 电子发烧友App
电子发烧友App


上一次我们用了单隐层的神经网络,效果还可以改善,这一次就使用CNN。
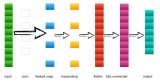
卷积神经网络
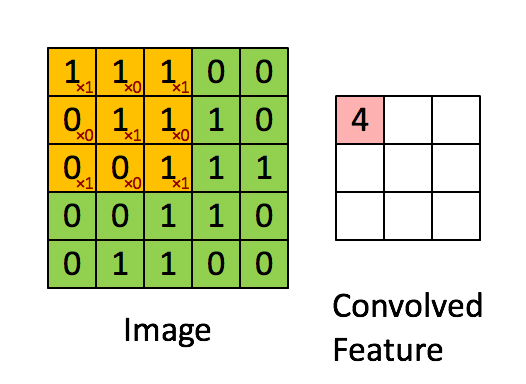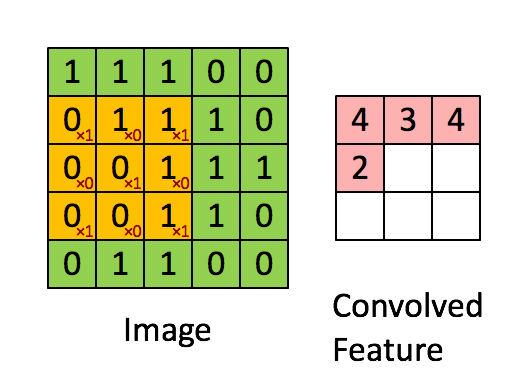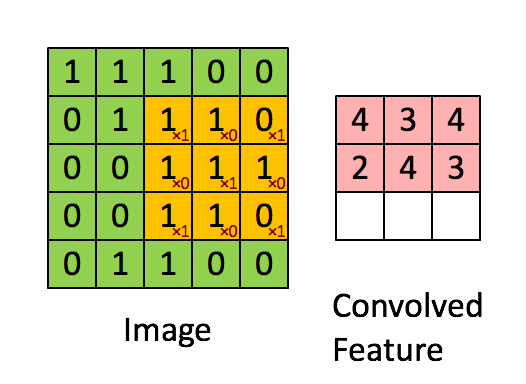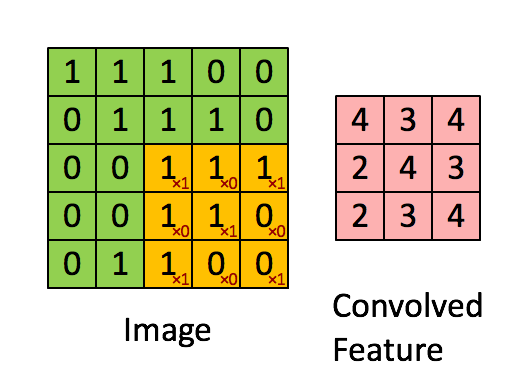
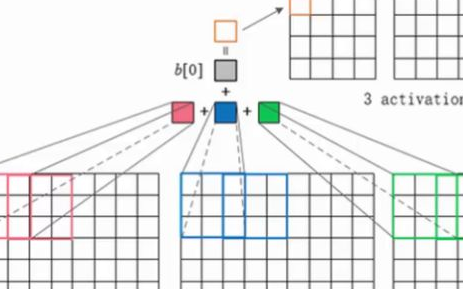
上图演示了卷积操作
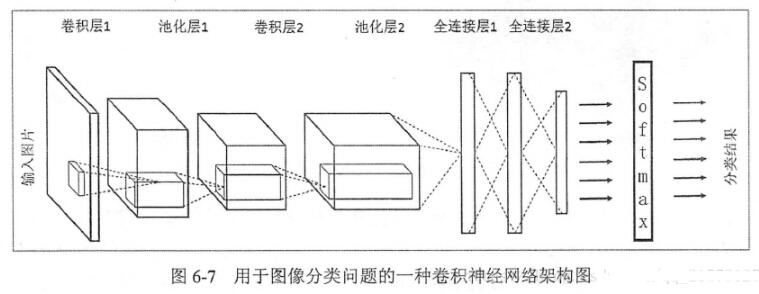
LeNet-5式的卷积神经网络,是计算机视觉领域近期取得的巨大突破的核心。卷积层和之前的全连接层不同,采用了一些技巧来避免过多的参数个数,但保持了模型的描述能力。这些技巧是:
1, 局部联结:神经元仅仅联结前一层神经元的一小部分。
2, 权重共享:在卷积层,神经元子集之间的权重是共享的。(这些神经元的形式被称为特征图[feature map])
3, 池化:对输入进行静态的子采样。
局部性和权重共享的图示
卷积层的单元实际上连接了前一层神经元中的一个2维patch,这个前提让网络利用了输入中的2维结构。
当使用Lasagne中的卷积层时,我们必须进行一些输入准备。输入不再像刚刚一样是一个9216像素强度的扁平向量,而是一个有着(c,0,1)形式的三维矩阵,其中c代表通道(颜色),0和1对应着图像的x和y维度。在我们的问题中,具体的三维矩阵为(1,96,96),因为我们仅仅使用了灰度一个颜色通道。
一个函数load2d对前述的load函数进行了包装,完成这个2维到三维的转变:
def load2d(test=False, cols=None):
X, y = load(test=test)
X = X.reshape(-1, 1, 96, 96)
return X, y
我们将要创建一个具有三个卷积层和两个全连接层的卷积神经网络。每个卷积层都跟着一个2*2的最大化池化层。初始卷积层有32个filter,之后每个卷积层我们把filter的数量翻番。全连接的隐层包含500个神经元。
这里还是一样没有任何形式(惩罚权重或者dropout)的正则化。事实证明当我们使用尺寸非常小的filter,如3*3或2*2,已经起到了非常不错的正则化效果。
代码如下:
net2 = NeuralNet(
layers=[
('input', layers.InputLayer),
('conv1', layers.Conv2DLayer),
('pool1', layers.MaxPool2DLayer),
('conv2', layers.Conv2DLayer),
('pool2', layers.MaxPool2DLayer),
('conv3', layers.Conv2DLayer),
('pool3', layers.MaxPool2DLayer),
('hidden4', layers.DenseLayer),
('hidden5', layers.DenseLayer),
('output', layers.DenseLayer),
],
input_shape=(None, 1, 96, 96),
conv1_num_filters=32, conv1_filter_size=(3, 3), pool1_pool_size=(2, 2),
conv2_num_filters=64, conv2_filter_size=(2, 2), pool2_pool_size=(2, 2),
conv3_num_filters=128, conv3_filter_size=(2, 2), pool3_pool_size=(2, 2),
hidden4_num_units=500, hidden5_num_units=500,
output_num_units=30, output_nonlinearity=None,
update_learning_rate=0.01,
update_momentum=0.9,
regression=True,
max_epochs=1000,
verbose=1,
)
X, y = load2d() # load 2-d data
net2.fit(X, y)
# Training for 1000 epochs will take a while. We'll pickle the
# trained model so that we can load it back later:
import cPickle as pickle
with open('net2.pickle', 'wb') as f:
pickle.dump(net2, f, -1)
训练这个网络和第一个网络相比,将要耗费巨大的时空资源。每次迭代要慢15倍,整个1000次迭代下来要耗费20多分钟的时间,这还是在你有一个相当不错的GPU的基础上。
然而耐心总是得到回馈,我们的模型和结果自然比刚刚好得多。让我们来看一看运行脚本时的输出。首先是输出形状的层列表,注意因为我们选择的窗口尺寸,第一个卷积层的32个filter输出了32张94*94 的特征图。
InputLayer (None, 1, 96, 96) produces 9216 outputs
Conv2DCCLayer (None, 32, 94, 94) produces 282752 outputs
MaxPool2DCCLayer (None, 32, 47, 47) produces 70688 outputs
Conv2DCCLayer (None, 64, 46, 46) produces 135424 outputs
MaxPool2DCCLayer (None, 64, 23, 23) produces 33856 outputs
Conv2DCCLayer (None, 128, 22, 22) produces 61952 outputs
MaxPool2DCCLayer (None, 128, 11, 11) produces 15488 outputs
DenseLayer (None, 500) produces 500 outputs
DenseLayer (None, 500) produces 500 outputs
DenseLayer (None, 30) produces 30 outputs
接下来我们看到,和第一个网络输出相同,是每一次迭代训练损失和验证损失以及他们之间的比率。
Epoch | Train loss | Valid loss | Train / Val
--------|--------------|--------------|----------------
1 | 0.111763 | 0.042740 | 2.614934
2 | 0.018500 | 0.009413 | 1.965295
3 | 0.008598 | 0.007918 | 1.085823
4 | 0.007292 | 0.007284 | 1.001139
5 | 0.006783 | 0.006841 | 0.991525
...
500 | 0.001791 | 0.002013 | 0.889810
501 | 0.001789 | 0.002011 | 0.889433
502 | 0.001786 | 0.002009 | 0.889044
503 | 0.001783 | 0.002007 | 0.888534
504 | 0.001780 | 0.002004 | 0.888095
505 | 0.001777 | 0.002002 | 0.887699
...
995 | 0.001083 | 0.001568 | 0.690497
996 | 0.001082 | 0.001567 | 0.690216
997 | 0.001081 | 0.001567 | 0.689867
998 | 0.001080 | 0.001567 | 0.689595
999 | 0.001080 | 0.001567 | 0.689089
1000 | 0.001079 | 0.001566 | 0.688874
1000次迭代后的结果相对第一个网络,有了非常不错的改善,我们的RMSE也有不错的结果。
>>> np.sqrt(0.001566) * 48
1.8994904579913006












 工商网监
工商网监
评论