 电子发烧友App
电子发烧友App


了解 Q-Learning 的一个好方法,就是将 Catch 游戏和下象棋进行比较。
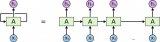
在这两种游戏中,你都会得到一个状态 S。在象棋中,这代表棋盘上棋子的位置。在 Catch 游戏中,这代表水果和篮子的位置。
然后,玩家要采取一个动作,称作 A。在象棋中,玩家要移动一个棋子。而在 Catch 游戏中,这代表着将篮子向左、向右移动,或是保持在当前位置。据此,会得到一些奖励 R 和一个新状态 S'。
Catch 游戏和象棋的一个共同点在于,奖励并不会立即出现在动作之后。
在 Catch 游戏中,只有在水果掉到篮子里或是撞到地板上时你才会获得奖励。而在象棋中,只有在整盘棋赢了或输了之后,才会获得奖励。这也就是说,奖励是稀疏分布的(sparsely distributed)。大多数时候,R 保持为零。
产生的奖励并不总是前一个动作的结果。也许,很早之前采取的某些动作才是获胜的关键。要弄清楚哪个动作对最终的奖励负责,这通常被称为信度分配问题(credit assignment problem)。
由于奖励的延迟性,优秀的象棋选手并不会仅通过最直接可见的奖励来选择他们的落子方式。相反,他们会考虑预期未来奖励(expected future reward),并据此进行选择。例如,他们不仅要考虑下一步是否能够消灭对手的一个棋子。他们也会考虑那些从长远的角度有益的行为。
在 Q-Learning 中,我们根据最高的预期未来奖励选行动。我们使用 Q 函数进行计算。这个数学函数有两个变量:游戏的当前状态和给定的动作。因此,我们可以将其记为 Q(state,action)。在 S 状态下,我们将估计每个可能的动作 A 所带来的的回报。我们假定在采取行动 A 且进入下一个状态 S' 以后,一切都很完美。
对于给定状态 S 和动作 A,预期未来奖励 Q(S,A)被计算为即时奖励 R 加上其后的预期未来奖励 Q(S',A')。我们假设下一个动作 A' 是最优的。
由于未来的不确定性,我们用 γ 因子乘以 Q(S',A')表示折扣:
Q(S,A) = R + γ * max Q(S',A')
象棋高手擅长在心里估算未来回报。换句话说,他们的 Q 函数 Q(S,A)非常精确。大多数象棋训练都是围绕着发展更好的 Q 函数进行的。玩家使用棋谱学习,从而了解特定动作如何发生,以及给定的动作有多大可能会导致胜利。但是,机器如何评估一个 Q 函数的好坏呢?这就是神经网络大展身手的地方了。
最终回归
玩游戏的时候,我们会产生很多「经历」,包括以下几个部分:
初始状态,S
采取的动作,A
获得的奖励,R
下一状态,S'
这些经历就是我们的训练数据。我们可以将估算 Q(S,A)的问题定义为回归问题。为了解决这个问题,我们可以使用神经网络。给定一个由 S 和 A 组成的输入向量,神经网络需要能预测 Q(S,A)的值等于目标:R + γ * max Q(S',A')。
如果我们能很好地预测不同状态 S 和不同行为 A 的 Q(S,A),我们就能很好地逼近 Q 函数。请注意,我们通过与 Q(S,A)相同的神经网络估算 Q(S',A')。
训练过程
给定一批经历
1、对于每个可能的动作 A'(向左、向右、不动),使用神经网络预测预期未来奖励 Q(S',A');
2、选择 3 个预期未来奖励中的最大值,作为 max Q(S',A');
3、计算 r + γ * max Q(S',A'),这就是神经网络的目标值;
4、使用损失函数(loss function)训练神经网络。损失函数可以计算预测值离目标值的距离。此处,我们使用 0.5 * (predicted_Q(S,A)—target)² 作为损失函数。
在游戏过程中,所有的经历都会被存储在回放存储器(replay memory)中。这就像一个存储
classExperienceReplay(object):""" During gameplay all the experiences < s, a, r, s’ > are stored in a replay memory. In training, batches of randomly drawn experiences are used to generate the input and target for training. """def__init__(self, max_memory=100, discount=.9):""" Setup max_memory: the maximum number of experiences we want to store memory: a list of experiences discount: the discount factor for future experience In the memory the information whether the game ended at the state is stored seperately in a nested array [... [experience, game_over] [experience, game_over] ...] """self.max_memory = max_memory self.memory = list() self.discount = discountdefremember(self, states, game_over):#Save a state to memoryself.memory.append([states, game_over])#We don't want to store infinite memories, so if we have too many, we just delete the oldest oneiflen(self.memory) > self.max_memory:delself.memory[0]defget_batch(self, model, batch_size=10):#How many experiences do we have?len_memory = len(self.memory)#Calculate the number of actions that can possibly be taken in the gamenum_actions = model.output_shape[-1]#Dimensions of the game fieldenv_dim = self.memory[0][0][0].shape[1]#We want to return an input and target vector with inputs from an observed state...inputs = np.zeros((min(len_memory, batch_size), env_dim))#...and the target r + gamma * max Q(s’,a’)#Note that our target is a matrix, with possible fields not only for the action taken but also#for the other possible actions. The actions not take the same value as the prediction to not affect themtargets = np.zeros((inputs.shape[0], num_actions))#We draw states to learn from randomlyfori, idxinenumerate(np.random.randint(0, len_memory, size=inputs.shape[0])):""" Here we load one transition
定义模型











 工商网监
工商网监
评论