 电子发烧友App
电子发烧友App


引子
系统的学习机器学习课程让我觉得受益匪浅,有些基础问题的认识我觉得是非常有必要的,比如机器学习算法的类别。
为什么这么说呢?我承认,作为初学者,可能无法在初期对一个学习的对象有全面而清晰的理解和审视,但是,对一些关键概念有一个初步并且较为清晰的认识,有助于让我们把握对问题的认识层次,说白了,就是帮助我们有目的的去学习新的知识,带着问题去学习,充满对解决问题的动力去实验,我觉得这种方式是有益并且良性的。
之前,我遇到过很多这方面的问题,可能出于对问题分析不够,在寻找解决的问题的方法或者模型的时候,有可能不知所措。造成这种情况的原因可能有两点:1、基础不深厚,不了解最常用的算法模型;2、学习过程中,缺乏对模型适用的实际问题的了解,缺乏将模型应用于实际问题的经验。
所以,在学习过程中,要特别注意的不光是深入研究算法的精髓,还要知道该算法的应用场合、适用条件和局限性。如果只是去探究原理,而不懂实际应用,只能是书呆子,只会纸上谈兵;如果只想拿来用,不去深究算法精髓,又只能游离在核心技术的边界,无法真正的领悟。只有结合理论和实践,才可以达到学习效果的最大化。从这条路径出发,一定要坚持不懈。
输入空间、特征空间和输出空间
输入空间和输出空间其实就是输入和输出所有可能取值的集合。输入和输出空间可以是有限元素的集合,也可以是整个欧式空间。输入空间和输出空间可以是一个空间,也可以是不同的空间;通常情况下,输出空间要远远小于输入空间。
特征空间是所有特征向量存在的空间。特征空间的每一维对应于一个特征。有时假设输入空间与特征空间为相同的空间,对它们不予区分;有时假设输入空间与特征空间为不同的空间,将实例从输入空间映射到特征空间。模型实际上都是定义在特征空间上的。
这就为机器学习算法的分类提供了很好的依据,可以根据输入空间、特征空间和输出空间的具体情况的不同,对算法限定的具体条件进行分类。
各种学习型算法的分类
首先声明一下,下面的分类是我在学习相关课程和自己学习过程中进行的归纳,不尽完善,但是可以概括一定的问题,希望在此能总结一下,以备以后能理清思路并完善。
接下来介绍的算法的分类是根据初学者学习的内容的普遍角度展开的,分类角度从常用的分类方式到相对陌生的分类方式。
以输出空间的不同作为分类依据
二类分类(binary classification),俗称是非问题(say YES/NO)。其输出空间Y={-1,+1}
多类别分类(multiclass classification),输出空间Y={1,2,...,K}
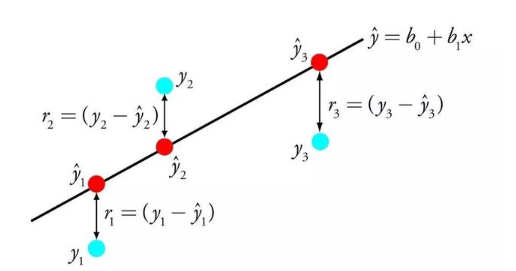
回归问题(regression),输出空间Y=R,即实数范围,输出是无限种可能
结构学习(structured learning),Y=structures,该学习模型也可以看做是多类别学习的一种,这里可能涉及到数量很大的类别
举例:
二类分类应用非常广泛,比如判断是否为垃圾邮件、广告投资是否能盈利、学习系统上在下一题答题是否正确。二类分类在机器学习中地位非常重要,是其他算法的基矗
多类别分类的应用,比如根据一张图片,得出图片中是苹果、橘子还是草莓等;还有像Google邮箱,将邮件自动分成垃圾邮件、重要邮件、社交邮件、促销邮件等。多类别分类在视觉或听觉的辨识中应用很广泛。
回归分析在股票价格预测和天气气温的预测上被广泛应用。
结构学习(Structured Learning)
在自然语言处理中,自动的词性标注是很典型的结构学习的例子。比如给定机器一个句子,由于词语在不同的句子当中可能会有不同的词性,所以该方法是用来对句子的结构特性的理解。这种学习方法可以被看做是多类别分类,但与多类别分类不同的是,其目标的结构种类可能规模很大,其类别是隐藏在句子的背后的。
这种结构学习的例子还有例如说,生物中蛋白质3D立体结构,自然语言处理方面。
结构学习在有些地方被描述成标注(tagging)问题,标注问题的输入是一个观测序列,输出是一个标记序列或状态序列。标注问题的目标在于学习一个模型,使它能够对观测序列给出标记序列作为预测。
以数据标签的不同作为分类依据
按照这种分类方法,最常见的类别就是监督学习(supervised learning)、无监督学习(unsupervised learning)和半监督学习(semi-supervised learning)。在上面讨论的以输出空间的不同作为分类依据中,介绍的基本都是监督学习,下面我们来具体看看另外两个。
无监督学习(unsupervised learning)
聚类(clustering),{x[n]} => cluster(x) , 这里数据的类别是不知道的,根据某种规则得到不同的分类。
它可以近似看做无监督的多类别分类。
密度估计(density estimation),{x[n]} => density(x) ,这里的density(x) 可以是一个概率密度函数或者概率函数。
它可以近似看做无监督的有界回归问题。
异常检测(outlier detection), {x[n]} => unusual(x) 。
它可以看做近似的无监督二类分类问题。
聚类的例子像是将网络上各式各样的文章分成不同的主题,商业公司根据不同的顾客的资料,将顾客分成不同的族群,进而采取不同的促销策略。
密度估计的典型例子是根据位置的交通情况报告,预测事故危险多发的区域。
异常检测的例子是,根据网络的日志的情况,检测是否有异常入侵行为,这是一个极端的“是非题”,可以用非监督的方法来得出。
半监督学习(Semi-supervised learning)
半监督学习(Semi-supervised Learning)是监督学习与无监督学习相结合的一种学习方法。它主要考虑如何利用少量的标注样本和大量的未标注样本进行训练和分类的问题。半监督学习是利用未标记的大量数据提升机器学习算法的表现效果。
半监督学习的主要算法有五类:基于概率的算法;在现有监督算法基础上作修改的方法;直接依赖于聚类假设的方法;基于多试图的方法;基于图的方法。
半监督学习的例子,比如Facebook上有关人脸照片的识别,可能只有一小部分人脸是被标记的,大部分是没有被标记的。
增强学习(Reinforce learning)
强化学习是一种以环境反馈作为输入的、特殊的、适应环境的机器学习方法。所谓强化学习是指从环境状态到行为映射的学习,以使系统行为从环境中获得的累积奖赏值最大。该方法不同与监督学习技术那样通过正例、反例来告知采取何种行为,而是通过试错(trial-and-error)的方法来发现最优行为策略。
这里的输出并不一定是你真正想要得到的输出,而是用过奖励或者惩罚的方式来告诉这个系统做的好还是不好。
比如一个线上广告系统,可以看做是顾客在训练这个广告系统。这个系统给顾客投放一个广告,即可能的输出,而顾客有没有点或者有没有因为这个广告赚钱,这评定了这个广告投放的好坏。这就让该广告系统学习到怎么样去放更适合的广告。
以与机器沟通方式的不同作为分类依据
批量学习(batch learning),一次性批量输入给学习算法,可以被形象的称为填鸭式学习。
线上学习(online learning),按照顺序,循序的学习,不断的去修正模型,进行优化。
hypothesis 'improves' through receiving data instances sequentially
前两种学习算法分类可以被看做是被动的学习算法。
主动学习(active learning),可以被看做是机器有问问题的能力,指定输入x[n],询问其输出y[n]
improve hypothesis with fewer labels (hopefully) by asking questions strategically
当label的获取成本非常昂贵时,会利用此法
很多机器学习大都是批量学习的情况。
线上学习的例子有像是垃圾邮件过滤器中,邮件并不是一下子全部拿来训练并且辨识的,而是呈序列形式,一封一封的到来,这样子循序学习的方式不断更新。
主动学习的一个简单例子是,像QQ空间中,有好友照片的标注,即机器向人提问问题。
以输入空间的不同作为分类依据
具体特征(concrete features),输入X的每一维特征都被人类进行的整理和分析,这种分析常常是与专业领域关联的
原始特征(raw features),需要人或者机器进行转化,将原始特征转化成为具体的特征,在机器视觉和声音信号的辨识都是属于该类
抽象特征(abstract features),
抽象特征的例子,比如在一个在线教学系统中学生的编号信息,还有广告系统中广告的编号ID。使用它们都需要更多特征抽取的动作。
原始特征的补充
这里要补充一下raw features中有关时兴的深度学习(deep learning)的有关知识。
深度学习是通过机器自动的进行特征提取的。它需要有大量的资料或者非监督式学习的方式去学习如何从中抽取出非常具体的特征。
深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
以上是我在初学阶段针对学习型算法的类别简述,可能有失准确的地方,还需要读者自行分析判断。最后,我还想对自己说一下,我在学习的过程中,不必追求将记录的内容表述的尽可能的细致全面,而是要在记录书写文字的过程中真正能加深对问题的理解,不断的进行自我思考。毕竟,我写这些内容不是为了出书,而是要灵活的积累学习中的关键内容,进行更好的知识管理。当然,如果能帮助到读者就更好了。




















 工商网监
工商网监
评论