 电子发烧友App
电子发烧友App


最近,GPT-4V 等视觉语言模型(VLM)在各种视觉语言任务中取得了令人难以置信的进步。我们深入研究了基于视觉的演绎推理这一更为复杂但探索较少的领域,并发现了当前 SOTA 视觉语言模型中尚未暴露的盲点。具体来说,我们利用Raven's Progressive Matrices(RPM)来评估 VLM 仅依靠视觉线索进行多跳multi-hop关系和演绎推理的能力。
我们在三个不同的数据集(包括 Mensa IQ 测试、IntelligenceTest 和 RAVEN)上对几种流行的 VLM 进行了全面评估,这些 VLM 采用了标准策略,如上下文学习、自我一致性(SC)和思维链(CoT)。结果表明,尽管 LLM 在文本推理方面的能力令人印象深刻,但我们在视觉演绎推理方面仍远未达到可比的熟练程度。我们发现,某些在 LLMs 中有效的标准策略并不能完美地应对视觉推理任务带来的挑战。此外,详细的分析表明,VLMs 在解决这些任务时之所以举步维艰,主要是因为他们无法感知和理解 RPM 示例中多种混淆的抽象模式。
https://arxiv.org/abs/2403.04732

Q1: 这篇论文试图解决什么问题?
A:这篇论文试图解决的问题是评估和理解当前最先进的视觉-语言模型(Vision-Language Models, VLMs)在视觉推理任务上的性能,特别是在需要复杂视觉推理能力的挑战性任务上。具体来说,研究者们通过使用Raven's Progressive Matrices(RPMs)问题来测试VLMs在仅依赖视觉线索进行多跳关系和演绎推理的能力。这些任务要求模型能够理解给定的模式、推导出潜在的规则,并使用这些规则来选择缺失模式的正确选项。论文的目标是揭示VLMs在视觉演绎推理方面的局限性,并探讨如何提高它们在这一领域的性能。
Q2: 有哪些相关研究?
A:相关研究包括以下几个方面:
通用大型语言模型(LLM)推理基准:研究者们介绍了多种基于文本的推理任务和基准,用于评估LLMs在不同领域(如常识、数学推理、常识推理、事实推理和编程)的性能。这些研究包括BIG-bench、HELM、SuperGLUE和LAMA等。
视觉推理评估:先前的工作主要集中在视觉问答(VQA)和图像描述等任务上,这些任务涉及回答有关图像的问题或生成视觉内容的自然语言描述。研究人员还检查了模型理解图像中对象的关系和组合方面的能力。CLEVR和SHAPES等数据集评估了计数、比较、逻辑推理和记忆存储等视觉推理能力。
演绎推理:在文本和视觉领域都进行了演绎推理评估和基准测试。例如,GuessWhat?!和ReferIt评估了模型的视觉推理能力。最近,LMRL Gym和Entity Deduction Arena被引入作为评估LLMs执行多轮演绎推理任务的能力的方法。ARC任务与RPMs相似,都需要根据给定的例子正确推断未见的输出。
视觉-语言模型(VLMs)的发展:随着VLMs在视觉推理方面的能力发展,基准测试也在不断进步。新的基准测试,如MMMU和MathVista,测试了模型在图像和视频中模拟人类对场景和对象理解的能力,包括场景文本理解、公式、图表解释、视觉刺激理解、几何推理、空间推理和面部表情理解与推理。
这些研究为评估VLMs在视觉演绎推理任务上的性能提供了背景和基础,同时也指出了当前模型在这一领域的局限性。
Q3: 论文如何解决这个问题?

A:论文通过以下步骤来解决视觉演绎推理的问题:
建立评估框架:研究者们建立了一个系统性的评估框架,用于评估VLMs在RPM问题上的性能。他们选择了包括Mensa IQ测试、IntelligenceTest和RAVEN在内的多样化数据集,并在这些数据集上评估了多个流行的开源和闭源VLMs。
应用标准策略:研究者们尝试了在大型语言模型(LLMs)中有效的标准推理时策略,**如上下文学习(in-context learning)和自我一致性(self-consistency),以探索这些策略在VLMs中的潜力。**
性能瓶颈分析:通过将VLMs的能力分解为感知、演绎推理和假设验证三个部分,研究者们详细诊断了VLMs在RPM任务中的性能瓶颈。他们发现感知是当前VLMs的限制因素,并提供了一个案例研究来突出强VLMs(如GPT-4V)中的特定“盲点”。
问题识别与分析:研究者们识别并检查了当前VLMs在这项任务中的几个问题,包括过度自信、对提示设计的敏感性以及无法有效利用上下文示例。他们通过消融实验研究了不同提示对模型整体性能的影响,并发现模型可以从更结构化的提示中受益。
实验设置:研究者们详细描述了实验设置,包括使用的数据集、比较的模型以及用于生成响应的提示方法。
结果评估:研究者们展示了不同VLMs在各个数据集上的表现,并分析了模型预测的不确定性。他们还探讨了标准策略在视觉演绎推理中的有效性,并讨论了VLMs在感知、推理和假设验证方面的表现。
结论与未来工作:最后,研究者们总结了VLMs在视觉演绎推理任务上的局限性,并提出了未来工作的方向,包括验证VLMs在描述模式时的盲点,以及探索对比学习或强化学习算法来提高模型的视觉演绎推理能力。
通过这些步骤,论文不仅揭示了VLMs在视觉演绎推理方面的当前能力,还为如何改进这些模型提供了见解和建议。
Q4: 论文做了哪些实验?

A:论文中进行的实验主要包括以下几个方面:
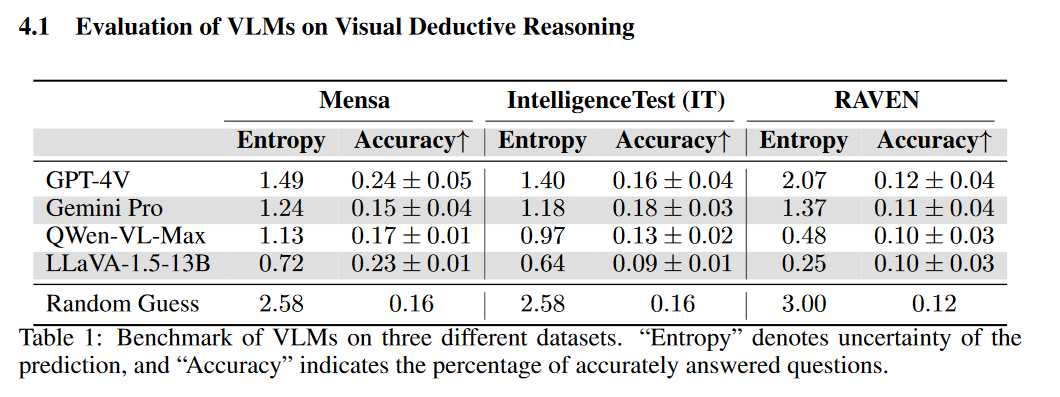
数据集评估:研究者们使用了三个不同的Raven's Progressive Matrices (RPMs) 数据集,包括Mensa IQ测试、IntelligenceTest和RAVEN,来评估多个流行的视觉-语言模型(VLMs)的性能。这些数据集涵盖了不同的难度级别和视觉模式。
模型比较:比较了多种代表最先进水平的VLMs,包括GPT-4V、Gemini-pro、Qwen-VL-Max和LLaVA-1.5-13B。这些模型在不同的数据集上进行了性能测试,以评估它们在视觉推理任务上的能力。
推理策略测试:尝试了在大型语言模型(LLMs)中有效的标准推理策略,如上下文学习(in-context learning)和自我一致性(self-consistency),以探究这些策略在VLMs中的效果。
性能瓶颈分析:通过将VLMs的能力分解为感知、演绎推理和假设验证三个部分,研究者们对VLMs在RPM任务中的性能瓶颈进行了详细分析。
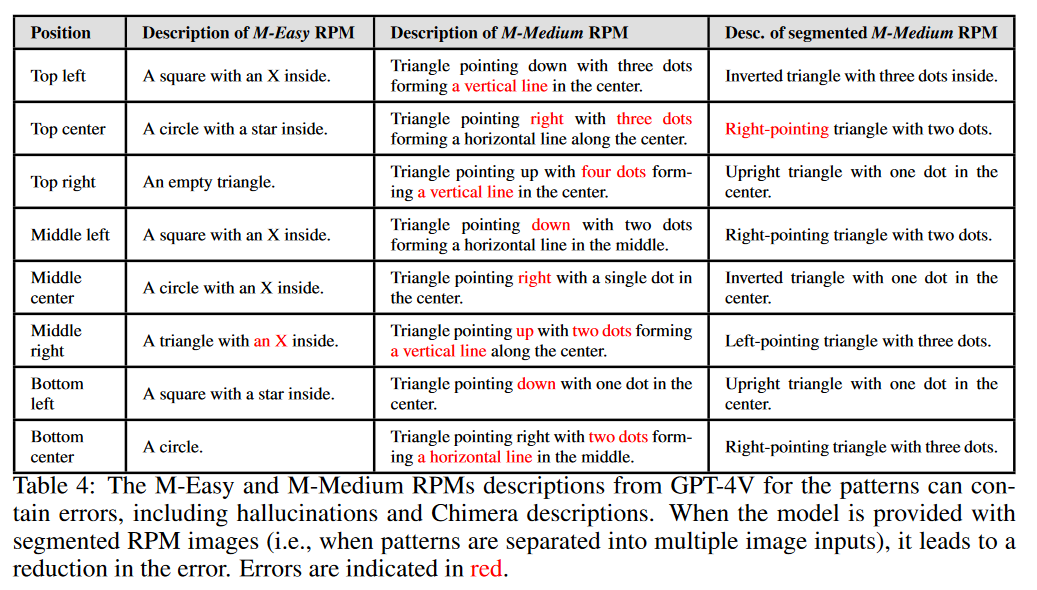
感知能力测试:评估了VLMs在理解RPM图像模式方面的能力,包括对图像的描述准确性和对模式的识别。
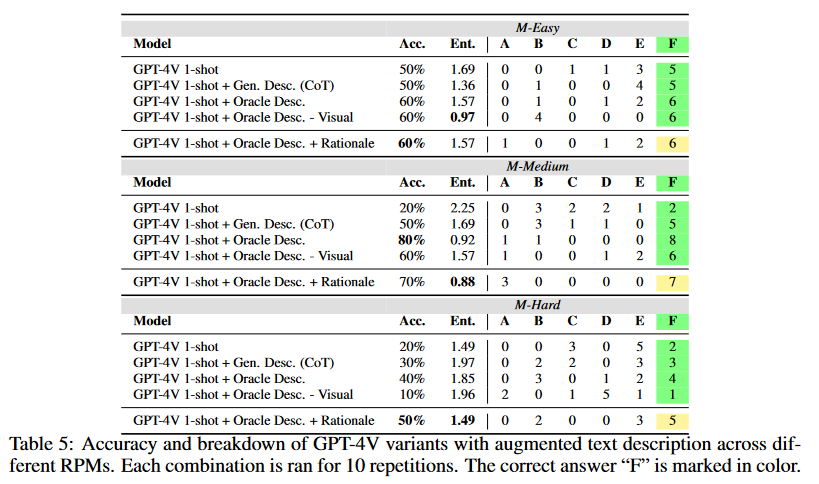
演绎推理能力测试:通过提供正确的文本描述(oracle descriptions)来测试模型在给定正确信息的情况下的推理能力。
假设验证能力测试:测试了模型在接收到正确的描述和推理(oracle rationale)后,能否有效地生成假设并验证这些假设。
提示格式影响测试:研究了提示的结构(如图像和文本的顺序)如何影响模型的预测性能。
错误描述处理:测试了模型在接收到自身生成的错误文本描述时,是否能够进行有效的推理。
这些实验旨在全面评估VLMs在视觉演绎推理任务上的能力,并识别它们在这一领域的局限性。通过这些实验,研究者们能够深入了解VLMs在视觉推理方面的性能,并为未来的改进提供了方向。
Q5: 有什么可以进一步探索的点?
A:论文提出了几个可以进一步探索的点:
模型训练数据的改进:研究者们提到,VLMs可能主要在真实世界图像上进行训练,这可能导致它们对抽象模式的敏感性降低。未来的工作可以探索在更多样化的RPM数据上进行微调,以提高模型对抽象模式的识别能力。
对比学习和强化学习算法:为了提高VLMs的视觉演绎推理能力,可以探索开发对比学习或强化学习算法,这些算法可能有助于模型更好地理解和推理视觉模式。
感知和推理的结合:研究者们发现,当任务涉及复杂的空间布局和关系推理时,文本信息可能不足以提供最佳性能,而视觉线索可能提供额外的对齐和更好的比较注意力。未来的研究可以探索如何更有效地结合视觉信息和文本线索。
提示结构的优化:论文中提到,VLMs对提示的结构非常敏感。未来的工作可以进一步研究如何设计更有效的提示结构,以提高模型在视觉推理任务上的性能。
模型的不确定性校准:研究者们观察到,即使在预测不确定性较高时,模型也倾向于提供确定性的答案,而不是表达不确定性。未来的研究可以探索如何改进模型的不确定性校准,使其在面对不确定性时能够更准确地表达其置信度。
模型的泛化能力:RPM任务要求模型具有强大的泛化能力,因为每个问题可能有不同的潜在规则。未来的工作可以探索如何提高VLMs在这种少样本学习任务中的泛化能力。
模型的解释能力:研究者们发现,模型在生成解释时可能会产生错误,特别是在复杂任务中。未来的研究可以探索如何提高模型的解释能力,使其能够更准确地生成与视觉线索相匹配的解释。
这些探索点为VLMs在视觉演绎推理领域的未来发展提供了潜在的研究方向。
Q6: 总结一下论文的主要内容?
A:这篇论文的主要内容可以总结如下:
研究背景:论文探讨了视觉-语言模型(VLMs)在视觉推理任务上的性能,特别是Raven's Progressive Matrices(RPMs)这类需要复杂视觉演绎推理的任务。
研究目标:旨在评估VLMs在视觉演绎推理任务上的能力,并识别当前模型的局限性。
实验设计:使用Mensa IQ测试、IntelligenceTest和RAVEN数据集,对多个流行的VLMs进行了全面评估。实验包括了标准策略的应用,如上下文学习和自我一致性。
主要发现:
**VLMs在文本推理任务上表现出色,但在视觉推理任务上仍有显著差距。**
某些在LLMs中有效的策略在VLMs中并不总是有效。
VLMs在感知、演绎推理和假设验证方面存在性能瓶颈,尤其是感知能力。
问题分析:通过详细分析,研究者们发现VLMs在处理RPM任务时,主要问题在于无法准确感知和理解多个复杂的抽象模式。
策略测试:测试了在LLMs中有效的策略在VLMs中的有效性,发现这些策略并不总是能够提高VLMs的性能。
性能提升:研究者们提出了一些可能的改进方向,包括在更多样化的RPM数据上进行微调,以及开发对比学习和强化学习算法。
结论:尽管VLMs在视觉推理任务上取得了一定的进展,但与人类水平相比仍有较大差距。未来的研究需要进一步探索如何提高VLMs在这一领域的性能。
总的来说,这篇论文提供了对VLMs在视觉演绎推理任务上性能的深入分析,并为未来的研究方向提供了指导。
审核编辑:黄飞












 工商网监
工商网监
评论