成学习在训练过程中,利用训练数据集训练基学习器,基学习器的算法可以是决策树、SVM、线性回归、KNN 等,在推理过程中对于输入的 X,在每个基学习器得到相应的答案后将所有结果有机统一起来,例如通过求均值的方法解决数值类问题,通过投票方式解决分类问题。
MoE 和集成学习的思想异曲同工,都是集成了多个模型的方法,但它们的实现方式有很大不同。与 MoE 的最大不同的地方是集成学习不需要将任务分解为子任务,而是将多个基础学习器组合起来。这些基础学习器可以使用相同或不同的算法,并且可以使用相同或不同的训练数据。

MoE 模型本身也并不是一个全新的概念,它的理论基础可以追溯到 1991 年由 MichaelJordan 和 GeoffreyHinton 等人提出的论文,距今已经有 30 多年的历史,但至今依然在被广泛应用的技术。这一理念在被提出来后经常被应用到各类模型的实际场景中,在 2017 年得到了更进一步的发展,当时,一个由 QuocLe,GeoffreyHinton 和 JeffDean 领衔的团队提出了一种新型的 MoE 层,它通过引入稀疏性来大幅提高模型的规模和效率。
大模型结合混合专家模型的方法属于老树发新芽,随着应用场景的复杂化和细分化,大模型越来越大,垂直领域应用更加碎片化,想要一个模型既能回答通识问题,又能解决专业领域问题,似乎 MoE 是一种性价比更高的选择。在多模态大模型的发展浪潮之下,MoE 大有可能成为 2024 年大模型研究的新方向之一,而大模型也会带着 MoE,让其再次伟大。
下面是近些年一部分 MoE 的应用发展事件,可以看出早期 MoE 的应用和 Transformer 的发展时间节点差不多,都是在 2017 年左右。
2017 年,谷歌首次将 MoE 引入自然语言处理领域,通过在 LSTM 层之间增加 MoE 实现了机器翻译方面的性能提升;
2020 年,Gshard 首次将 MoE 技术引入 Transformer 架构中,并提供了高效的分布式并行计算架构,而后谷歌的 Swtich Transformer 和 GLaM 则进一步挖掘 MoE 技术在自然语言处理领域中的应用潜力,实现了优秀的性能表现;
2021 年的 V-MoE 将 MoE 架构应用在计算机视觉领域的 Transformer 架构模型中,同时通过路由算法的改进在相关任务中实现了更高的训练效率和更优秀的性能表现;
2022 年的 LIMoE 是首个应用了稀疏混合专家模型技术的多模态模型,模型性能相较于 CLIP 也有所提升。
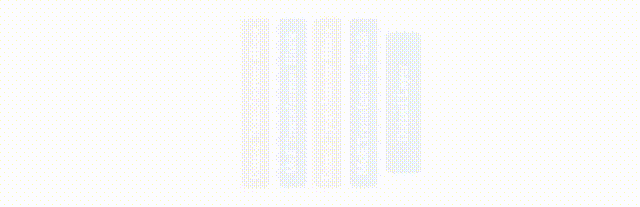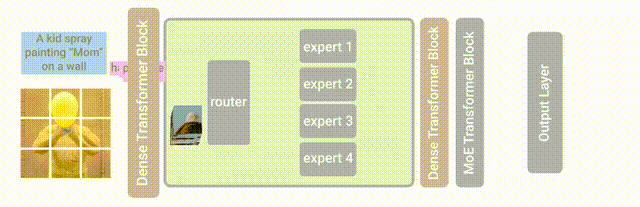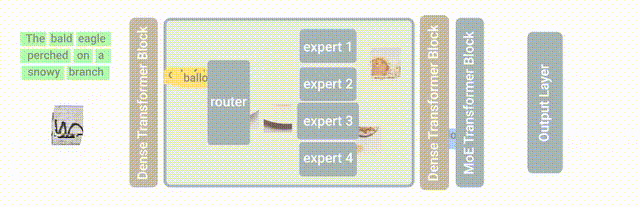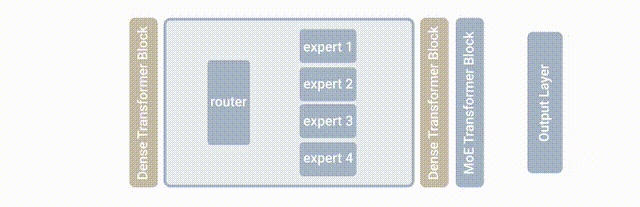
近期 Mistral AI 发布的 Mistral 8x7B 模型是由 70 亿参数的小模型组合起来的 MoE 模型,直接在多个跑分上超过了多达 700 亿参数的 Llama 2。
将混合专家模型(Mixture of Experts:MoE)应用于大模型中似乎是不一个不错的想法,Mistral AI 发布的 Mistral 8x7B 模型在各项性能和参数上证明了这一点,使用了更少的参数却获得了远超于 Llama 2 的效果,这为大模型的发展提供了一种新的思路。
02、MoE 的核心思想:术有专攻
「学有所长,术有专攻」,古人早已将告诉过我们如何将复杂的事物简单化处理。大模型从早期只处理文本数据,到后来需要同时处理图像数据和语音数据的发展过程中,其参数量和模型结构设计也越来复杂和庞大。
如果说单模态大模型是一个「特长生」,那么多模态大模型就是一个「全能天才」,想要让这个「全能天才」学习的更好,那么就需要对其学习任务分类,安排不同科目的老师进行学习任务的辅导,这样才能让其高效快速的学习到各科的知识,在考试的时候才有可能在各科成绩上有优异的表现。
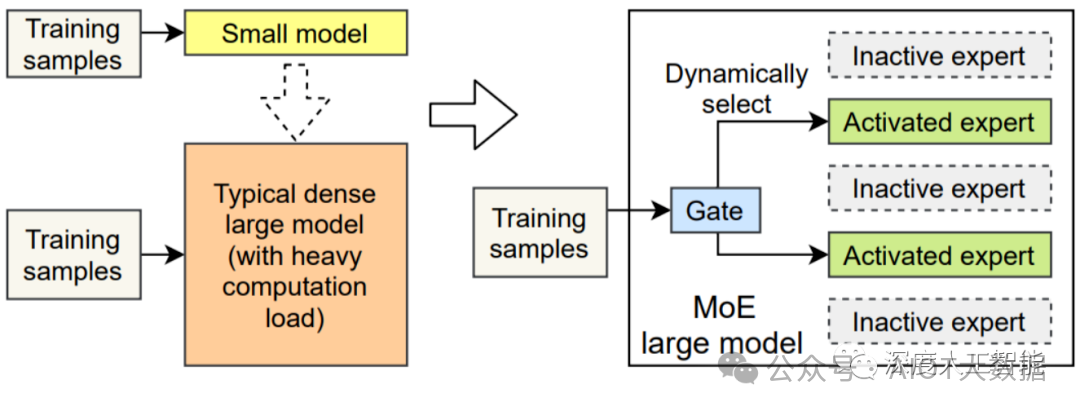
混合专家模型(MixtureofExperts:MoE)正是这样一个培养「全能天才」的方法,其核心思想就是先把任务分门别类,然后分给各个「专家模型」进行解决。混合专家模型(MoE)是一种稀疏门控制的深度学习模型,它主要由一组专家模型和一个门控模型组成。MoE 的基本理念是将输入数据根据任务类型分割成多个区域,并将每个区域的数据分配一个或多个专家模型。每个专家模型可以专注于处理输入这部分数据,从而提高模型的整体性能。
MoE 架构的基本原理非常简单明了,它主要包括两个核心组件:GateNet 和 Experts。GateNet 的作用在于判定输入样本应该由哪个专家模型接管处理。而 Experts 则构成了一组相对独立的专家模型,每个专家负责处理特定的输入子空间。
门控模型(GateNet):混合专家模型中「门」是一种稀疏门网络,它接收单个数据元素作为输入,然后输出一个权重,这些权重表示每个专家模型对处理输入数据的贡献。一般是通过 softmax 门控函数通过专家或 token 对概率分布进行建模,并选择前 K 个。例如,如果模型有三个专家,输出的概率可能为 0.5 和 0.4、0.1,这意味着第一个专家对处理此数据的贡献为 50%,第二个专家为 40%,第二个专家为 10%,这个时候的 K 就可以选择为 2,我们认为前两个专家模型的建议会更好,可以用于更加精确的回答中,而第三个专家模型的建议可以用于更加富有创意性的答案中。
专家模型(Experts):在训练的过程中,输入的数据被门控模型分配到不同的专家模型中进行处理;在推理的过程中,被门控选择的专家会针对输入的数据,产生相应的输出。这些输出最后会和每个专家模型处理该特征的能力分配的权重进行加权组合,形成最终的预测结果。
混合专家模型在训练过程中通过门控模型实现「因材施教」,进而在推理过程中实现专家模型之间的「博采众长」。MoE 的专家模型可以是小型的 MLP 或者复杂的 LLM。
在传统的密集模型中,每个输入都必须经历完整的计算流程,这导致了在处理大规模数据时的显著计算成本。然而,在现代深度学习中,稀疏混合专家(MoE)模型的引入为解决这一问题提供了一种新的方法。在这种模型中,输入数据只激活或利用了少数专家模型,而其他专家模型保持不活跃状态,形成了「稀疏」结构。这种稀疏性被认为是混合专家模型的重要优点,不仅在减少计算负担的同时,还能提高模型的效率和性能。
MoE模型的优势在于其灵活性和扩展性。由于可以动态地调整专家网络的数量和类型,MoE 模型可以有效地处理大规模和复杂的数据集。此外,通过并行处理不同的专家网络,MoE 模型还可以提高计算效率。
在实际应用中,MoE 模型常用于处理需要大量计算资源的任务,如语言模型、图像识别和复杂的预测问题。通过将大型问题分解为更小、更易管理的子问题,MoE 模型能够提供更高效和精确的解决方案。
03、MoE 的优势与缺点
混合专家模型的优势显而易见,通过 MoE 的方式,可以极大的促进大模型的研究和发展,但也不能忽视其各方面的问题,在实际应用中应该结合具体的需求对各方面的性能和参数进行一个权衡。
混合专家模型(Mixture of Experts,MoE)的优势:
混合专家模型(Mixture of Experts,MoE)具有多方面的优势,使其在深度学习领域得到广泛应用。以下是一些混合专家模型的优势:
1. 任务特异性:采用混合专家方法可以有效地充分利用多个专家模型的优势,每个专家都可以专门处理不同的任务或数据的不同部分,在处理复杂任务时取得更卓越的性能。各个专家模型能够针对不同的数据分布和模式进行建模,从而显著提升模型的准确性和泛化能力,因此模型可以更好地适应任务的复杂性。这种任务特异性使得混合专家模型在处理多模态数据和复杂任务时表现出色。
2. 灵活性:混合专家方法展现出卓越的灵活性,能够根据任务的需求灵活选择并组合适宜的专家模型。模型的结构允许根据任务的需要动态选择激活的专家模型,实现对输入数据的灵活处理。这使得模型能够适应不同的输入分布和任务场景,提高了模型的灵活性。
3. 高效性:由于只有少数专家模型被激活,大部分模型处于未激活状态,混合专家模型具有很高的稀疏性。这种稀疏性带来了计算效率的提升,因为只有特定的专家模型对当前输入进行处理,减少了计算的开销。
4. 表现能力:每个专家模型可以被设计为更加专业化,能够更好地捕捉输入数据中的模式和关系。整体模型通过组合这些专家的输出,提高了对复杂数据结构的建模能力,从而增强了模型的性能。
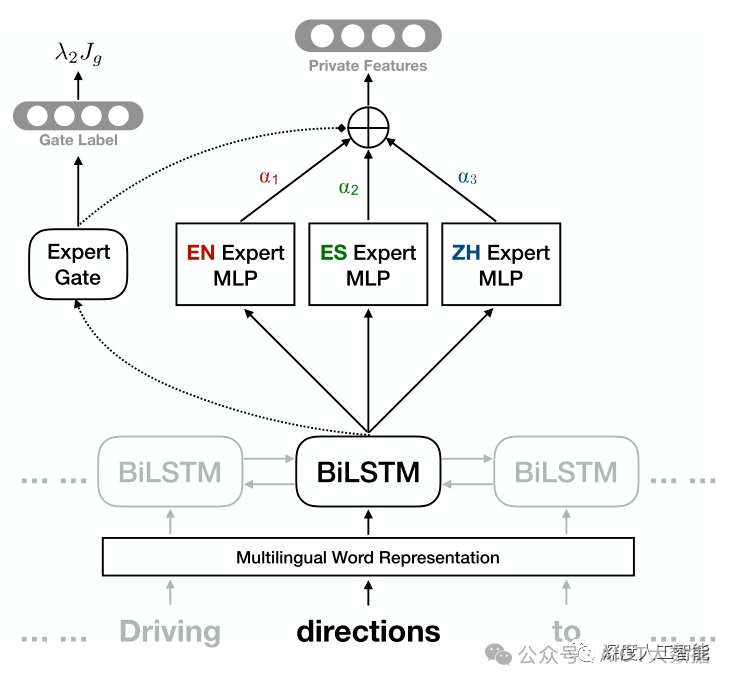
5. 可解释性:由于每个专家模型相对独立,因此模型的决策过程更易于解释和理解,为用户提供更高的可解释性,这对于一些对模型决策过程有强解释要求的应用场景非常重要。
MoE 构架还能向 LLM 添加可学习参数,而不增加推理成本。
6. 适应大规模数据:混合专家方法是处理大规模数据集的理想选择,能够有效地应对数据量巨大和特征复杂的挑战,可以利用稀疏矩阵的高效计算,利用 GPU 的并行能力计算所有专家层,能够有效地应对海量数据和复杂特征的挑战。其并行处理不同子任务的特性,充分发挥计算资源,帮助有效地扩展模型并减少训练时间,提高模型在训练和推理阶段的效率,使其在大规模数据下具有较强的可扩展性,以更低的计算成本获得更好的结果。这种优势使得混合专家方法成为在大数据环境下进行深度学习的强有力工具。
混合专家模型通过充分利用多个专家模型的优势,实现了在任务处理、灵活性、计算效率和可解释性等方面的平衡,使其成为处理复杂任务和大规模数据的有效工具。
混合专家模型(Mixture of Experts,MoE)的问题:
尽管混合专家模型在许多方面具有优势,但也存在一些问题和挑战,这些需要在实际应用中谨慎考虑。以下是一些混合专家模型可能面临的问题:
训练复杂性:混合专家模型的训练相对复杂,尤其是涉及到门控网络的参数调整。为了正确地学习专家的权重和整体模型的参数,可能需要更多的训练时间。
超参数调整:选择适当的超参数,特别是与门控网络相关的参数,以达到最佳性能,是一个复杂的任务。这可能需要通过交叉验证等技术进行仔细调整。
专家模型设计:专家模型的设计对模型的性能影响显著。选择适当的专家模型结构,确保其在特定任务上有足够的表现力,是一个挑战。
稀疏性失真:在某些情况下,为了实现稀疏性,门控网络可能会过度地激活或不激活某些专家,导致模型性能下降。需要谨慎设计稀疏性调整策略,以平衡效率和性能。
动态性问题:在处理动态或快速变化的数据分布时,门控网络可能需要更加灵活的调整,以适应输入数据的变化。这需要额外的处理和设计。
对数据噪声的敏感性:混合专家模型对于数据中的噪声相对敏感,可能在一些情况下表现不如其他更简单的模型。
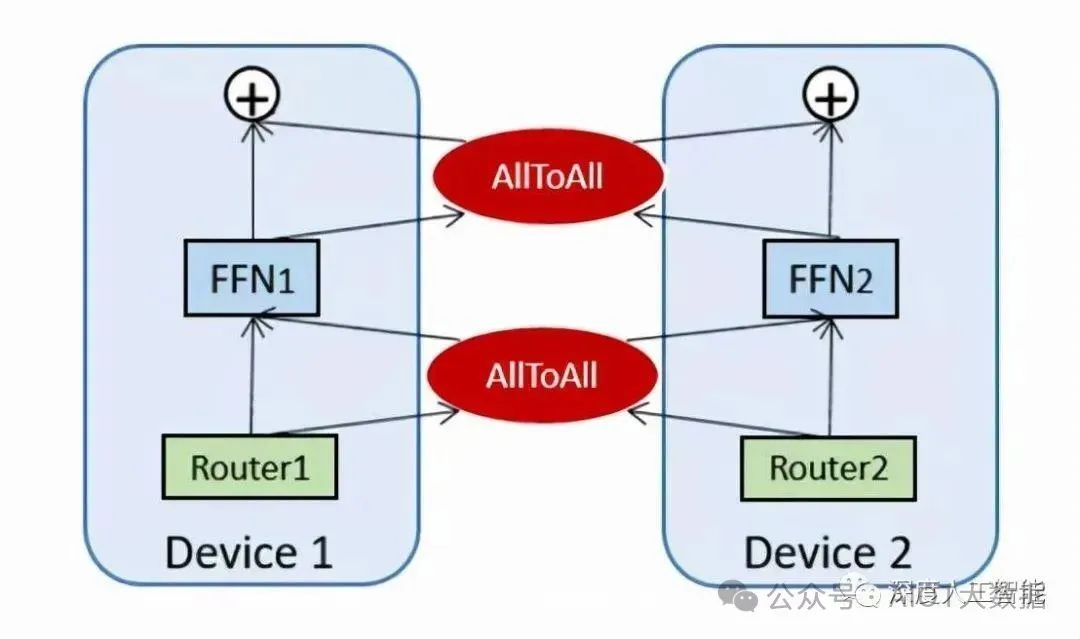
此外,还有重要的一点是混合专家模型在分布式计算环境下可能面临通信宽带瓶颈的问题。这主要涉及到混合专家模型的分布式部署,其中不同的专家模型或门控网络可能分布在不同的计算节点上。在这种情况下,模型参数的传输和同步可能导致通信开销过大,成为性能的一个瓶颈。
04、MoE 相关论文粗读
MoE 相关论文
1. Adaptive mixtures of local experts, Neural Computation'1991
2. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, ICLR'17
3. GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding, ICLR'21
4. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity, JMLR'22
5. GLaM: Efficient Scaling of Language Models with Mixture-of-Experts, 2021
6. Go Wider Instead of Deeper, AAAI'22
7. MoEBERT: from BERT to Mixture-of-Experts via Importance-Guided Adaptation, NAACL'22
论文 3 GShard 是第一个将 MoE 的思想拓展到 Transformer 上的工作,但论文亮点是提出了 GShard 这个框架,可以方便的做对 MoE 结构做数据并行或者模型并行。
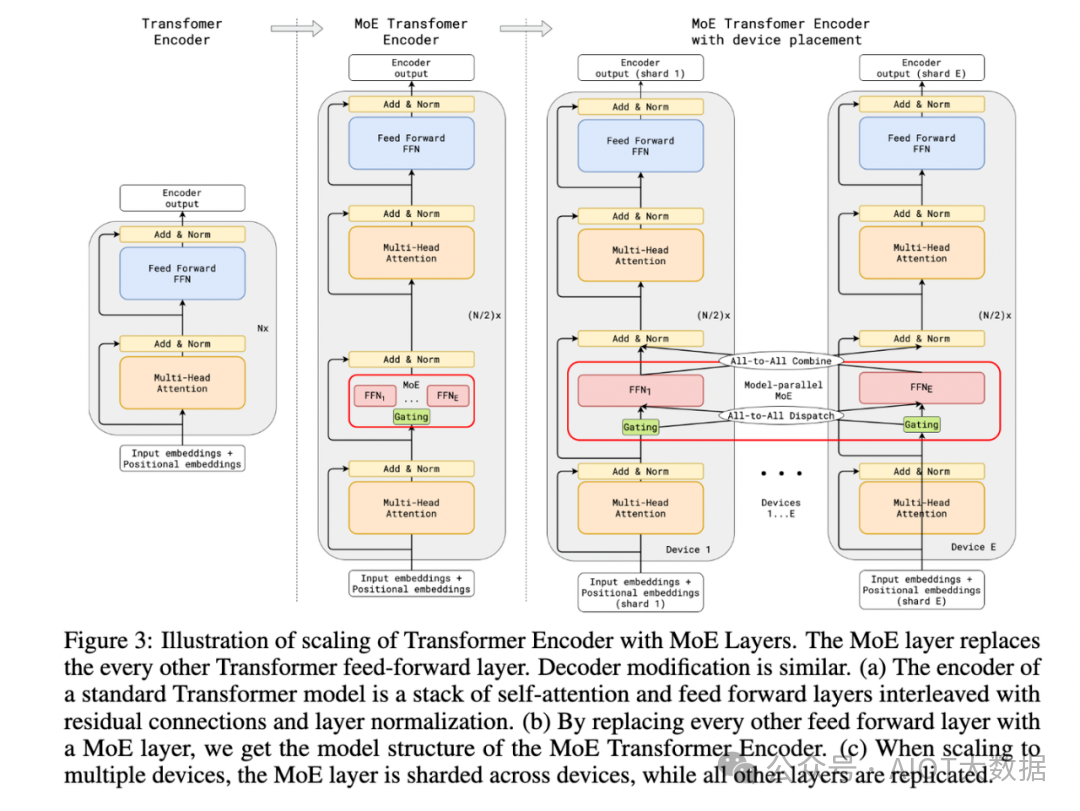
我们可以重点看其中提出的MoE结构,论文具体的做法是:把 Transformer 的 encoder 和 decoder 中,每隔一个(every other)的 FFN 层,替换成 position-wise 的 MoE 层,又加了一个分发器(Gating),使用的是 Top-2 gating network,即不同的 token 每次会发给至多两个专家。
文中还提到了很多其他设计:
Expert capacity balancing:强制每个 expert 处理的 tokens 数量在一定范围内。
Local group dispatching:通过把一个 batch 内所有的 tokens 分组,来实现并行化计算。
Auxiliary loss:也是为了缓解「赢者通吃」问题。
Random routing:在 Top-2 gating 的设计下,两个 expert 如何更高效地进行 routing。
论文 4 Switch Transformer 的亮点在于它简化了 MoE 的 routing 算法,每个 FFN 层激活的专家个数从多个变成了一个,提高了计算效率,可以将语言模型的参数量扩展至 1.6 万亿。
论文 5 GLaM 是 Google 在 2021 年推出的一个超大模型,比 GPT-3 大三倍,但是由于使用了 Sparse MoE 的设计,训练成本却只有 GPT-3 的 1/3,而且在 29 个 NLP 任务上超越了 GPT-3。
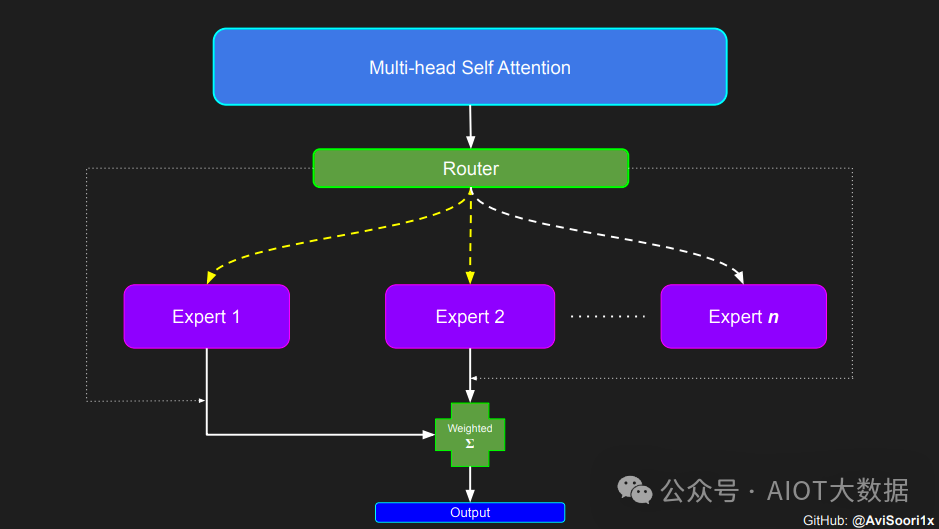
以上三篇文章(GShard,Switch-Transformer,GLaM)都是希望通过 MoE 的方式把模型做得尽可能的大,大到普通人玩不起(动辄使用几百个 experts)。
但也有更亲民一点的,论文 6 和 7 是关于如何利用 MoE 去压缩模型、提高效率。
手把手教你,从零开始实现一个稀疏混合专家架构语言模型(MoE)
选自huggingface
本文介绍了实现一个稀疏混合专家语言模型(MoE)的方法,详细解释了模型的实施过程,包括采用稀疏混合专家取代传统的前馈神经网络,实现 top-k 门控和带噪声的 top-k 门控,以及采用 Kaiming He 初始化技术。作者还说明了从 makemore 架构保持不变的元素,比如数据集处理、分词预处理和语言建模任务。最后还提供了一个 GitHub 仓库链接,用于实现模型的整个过程,是一本不可多得的实战教科书。
内容简介
在混合专家模型 Mixtral 发布后,混合专家模型(MoE)越来越受到人们的关注。在稀疏化的混合专家语言模型中,大部分组件都与传统的 transformers 相同。然而,尽管看似简单,但经验表明,稀疏混合专家语言模型训练的稳定性还存在着一些问题。
像这样易于修改的小规模实现可能有助于快速试验新方法。Hugging Face 上的一篇博客介绍了一种可配置的小规模稀疏 MoE 实施方法,也许有助于打算在这个方向深耕的研究者们进行快速试验自己的新方法,并且给出了基于 PyTorch 的详细代码:https://github.com/AviSoori1x/makeMoE/tree/main
本文在 makemore 架构的基础上,进行了几处更改:
使用稀疏混合专家代替单独的前馈神经网络;
Top-k 门控和有噪声的 Top-k 门控;
参数初始化使用了 Kaiming He 初始化方法,但本文的重点是可以对初始化方法进行自定义,这样就可以在 Xavier/Glorot 等初始化中进行选择。
同时,以下模块与 makemore 保持一致:
数据集、预处理(分词)部分以及 Andrej 最初选择的语言建模任务 - 生成莎士比亚文风的文本内容
Casusal 自注意力机制
训练循环
推理逻辑
接下来逐步介绍实施方案,先从注意力机制开始。
因果缩放点积注意力机制
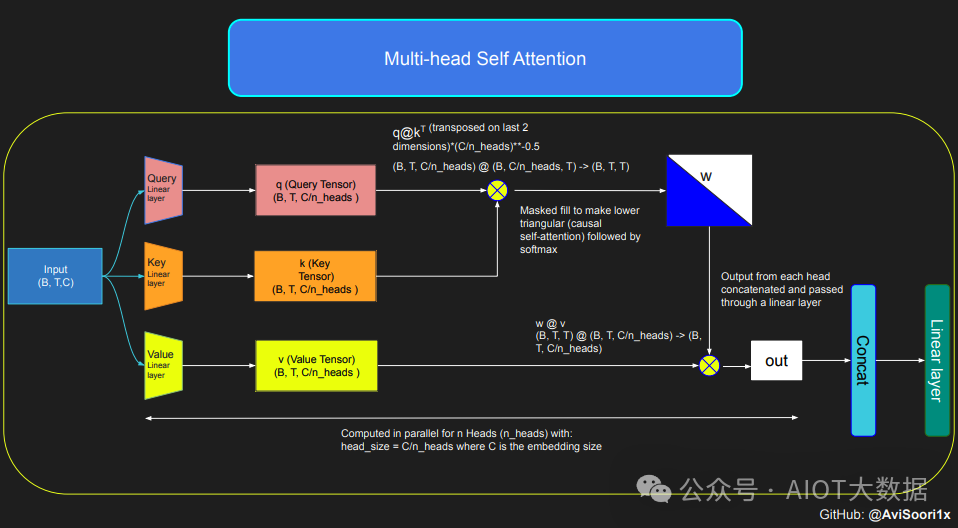
下面这段代码展示了自注意力机制的基本概念,并且侧重于使用经典的缩放点积自注意力(scaled dot product self-attention.)实现。在这一自注意力变体机制中,查询矩阵、键矩阵和值矩阵都来自相同的输入序列。同时为了确保自回归语言生成过程的完整性,特别是在纯解码器模型中,使用了一种掩码机制。
这种掩码机制非常关键,因为它可以掩盖当前 token 所处位置之后的任何信息,从而引导模型只关注序列的前面部分。这种了遮挡 token 后面内容的注意力被称为因果自注意力。值得注意的是,稀疏混合专家模型并不局限于仅有解码器的 Transformer 架构。事实上,这一领域的许多重要的成果都是围绕 T5 架构展开的,T5 架构也包含了 Transformer 模型中的编码器和解码器组件。
#This code is borrowed from Andrej Karpathy's makemore repository linked in the repo.The self attention layers in Sparse mixture of experts models are the same asin regular transformer models
torch.manual_seed(1337)B,T,C = 4,8,32 # batch, time, channelsx = torch.randn(B,T,C)
# let's see a single Head perform self-attentionhead_size = 16key = nn.Linear(C, head_size, bias=False)query = nn.Linear(C, head_size, bias=False)value = nn.Linear(C, head_size, bias=False)k = key(x) # (B, T, 16)q = query(x) # (B, T, 16)wei = q @ k.transpose(-2, -1) # (B, T, 16) @ (B, 16, T) ---> (B, T, T)
tril = torch.tril(torch.ones(T, T))#wei = torch.zeros((T,T))wei = wei.masked_fill(tril == 0, float('-inf'))wei = F.softmax(wei, dim=-1) #B,T,T
v = value(x) #B,T,Hout = wei @ v # (B,T,T) @ (B,T,H) -> (B,T,H)out.shape
torch.Size([4, 8, 16])
然后,因果自注意力和多头因果自注意力的代码可整理如下。多头自注意力并行应用多个注意力头,每个注意力头单独关注通道的一个部分(嵌入维度)。多头自注意力从本质上改善了学习过程,并由于其固有的并行能力提高了模型训练的效率。下面这段代码使用了 dropout 来进行正则化,来防止过拟合。
#Causal scaled dot product self-Attention Head
n_embd = 64
n_head = 4
n_layer = 4
head_size = 16
dropout = 0.1
class Head(nn.Module):
""" one head of self-attention """
def __init__(self, head_size):
super().__init__()
self.key = nn.Linear(n_embd, head_size, bias=False)
self.query = nn.Linear(n_embd, head_size, bias=False)
self.value = nn.Linear(n_embd, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B,T,C = x.shape
k = self.key(x) # (B,T,C)
q = self.query(x) # (B,T,C)
# compute attention scores ("affinities")
wei = q @ k.transpose(-2,-1) * C**-0.5 # (B, T, C) @ (B, C, T) -> (B, T, T)
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # (B, T, T)
wei = F.softmax(wei, dim=-1) # (B, T, T)
wei = self.dropout(wei)
# perform the weighted aggregation of the values
v = self.value(x) # (B,T,C)
out = wei @ v # (B, T, T) @ (B, T, C) -> (B, T, C)
return out
多头自注意力的实现方式如下:
#Multi-Headed Self Attention
class MultiHeadAttention(nn.Module):
""" multiple heads of self-attention in parallel """
def __init__(self, num_heads, head_size):
super().__init__()
self.heads = nn.ModuleList([Head(head_size) for _ in range(num_heads)])
self.proj = nn.Linear(n_embd, n_embd)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
out = torch.cat([h(x) for h in self.heads], dim=-1)
out = self.dropout(self.proj(out))
return out
创建一个专家模块
即一个简单的多层感知器
在稀疏混合专家架构中,每个 transformer 区块内的自注意力机制保持不变。不过,每个区块的结构发生了巨大的变化:标准的前馈神经网络被多个稀疏激活的前馈网络(即专家网络)所取代。所谓「稀疏激活」,是指序列中的每个 token 只被分配给有限数量的专家(通常是一个或两个)。
这有助于提高训练和推理速度,因为每次前向传递都会激活少数专家。不过,所有专家都必须存在 GPU 内存中,因此当参数总数达到数千亿甚至数万亿时,就会产生部署方面的问题。
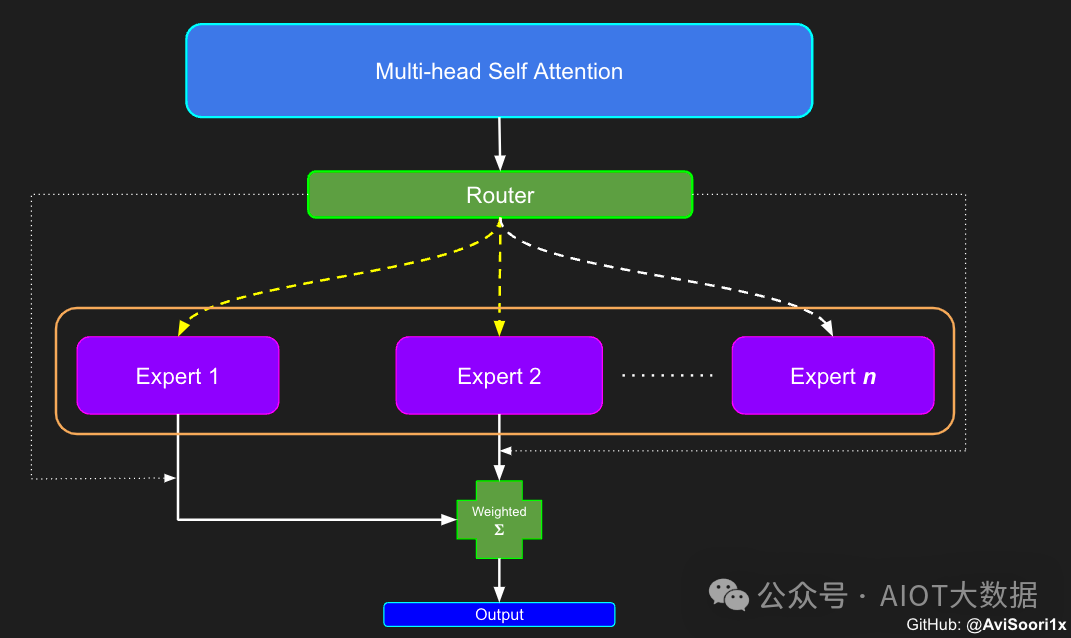
#Expert module
class Expert(nn.Module):
""" An MLP is a simple linear layer followed by a non-linearity i.e. each Expert """
def __init__(self, n_embd):
super().__init__()
self.net = nn.Sequential(
nn.Linear(n_embd, 4 * n_embd),
nn.ReLU(),
nn.Linear(4 * n_embd, n_embd),
nn.Dropout(dropout),
)
def forward(self, x):
return self.net(x)
Top-k 门控的一个例子
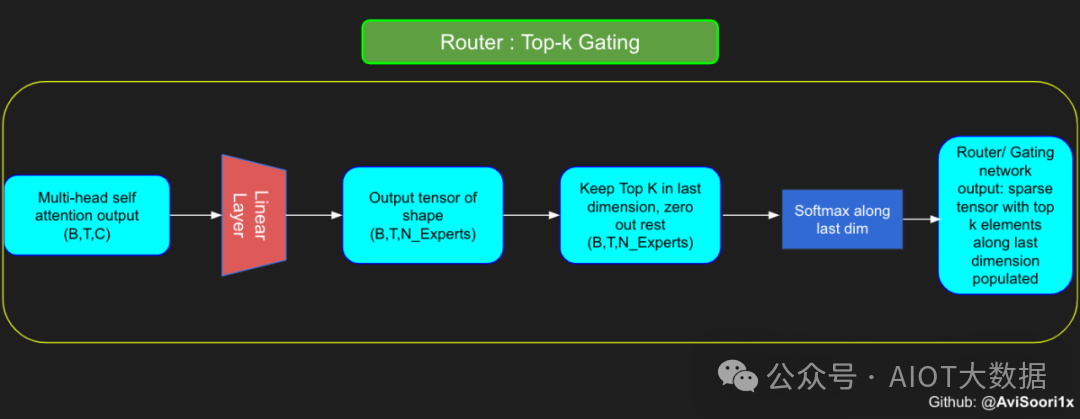
门控网络,也称为路由,确定哪个专家网络接收来自多头注意力的 token 的输出。举个例子解释路由的机制,假设有 4 个专家,token 需要被路由到前 2 个专家中。首先需要通过线性层将 token 输入到门控网络中。该层将对应于(Batch size,Tokens,n_embed)的输入张量从(2,4,32)维度,投影到对应于(Batch size、Tokens,num_expert)的新形状:(2、4,4)。其中 n_embed 是输入的通道维度,num_experts 是专家网络的计数。
接下来,沿最后一个维度,找出最大的前两个值及其相应的索引。
#Understanding how gating works
num_experts = 4
top_k=2
n_embed=32
#Example multi-head attention output for a simple illustrative example, consider n_embed=32, context_length=4 and batch_size=2
mh_output = torch.randn(2, 4, n_embed)
topkgate_linear = nn.Linear(n_embed, num_experts) # nn.Linear(32, 4)
logits = topkgate_linear(mh_output)
top_k_logits, top_k_indices = logits.topk(top_k, dim=-1) # Get top-k experts
top_k_logits, top_k_indices
#output:
(tensor([[[ 0.0246, -0.0190],
[ 0.1991, 0.1513],
[ 0.9749, 0.7185],
[ 0.4406, -0.8357]],
[[ 0.6206, -0.0503],
[ 0.8635, 0.3784],
[ 0.6828, 0.5972],
[ 0.4743, 0.3420]]], grad_fn=),
tensor([[[2, 3],
[2, 1],
[3, 1],
[2, 1]],
[[0, 2],
[0, 3],
[3, 2],
[3, 0]]]))
通过仅保留沿最后一个维度进行比较的前 k 大的值,来获得稀疏门控的输出。用负无穷值填充其余部分,在使用 softmax 激活函数。负无穷会被映射至零,而最大的前两个值会更加突出,且和为 1。要求和为 1 是为了对专家输出的内容进行加权。
zeros = torch.full_like(logits, float('-inf')) #full_like clones a tensor and fills it with a specified value (like infinity) for masking or calculations.
sparse_logits = zeros.scatter(-1, top_k_indices, top_k_logits)sparse_logits
#output
tensor([[[ -inf, -inf, 0.0246, -0.0190],
[ -inf, 0.1513, 0.1991, -inf],
[ -inf, 0.7185, -inf, 0.9749],
[ -inf, -0.8357, 0.4406, -inf]],
[[ 0.6206, -inf, -0.0503, -inf],
[ 0.8635, -inf, -inf, 0.3784],
[ -inf, -inf, 0.5972, 0.6828],
[ 0.3420, -inf, -inf, 0.4743]]], grad_fn=)
gating_output= F.softmax(sparse_logits, dim=-1)
gating_output
#ouput
tensor([[[0.0000, 0.0000, 0.5109, 0.4891],
[0.0000, 0.4881, 0.5119, 0.0000],
[0.0000, 0.4362, 0.0000, 0.5638],
[0.0000, 0.2182, 0.7818, 0.0000]],
[[0.6617, 0.0000, 0.3383, 0.0000],
[0.6190, 0.0000, 0.0000, 0.3810],
[0.0000, 0.0000, 0.4786, 0.5214],
[0.4670, 0.0000, 0.0000, 0.5330]]], grad_fn=)
使用有噪声的 top-k 门控以实现负载平衡
# First define the top k router module
class TopkRouter(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(TopkRouter, self).__init__()
self.top_k = top_k
self.linear =nn.Linear(n_embed, num_experts)
def forward(self, mh_ouput):
# mh_ouput is the output tensor from multihead self attention block
logits = self.linear(mh_output)
top_k_logits, indices = logits.topk(self.top_k, dim=-1)
zeros = torch.full_like(logits, float('-inf'))
sparse_logits = zeros.scatter(-1, indices, top_k_logits)
router_output = F.softmax(sparse_logits, dim=-1)
return router_output, indices
接下来使用下面这段代码来测试程序:
#Testing this out:
num_experts = 4
top_k = 2
n_embd = 32
mh_output = torch.randn(2, 4, n_embd) # Example input
top_k_gate = TopkRouter(n_embd, num_experts, top_k)
gating_output, indices = top_k_gate(mh_output)
gating_output.shape, gating_output, indices#
And it works!!
#output
(torch.Size([2, 4, 4]),
tensor([[[0.5284, 0.0000, 0.4716, 0.0000],
[0.0000, 0.4592, 0.0000, 0.5408],
[0.0000, 0.3529, 0.0000, 0.6471],
[0.3948, 0.0000, 0.0000, 0.6052]],
[[0.0000, 0.5950, 0.4050, 0.0000],
[0.4456, 0.0000, 0.5544, 0.0000],
[0.7208, 0.0000, 0.0000, 0.2792],
[0.0000, 0.0000, 0.5659, 0.4341]]], grad_fn=),
tensor([[[0, 2],
[3, 1],
[3, 1],
[3, 0]],
[[1, 2],
[2, 0],
[0, 3],
[2, 3]]]))
尽管最近发布的 mixtral 的论文没有提到这一点,但本文的作者相信有噪声的 Top-k 门控机制是训练 MoE 模型的一个重要工具。从本质上讲,不会希望所有的 token 都发送给同一组「受欢迎」的专家网络。人们需要的是能在开发和探索之间取得良好平衡。为此,为了负载平衡,从门控的线性层向 logits 激活函数添加标准正态噪声是有帮助的,这使训练更有效率。
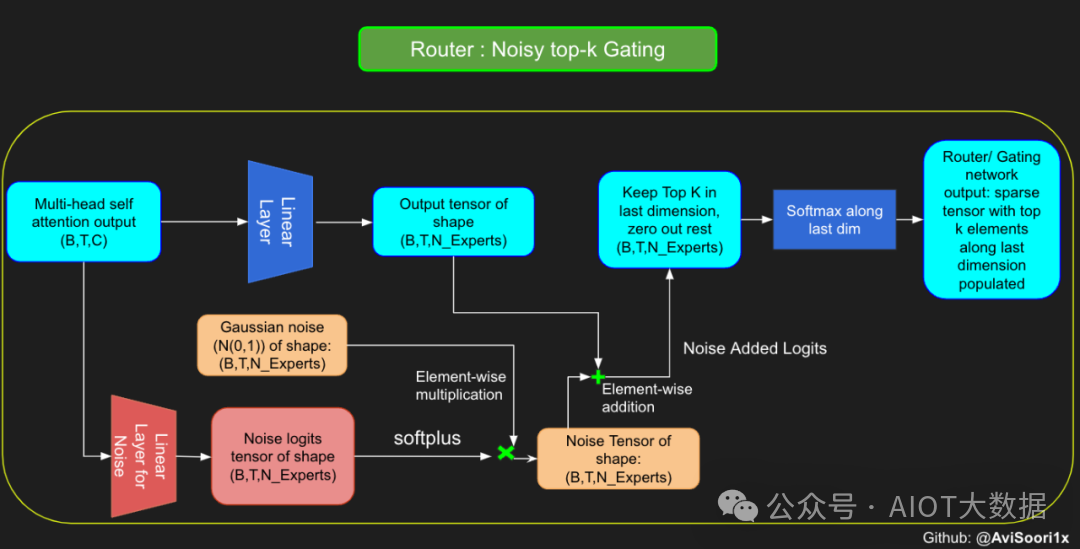
#Changing the above to accomodate noisy top-k gating
class NoisyTopkRouter(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(NoisyTopkRouter, self).__init__()
self.top_k = top_k
#layer for router logits
self.topkroute_linear = nn.Linear(n_embed, num_experts)
self.noise_linear =nn.Linear(n_embed, num_experts)
def forward(self, mh_output):
# mh_ouput is the output tensor from multihead self attention block
logits = self.topkroute_linear(mh_output)
#Noise logits
noise_logits = self.noise_linear(mh_output)
#Adding scaled unit gaussian noise to the logits
noise = torch.randn_like(logits)*F.softplus(noise_logits)
noisy_logits = logits + noise
top_k_logits, indices = noisy_logits.topk(self.top_k, dim=-1)
zeros = torch.full_like(noisy_logits, float('-inf'))
sparse_logits = zeros.scatter(-1, indices, top_k_logits)
router_output = F.softmax(sparse_logits, dim=-1)
return router_output, indices
再次尝试代码:
#Testing this out, again:
num_experts = 8
top_k = 2
n_embd = 16
mh_output = torch.randn(2, 4, n_embd) # Example input
noisy_top_k_gate = NoisyTopkRouter(n_embd, num_experts, top_k)
gating_output, indices = noisy_top_k_gate(mh_output)
gating_output.shape, gating_output, indices
#It works!!
#output
(torch.Size([2, 4, 8]),
tensor([[[0.4181, 0.0000, 0.5819, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.4693, 0.5307, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.4985, 0.5015, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.2641, 0.0000, 0.7359, 0.0000, 0.0000]],
[[0.0000, 0.0000, 0.0000, 0.6301, 0.0000, 0.3699, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000, 0.4766, 0.0000, 0.0000, 0.0000, 0.5234],
[0.0000, 0.0000, 0.0000, 0.6815, 0.0000, 0.0000, 0.3185, 0.0000],
[0.4482, 0.5518, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000]]],
grad_fn=),
tensor([[[2, 0],
[1, 0],
[2, 1],
[5, 3]],
[[3, 5],
[7, 3],
[3, 6],
[1, 0]]]))
创建稀疏化的混合专家模块
在获得门控网络的输出结果之后,对于给定的 token,将前 k 个值选择性地与来自相应的前 k 个专家的输出相乘。这种选择性乘法的结果是一个加权和,该加权和构成 SparseMoe 模块的输出。这个过程的关键和难点是避免不必要的乘法运算,只为前 k 名专家进行正向转播。为每个专家执行前向传播将破坏使用稀疏 MoE 的目的,因为这个过程将不再是稀疏的。
class SparseMoE(nn.Module):
def __init__(self, n_embed, num_experts, top_k):
super(SparseMoE, self).__init__()
self.router = NoisyTopkRouter(n_embed, num_experts, top_k)
self.experts = nn.ModuleList([Expert(n_embed) for _ in range(num_experts)])
self.top_k = top_k
def forward(self, x):
gating_output, indices = self.router(x)
final_output = torch.zeros_like(x)
# Reshape inputs for batch processing
flat_x = x.view(-1, x.size(-1))
flat_gating_output = gating_output.view(-1, gating_output.size(-1))
# Process each expert in parallel
for i, expert in enumerate(self.experts):
# Create a mask for the inputs where the current expert is in top-k
expert_mask = (indices == i).any(dim=-1)
flat_mask = expert_mask.view(-1)
if flat_mask.any():
expert_input = flat_x[flat_mask]
expert_output = expert(expert_input)
# Extract and apply gating scores
gating_scores = flat_gating_output[flat_mask, i].unsqueeze(1)
weighted_output = expert_output * gating_scores
# Update final output additively by indexing and adding
final_output[expert_mask] += weighted_output.squeeze(1)
return final_output
运行以下代码来用样本测试上述实现,可以看到确实如此!
import torch
import torch.nn as nn
#Let's test this outnum_experts = 8
top_k = 2
n_embd = 16
dropout=0.1
mh_output = torch.randn(4, 8, n_embd) # Example multi-head attention output
sparse_moe = SparseMoE(n_embd, num_experts, top_k)
final_output = sparse_moe(mh_output)
print("Shape of the final output:", final_output.shape)
Shape of the final output: torch.Size([4, 8, 16])
需要强调的是,如上代码所示,从路由 / 门控网络输出的 top_k 本身也很重要。索引确定了被激活的专家是哪些, 对应的值又决定了权重大小。下图进一步解释了加权求和的概念。
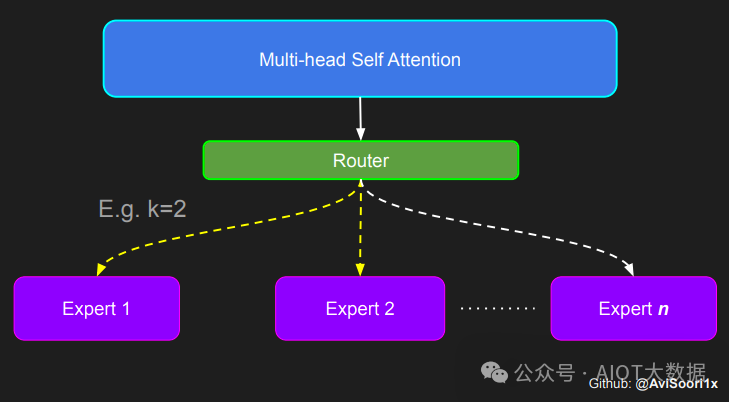
模块整合
将多头自注意力和稀疏混合专家相结合,形成稀疏混合专家 transformer 块。就像在 vanilla transformer 块中一样,也要使用残差以确保训练稳定,并避免梯度消失等问题。此外,要采用层归一化来进一步稳定学习过程。
#Create a self attention + mixture of experts block, that may be repeated several number of times
class Block(nn.Module):
""" Mixture of Experts Transformer block: communication followed by computation (multi-head self attention + SparseMoE) """
def __init__(self, n_embed, n_head, num_experts, top_k):
# n_embed: embedding dimension, n_head: the number of heads we'd like
super().__init__()
head_size = n_embed // n_head
self.sa = MultiHeadAttention(n_head, head_size)
self.smoe = SparseMoE(n_embed, num_experts, top_k)
self.ln1 = nn.LayerNorm(n_embed)
self.ln2 = nn.LayerNorm(n_embed)
def forward(self, x):
x = x + self.sa(self.ln1(x))
x = x + self.smoe(self.ln2(x))
return x
最后,将所有内容整合在一起,形成稀疏混合专家语言模型。
class SparseMoELanguageModel(nn.Module):
def __init__(self):
super().__init__()
# each token directly reads off the logits for the next token from a lookup table
self.token_embedding_table = nn.Embedding(vocab_size, n_embed)
self.position_embedding_table = nn.Embedding(block_size, n_embed)
self.blocks = nn.Sequential(*[Block(n_embed, n_head=n_head, num_experts=num_experts,top_k=top_k) for _ in range(n_layer)])
self.ln_f = nn.LayerNorm(n_embed) # final layer norm
self.lm_head = nn.Linear(n_embed, vocab_size)
def forward(self, idx, targets=None):
B, T = idx.shape
# idx and targets are both (B,T) tensor of integers
tok_emb = self.token_embedding_table(idx) # (B,T,C)
pos_emb = self.position_embedding_table(torch.arange(T, device=device)) # (T,C)
x = tok_emb + pos_emb # (B,T,C)
x = self.blocks(x) # (B,T,C)
x = self.ln_f(x) # (B,T,C)
logits = self.lm_head(x) # (B,T,vocab_size)
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx is (B, T) array of indices in the current context
for _ in range(max_new_tokens):
# crop idx to the last block_size tokens
idx_cond = idx[:, -block_size:]
# get the predictions
logits, loss = self(idx_cond)
# focus only on the last time step
logits = logits[:, -1, :] # becomes (B, C)
# apply softmax to get probabilities
probs = F.softmax(logits, dim=-1) # (B, C)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1) # (B, 1)
# append sampled index to the running sequence
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx
参数初始化对于深度神经网络的高效训练非常重要。由于专家中存在 ReLU 激活,因此这里使用了 Kaiming He 初始化。也可以尝试在 transformer 中更常用的 Glorot 初始化。杰里米 - 霍华德(Jeremy Howard)的《Fastai》第 2 部分有一个从头开始实现这些功能的精彩讲座:https://course.fast.ai/Lessons/lesson17.html
Glorot 参数初始化通常被用于 transformer 模型,因此这是一个可能提高模型性能的方法。
def kaiming_init_weights(m):
if isinstance (m, (nn.Linear)):
init.kaiming_normal_(m.weight)
model = SparseMoELanguageModel()
model.apply(kaiming_init_weights)
本文作者使用 mlflow 跟踪并记录重要指标和训练超参数。
#Using MLFlow
m = model.to(device)
# print the number of parameters in the modelprint(sum(p.numel() for p in m.parameters())/1e6, 'M parameters')
# create a PyTorch optimizer
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
#mlflow.set_experiment("makeMoE")with mlflow.start_run():
#If you use mlflow.autolog() this will be automatically logged. I chose to explicitly log here for completeness
params = {"batch_size": batch_size , "block_size" : block_size, "max_iters": max_iters, "eval_interval": eval_interval, "learning_rate": learning_rate, "device": device, "eval_iters": eval_iters, "dropout" : dropout, "num_experts": num_experts, "top_k": top_k } mlflow.log_params(params) for iter in range(max_iters):
# every once in a while evaluate the loss on train and val sets
if iter % eval_interval == 0 or iter == max_iters - 1:
losses = estimate_loss()
print(f"step {iter}: train loss {losses['train']:.4f}, val loss {losses['val']:.4f}")
metrics = {"train_loss": losses['train'], "val_loss": losses['val']}
mlflow.log_metrics(metrics, step=iter)
# sample a batch of data
xb, yb = get_batch('train')
# evaluate the loss
logits, loss = model(xb, yb)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
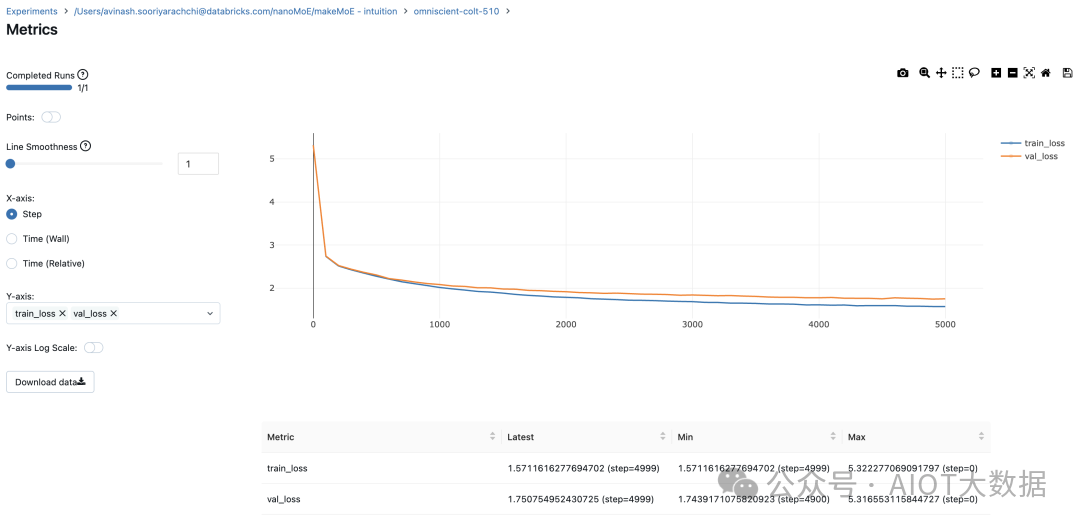
8.996545 M parameters
step 0: train loss 5.3223, val loss 5.3166
step 100: train loss 2.7351, val loss 2.7429
step 200: train loss 2.5125, val loss 2.5233...
.
.
step 4999: train loss 1.5712, val loss 1.7508
记录训练和验证损失可以很好地指示训练的进展情况。该图显示,可能应该在 4500 次时停止(当验证损失稍微增加时)
接下来可以使用这个模型逐字符自回归地生成文本。
# generate from the model. Not great. Not too bad either
context = torch.zeros((1, 1), dtype=torch.long, device=device)
print(decode(m.generate(context, max_new_tokens=2000)[0].tolist()))
DUKE VINCENVENTIO:
If it ever fecond he town sue kigh now,
That thou wold'st is steen 't.
SIMNA:
Angent her; no, my a born Yorthort,
Romeoos soun and lawf to your sawe with ch a woft ttastly defy,
To declay the soul art; and meart smad.
CORPIOLLANUS:
Which I cannot shall do from by born und ot cold warrike,
What king we best anone wrave's going of heard and good
Thus playvage; you have wold the grace
....
审核编辑:黄飞











 工商网监
工商网监
评论