求一个simulink的蓄电池用BP神经网络PID控制电机加速匀速减速运动的模型仿真
2020-02-22 02:17:03
一文看懂BP神经网络的基础数学知识
2020-06-16 07:14:35
03_深度学习入门_神经网络和反向传播算法
2019-09-12 07:08:05
网络BP算法的程序设计 多层前向网络BP算法源程序 第4章 Hopfield网络模型 4.1 离散型Hopfield神经网络 4.2 连续型Hopfield神经网络 Hopfield网络模型
2012-03-20 11:32:43
MATLAB神经网络工具箱函数说明:本文档中所列出的函数适用于MATLAB5.3以上版本,为了简明起见,只列出了函数名,若需要进一步的说明,请参阅MATLAB的帮助文档。1. 网络创建函数newp
2009-09-22 16:10:08
请问:我在用labview做BP神经网络实现故障诊断,在NI官网找到了机器学习工具包(MLT),但是里面没有关于这部分VI的帮助文档,对于”BP神经网络分类“这个范例有很多不懂的地方,比如
2017-02-22 16:08:08
传播的,不会回流),区别于循环神经网络RNN。BP算法(Back Propagation):误差反向传播算法,用于更新网络中的权重。BP神经网络思想:表面上:1. 数据信息的前向传播,从输入层到隐含层
2019-07-21 04:00:00
请问用matlab编程进行BP神经网络预测时,训练结果很多都是合适的,但如何确定最合适的?且如何用最合适的BP模型进行外推预测?
2014-02-08 14:23:06
propagation algorithm,BP)[22]。BP 算法采用 Sigmoid 进行非线性映射,有效解决了 非线性分类和学习的问题,掀起了神经网络第二次 研究高潮。BP 网络是迄今为止最常用的神经网络, 目前
2022-08-02 10:39:39
反馈神经网络算法
2020-04-28 08:36:58
最近一个月的时间没有更博,跟随老师出差谈项目了。前段时间学习了电机的智能控制,这次把设计好的基于BP神经网络PID控制器应用于双闭环直流调速系统。双闭环直流调速系统的动态数学模型如下图所示: 外环为
2021-06-28 12:03:44
最近在学习电机的智能控制,上周学习了基于单神经元的PID控制,这周研究基于BP神经网络的PID控制。神经网络具有任意非线性表达能力,可以通过对系统性能的学习来实现具有最佳组合的PID控制。利用BP
2021-09-07 07:43:47
摘 要:本文给出了采用ADXL335加速度传感器来采集五个手指和手背的加速度三轴信息,并通过ZigBee无线网络传输来提取手势特征量,同时利用BP神经网络算法进行误差分析来实现手势识别的设计方法
2018-11-13 16:04:45
基于BP神经网络的辨识
2018-01-04 13:37:27
`点击学习>>《龙哥手把手教你学LabVIEW视觉设计》视频教程用LabVIEW实现的BP人工神经网络曲线拟合,感谢LabVIEW的矩阵运算函数,程序流程较之文本型语言清晰很多。[hide] [/hide]`
2011-12-13 16:41:43
本文介绍了基于三层前馈BP神经网络的图像压缩算法,提出了基于FPGA的实现验证方案,详细讨论了实现该压缩网络组成的重要模块MAC电路的流水线设计。
2021-05-06 07:01:59
,并能在脑海中重现这些图像信息,这不仅与人脑的海量信息存储能力有关,还与人脑的信息处理能力,包括数据压缩能力有关。在各种神经网络中,多层前馈神经网络具有很强的信息处理能力,由于其采用BP算法,因此也
2019-08-08 06:11:30
求一个simulink的蓄电池用BP神经网络PID控制电机加速匀速减速运动的模型仿真
2020-02-22 02:15:50
谁有利用LABVIEW 实现bp神经网络的程序啊(我用的版本是8.6的 )
2012-11-26 14:54:59
求高手,基于labview的BP神经网络算法的实现过程,最好有程序哈,谢谢!!
2012-12-10 14:55:50
参考文献用labview编写的一个3层BP神经网络程序
2015-05-28 10:35:08
请问用matlab编程进行BP神经网络预测时,训练结果很多都是合适的,但如何确定最合适的?且如何用最合适的BP模型进行外推预测?
2014-02-08 14:19:12
针对模糊神经网络训练采用BP算法比较依赖于网络的初始条件,训练时间较长,容易陷入局部极值的缺点,利用粒子群优化算法(PSO)的全局搜索性能,将PSO用于模糊神经网络的训练过程.由于基本PSO算法存在
2010-05-06 09:05:35
关于遗传算法和神经网络的
2013-05-19 10:22:16
本文采用BP 多层前馈神经网络及其改进算法对传感器特性进行补偿. 提出附加动量法、自适应参数变化法为主要内容的BP 神经网络改进算法,有效地改善了BP 网络传统算法收敛慢、容
2009-07-02 08:35:17 14
14 本文讨论了使用BP 神经网络PID 控制算法,并且将这种控制算法应用在漂白工段的控制当中。利用神经网络自学习能力,在线整定PID 控制参数。实践证明BP 神经网络PID控制器具有
2009-08-15 10:27:3635 本文介绍了BP神经网络的基本原理。由于BP神经网络有着神奇的非线性映射能力,通过构造特殊的映射关系,获得了一套基于BP神经网络的通用高效无损数据压缩方案。通过试验证明
2009-09-11 16:00:3911 BP 神经网络是目前用于模拟电路故障诊断的神经网络之一。本文应用BP 神经网络完成了实际电路最优测试集的生成设计,验证了基于BP 神经网络的最优测试集的生成的可行性和有
2009-12-16 16:08:339 本文首先介绍了传统的神经网络BP 算法的优缺点,并结合模拟退火算法局部搜索全局的特点,提出将模拟退火算法和传统的BP 算法相结合,形成一种新的BP 神经网络算法,有效的解
2010-01-09 11:57:0512 提出了基于BP 神经网络的2DPCA 人脸识别算法。通过图像预处理改善图像质量,降低图像维数,然后用2DPCA 进行特征提取,作为BP 神经网络的输入,用改进的BP 神经网络作为分类
2010-01-18 12:27:1418 采用神经网络控制方法! 建立了基于BP算法的神经网络有源消声实验系统" 实验证明基于BP算法的有源消声实验系统具有良好的消声效果和稳定性"
2010-07-22 16:09:5311 用BP神经网络及其改进算法改善
传感器特性BP算法即多层网络误差反传算法,是近几年在传感器输出信号补偿技术领域中一种较新的方法,
2009-06-08 13:50:04 2191
2191 BP神经网络图像压缩算法乘累加单元的FPGA设计
0 引 言 神经网络(Neural Networks)是人工神经网络(Ar-tificial Neural Networks)的简称,是当前的研究热点之一。人
2009-11-13 09:50:051774 BP神经网络图像压缩算法乘累加单元的FPGA设计
概 述神经网络(Neural Networks)是人工神经网络(Ar-tificial Neural Networks)的简称,是当前的研究热点之一。人脑在接受视觉
2010-03-29 10:05:12893 
针对BP(Back Propagation)神经网络易陷入局部极
2011-03-07 14:59:5999 提出了一种基于改进差分进化算法和 BP神经网络 的计算机网络流量预测方法。利用差分进化算法的全局寻优能力,快速地得到BP神经网络的权值和阈值;然后利用BP神经网络的非线性拟
2011-08-10 16:13:0731 文中将BP神经网络的原理应用于参数辨识过程,结合传统的 PID控制算法,形成一种改进型BP神经网络PID控制算法。该算法利用BP神经网络建立系统参数模型,能够跟踪被控对象的变化,取
2012-07-16 15:53:0851 基于BP神经网络的SVPWM算法的研究与仿真
2016-04-15 18:29:1611 基于模拟退火算法改进的BP神经网络算法_周爱武
2017-01-03 17:41:320 BP神经网络模型与学习算法
2017-09-08 09:42:4810 针对BP神经网络风速预测中存在的结构不确定以及网络过度拟合的问题,利用遗传算法的全局搜索能力和模糊聚类算法的数据筛选能力,分别对BP神经网络的结构与数据进行双重优化,提出了基于遗传算法和聚类算法的改进BP神经网络风速预测方法,仿真表明,改进风速后的预测方法大大提高了风速预测的准确性。
2017-11-10 11:23:415 神经网络计算模型的优化,运用到汽车加油量计算中,通过比较标准BP网络、Srinivas提出的自适应遗传算法优化的BP神经网络和改进的自适应遗传算法优化的BP神经网络3种模型的计算误差,验证得出改进的自适应遗传算法优化BP神经网络的算法优于另外两种
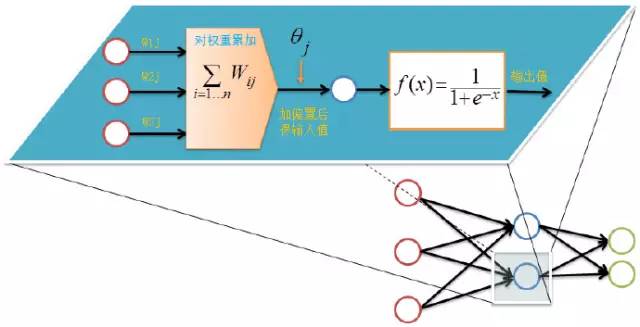
2017-11-16 10:39:5513 基于BP神经网络的辨识,1986年,Rumelhart等提出了误差反向传播神经网络,简称BP网络(Back Propagation),该网络是一种单向传播的多层前向网络。
误差反向传播
2017-12-06 15:11:580 针对传统税收预测模型精度较低的问题,提出一种将Adaboost算法和BP神经网络相结合进行税收预测的方法。该方法首先对历年税收数据进行预处理并初始化测试数据分布权值;然后初始化BP神经网络权值和阈值
2018-02-27 16:51:440 BP 神经网络是一类基于误差逆向传播 (BackPropagation, 简称 BP) 算法的多层前馈神经网络,BP算法是迄今最成功的神经网络学习算法。现实任务中使用神经网络时,大多是在使用 BP
2018-06-19 15:17:1545171 
本文档的主要内容详细介绍的是MATLAB和BP人工神经网络算法源代码与演示程序详细资料免费下载 解压后,运行CMMATools.exe即可 用于演示BP人工神经网络算法。
2020-03-23 08:00:005 BP神经网络是一种多层的前馈神经网络,其主要的特点是:信号是前向传播的,而误差是反向传播的。具体来说,对于如下的只含一个隐层的神经网络模型:输入向量应为n个特征
2020-09-24 11:51:3515505 
在 深度神经网络(DNN)模型与前向传播算法 中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结。 1. DNN反向传播算法要解决的问题
2021-03-22 16:28:224292 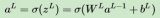
个 2×3×1 的神经网络即输入层有两个节点, 隐层含三个节点, 输出层有一个节点,神经网络如图示。
2021-03-25 10:03:0510 BP神经网络基本原理资料免费下载。
2021-04-25 15:36:1618 BP神经网络原理及应用说明。
2021-04-27 10:48:1117 人工智能-BP神经网络算法的简单实现说明。
2021-05-25 11:30:1612 基于遗传算法优化的BP神经网络及其仿真研究说明。
2021-05-31 17:01:0616 通过对传统BP神经网络缺点的分析,从参数选取、BP算法、激活函数、网络结构4个方面综述了其改进方法。介绍了各种方法的原理、应用背景及其在BP神经网络中的应用,同时分析了各种方法的优缺点。指出不断提高网络的训练速度、收敛性和泛化能力仍是今后的研究方向,并展望了BP神经网络的研究重点。
2021-06-01 11:28:435 倒对于老年人来说是一个十分严重的问题,实时检测老年人是否摔倒对于减轻摔倒造成的伤害具有重要意义。为此,文中提出了一种基于BP神经网络的摔倒检测算法。该算法采用佩戴于腰部的六轴传感器(MPU6050来
2021-06-16 16:09:015 神经网络及BP与RBF的比较说明。
2021-06-18 09:59:1122 卷积神经网络算法流程 卷积神经网络模型工作流程 卷积神经网络(Convolutional Neural Network,CNN)是一种广泛应用于目标跟踪、图像识别和语音识别等领域的深度学习模型,其
2023-08-21 16:50:193704 人工神经网络和bp神经网络的区别 人工神经网络(Artificial Neural Network, ANN)是一种模仿人脑神经元网络结构和功能的计算模型,也被称为神经网络(Neural
2023-08-22 16:45:186057 卷积神经网络(Convolutional Neural Networks,简称CNN)和BP神经网络(Backpropagation Neural Networks,简称BPNN)是两种
2024-07-02 14:24:037113 、自然语言处理等。本文将详细介绍BP神经网络算法的基本流程,包括网络结构、激活函数、前向传播、反向传播、权重更新和训练过程等。 网络结构 BP神经网络由输入层、隐藏层和输出层组成。输入层接收外部输入信号,隐藏层对输入信号进行非线性变换,输出层
2024-07-03 09:52:511472 越接近1,表示模型的预测效果越好。当BP神经网络算法的R2值较小时,说明模型的预测效果不理想,需要进行相应的优化和调整。 数据预处理 数据预处理是提高BP神经网络算法R2值的关键步骤之一。以下是一些常见的数据预处理方法: 1.1 数据清洗:去除数据集中的噪声、异常值和缺失值,以提高
2024-07-03 09:55:332861 BP神经网络(Backpropagation Neural Network,简称BP网络)是一种多层前馈神经网络,它通过反向传播算法来调整网络中的权重和偏置,从而实现对输入数据的预测。本文将详细介绍
2024-07-03 09:59:421565 BP神经网络(Backpropagation Neural Network)是一种多层前馈神经网络,其核心思想是通过反向传播算法来调整网络中的权重和偏置,以实现对输入数据的分类或回归。在BP神经网络
2024-07-03 10:02:011808 BP神经网络(Backpropagation Neural Network)是一种基于梯度下降算法的多层前馈神经网络,具有强大的非线性拟合能力。 BP神经网络的原理 1.1 神经网络的基本概念
2024-07-03 10:08:551800 结构、原理、应用场景等方面都存在一定的差异。以下是对这两种神经网络的比较: 基本结构 BP神经网络是一种多层前馈神经网络,由输入层、隐藏层和输出层组成。每个神经元之间通过权重连接,并通过激活函数进行非线性转换。BP神经网络通过反向传播算法进行训练,通过调整权重和偏置来最小化损失函数。 卷积神经网络
2024-07-03 10:12:473381 BP神经网络(Backpropagation Neural Network)是一种常见的前馈神经网络,它使用反向传播算法来训练网络。虽然BP神经网络在某些方面与深度神经网络(Deep Neural
2024-07-03 10:14:301801 BP神经网络,即反向传播(Backpropagation)神经网络,是一种前馈神经网络(Feedforward Neural Network)。以下是关于BP神经网络的介绍: 神经网络的基本概念
2024-07-03 10:16:072193 属于。BP神经网络(Backpropagation Neural Network)是一种基于误差反向传播算法的多层前馈神经网络,是深度学习(Deep Learning)领域中非常重要的一种模型。而
2024-07-03 10:18:091799 BP神经网络(Backpropagation Neural Network)是一种多层前馈神经网络,广泛应用于各种领域的数据建模和预测任务。然而,BP神经网络在处理不连续变量时可能会遇到一些挑战
2024-07-03 10:19:57916 BP神经网络(Backpropagation Neural Network)是一种多层前馈神经网络,其核心思想是通过反向传播算法来调整网络权重,使得网络的输出尽可能接近目标值。在MATLAB中,可以
2024-07-03 10:28:232186 反向传播神经网络(Backpropagation Neural Network,简称BP神经网络)是一种多层前馈神经网络,它通过反向传播算法来调整网络中的权重和偏置,以达到最小化误差的目的。BP
2024-07-03 11:00:201742 BP神经网络(Backpropagation Neural Network)是一种基于误差反向传播算法的多层前馈神经网络,具有强大的非线性映射能力,广泛应用于模式识别、信号处理、预测控制等领域
2024-07-04 09:44:113013 的算法过程,包括网络结构、激活函数、训练过程、反向传播算法、权重更新策略等。 网络结构 BP神经网络由输入层、隐藏层和输出层组成,每层包含若干神经元。输入层的神经元数量与问题的特征维度相同,输出层的神经元数量与问题的输出维度相同。隐藏层的数量和每层的神经元数
2024-07-04 09:45:491475 BP神经网络算法,即反向传播神经网络算法,是一种常用的多层前馈神经网络训练算法。它通过反向传播误差来调整网络的权重和偏置,从而实现对输入数据的分类或回归。下面详细介绍BP神经网络算法的基本流程
2024-07-04 09:47:191883 结构、原理、应用场景等方面都存在一定的差异。以下是对这两种神经网络的详细比较: 基本结构 BP神经网络是一种多层前馈神经网络,由输入层、隐藏层和输出层组成。每个神经元之间通过权重连接,并通过激活函数进行非线性转换。BP神经网络通过反向传播算法进行训练,通过调整权重和偏置来最小化损失函数。 卷积神经
2024-07-04 09:49:4426258 反向传播神经网络(Backpropagation Neural Network,简称BP神经网络)是一种多层前馈神经网络,它通过反向传播算法来调整网络中的权重和偏置,以达到最小化误差的目的。BP
2024-07-04 09:51:321389 网络结构,通过误差反向传播算法(Error Backpropagation Algorithm)来训练网络,实现对复杂问题的学习和解决。以下将详细阐述BP神经网络的工作方式,涵盖其基本原理、训练过程、应用实例以及优缺点等多个方面。
2024-07-10 15:07:119467 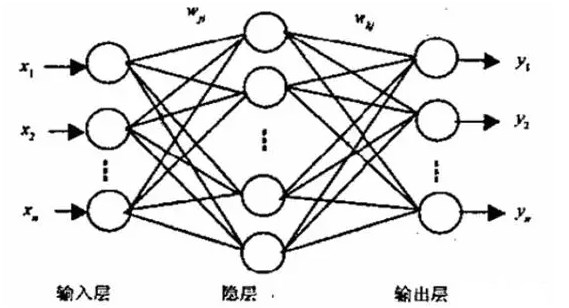
BP(Back-propagation,反向传播)神经网络是一种多层前馈神经网络,通过反向传播算法训练,以最小化预测值与实际值之间的误差。BP神经网络因其广泛的应用和灵活性,在机器学习、人工智能
2024-07-10 15:14:161821 BP神经网络和人工神经网络(Artificial Neural Networks,简称ANNs)之间的关系与区别,是神经网络领域中一个基础且重要的话题。本文将从定义、结构、算法、应用及未来发展等多个方面,详细阐述BP神经网络与人工神经网络之间的异同,以期为读者提供一个全面而深入的理解。
2024-07-10 15:20:533040 BP神经网络(Backpropagation Neural Network)和卷积神经网络(Convolutional Neural Network,简称CNN)是两种在人工智能和机器学习领域
2024-07-10 15:24:442989 BP神经网络(Backpropagation Neural Network),即反向传播神经网络,是一种基于梯度下降算法的多层前馈神经网络,其学习机制的核心在于通过反向传播算法
2024-07-10 15:49:291917 BP神经网络(Backpropagation Neural Network)是一种多层前馈神经网络,通过反向传播算法进行训练。BP神经网络在许多领域都有广泛的应用,如图像识别、语音识别、自然语言处理
2024-07-11 10:31:211777 BP神经网络(Backpropagation Neural Network)是一种基于误差反向传播算法的多层前馈神经网络,广泛应用于模式识别、分类、预测等领域。在构建BP神经网络模型之前,获取高质量
2024-07-11 10:50:501488 BP神经网络(Backpropagation Neural Network)是一种多层前馈神经网络,其核心思想是通过反向传播算法来调整网络中的权重和偏置,从而实现对输入数据的预测或分类。本文将详细
2024-07-11 10:52:341892 引言 BP神经网络(Backpropagation Neural Network)是一种前馈神经网络,通过反向传播算法进行训练。三层BP神经网络由输入层、隐藏层和输出层组成,具有较好的泛化能力和学习
2024-07-11 10:55:481483 BP(反向传播)神经网络是一种多层前馈神经网络,它通过反向传播算法来训练网络中的权重和偏置,以最小化输出误差。BP神经网络的核心在于其前向传播过程,即信息从输入层通过隐藏层到输出层的传递,以及反向
2024-07-11 16:44:131627 传播神经网络(Back Propagation Neural Network),是一种多层前馈神经网络,主要通过反向传播算法进行学习。它通常包括输入层、一个或多个隐藏层和输出层。BP神经网络的训练过程涉及到前向传播和反向传播两个阶段:在前向传播阶段,输入信号通过
2025-02-12 15:12:081268 BP神经网络(Back Propagation Neural Network)的基本原理涉及前向传播和反向传播两个核心过程。以下是关于BP神经网络基本原理的介绍: 一、网络结构 BP神经网络通常由
2025-02-12 15:13:371656 ),是一种多层前馈神经网络,它通过反向传播算法进行训练。BP神经网络由输入层、一个或多个隐藏层和输出层组成,通过逐层递减的方式调整网络权重,目的是最小化网络的输出误差。 二、深度学习的定义与发展 深度学习是机器学习的一个子集,指的是那些包含多个处理层的复杂网络模
2025-02-12 15:15:211520 BP神经网络的反向传播算法(Backpropagation Algorithm)是一种用于训练神经网络的有效方法。以下是关于BP神经网络的反向传播算法的介绍: 一、基本概念 反向传播算法是BP
2025-02-12 15:18:191429 BP神经网络(Back Propagation Neural Network)作为一种常用的机器学习模型,具有显著的优点,同时也存在一些不容忽视的缺点。以下是对BP神经网络优缺点的分析: 优点
2025-02-12 15:36:491800 优化BP神经网络的学习率是提高模型训练效率和性能的关键步骤。以下是一些优化BP神经网络学习率的方法: 一、理解学习率的重要性 学习率决定了模型参数在每次迭代时更新的幅度。过大的学习率可能导致模型在
2025-02-12 15:51:371536 BP神经网络与卷积神经网络在多个方面存在显著差异,以下是对两者的比较: 一、结构特点 BP神经网络 : BP神经网络是一种多层的前馈神经网络,通常由输入层、隐藏层和输出层组成,其中隐藏层可以有一层或
2025-02-12 15:53:141490
 电子发烧友App
电子发烧友App



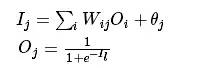
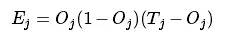
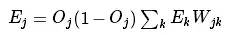
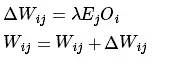
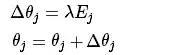





 工商网监
工商网监
评论