 电子发烧友App
电子发烧友App


妙手、本手还是俗手?
昨夜,谷歌罕见地改变了去年坚持的“大模型闭源”策略,推出了“开源”大模型 Gemma。
Gemma 采用了与 Gemini 相同的技术,由谷歌 DeepMind 与谷歌其他团队共同合作开发,在拉丁文中意为 “宝石”。
Gemma 包括两种权重规模的模型:Gemma 2B 与 Gemma 7B,每种规模都有预训练与指令微调版本。同时,谷歌还推出了一系列工具,旨在支持开发者创新,促进合作,并指导如何负责任地使用 Gemma 模型。
这样一来,谷歌在大模型领域形成了双线作战——闭源领域对抗 OpenAI,开源领域对抗 Meta。
在人工智能领域,谷歌可以算是开源的鼻祖。今天几乎所有的大语言模型,都基于谷歌在 2017 年发布的 Transformer 论文;谷歌的发布的 BERT、T5,都是最早的一批开源 AI 模型。
然而,自从 OpenAI 在 2022 年底发布闭源的 ChatGPT,谷歌也开始转向闭源策略。此后,开源大模型被 Meta 的Llama 主导,后来被称为“欧洲版 OpenAI”的法国开源大模型公司 Mistral AI 走红,其 MoE 模型也被众多 AI 公司追捧。
无论在闭源还是开源领域,有世界上最前沿技术储备与人才储备的谷歌,都没能确立绝对的领先地位。
如今,闭源与开源双线作战,这是谷歌的妙手、本手还是俗手?
1.谷歌被迫开源?
谷歌开源大模型的发布时间,比 Meta 的 Llama 晚了整整一年。
对此,出门问问创始人李志飞表示:“相比于去年上半年就开源,现在可能要花数倍的努力进行模型的差异化以及推广的投入、才有可能在众多开源模型中脱颖而出。”
同时,李志飞认为谷歌的开源力度也不够,还是被动防御和扭扭捏捏的应对之策,不是进攻。“比如说,开个7B的模型实在是太小儿科了,一点杀伤力都没有。应该直接开源一个超越市场上所有开源的至少 100B 的模型、1M 的超长上下文、完善的推理 infra 方案、外加送一定的 cloud credit。是的,再不歇斯底里 Google 真的就晚了。面对 OpenAI 的强力竞争,只有杀敌一千、自损一千五。”
李志飞感觉,谷歌觉得自己还是 AI 王者,放不下高贵的头颅,很多发布都有点不痛不痒,还是沿着过去研发驱动的老路而不是产品和竞争驱动,比如说不停发论文、取新名字(多模态相关模型过去半年就发了 Palme、rt-2、Gemini、VideoPoet、W.A.L.T 等等)、发布的模型又完整度不够,感觉就没有一个绝对能打的产品。谷歌可能要意识到在公众眼中,他在 AI 领域已经是廉颇老矣溃不成军,经常起大早赶晚集(比如说这次 Sora 借鉴的 ViT、ViViT、NaVit、MAGVit 等核心组件技术都是它家写的论文)。
但作为前谷歌总部科学家,李志飞也希望谷歌希望亡羊补牢未为晚。他表示:“Google 作为一个僵化的大公司,动作慢一点可以理解,但是如果再不努力是不是就是 PC 互联网的 IBM、移动互联网的 Microsoft ? 作为 Google 的铁粉,还是希望他能打起精神一战,AI 产业需要强力的竞争才能不停往前发展,也需要他在前沿研究和系统的开源才能帮助一大众贫穷的 AI 创业公司。”
另一位 AI 专家——微博新技术研发负责人张俊林认为,谷歌重返开源赛场,这是个大好事,但很明显是被迫的。
张俊林表示:“去年 Google 貌似已经下定决心要闭源了,这可能源于低估了追赶 OpenAI 的技术难度,Bard 推出令人大失所望使得谷歌不得不面对现实,去年下半年进入很尴尬的局面,闭源要追上 OpenAI 估计还要不少时间,而开源方面 Meta 已下决心,还有 Mistral 这种新秀冒头,逐渐主导了开源市场。这导致无论开源闭源,谷歌都处于被两面夹击,进退为难的境地。”
很明显,Gemma 代表谷歌大模型策略的转变:兼顾开源和闭源,开源主打性能最强大的小规模模型,希望脚踢 Meta 和 Mistral;闭源主打规模大的效果最好的大模型,希望尽快追上 OpenAI。
大模型到底要做开源还是闭源?
张俊林的判断是,如果是做当前最强大的大模型,目前看还是要拼模型规模,这方面开源模型相对闭源模型处于明显劣势,短期内难以追上 GPT-4 或 GPT-4V。而且这种类型的大模型,即使是开源,也只能仰仗谷歌或者 Meta 这种财大气粗的大公司,主要是太消耗资源了,一般人玩不起。国内这方面阿里千问系列做得比较好,肯把比较大规模的模型开源出来,当然肯定不是最好的,不过这也很难得了。
而在开源领域,张俊林的判断是应该把主要精力放在开发并开源出性能足够强的“小规模大模型”上(SLLM,Small Large Language Model),因此谷歌的开源策略是非常合理的。
目前看,作出强大的 SLLM 并没有太多技巧,主要是把模型压小的基础上,大量增加训练数据的规模,数据质量方面则是增加数学、代码等数据来提升模型的推理能力。比如 Gemma 7B 用 6 万亿 Token 数据,外界猜测 Mistral 7B 使用了 7 万亿 Token 数据,两者也应该大量采用了增强推理能力的训练数据。
所以 SLLM 模型的性能天花板目前也没有到头,只要有更多更高质量的数据,就能持续提升 SLLM 模型的效果,仍然有很大空间。
而且 SLLM 相对 GPT-4 这种追求最强效果的模型比,训练成本低得多,而因为模型规模小,推理成本也极低,只要持续优化效果,从应用层面,大家肯定会比较积极地部署 SLLM 用来实战的,市场潜力巨大。也就是说,SLLM 应该是没有太多资源,但是还是有一些资源的大模型公司必争之地。
张俊林相信,2024 年开源 SLLM 会有黑马出现。
2.大模型打压链
从今天起,Gemma 在全球范围内开放使用。该模型的关键细节如下:
发布了两种权重规模的模型:Gemma 2B 和 Gemma 7B。每种规模都有预训练和指令微调版本。
新的 Responsible Generative AI Toolkit 为使用 Gemma 创建更安全的 AI 应用程序提供指导和必备工具。
通过原生 Keras 3.0 为所有主要框架(JAX、PyTorch 和 TensorFlow)提供推理和监督微调(SFT)的工具链。
上手即用 Colab 和 Kaggle notebooks,以及与 Hugging Face、MaxText 和 NVIDIA NeMo 等受欢迎的工具集成,让开始使用 Gemma 变得简单容易。
经过预训练和指令微调的 Gemma 模型可以在笔记本电脑、工作站或 Google Cloud 上运行,并可轻松部署在 Vertex AI 和 Google Kubernetes Engine(GKE)上。
基于多个 AI 硬件平台进行优化,其中包括 NVIDIA GPUs 和 Google Cloud TPUs。
使用条款允许所有组织(无论规模大小)负责任地进行商用和分发。
Gemma 是开源领域一股不可忽视的力量。根据谷歌给出的数据,性能超越 Llama 2。
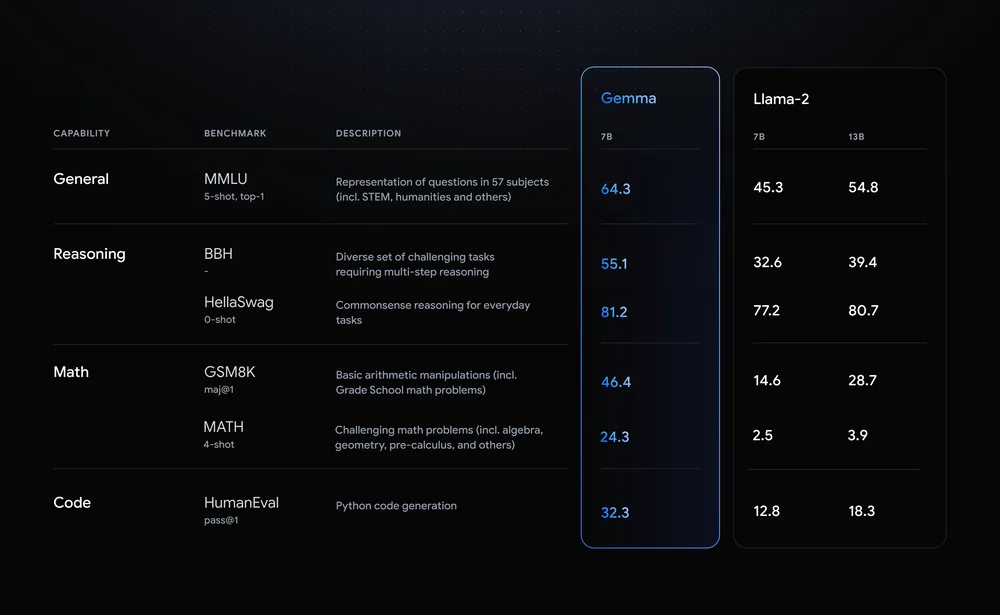
图片来自谷歌
至此,大模型开源形成三巨头局面:谷歌 Gemma、Meta LLama 和欧洲的 Mistral。 张俊林认为,大模型巨头混战形成了打压链局面:OpenAI 处于链条顶端,主要打压对手是有潜力追上它的竞争对手:谷歌和 Anthropic,Mistral 估计也正在被列入 OpenAI 的打压列表中。打压链条为:OpenAI→Google &Anthropic & Mistral→ Meta→其它大模型公司。 比如,谷歌上周发布的 Gemini 1.5 Pro 就是一个有代表性的案例,本身模型实例很强大,但在宣发策略上被 Sora 打到哑火;前年年底发布的 ChatGPT 也是临时赶工出来打压 Anthropic 的 Claude 模型的。
张俊林对此判断:“OpenAI 应该储备了一个用于打压对手的技术储备库,即使做得差不多了也隐而不发,专等竞争对手发布新产品的时候扔出来,以形成宣传优势。如果 OpenAI 判断对手的产品对自己的威胁越强,就越可能把技术储备库里最强的扔出来,比如 ChatGPT 和 Sora,都是大杀器级别的,这也侧面说明 OpenAI 比较认可 Gemini 1.5 和 Claude 的实力。而这种打压策略很明显还会继续下去,以后我们仍然会经常看到类似的情景,不巧的是,可能其它公司比如谷歌也学会这招了,估计也很快会传导到国内大模型公司范围里。所以 2024 年会比较热闹,估计会有不少大戏上演。” 谷歌开源 Gemma 很明显是针对 Meta 和 Mistral 而来。张俊林据此推测,Meta 的 LLama 3 很快就要发布了,或者Mistral 最近会有新品发布。
审核编辑:黄飞














 工商网监
工商网监
评论