 电子发烧友App
电子发烧友App


2017年终解读:语音识别技术今年只走了一半的路
这一年,百度开放了语音平台DuerOS,阿里补贴了4个亿销售百万智能音箱抢占语音入口。而作为语音识别的先驱龙头,大家开始担心科大讯飞用近二十年建立起来的技术壁垒被摧毁,有人扒讯飞的业务,有人开始扒讯飞十年的财报。
这一年的人工智能大潮,无疑让更多人关注科大讯飞,关心在这样的潮流里,一家深耕语音识别的公司如何能获得更多业务和利润,如何能去迎合AI上升的趋势,从而满足人们对人工智能的所有期望。
其实这一年,技术的进程还是和往年一样。(我们从语音识别的角度来解读2017年的进展,部分技术解读来源自对讯飞的采访)。
2017,从数据提升开始说起
去年IBM、微软、谷歌和百度都发布过自家语音识别进展,而今年对媒体更新词错率进展的有三家:
2017年3月,IBM结合了 LSTM 模型和带有 3 个强声学模型的 WaveNet 语言模型。“集中扩展深度学习应用技术终于取得了 5.5% 词错率的突破”。相对应的是去年5月的6.9%。
2017年8月,微软发布新的里程碑,通过改进微软语音识别系统中基于神经网络的听觉和语言模型,在去年基础上降低了大约12%的出错率,词错率为5.1%,声称超过专业速记员。相对应的是去年10月的5.9%,声称超过人类。
2017年12月,谷歌发布全新端到端语音识别系统(State-of-the-art Speech Recognition With Sequence-to-Sequence Models),词错率降低至5.6%。相对于强大的传统系统有 16% 的性能提升。
大家的目标很一致,就是想“超过人类”,之前设定人类词错率为5.9%的这个界线。
总结来说,因为Deep CNN引入之后,语音识别取得了很大的突破,例如谷歌从2013年到现在,性能提升了20%。
而国内语音识别的企业如百度、搜狗、科大讯飞,识别率都在97%左右。在语音识别这件事情上,汉语比英语早一年超越人类水平。
去年,科大讯飞又推出了全新的深度全序列卷积神经网络(DFCNN)语音识别框架,该框架的表现比学术界和工业界最好的双向 RNN 语音识别系统识别率提升了15% 以上。今年,在实际应用领域,讯飞输入法的识别准确率在今年7月份也终于突破了97%,达到了98%。
技术“可用”是第一步,但技术最终是要落地的,变成产品和服务才能实现价值。
今年技术应用场景有什么变化?
今年的产品落地,让人联想到的首先肯定是智能音箱。
2016年的数据统计表明,中国智能音箱销售量占全球比重为0.35%,6万:1710万台的差距。在2017年双十一阿里的补贴销售之后,终于可以说“中国智能音箱销量在百万以上”,“中国的智能音箱得到了爆炸式的增长”。但从需求上说,智能音箱的功能集中在听音乐、闹钟、智能家居等,这些功能并不属于国人的“刚需”。BAT巨头都将智能音箱作为语音入口进行抢占,也给了我们一种爆发的假象。
但这一年,应用场景无疑是越来越丰富。基于各个领域的应用拓展,智能语音技术已经走出安静的室内或者私人环境,走上了服务大厅、卖场及行驶中的汽车等。技术的应用也越来越深入。机器翻译、远场识别、智能降噪、多轮交互、智能打断等技术的进步,也又给智能语音的应用场景带来了更多的变化。
在智能车载领域,2017年科大讯飞发布的飞鱼系统2.0,融合了 Barge-in全双工语音交互技术,窄波束定向识别技术,自然语义理解技术,免唤醒技术,多轮对话技术等科大讯飞核心技术。目前,科大讯飞已经为超过200款车型,累计超过1000万部车辆输出了语音交互产品。
此外,在新零售领域,智能语音技术的应用也在不断扩展。比如12月18日,科大讯飞和红星美凯龙发布战略合作计划,未来由科大讯飞研发的智能导购机器人“美美”将在全国红星美凯龙门店上市。
语音识别六十年,技术突破总是艰难而缓慢
语音识别的研究起源可以追溯到上世纪50年代,AT&T贝尔实验室的Audry系统率先实现了十个英文数字识别。
从上世纪60年代开始,CMU的Reddy开始进行连续语音识别的开创性工作。但是这期间进展缓慢,以至于贝尔实验室的约翰·皮尔斯(John Pierce)认为语音识别是几乎不可能实现的事情。
上世纪70年代,计算机性能的提升,以及模式识别基础研究的发展,促进了语音识别的发展。IBM、贝尔实验室相继推出了实时的PC端孤立词识别系统。
上世纪80年代是语音识别快速发展的时期,引入了隐马尔科夫模型(HMM)。此时语音识别开始从孤立词识别系统向大词汇量连续语音识别系统发展。
上世纪90年代是语音识别基本成熟的时期,但是识别效果离实用化还相差甚远,语音识别的研究陷入了瓶颈。
关键突破起始于2006年。这一年辛顿(Hinton)提出深度置信网络(DBN),促使了深度神经网络(Deep Neural Network,DNN)研究的复苏,掀起了深度学习的热潮。2009年,辛顿以及他的学生默罕默德(D. Mohamed)将深度神经网络应用于语音的声学建模,在小词汇量连续语音识别数据库TIMIT上获得成功。2011年,微软研究院俞栋、邓力等发表深度神经网络在语音识别上的应用文章,在大词汇量连续语音识别任务上获得突破。国内外巨头大力开展语音识别研究。
科大讯飞的智能语音探索之路
科大讯飞在2010年首批开展DNN语音识别研究,2011年上线了全球首个中文语音识别DNN系统。2012年,在语音合成领域首创RBM技术。2013年又在语种识别领域首创BN-ivec技术。2014年科大讯飞开始深度布局NLP领域,2015年,RNN语音识别系统全面升级。
2016年,上线DFCNN(深度全序列卷积神经网络,Deep Fully Convolutional Neural Network)语音识别系统。在和其他多个技术点结合后,科大讯飞DFCNN的语音识别框架在内部数千小时的中文语音短信听写任务上,相比目前业界最好的语音识别框架双向RNN-CTC系统获得了15%的性能提升,同时结合科大讯飞的HPC平台和多GPU并行加速技术,训练速度也优于传统的双向RNN-CTC系统。DFCNN的提出开辟了语音识别的一片新天地,后续基于DFCNN框架,还将展开更多相关的研究工作。
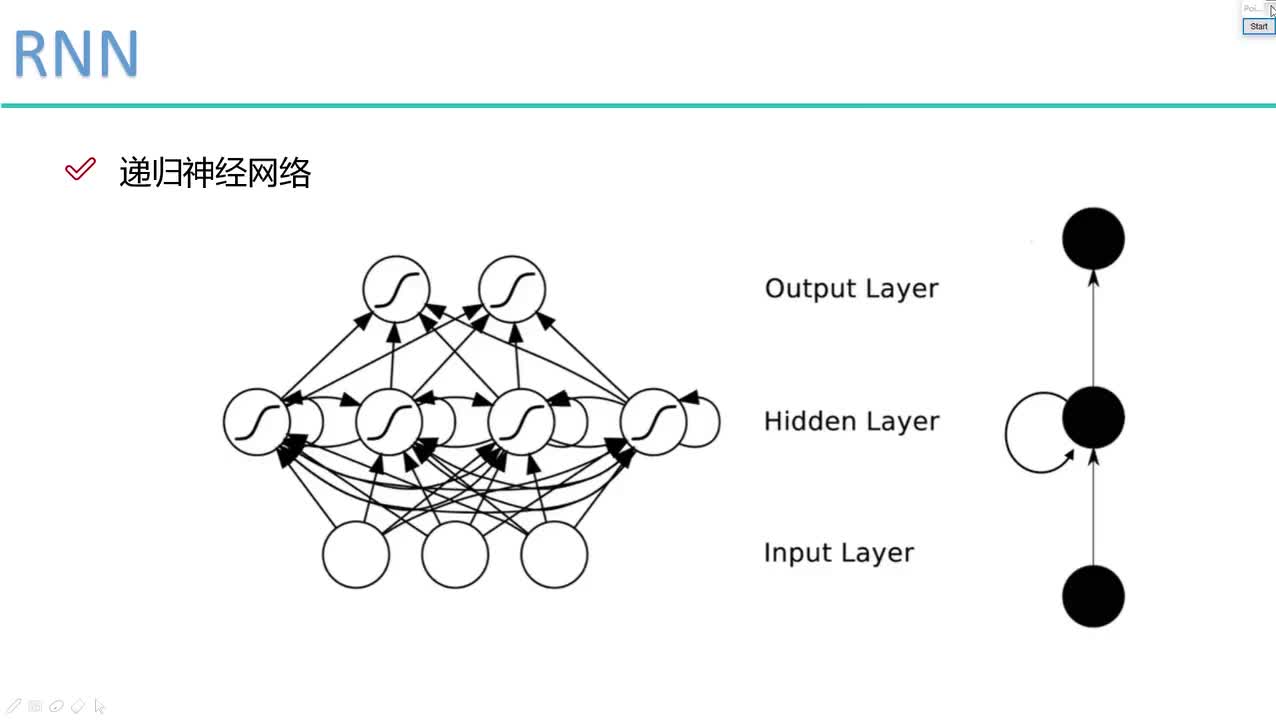
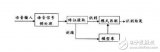
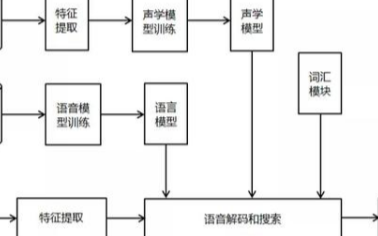
(图1)DFCNN的结构如图所示,它直接将一句语音转化成一张语谱图作为输入,即先对每帧语音进行傅里叶变换,再将时间和频率作为图像的两个维度,然后通过非常多的卷积层和池化(pooling)层的组合,对整句语音进行建模,输出单元直接与最终的识别结果比如音节或者汉字相对应。
(图2)
在语音识别子领域上,今年科大讯飞的智能语音技术所取得的代表性的成就在自然语言理解领域。7月份,哈工大讯飞实验室(HFL)刷新了斯坦福大学发起的SQuAD(Stanford Question Answering Dataset)机器阅读理解挑战赛全球纪录,提交的“基于交互式层叠注意力模型”(Interactive Attention-over-Attention Model)取得了精确匹配77.845%和模糊匹配85.297%的成绩,位列世界第一,也是中国本土研究机构首次取得赛事榜首。
语音合成上,暴风雪竞赛(Blizzard Challenge)是国际最权威的语音合成比赛。科大讯飞以语音合成技术率先达到4.0分的成绩并连续12年蝉联全球第一名,这是全世界唯一能让语音合成技术能够达到真人说话水平的系统。5.0分代表播音员的水平,4.0分代表美国普通老百姓的发音水平。
在人机交互系统上,科大讯飞于11月发布了AIUI2.0系统,支持远场降噪、方言识别和多轮对话的技术的基础上又增加了主动式对话、多模态交互、自适应、个性化识别等能力并能在嘈杂会场完成全双工翻译功能。
而科大讯飞的云端语音开放平台,截至2017年12月,累计终端数达到15亿,日均交互次数达到40亿,开发者团队数已达50万。
语音识别还有哪些没有解决的问题?
深度学习应用到语音识别领域之后,词错率有显著降低,但是并不代表解决了语音识别的所有问题。认识这些问题,想办法去解决,是语音识别能够取得进步的关键所在,将 ASR(自动语音识别)从“大部分时间仅适用于一部分人”发展到“在任何时候适用于任何人”。
1.口音和噪声
语音识别中最明显的一个缺陷就是对口音和背景噪声的处理。最直接的原因是大部分的训练数据都是高信噪比、带有口音的语言。比如单是为美式口音英语构建一个高质量的语音识别器就需要 5000 小时以上的转录音频,因而仅凭训练数据很难解决掉这个问题。
在中国,口音问题解决得比较好的,是科大讯飞。科大讯飞目前推出了22种方言相关的语音识别系统,但对于那些音素体系与汉语不同的方言或外国语种,在成本问题上还没有很好的办法。
2.多人会话
每个说话人使用独立的麦克风进行录音,在同一段音频流中不存在多个说话人的语音重叠,这种情况下的语音识别任务比较容易。然而,人类即使在多个说话人同时说话的时候也能够理解说话内容。一个好的会话语音识别器必须能够根据谁在说话对音频进行划分(Diarisation),还应该理解多个说话人语音重叠的音频(声源分离)。
在利用语音技术推动输入和交互模式变革的过程中,仍面临这些阻碍。多人对话等场景下的语音识别率虽然很高,声纹识别虽然也已经在实验室实现,但距离实际应用还有一些距离。
3.认知智能
语音识别技术在质检、安全等方面有很好的应用,但是对于人类所希望达到100%的识别率来说,从科研角度看肯定还有很多需要继续努力的地方。比如减少语义错误、理解上下文上(机器的学习和推理),我们才仅触及皮毛。“ 认知智能有没有真正的突破,是这一轮人工智能热潮——包括产业化热潮——能不能进一步打开天花板、进一步形成更大规模的产业的关键技术所在”,2017年底,科技部正式发文将依托科大讯飞建立首个认知智能国家重点实验室。
未来五年内,语音识别领域仍然存在许多开放性和挑战性的问题,如,在新地区、口音、远场和低信噪比语音方面的能力扩展;在识别过程中引入更多的上下文;Diarisation 和声源分离;评价语音识别的语义错误率和创新方法;超低延迟和高效推理等。尽管语音识别目前成果斐然,但剩下的难题和已克服的一样令人生畏。虽然近几年深度神经网络的兴起使得语音识别性能获得了极大的提升,但是我们并不能迷信于现有的技术,总有一天新技术的提出会替代现有的技术。
除技术外,一个AI企业的那些事儿
人工智能催生了大量新技术、新企业和新业态,人工智能火热背景下, 作为A股人工智能龙头股科大讯飞,曾在一个月猛增360多亿元,市值突破千亿。似乎很正契合普通百姓对“AI”神化的认知。
2017年11月15日,中国新一代人工智能发展规划暨重大科技项目启动会在京召开,科技部公布我国第一批国家人工智能开放创新平台,包括:1、依托百度公司建设自动驾驶国家新一代人工智能开放创新平台;2、依托阿里云公司建设城市大脑国家新一代人工智能开放创新平台;3、依托腾讯公司建设医疗影像国家新一代人工智能开放创新平台;4、依托科大讯飞公司建设智能语音国家新一代人工智能开放创新平台。作为首批入选国家新一代人工智能开放创新平台,目前的科大讯飞,用刘庆峰的话说是“现在还未到达登顶的状态,只能说是已经开始登山,刚克服了爬坡之后的艰难,开始到慢慢适应的状态”,如同语音识别技术现状。
人工智能是个大趋势,本身也是需要很重投入的,但它也会有更长远的影响,所以不能特别短视于此时此刻的回报上。“必须具备了强技术,才能形成刚需”,“就是要把技术做深做透,做到大家真正觉得有刚需”,刘庆峰说,“我们瞄准着五到十年更前沿的技术研究”。











 工商网监
工商网监
评论