 电子发烧友App
电子发烧友App


2016年,一场风风火火的人机大战,谷歌旗下DeepMind的围棋程序AlphaGo以5局4胜的大比分赢得胜利,掀起了全世界人民,尤其是中国老百姓,对于AI前所未有的热潮,深度学习的概念也从实验室、教科书首次进入了普通大众的视野。不少人通过互联网,第一次了解到AI的魅力。但是,AI的应用远不止互联网企业这么简单,它已经渗透到安防、公安ISV、研究机构、金融、医疗等各行各业。
纵观整个2017年,互联网圈里提到最多的一个词一定是“人工智能”,而且这个“人工智能”已经不仅是2016年那个很会下棋的AlphaGo,它成了无所不能的助手管家,能和你对话(智能音响),能帮公安抓人(人脸识别),也开始抢老司机的活儿(无人驾驶)。如今的人工智能早已不再是70多年前的那个“它”了。
中国制造2025——智能制造工程
中国制造2025战略中,智能制造是一个非常关键的奋斗目标。到2020年,制造业重点领域智能化水平显著提升,试点示范项目运营成本降低30%,产品生产周期缩短30%,不良品率降低30%。到2025年,制造业重点领域全面实现智能化,试点示范项目运营成本降低50%,产品生产周期缩短50%,不良品率降低50%。
智能制造工程推动制造业智能转型,推进产业迈向中高端;高端装备创新工程以突破一批重大装备的产业化应用为重点,为各行业升级提供先进的生产工具。重点聚焦“五三五十”重点任务,即:攻克五类关键技术装备,夯实智能制造三大基础,培育推广五种智能制造新模式,推进十大重点领域智能制造成套装备集成应用。
那么,如何加速智能制造的发展进度?尽快实现广泛的行业领域应用呢?
容错服务器专家的观点认为,以边缘计算引领人工智能的发展,将有力的推动制造智能化进程,并且让人工智能更加“聪明”。
目前,受过训练的人工智能系统,在特定领域的表现已可超越人类,而相关软件技术迅速发展的背后,边缘计算解决方法的运用让人工智能变得更加强大。物联网(IoT)将可望进化成AIoT(AI+IoT)。 智能机器人的遍地开花可能还只是个开端,人工智能终端的边缘运算能力,其所将带来的价值更让人引颈期盼。
容错边缘计算团队认为,基于边缘计算解决方案的人工智能终端,将在各行各业带来变革,从而改变未来的走向。传统人工智能运算的硬件架构,主要包括中央处理器(CPU)、图型处理器(GPU)、现场可编程数组(FPGA)等。
特定领域的专用人工智能系统,由于应用背景需求明确、深厚之领域知识、模型建立计算简单可行,在单项测试之智能水平,目前已可超越人类智能,在许多领域取得具体成效。如今的技术挑战在于,如何发展低功耗、高准确率的认知计算,包括新型运算架构电路设计、算法等。 未来人工智能将由特定的算法加速器,来加速包括卷积神经网络(Convolution Neutral Network)、递归神经网络(Recursive Neutral Network)在内的各种神经网络算法。边缘计算推动人工智能实现变革性发展,这是实现智能制造必须跨过的一步。
虽然目前人工智能领域的主流研究是在服务器上的人工智能运算,但有越来越多应用产品须在终端上进行实时运算,此种技术便是边缘运算的运用。这个发展趋势将改变整体人工智能运算系统架构的设计与技术需求。
容错专家认为,人工智能在边缘侧的不断扩展,是驾驭数据洪流的关键环节之一,也是物联网未来发展的重要趋势。随着人工智能如火如荼的发展,海量数据需要快速有效地分析和提取洞察,这也大大加强了对于边缘计算的需求。
两个问题值得思考,首先是边缘侧趋向负载整合。以前的数据很多都是结构化数据,可以通过Excel表格或者简单的关系型数据库对其进行维护和管理。但今后会有越来越多的非结构化数据需要进行处理并借此发现内在关联,这时就需要边缘计算和人工智能技术。
其次,构建边缘协同的端到端系统。在一个边缘协同的端到端系统中,由于不同网源的功耗、计算性能和所能承担的成本各不相同,因此在选取硬件架构时往往会有特定要求。要根据用户需求提供不同架构的解决方案,涵盖至强处理器、至强融核处理器、Movidius/Nervana神经网络处理器和FPGA、网络以及存储技术等硬件平台,以及多种软件工具及函数库,优化开源框架,来让他们进行自主选择。
容错服务器及容错软件,具有ftServer 的Lock Step和 everRun Check Point技术, 在实时性,可靠性,安全私密性上有独特的优势,在已经有广泛的工业自动化 (IA) 客户应用的基础之上, 助力边缘计算产业创新技术的落地。
容错服务器,在中国制造2025的奋斗目标下,协助边缘计算产业联盟建立开放与创新的平台、行业践行与示范的平台。携手人工智能技术,加速中国制造2025实现进程。
如何搭建一套高效的AI计算平台?
早在1950年,图灵在论文中探讨了机器智能的问题,并提出了著名的图灵测试,1956年达特茅斯的讨论会上,人工智能这一概念由此诞生。几十年中,人工智能曾大起大落,原因为何?
“数据”先背一个锅,最早的人工智能也可以称之为专家系统,也就是把专家们的所有理论、方法全都录入到计算机,在具体执行任务的时候,计算机会检索数据库中相似的内容,如果没有,那么它就无能为力了。
然后是算法,类似于数据库检索的算法可能只能称之为一个笨办法,但20世纪90年代,神经网络的概念就成为热点,人工智能却没有取得长足的进展。这是因为受限于另一个重要因素-计算。由于硬件计算平台的限制,十余年间的进展极其缓慢,直到以GPU为核心的协处理加速设备的应用,人工智能应用效率才得以大大提升。
近年来,众多企业都已经看到了AI未来的前景,想纷纷踏入这篇沃土,孕育新的商机。想要跨进这个新领域,首先要做的,是要拥有一套好的AI架构。那么如何打造最优的AI计算平台?怎样的AI计算硬件架构更高效?AI 更注重哪些性能指标?
要把AI练好要分三步,即“数据预处理——模型训练——识别推理”。三个过程分别对应不同的计算特点:数据预处理,对IO要求较高;模型训练的并行计算量很大,且通信也相对密集;推理识别则需要较高的吞吐处理能力和对单个样本低延时的响应。
当我们知道了AI计算的特性之后,我们通过实测数据来看看人工智能计算对于服务器的硬件性能诉求有什么样的特点:
CPU和GPU谁是AI计算的主力军?
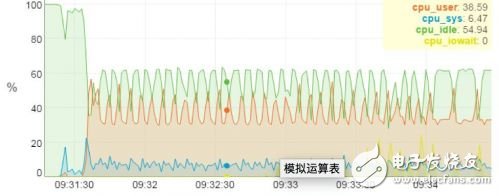

▼ CPU和GPU负载实测数据▼
上图是一个搭载4块GPU卡服务器上运行Alexnet神经网络的测试分析图,从图上我们可以很清楚的看到计算的任务主要由GPU承担,4块GPU卡的负载基本上都接近10%,而CPU的负载率只有不到40%。由此可见, AI计算的计算量主要都在GPU加速卡上。
内存和显存,越大越好吗?
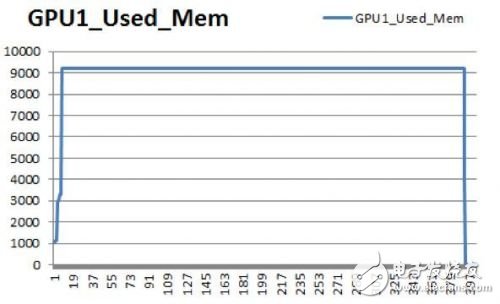

▼ 内存和显存负载实测数据▼
同样的测试环境,内存容量固定时,总容量需求随Batch size扩大而增加,Alexnet模型,Batch size为256时,占用CPU内存60GB,GPU显存9GB。
这样看,AI计算对于CPU内存和GPU显存容量的需求都很大。
磁盘IO,在模型训练过程中要求并不太高

▼ 磁盘IO实测数据▼
通过上图我们可以看到,磁盘IO是一次读,多次写,在Alexnet模型下,磁盘读带宽85MB/s,写带宽0.5MB/s。所以, 在模型训练阶段,磁盘的IO并不是AI计算的瓶颈点。
PCIE带宽,“路”越宽越不堵
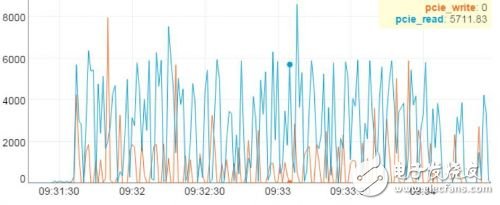
▼ PCIE带宽负载实测数据▼
最后,我们再看看AI计算对于PCIE带宽的占用情况。图上显示,带宽与训练数据规模成正比。测试中,PCIE持续读带宽达到5.7GB/s,峰值带宽超过8GB/s,因此PCIE的带宽将是AI计算的关键瓶颈点。
于是,我们可以得出几个结论:
1. 数据预处理阶段需要提高小文件的随机读写性能
2. 模型训练阶段需要提升并行计算能力
3. 线上推理阶段需要提升批量模型推理的吞吐效率
用高计算性能的CPU服务器+高性能存储,解决小文件随机读取难题
数据预处理的主要任务是处理缺失值,光滑噪声数据,识别或删除利群点,解决数据的不一致性。这些任务可以利用基于CPU服务器来实现,比如浪潮SA5212M5这种最新型2U服务器,搭载最新一代英特尔至强可扩展处理器,支持Intel Skylake平台3/4/5/6/8全系处理器,支持全新的微处理架构,AVX512指令集可提供上一代2倍的FLOPs/core,多达28个内核及56线程,计算性能可达到上一代的1.3倍,能够快速实现数据的预处理任务。
在存储方面,可以采用HDFS(Hadoop分布式文件系统)存储架构来设计。HDFS是使用Java实现分布式的、可横向扩展的文件系统,因为深度学习天生用于处理大数据任务,很多场景下,深度学习框架需要对接HDFS。通过浪潮SA5224M4服务器组成高效、可扩展的存储集群,在满足AI计算分布式存储应用的基础上,最大可能降低整个系统的TCO。
▼ 浪潮SA5224M4 4U36盘位存储服务器 ▼
SA5224M4一款4U36盘位的存储型服务器,在4U的空间内支持36块大容量硬盘。并且相比传统的双路E5存储服务器,功耗降低35W以上。同时,通过背板Expander芯片的带宽加速技术,显著提升大容量SATA盘的性能表现,更适合构建AI所需要的HDFS存储系统。
用GPU服务器实现更快速、精准的AI模型训练
从内部结构上来看,CPU中70%晶体管都是用来构建Cache(高速缓冲存储器)和一部分控制单元,负责逻辑运算的部分并不多,控制单元等模块的存在都是为了保证指令能够一条接一条的有序执行,这种通用性结构对于传统的编程计算模式非常适合,但对于并不需要太多的程序指令,却需要海量数据运算的深度学习计算需求,这种结构就显得有心无力了。
与 CPU 少量的逻辑运算单元相比,GPU设备整个就是一个庞大的计算矩阵,动辄具有数以千计的计算核心、可实现 10-100 倍应用吞吐量,而且它还支持对深度学习至关重要的并行计算能力,可以比传统处理器更加快速,大大加快了训练过程。
根据不同规模的AI模型训练场景,可能会用到2卡、4卡、8卡甚至到64卡以上的AI计算集群。在AI计算服务器方面,浪潮也拥有业界最全的产品阵列。既拥有NF5280M5、AGX-2、NF6248等传统的GPU/KNL服务器以及FPGA卡等,也包含了创新的GX4、SR-AI整机柜服务器等独立加速计算模块。

浪潮AI计算服务器阵列
其中,SR-AI整机柜服务器面向超大规模线下模型训练,能够实现单节点16卡、单物理集群64卡的超高密扩展能力;GX4是能够覆盖全AI应用场景的创新架构产品,可以通过标准机架服务器连接协处理器计算扩展模块的形式完成计算性能扩展,满足AI云、深度学习模型训练和线上推理等各种AI应用场景对计算架构性能、功耗的不同需求;AGX-2是2U8 NVLinkGPU全球密度最高、性能最强的AI平台,面向需要更高空间密度比AI算法和应用服务商。
根据业务应用的需要,选择不同规模的GPU服务器集群,从而平衡计算能力和成本,达到最优的TCO和最佳的计算效率。
用FPGA来实现更低延迟、更高吞吐量的线上推理
GPU在深度学习算法模型训练上非常高效,但在推理时一次性只能对于一个输入项进行处理,并行计算的优势不能发挥出来。而FPGA正是强在推断。大幅提升推断效率的同时,还要最小限度损失精确性,这正是FPGA的强项。
▼ 业界支持OpenCL的最高密度最高性能的FPGA-浪潮F10A▼
以浪潮F10A为例,这是目前业界支持OpenCL的最高密度最高性能的FPGA加速设备,单芯片峰值运算能力达到了1.5TFlops,功耗却只需35W,每瓦特性能到42GFlops。
测试数据显示,在语音识别应用下,浪潮F10A较CPU性能加速2.87倍,而功耗相当于CPU的15.7%,性能功耗比提升18倍。在图片识别分类应用上,相比GPU能够提升10倍以上。
通过CPU、GPU、FPGA等不同计算设备的组合,充分发挥各自在不同方向的优势,才能够形成一套高效的AI计算平台。然后选择一个合适的框架,运用最优的算法,就能够实现人工智能应用的快速落地和精准服务。









 工商网监
工商网监
评论