 电子发烧友App
电子发烧友App


作为一种人机交互的手段,语音的端点检测在解放人类双手方面意义重大。同时,工作环境存在着各种各样的背景噪声,这些噪声会严重降低语音的质量从而影响语音应用的效果,比如会降低识别率。未经压缩的语音数据,网络交互应用中的网络流量偏大,从而降低语音应用的成功率。因此,音频的端点检测、降噪和音频压缩始终是终端语音处理关注的重点,目前仍是活跃的研究主题。
为了能和您一起了解端点检测和降噪的基本原理,带您一起一窥音频压缩的奥秘,科大讯飞资深研发工程师李洪亮将为我们详解语音处理检测技术中的热点——端点检测、降噪和压缩 。
▎端点检测
首先来看端点检测(Voice Activity Detection, VAD)。音频端点检测就是从连续的语音流中检测出有效的语音段。它包括两个方面,检测出有效语音的起始点即前端点,检测出有效语音的结束点即后端点。
在语音应用中进行语音的端点检测是很必要的,首先很简单的一点,就是在存储或传输语音的场景下,从连续的语音流中分离出有效语音,可以降低存储或传输的数据量。其次是在有些应用场景中,使用端点检测可以简化人机交互,比如在录音的场景中,语音后端点检测可以省略结束录音的操作。

为了能更清楚说明端点检测的原理,先来分析一段音频。上图是一段只有两个字的简单音频,从图上可以很直观的看出,首尾的静音部分声波的振幅很小,而有效语音部分的振幅比较大,一个信号的振幅从直观上表示了信号能量的大小:静音部分能量值较小,有效语音部分的能量值较大。语音信号是一个以时间为自变量的一维连续函数,计算机处理的语音数据是语音信号按时间排序的采样值序列,这些采样值的大小同样表示了语音信号在采样点处的能量。

采样值中有正值和负值,计算能量值时不需要考虑正负号,从这个意义上看,使用采样值的绝对值来表示能量值是自然而然的想法,由于绝对值符号在数学处理上不方便,所以采样点的能量值通常使用采样值的平方,一段包含N个采样点的语音的能量值可以定义为其中各采样值的平方和。
这样,一段语音的能量值既与其中的采样值大小有关,又与其中包含的采样点数量有关。为了考察语音能量值的变化,需要先将语音信号按照固定时长比如20毫秒进行分割,每个分割单元称为帧,每帧中包含数量相同的采样点,然后计算每帧语音的能量值。
如果音频前面部分连续M0帧的能量值低于一个事先指定的能量值阈值E0,接下来的连续M0帧能量值大于E0,则在语音能量值增大的地方就是语音的前端点。同样的,如果连续的若干帧语音能量值较大,随后的帧能量值变小,并且持续一定的时长,可以认为在能量值减小的地方即是语音的后端点。
现在的问题是,能量值阈值E0怎么取?M0又是多少?理想的静音能量值为0,故上面算法中的E0理想状态下取0。不幸的是,采集音频的场景中往往有一定强度的背景音,这种单纯的背景音当然算静音,但其能量值显然不为0,因此,实际采集到的音频其背景音通常有一定的基础能量值。
我们总是假设采集到的音频在起始处有一小段静音,长度一般为几百毫秒,这一小段静音是我们估计阈值E0的基础。对,总是假设音频起始处的一小段语音是静音,这一点假设非常重要!!!!在随后的降噪介绍中也要用到这一假设。在估计E0时,选取一定数量的帧比如前100帧语音数据(这些是“静音”),计算其平均能量值,然后加上一个经验值或乘以一个大于1的系数,由此得到E0。这个E0就是我们判断一帧语音是否是静音的基准,大于这个值就是有效语音,小于这个值就是静音。
至于M0,比较容易理解,其大小决定了端点检测的灵敏度,M0越小,端点检测的灵敏度越高,反之越低。语音应用的场景不同,端点检测的灵敏度也应该被设置为不同的值。例如,在声控遥控器的应用中,由于语音指令一般都是简单的控制指令,中间出现逗号或句号等较长停顿的可能性很小,所以提高端点检测的灵敏度是合理的,M0设置为较小值,对应的音频时长一般为200-400毫秒左右。在大段的语音听写应用中,由于中间会出现逗号或句号等较长时间的停顿,宜将端点检测的灵敏度降低,此时M0值设置为较大值,对应的音频时长一般为1500-3000毫秒。所以M0的值,也就是端点检测的灵敏度,在实际中应该做成可调整的,它的取值要根据语音应用的场景来选择。
以上只是语音端点检测的很简单的一般原理,实际应用中的算法远比上面讲的要复杂。作为一个应用较广的语音处理技术,音频端点检测仍然是一个较为活跃的研究方向。科大讯飞已经使用循环神经网络(Recurrent Neural Networks, RNN)技术来进行语音的端点检测,实际的效果可以关注讯飞的产品。
▎降噪
降噪又称噪声抑制(Noise Reduction),前文提到,实际采集到的音频通常会有一定强度的背景音,这些背景音一般是背景噪音,当背景噪音强度较大时,会对语音应用的效果产生明显的影响,比如语音识别率降低,端点检测灵敏度下降等,因此,在语音的前端处理中,进行噪声抑制是很有必要的。
噪声有很多种,既有频谱稳定的白噪声,又有不稳定的脉冲噪声和起伏噪声,在语音应用中,稳定的背景噪音最为常见,技术也最成熟,效果也最好。本课程只讨论稳定的白噪声,即总是假设背景噪声的频谱是稳定或者是准稳定的。
前面讲的语音端点检测是在时域上进行的,降噪的过程则是在频域上进行的,为此,我们先来简单介绍或者说复习一下用于时域-频域相互转换的重要工具——傅里叶变换。
为了更容易理解,先看高等数学中学过的傅里叶级数,高等数学理论指出,一个满足Dirichlet条件的周期为2T的函数f(t),可以展开成傅里叶级数:


对于一般的连续时域信号f(t),设其定义域为[0,T],对其进行奇延拓后,其傅里叶级数如下式:

bn的计算同上,由上式可知,任何一个连续的时域信号f(t),都可以由一组三角函数线性叠加而成。或者说, f(t)都可以由一个三角函数线性组合组成的序列来无限的逼近。信号的傅里叶级数展示的是构成信号的频率以及各个频率处的振幅,因此,式子的右端又可以看做是信号f(t)的频谱,说的更直白一点,信号的频谱就是指这个信号有哪些频率成分,各个频率的振幅如何。上式从左到右的过程是一个求已知信号的频谱的过程,从右到左的过程是一个由信号的频谱重构该信号的过程。
虽然由信号的傅里叶级数很容易理解频谱的概念,但在实际中求取信号的频谱时,使用的是傅里叶级数的一种推广形式——傅里叶变换。
傅里叶变换是一个大的家族,在不同的应用领域,有不同的形式,在这里我们只给出两种形式——连续形式的傅里叶变换和离散傅里叶变换:

其中的j是虚数单位,也就是j*j=-1,其对应的傅里叶逆变换分别为:

在实际应用中,将数字采样信号进行傅里叶变换后,可以得到信号的频谱。频域上的处理完成后,可以使用傅里叶逆变换将信号由频域转换到时域中。对,傅里叶变换是一个可以完成由时域向频域转换的重要工具,一个信号经傅里叶变换后,可以得到信号的频谱。
以上是傅里叶变换的简单介绍,数学功底不太好的朋友看不大懂也没关系,只要明白,一个时域信号进行傅里叶变换后,可以得到这个信号的频谱,即完成如下转换:

左面的是时域信号,右面的是对应的频谱,时域信号一般关注的是什么时间取什么值,频域信号关心的是频率分布和振幅。
有了以上的理论作为基础,理解降噪的原理就容易多了,噪音抑制的关键是提取出噪声的频谱,然后将含噪语音根据噪声的频谱做一个反向的补偿运算,从而得到降噪后的语音。这句话很重要,后面的内容都是围绕这句话展开的。
噪声抑制的一般流程如下图所示:
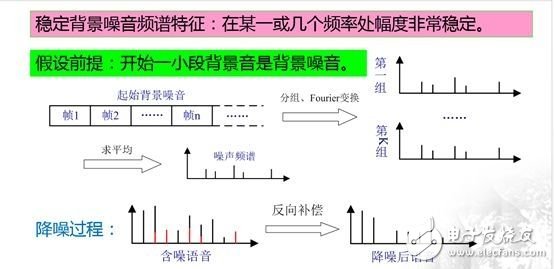
同端点检测类似,假设音频起始处的一小段语音是背景音,这一假设非常重要,因为这一小段背景音也是背景噪声,是提取噪声频谱的基础。
降噪过程:首先将这一小段背景音进行分帧,并按照帧的先后顺序进行分组,每组的帧数可以为10或其他值,组的数量一般不少于5,随后对每组背景噪声数据帧使用傅里叶变换得到其频谱,再将各频谱求平均后得到背景噪声的频谱。
得到噪声的频谱后,降噪的过程就非常简单了,上图下面左侧的图中红色部分即为噪声的频谱,黑色的线为有效语音信号的频谱,两者共同构成含噪语音的频谱,用含噪语音的频谱减去噪音频谱后得到降噪后语音的频谱,再使用傅里叶逆变换转回到时域中,从而得到降噪后的语音数据。
下图展示了降噪的效果

左右两幅图是降噪前后时域中的对比,左面的是含噪语音信号,从图中可以看到噪声还是很明显的。右侧的是降噪后的语音信号,可以看出,背景噪声被大大的抑制了。
下面两幅图是频域中的对比
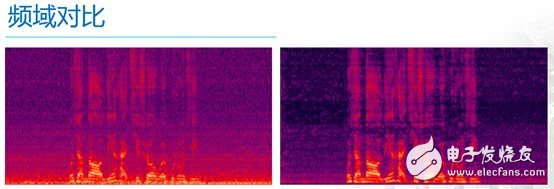
其中横轴表示时间轴,纵轴表示频率,左面的是含噪语音,其中的亮红色部分是有效语音,而那些像沙子一样的紫色的部分则是噪声。从图中可以看出,噪声不仅是“无时不在”,而且还是“无处不在”,也就是在各种频率处都有分布,右侧的是降噪后的语音,可以很明显的看出,降噪前那些像沙子一样的紫色的部分淡了很多,就是噪声被有效的抑制了。
在实际应用中,降噪使用的噪声频谱通常不是一成不变的,而是随着降噪过程的进行被持续修正的,即降噪的过程是自适应的。这样做的原因一方面是语音数据前部的静音长度有时不够长,背景噪声数据不足导致得到的噪声频谱往往不够准确,另一方面,背景噪声往往不是绝对稳定的,而是渐变的甚至会突变到另一种稳定的背景噪声。
这些原因都要求在降噪的过程中对使用的噪声频谱做及时修正,以得到较好的降噪效果。修正噪声频谱的方法是使用后继音频中的静音,重复噪声频谱提取算法,得到新的噪声频谱,并将之用于修正降噪所用的噪声频谱,所以降噪的过程中仍然要使用端点检测中用到的如何判断静音。噪声频谱修正的方法或者是新旧频谱进行加权平均,或者使用新的噪声频谱完全替换使用中的噪声频谱。
以上介绍的是降噪的非常简单的原理。实际应用中的降噪算法远比上面介绍的要复杂,现实中的噪声源多种多样,其产生的机理和特性也较为复杂,所以噪声抑制在现今仍然是一个较为活跃的研究领域,各种新技术也层出不穷,比如在实际应用中已经使用了多麦克风阵列来进行噪声抑制。
▎音频压缩
音频压缩的必要性众所周知,不再赘述。所有的音频压缩系统都要求有两种对应的算法,一种是运行于源端上的编码算法(encoding),另一种是运行于接收端或用户终端的解码算法(decoding)。
编码算法和解码算法表现出一定的不对称性。这种不对称性一是表现在编码算法和解码算法的效率可以不同。音频或视频数据在存储时,通常只被编码一次,但将被解码成千上万次,所以编码算法较复杂、效率降低、费用昂贵是可以被接受的,但解码算法一定要快速、简单而且廉价。编码算法和解码算法的不对称性还表现在编码和解码的过程通常是不可逆的,也就是说,解码后得到的数据和编码之前的原始数据可以是不同的,只要它们听起来或看起来是一样的即可,这种编解码算法通常称为有损的,与此对应的是,如果解码后得到和原始数据一致的数据,这种编码和解码称为无损的。
音视频编解码算法大多是有损的,因为忍受一些少量信息的丢失,往往可以换来压缩率的大幅提升,音频信号的压缩编码采用了数据编码中的一些技术,如熵编码、波形编码、参数编码、混合编码、感知编码等。
本次课重点介绍感知编码,相对于其他的编码算法,感知编码基于人耳听觉的一些特性(心理声学),去除音频信号中的冗余,从而达到音频压缩的目的。相对于其他的音频编码算法(无损的),在人耳没有感觉到明显失真的条件下,可以达到10倍以上的较大压缩率。
首先来介绍感知编码的心理声学基础。音频压缩的核心是去除冗余。所谓冗余就是语音信号中包含的不能为人耳所感知的信息,它对人类确定音色、音调等信息没有任何帮助,比如,人耳能听到的声音频率范围为20-20KHz,无法感知频率低于20Hz的次声波和频率高于20KHz的超声波。再比如,人耳也无法听到一段“不够响”的声音。感知编码就是利用了人类听觉系统的这类特性,达到去除音频冗余信息的目的。
感知编码中的心理声学主要有:频率屏蔽、时域屏蔽、可听度阈值等。

频率屏蔽 频率屏蔽在生活中处处可见,比如你在家中坐在沙发上安静的看电视,突然,正在装修的邻居家一阵很刺耳的电钻钻墙的声音传来,这时你所能听到的只有手提电钻发出的很强的噪声,尽管此时电视所发出的声音仍然在刺激着你的耳膜,但你却充耳不闻,也就是说,一段强度很高的声音可以完全屏蔽一段强度较低的声音,这种现象称为频率屏蔽。

时域屏蔽 承接前一个例子,不仅在电钻发出声音的时间内人耳听不到电视机的声音,就是在电钻的声音刚停下来的一小段时间内,人耳也听不到电视机的声音,这种现象称为时域屏蔽。产生时域屏蔽的原因是人类的听觉系统是一个增益可调的系统,听强度较大的声音时,增益较低,听强度较小的声音时,增益较高。有时人类甚至借助外部手段来改变听觉系统的增益,比如,捂耳朵以避免强度很大的声音损伤耳膜,而屏住呼吸、侧耳、以手放耳廓后更是听较弱声音时的常见行为。在上例中,强度很大的声音刚消失时,听觉系统需要一小段时间来调高增益,正是在这一小段时间内产生了时域屏蔽。
下面来说可听度阈值,它对于音频压缩灰常重要。
设想在一个安静的房间中,一台由计算机控制的扬声器可以发出某一频率的声音,刚开始时扬声器功率较小,处于一定距离上的听觉正常的人听不到扬声器发出的声音。然后开始逐渐增大扬声器的功率,当功率增大到刚好可以被听见的时候,记录下此时扬声器的功率(声强级,单位分贝),这个功率就是这个频率下的可听度阈值。
然后改变扬声器所发音频的频率,重复以上实验,最终获得的可听度阈值随频率变化的曲线如下图所示:

由图中可以很明显的看出,人类的听觉系统对频率在1000-5000Hz范围的声音最敏感,频率越接近两侧,人类听觉反应越迟钝。
回过头来再看频率屏蔽的情形,这次实验在房间中增加一个频率为150Hz,强度为60dB的信号,然后重复实验,实验得出的可听度阈值曲线如下图所示:
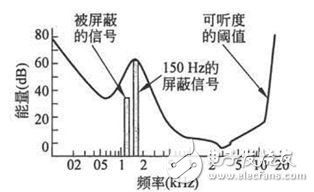
从图中很明显的看出,可听度阈值曲线在150Hz附近被强烈的扭曲了,被向上提高了很多。这意味着,本来位于可听度阈值之上的150Hz附近的某个频率的声音,有可能由于150Hz的更强的信号的存在而变得不可闻了,也就是被屏蔽了。
感知编码的基本规则就是,永远不需要对人耳听不到的信号进行编码,简单来说就是,听不到的信号不需要编码,这句废话恰恰是语音压缩研究的重点之一。废话的另外一种含义就是非常容易理解的正确的话。言归正传,哪些东西听不见呢?功率低于可听度阈值的信号或者说分量,被屏蔽的信号或者说分量,这些人耳都听不见,都是上文提到的“冗余”。
以上是心里声学的一些东西。要想很好的理解音频压缩,还需要理解一个更重要的概念:子带。子带(subband)是指这样的一种频率范围,当两个音调的频率位于一个子带内时,人就会把两个音调听成一个。更一般的情况是,如果一个复杂信号的频率分布位于一个子带内时,人耳的感觉是该信号等价于一个频率位于该子带中心频率处的简单信号,这是子带的核心内涵。简单说,子带是指一个频率范围,频谱位于这个范围内的信号可以用一个单一频率的分量来代替。
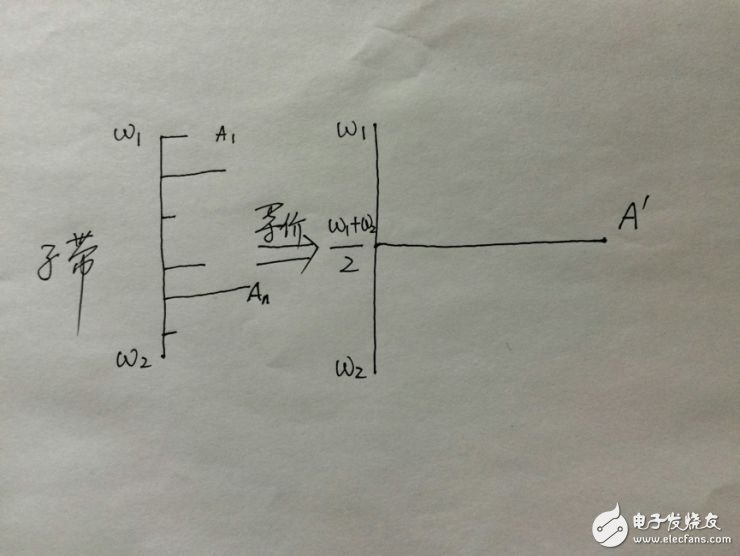
一般等价的频率取子带的中心频率,振幅取子带内个频率分量振幅的加权和,更简单的方法则是将各频率分量的振幅直接相加,作为等价信号的振幅,这样一个范围内的频率分量用一个分量就可以代替了。
设一个信号的频谱频率最低值为w0,最大值为w1。子带编码就是将w0-w1之间的频率范围划分成若干子带,然后每个子带范围内的分量用一个等价的频率分量来替换。这样,一个具有复杂频谱的信号可以等价为一个频谱构成灰常简单的信号——频谱被大大简化了,需要存储的东西就非常少了。
从以上过程不难知道,子带如何划分对压缩后音频的质量影响很大(毕竟是近似等价)。子带的划分方法是子带编码的一个很重要的研究主题,大致可以分为等宽子带编码和变宽子带编码,见名知意,不解释。
子带划分后子带数量的不同导致了压缩算法的不同等级。容易知道,码率越低压缩率越高时,子带数量少,同时音质较差。相反的情况也容易理解。
理解了子带编码,音频压缩就很容易理解了,一个信号经过一组三角滤波器(等同于一组子带)后,被精简为数量很少的频率分量。然后考察这些频率分量,能量或者说振幅位于可听度阈值曲线之下的直接无视(删除该分量,因为听不到)。再考察余下的两两相邻的频率分量,如果其中一个被旁边的频率屏蔽,也删除掉。经过以上的处理,一个复杂信号的频谱所含有的频率分量就很简单了,使用很少的数据就可以存储或者传输这些信息。
解码的时候使用傅里叶逆变换将上面得到的简单频谱重构到时域上,得到解码后的语音。
以上就是音频压缩的简单原理,下面谈谈音频编解码库。
可以公开获取的音频编解码开源库很多,其特点和能力也有所不同,如下图:

由图中可以看到,AAC和MP3等走的是“高端路线”,用来对高采样率的音乐进行编码,而AMR和SPEEX等走的是中低端路线,可以处理16K采样率以下的语音信号,这对于语音合成、语音识别、声纹识别等语音应用足够了。
科大讯飞语音云使用的是SPEEX系列,算法相关信息如下图所示:

Speex编解码库压缩率变换范围较广,压缩等级可供选择的范围较宽,所以应用在网络状况较为复杂的移动终端应用中甚为合适。
好了,以上就是本次课分享的全部内容。
小结:
音频端点检测、降噪和语音压缩,很多人觉得神秘、难于理解和难以把握。但经李老师娓娓道来,平时感觉高大上的语音处理技术也被讲的深入浅出。原来,不需要很高深的理论功底也可以理解这些技术的关键:音频端点检测的关键是根据前面的静音确定用来分辨静音和有效语音的标尺,降噪的关键是使用前面的一小段背景噪音提取出噪声的频谱,音频压缩方法之一是充分利用人类的心里声学,划分子带,去除冗余等。
让我们一起关注语音处理技术在以上几个方面的最新发展吧。
演讲嘉宾介绍
李洪亮,毕业于中国科学技术大学。科大讯飞资深研发工程师,长期从事语音引擎和语音类云计算相关开发,科大讯飞语音云的缔造者之一,主导研发的用于讯飞语音云平台上的语音编解码库,日使用量超过二十亿。主导语音类国家标准体系的建设,主导、参与多个语音类国家标准的制定。 他今天的分享将分为两大部分,第一部分是端点检测和降噪,第二部分是音频压缩。
















 工商网监
工商网监
评论