 电子发烧友App
电子发烧友App


根据行业的参考标准,AI将是下一件大事,或将在下一件大事中发挥重要作用。这也就解释了过去18个月里人工智能领域活动的疯狂。大公司支付数十亿美元收购创业公司,甚至投入更多的资金用于研发。此外,各国政府正在向大学和研究机构投入数十亿美元。全球竞赛正在进行,目的是创建的最佳的架构和系统来处理AI工作所必需的海量数据。
市场预测也相应上升。 根据Tractica研究所的数据,到2025年,AI年收入预计将达到368亿美元。Tractica表示,迄今为止已经确定了AI的27种不同的细分行业以及191个使用案例。
但随着我们深入挖掘,很快就可以明显地看到,并不存在一个的最好的方式来解决AI问题。甚至对于AI是什么,或需要分析的数据类型,我们尚没有一致的定义。

图1 AI收入增长预测。来源:Tractica
OneSpin Solutions总裁兼首席执行官Raik Brinkmann说,“在人工智能芯片中,你有三个问题需要解决。首先,你需要处理大量的数据。其次,构建用于并行处理的互连。第三是功率,这是你移动数据量的直接结果。所以你亟须从冯诺依曼架构转变到数据流架构。但它究竟是什么样子?”
目前的答案很少,这就是为什么AI市场的第一颗芯片包括现成的CPU,GPU,FPGA和DSP的各种组合。虽然新设计正在由诸如英特尔、谷歌、英伟达、高通,以及IBM等公司开发,但目前还不清楚哪家的方法会胜出。似乎至少需要一个CPU来控制这些系统,但是当流数据并行化时,就会需要各种类型的协处理器。
AI的许多数据处理涉及矩阵乘法和加法。大量并行工作的GPU提供了一种廉价的方法,但缺点是更高的功率。具有内置DSP模块和本地存储器的FPGA更节能,但它们通常更昂贵。这也是软件和硬件真正需要共同开发的领域,但许多软件远远落后于硬件。
Mentor Graphics董事长兼首席执行官Wally Rhines表示:“目前,研究和教育机构有大量的活动。有一场新的处理器开发竞赛。也有标准的GPU用于深度学习,同时还有很多人在从事CPU的工作。目标是使神经网络的行为更像人脑,这将刺激一次全新的设计浪潮。”
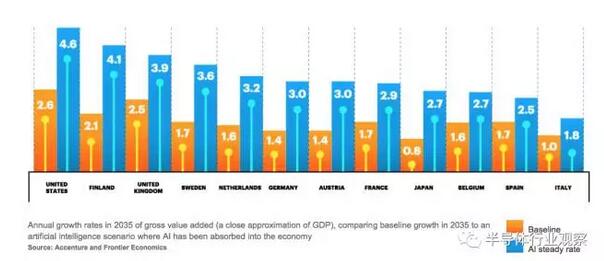
当视觉处理开始涉及到AI时,便受到了极大的关注,主要是因为特斯拉在预计推出自动驾驶汽车的15年前就已经提出了自动驾驶概念。这为视觉处理技术,以及为处理由图像传感器、雷达和激光雷达收集的数据所需的芯片和整体系统架构开辟了巨大的市场。但许多经济学家和咨询公司正寻求超越这个市场,探讨AI将如何影响整体生产力。Accenture最近的报道预测,AI将使一些国家的GDP翻番(见下图2)。虽然这将导致就业机会大幅减少,但整体收入的提高不容忽视。
Synopsys董事长兼联合首席执行官Aart de Geus指出了电子学的三个浪潮——计算和网络、移动、数字智能。在后一种类型中,焦点从技术本身转移到它可以为人们做什么。
“You’ll see processors with neural networking IP for facial recognition and vision processing in automobiles,” said de Geus. “Machine learning is the other side of this. There is a massive push for more capabilities, and the state of the art is doing this faster. This will drive development to 7nm and 5nm and beyond.”
de Geus说:“你将看到具有面部识别和汽车视觉处理的神经网络IP。机器学习是其另一面。它对于更多的能力会产生一种巨大的推动,目前的技术水平可以快速完成这些。这将推动芯片发展到7nm、5nm,甚至更高的水平。”
目前的方法
自动驾驶中的视觉处理在AI当前研究中占主导地位,但该技术在无人机和机器人中的作用也越来越大。
Achronix公司总裁兼首席执行官Robert Blake说:“对于图像处理的AI应用,计算复杂度很高。对于无线技术,数学很好理解。对于图像处理,数学就像西部拓荒,工作负载复杂多变。大概花费5~10年时间才能解决市场问题,但是它对于可编程逻辑肯定会有很大的作用,因为我们需要能够以高度并行的方式完成的变精度数学。”
FPGA非常适合矩阵乘法。最重要的是,它的可编程性增加了一些必要的灵活性和面向未来的设计,因为在这一点上,不清楚所谓的智能将存在于一个设计的哪部分。用于做决策的数据一些将在本地处理,一些将在数据中心中处理。但在每个实现中,其百分比可能会改变。
这对AI芯片和软件设计有很大的影响。虽然AI的大局并没有太大的变化(大部分所谓的AI更接近于机器学习,而非真正的AI),但是对于如何构建这些系统的理解却发生了重大的变化。
图3:谷歌TPU开发板 来源:谷歌
Arteris营销副总裁Kurt Shuler说:“对于自动驾驶汽车,人们正在做的就是把现有的东西放在一起。为了使一个真正高效的嵌入式系统能够学习,它需要一个高效的硬件系统。我们采用了几种不同的方法。如果你关注视觉处理,你要做的是试图弄清楚器件看到的是什么,以及你如何推断。这包括来自视觉传感器、激光雷达和雷达的数据,然后应用专门的算法。这里的很多事情都是试图模仿大脑中的事情,方法是利用深度卷积神经网络。”
它与真正的AI的不同之处是,现有技术水平能够检测和避开物体,而真正的AI能够拥有推理能力,例如如何通过一群人正在横穿的街道,或判断玩皮球的小孩子是否会跑到街道上。对于前者,判断是基于各种传感器的输入,而传感器的输入是基于海量数据处理和预编程的行为。对于后者,机器能够作出价值判断,例如判断转弯避开孩子可能会造成的很多结果,并做出最佳选择。
Shuler说:“传感器融合是20世纪90年代出现的一种理念。你要把它变成机器可以处理的通用的数据格式。如果你在军队里,你担心有人向你开枪。对于自动驾驶汽车而言,这就像面前有人推婴儿车。所有这些系统都需要非常高的带宽,并且都必须在其中内置安全措施。最重要的是,你必须保护数据,因为安全正在成为越来越大的问题。因此,你需要的是计算效率和编程效率。”
这是今天的许多设计中所缺少的,因为太多的开发是由现成的零件搭建的。
Cadence高级架构师以及深度学习小组总监Samer Hijazi说:“如果你优化网络、优化问题、最小化位数,并使用为卷积神经网络定制的硬件,那么你可以实现功率降低2~3倍的改进。效率来自软件算法和硬件IP。”
谷歌正尝试改变这个公式。谷歌开发了Tensor处理单元(TPU),这是专门为机器学习而创建的ASIC。为了加快AI的发展,谷歌在2015年开源了TensorFlow软件。
其他公司拥有自己的平台。但这些都不是最终产品。这是进化的过程,没有人能确定未来十年AI将如何发展。部分是因为AI技术的使用案例正在逐渐被发现。在某个领域里有效的AI技术(如视觉处理)不一定适用于另一个领域(例如确定某种气味是危险的还是安全的,抑或是二者的组合)。
NetSpeed Systems营销和业务开发副总裁Anush Mohandass说:“我们在黑暗中摸索,我们知道如何做机器学习和人工智能,但却不知道它们真正的工作方式。目前的方法是使用大量拥有不同计算能力和不同种类的计算引擎——用于神经网络应用的CPU、DSP,你需要确定它是有效的。但这只是第一代AI。重点是计算能力和异构性。”
然而,随着问题的解决变得更有针对性,这有望改变。就像早期版本的物联网器件一样,没有人知道各类市场如何演变,因此系统公司投入了一切,并使用现有的芯片技术将产品推向市场。在智能手表的案例中,结果是电池充电后只能续航几个小时。随着针对这些特定应用的新芯片的开发,功耗和性能会实现平衡,方法是更有针对性的功能、本地处理与云处理之间更智能的分布、以及对于设计中的瓶颈的更深入的理解这三者的结合。
ARM模型技术总监Bill Neifert说:“我们的挑战是找到未知的瓶颈和限制。但根据于工作负载,处理器与软件的交互方式不同,软件本质上是并行应用程序。因此,如果你正在考虑工作负载,如金融建模或天气图,它们强调基础系统的方式是不同的。你只能通过深入探索来理解。”
Neifert指出,软件方面需要解决的问题需要从更高层次的抽象来看,因为这使得它们更容易约束和修复。这是拼图的一个关键部分。随着AI进军更多市场,所有这些技术都需要发展,以达到一般技术行业,特别是半导体行业的同等效率。
Mohandass说:“现在我们发现,如果他们只处理好一种类型的计算,那么架构就会很困难。但异构性的缺点是,将整体分而治之的方法变得土崩瓦解。因此,该解决方案通常涉及到超量供应或供应不足。”
新方法
随着AI的应用案例超越了自动驾驶汽车领域,其应用将会扩展。
这就是为什么英特尔去年八月收购了Nervana。Nervana开发了2.5D深度学习芯片,该芯片利用高性能处理器内核,将数据通过中介层移动到高带宽内存。 Nervana声称的目标是,与基于GPU的解决方案相比,该芯片训练深度学习模型的时间将缩短100倍。
eSilicon营销副总裁Mike Gianfagna说:“这些看起来很像高性能计算芯片,本质上是使用硅中介层的2.5D芯片。你将需要大量的吞吐量和超高带宽内存。我们已经看到一些公司在关注它,但尚不足几十家。它还为时尚早,实现机器学习和自适应算法,以及如何将这些与传感器和信息流整合,是非常复杂的。例如自动驾驶汽车,它从多个不同的来源串流数据并添加自适应算法,以避免碰撞。”
Gianfagna表示,实现这些器件有两个挑战。其一是可靠性和认证。其二是安全。
对于AI,可靠性需要在系统级考虑,其中包括硬件和软件。ARM在12月收购Allinea提供了一个参照。另一个参照来自斯坦福大学,研究人员试图量化来自软件的裁剪计算的影响。他们发现,大规模切割或修剪不会对最终产品产生显着影响。加州大学伯克利分校已经开发了一个类似的方法,基于的计算接近100%的准确率。
正在研究节能深度学习的斯坦福大学博士研究生韩松说“与精粒修剪相比,粗粒修剪不会降低精度。”他表示,斯坦福开发的稀疏矩阵要求计算减少10倍,内存占用减少8倍,比DRAM的能耗减少120倍。它应用于斯坦福所谓的高效语音识别引擎,压缩导致了推理过程的加快。(Cadence最近的嵌入式神经网络峰会上提出了这些发现。)
量子计算为AI系统增加了另一个选择。 Leti首席执行官Marie Semeria表示,量子计算是她的团队未来的方向之一,特别是AI应用。IBM Research的科学与解决方案团队副总裁Dario Gil解释说,使用经典计算,如果四张卡片三蓝一红,那么有四分之一的机会猜中那张红色的卡片。使用量子计算机和量子比特的叠加和纠缠,通过扭转纠缠,系统每次都会给出正确答案。
结论
AI不是一件事,因此没有单一的系统在任何地方都能完美地工作。但AI系统有一些通用要求,如下图所示。
AI在许多市场都有应用,所有这些都需要广泛的改进、昂贵的工具,以及支持它们的生态系统。经过多年来依靠萎缩器件来提高功率、性能和成本,如今整个市场部门都在重新思考如何进入新市场。这对于架构师来说是一个巨大的胜利,这为设计团队增加了巨大的创造性选择,也将刺激从工具和IP供应商一直到包装和流程开发的巨大发展。这就像为技术行业按下了重启按钮,可以证明,这对于未来整个生态系统的业务都是有益的。















 工商网监
工商网监
评论