K-means 算法是典型的基于距离的聚类算法,采用距离作为相似性的评价指标,两个对象的距离越近,其相似度就越大。而簇是由距离靠近的对象组成的,因此算法目的是得到紧凑并且独立的簇。
2022-07-18 09:19:13 3028
3028 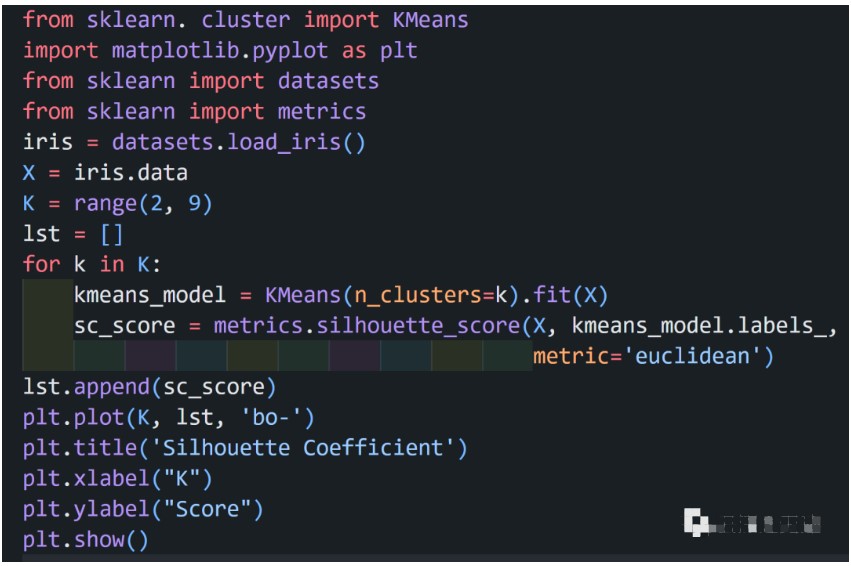
K-Means的主要优点是什么?K-Means的主要缺点是什么?
2021-06-10 06:14:37
包含SVPWM的算法介绍,基本原理,以及详细的公式推导,详细的图表示意,是初学FOC,准备自己手写FOC库或者理解FOC算法的工程师的有利手册,手册中也简单介绍了SVPWM与SPWM的内在联系与区别。读者可自行推导公式后与手册结果进行对照。
2023-10-07 09:13:05
山东大学机器学习(实验六内容)—— K-Means
2019-08-28 09:25:58
关于ADPCM压缩算法流程介绍
2021-06-03 06:44:13
使用Weka进行K-近邻算法和K-均值算法的使用
2019-05-24 12:02:15
聚类。这些集群围绕着质心分组,使它们成为球形,并具有相似的大小。 对于初学者来说,这是我们推荐的一种算法,因为它很简单,而且足够灵活,可以为大多数问题获得合理的结果。 优点:K-Means算法是最流行
2019-09-22 08:30:00
几个元素的节点,不考虑最好,不然容易导致过拟。3、能对非离散数据和不完整数据进行处理。该算法适用于临床决策、生产制造、文档分析、生物信息学、空间数据建模等领域。二、K平均算法K平均算法(k-means algorithm)是一个聚类算法,把n个分类对象根据它们的属性分为k类(k
2018-11-06 17:02:30
过长,甚至可能达不到学习的目的。8、K-Means聚类关于K-Means聚类的文章,链接:机器学习算法-K-means聚类。关于K-Means的推导,里面有着很强大的EM思想。优点算法简单,容易实现
2016-09-27 10:48:01
DIY图像压缩——机器学习实战之K-means 聚类图像压缩:色彩量化
2019-08-19 07:07:18
无监督学习算法中,我们没有目标或结果变量来预测。 通常用于不同群体的群体聚类。无监督学习的例子:Apriori 算法,K-means。0.3 强化学习 工作原理: 强化学习(reinforcement
2018-10-23 14:31:12
[源码和文档分享]JAVA实现基于k-means聚类算法实现微博舆情热点分析系统
2020-06-04 08:21:55
【python】调用sklearn使用k-means模型
2020-06-12 13:33:22
针对聚类算法在金融领域广泛应用的实际情况,基于银行客户数据集,对DBSCAN, K-means和X-means 3种聚类算法在执行效率、可扩展性、异常点检测能力等方面进行对比分析,并提出将X-mea
2009-04-06 08:50:12 22
22 分析了常见的社团发现算法的特点,以及谱二分法在实际应用中必须不断迭代才能完成多社团发现的不足,并提出了基于Laplace图谱和K-Means聚类算法的多社团发现方法,该方法是一个
2009-04-20 09:49:2822 异常检测是入侵检测中防范新型攻击的基本手段,本文应用增强的K-means 算法对检测数据进行聚类分类。计算机仿真结果说明了该方法对入侵检测是有
2009-09-03 10:21:3714 针对k-means算法存在的不足,提出了一种改进算法。 针对目前供电企业CRM系统的特点提出了用聚类分析方法进行客户群细分模型设计,通过实验验证了本文提出的k-means改进算法的高效性
2010-03-01 15:28:5115 Web文档聚类中k-means算法的改进
介绍了Web文档聚类中普遍使用的、基于分割的k-means算法,分析了k-means算法所使用的向量空间模型和基于距离的相似性度量的局限性,从而
2009-09-19 09:17:031233 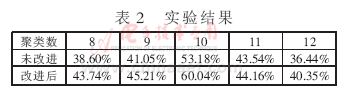
介绍了K-means 聚类算法的目标函数、算法流程,并列举了一个实例,指出了数据子集的数目K、初始聚类中心选取、相似性度量和距离矩阵为K-means聚类算法的3个基本参数。总结了K-means聚
2012-05-07 14:09:1427 2015-08-24 21:12:233 基于最小生成树的层次K_means聚类算法_贾瑞玉
2017-01-03 15:24:455 基于改进K_means算法的海量数据分析技术研究_李欢
2017-01-07 18:39:170 基于聚类中心优化的k_means最佳聚类数确定方法_贾瑞玉
2017-01-07 18:56:130 混合细菌觅食和粒子群的k_means聚类算法_闫婷
2017-01-07 19:00:390 基于K_means和图割的脑部MRI分割算法_田换
2017-01-08 11:13:291 K_means算法的改进及应用_王刚勇
2017-03-19 11:27:340 基于Canopy的K_means多核算法_邱荣太
2017-03-19 11:33:110 基于k_means的改进粒子群算法求解TSP问题_易云飞
2017-03-18 09:43:453 基于SVD的K_means聚类协同过滤算法_王伟
2017-03-17 08:00:000 基于改进K_means聚类的欠定盲分离算法_柴文标
2017-03-17 10:31:390 采用密度k_means和改进双边滤波的点云自适应去噪算法_郭进
2017-03-19 18:58:371 传统kmeans算法由于初始聚类中心的选择是随机的,因此会使聚类结果不稳定。针对这个问题,提出一种基于离散量改进k-means初始聚类中心选择的算法。算法首先将所有对象作为一个大类,然后不断从对象
2017-11-20 10:03:232 挖掘其聚类关系,选取初始聚类中心,避免了传统k-means算法对随机选取初始聚类中心的敏感性,减少了k-means算法的迭代次数。又结合MapReduce框架将算法整体并行化,并通过Partition、Combine等机制加强了并行化程度和执行效率。实验表明,该算法不仅提高了聚
2017-11-24 14:24:322 针对传统的K-means算法无法预先明确聚类数目,对初始聚类中心选取敏感且易受离群孤点影响导致聚类结果稳定性和准确性欠佳的问题,提出一种改进的基于密度的K-means算法。该算法首先基于轨迹数据分布
2017-11-25 11:35:380 K-means算法是最简单的一种聚类算法。算法的目的是使各个样本与所在类均值的误差平方和达到最小(这也是评价K-means算法最后聚类效果的评价标准)
2017-12-01 14:07:3321912 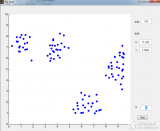
Spark Streaming运行的原理设计一种动态采样的K-Means并行算法,与DRDAS结合能实时有效地检测大数据环境下的各种分布式拒绝服务( DDoS)攻击。实验结果显示:DRDAS具有好的可扩展性、容错性和实时处理能力,与动态采样的K-Means并行算法结合能
2017-12-03 10:37:280 人工鱼群是一种随机搜索优化算法,具有较快的收敛速度,对问题的机理模型与描述无严格要求,具有广泛的应用范围。本文在该算法的基础上,结合传统的K-means聚类方法,提出了一种新的人工鱼群混合聚类算法
2017-12-04 16:18:150 传统的k-means算法采用的是随机数初始化聚类中心的方法,这种方法的主要优点是能够快速的产生初始化的聚类中心,其主要缺点是初始化的聚类中心可能会同时出现在同一个类别中,导致迭代次数过多,甚至陷入
2017-12-05 18:32:540 稳定、收敛速度快等优点,提出了一种简单有效的人脸识别方法,主要包含三个部分:卷积滤波器学习、非线性处理和空间平均值池化。具体而言,首先在训练图像中提取局部图像块,预处理后,使用K-means算法快速学习滤波器,每个滤波器与
2017-12-06 15:54:370 方法进行改进,将传统谱聚类算法(NJW-SC)中的基于欧氏距离的相似性测度换为基于流行距离的相似性测度,在此基础上对样本对象集进行聚类。之后将新提出来的算法同K-Means算法、传统谱聚类算法、模糊C均值聚类算法在人工数据集
2017-12-07 14:53:033 任务调度是云计算中的一个关键问题,遗传算法是一种能较好解决优化问题的算法。本论文针对遗传算法在任务调度过程中随着任务调度问题复杂度增加,算法的性能出现下降的现象,引入K-means聚类算法,提出一种
2017-12-07 15:16:100 k-means算法自提出50多年来,在聚类分析中得到了广泛应用,但是,k-means算法存在一个突出的问题,即需要预先设定聚类数目。所以,本文针对如何自动获取k-means的聚类数目进行了研究
2017-12-13 10:49:440 针对原始K-means聚类算法受初始聚类中心影响过大以及容易陷入局部最优的不足,提出一种基于改进布谷鸟搜索(cs)的K-means聚类算法(ACS-K-means)。其中,自适应CS( ACS)算法
2017-12-13 17:24:063 在基于视角加权的多视角聚类中,每个视角的权重取值对聚类结果的精度都有着重要的影V向。针对此问题,提出熵加权多视角核K-means( EWKKM)算法,通过给每个视角分配一个合理的权值来降低噪声视角或
2017-12-17 09:57:111 的基础上,设计并实现了增加机器性能评估影响因子的meDRF分配算法。将计算节点的机器性能得分,作为DRF主导份额计算的因子,使得计算任务有均等的机会获得优质计算资源和劣质计算资源。通过选取K-means、Bayes及PageRank等多种作业进行实验,实验结果表
2017-12-18 10:54:480 针对大数据环境下K-means聚类算法聚类精度不足和收敛速度慢的问题,提出一种基于优化抽样聚类的K-means算法(OSCK)。首先,该算法从海量数据中概率抽样多个样本;其次,基于最佳聚类中心的欧氏
2017-12-22 15:47:184 的主题词。在新浪微博数据集上进行实验发现,与k-means算法和基于加权语义和贝叶斯的中文短文本增量聚类算法(ICST-WSNB)相比,基于话题标签和转发关系的微博聚类算法的准确率比k-means算法提高了18.5%,比ICST-WSNB提高了6.48%,召回率以及F-值也有
2017-12-23 10:55:580 数据挖掘常用的十大算法包括: C4.5 ,K-means算法 3.SVM 4.Apriori ,EM:最大期望值法,pagerank:是google算法的重要内容,Adaboost: 迭代算法 ,KNN 最简单的机器学习方法之一,Naive Bayes Cart:分类与回归。下面我将一一介绍
2017-12-29 11:26:3027572 针对传统的TF-IDF算法、K-means算法、自适应遗传算法在网络检索结果中含有大量不相关数据、语义检索准确性不高的问题,研究了TF-IDF算法的改进及其在语义检索中的应用。将正则表达式和语义分析
2018-01-02 11:25:320 的半监督复合核支持向量机图像分类方法。结合Mean-Shift对像素点进行聚类分析以避免K-means图像聚类的局限性;利用图像的结构特征自适应算法参数以避免算法的波动性;由Mean-Shift结果构造Mean Map聚类核以增强同一聚类中的样本属于同一类别的可能性,使复合
2018-01-03 10:41:551 通过对基于K-means聚类的缺失值填充算法的改进,文中提出了基于距离最大化和缺失数据聚类的填充算法。首先,针对原填充算法需要提前输入聚类个数这一缺点,设计了改进的K-means聚类算法:使用数据间
2018-01-09 10:56:560 针对海量遥感影像快速分类的应用需求,提出一种基于K-means算法的遥感影像并行分类方法。该方法结合CPU下进程级与线程级模式的并行特征,设计融合进程级与线程级并行的两阶段数据粒度划分方法和任务调度
2018-01-10 16:24:540 网络中的脆弱节点进行补强。仿真实验结果显示这种结合K-means和脆弱性分析的拓扑生成算法在生成对意外风险具有较强抗性的电力网络拓扑方面具有比较好的效果。
2018-02-02 17:05:550 针对云计算平台的硬盘不可靠问题,提出基于带过采样的COG( COC-OS)框架,利用硬盘自我监测分析和报告技术( SMART)日志预测故障硬盘。首先采用DBScan或K-means聚类算法将无故障
2018-02-04 11:38:130 归为一类,而将不具有该特征的项排除在外。主流的聚类方法包括基于划分的聚类方法,如K-means;层次聚类方法,如CURE和BIRCH等;基于统计模型的方法,如EM算法等;基于密度的方法,如DBSCAN,OPTICS等。在基于密度的方法中,DBSCAN是
2018-02-08 14:58:330 对于K-Means算法,首先要注意的是k值的选择,一般来说,我们会根据对数据的先验经验选择一个合适的k值,如果没有什么先验知识,则可以通过交叉验证选择一个合适的k值。
2018-02-12 16:06:508916 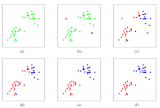
K-means算法的优点是:首先,算法能根据较少的已知聚类样本的类别对树进行剪枝确定部分样本的分类;其次,为克服少量样本聚类的不准确性,该算法本身具有优化迭代功能,在已经求得的聚类上再次进行迭代修正
2018-02-12 16:27:5933195 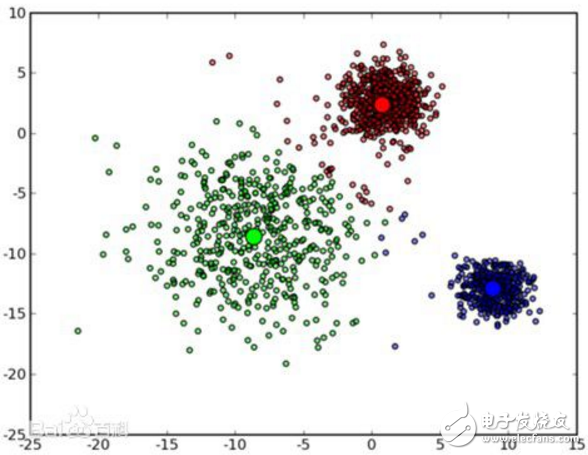
与分类不同,分类是示例式学习,要求分类前明确各个类别,并断言每个元素映射到一个类别,而聚类是观察式学习,在聚类前可以不知道类别甚至不给定类别数量,是无监督学习的一种。目前聚类广泛应用于统计学、生物学、数据库技术和市场营销等领域,相应的算法也非常的多。
2018-02-12 16:42:3516368 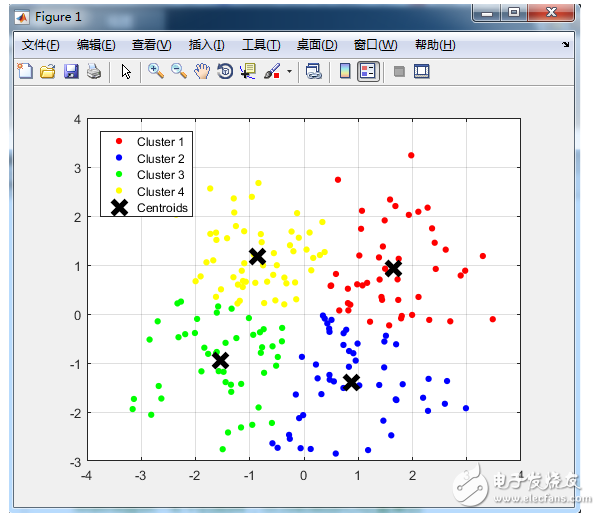
针对谱聚类存在计算瓶颈的问题,提出了一种快速的集成算法,称为间接谱聚类。它首先运用K-Means算法对数据集进行过分聚类,然后把每个过分簇看成一个基本对象,最后在过分簇的级别上利用标准谱聚类来完成
2018-02-24 14:43:590 针对移动自组网( MANET,mobile ad hoc networks)入侵检测过程中的攻击类型多样性和监测数据海量性问题,提出了一种基于改进k-means算法的MANET异常检测方法。通过引入
2018-03-06 15:18:500 测试用例集约简是软件测试中的重要研究问题之一,目的是以尽量少的测试用例达到测试目标。为此,提出一种新的测试用例集约简方法。应用二分K-means聚类算法对回归测试的测试用例集进行约简,以白盒测试
2018-03-12 15:06:230 及SMS4密文的随机性度量值取值个数进行了统计分析,采用k-means算法对其进行了初始聚类划分。其次,针对相同聚类中的分组密码算法识别问题,基于降低特征向量问相似度的原则,求解了码元频数检测、块内频数检测及游程检测对应的密文随机性度量值特征向量维数
2018-03-19 15:05:510 这个函数是对矩阵mat填充随机数,随机数的产生方式有参数2来决定,如果为参数2的类型为RNG::UNIFORM,则表示产生均一分布的随机数,如果为RNG::NORMAL则表示产生高斯分布的随机数。对应的参数3和参数4为上面两种随机数产生模型的参数。
2018-04-08 09:49:296547 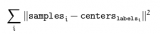
。将故事线看成日期、时间、机构、人物、地点、主题和关键词的联合概率分布,并考虑新闻时效性。在多个新闻数据集上进行的实验和评估结果表明,与K-means、LSA等算法相比,该算法模型具有较高的故事线挖掘能力。
2018-04-24 14:51:3218 Content: 9.1 Supervised Learning and Unsupervised Learning 9.2 K-means algorithm 9.3 Optimization
2018-05-01 17:43:0013046 
无监督学习是机器学习技术中的一类,用于发现数据中的模式。本文介绍用Python进行无监督学习的几种聚类算法,包括K-Means聚类、分层聚类、t-SNE聚类、DBSCAN聚类等。
2018-05-27 09:59:1331502 
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
2018-07-24 17:44:2120219 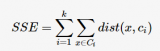
基于迭代框架的主动半监督聚类框架(IASSCF)是一个流行的半监督聚类框架。该框架存在两个问题:其一,初始先验信息较少导致迭代初期聚类效果不佳,进而影响后续聚类结果;其二,每次迭代只选择信息量最大的一个样本标记,导致运行速度慢性能提升慢。
2018-11-16 11:16:000 字段删除和部分时段数据过滤三方面的预处理,其次进行地图匹配,最后利用Spark大数据处理平台,实现K-Means||算法,分为工作日和休息日的不同时段进行挖掘分析,得到成都市居民出行热点区域及其时空分布特征,并将单机K-Means算法和K-Means
2018-11-23 16:12:1916 针对传统K-means型算法的“均匀效应”问题,提出一种基于概率模型的聚类算法。首先,提出一个描述非均匀数据簇的高斯混合分布模型,该模型允许数据集中同时包含密度和大小存在差异的簇;其次,推导了非均匀
2018-12-13 10:57:5910 K-means算法是被广泛使用的一种聚类算法,传统的-means算法中初始聚类中心的选择具有随机性,易使算法陷入局部最优,聚类结果不稳定。针对此问题,引入多维网格空间的思想,首先将样本集映射到一个
2018-12-13 17:56:551 本文档的主要内容详细介绍的是机器学习教程之机器学习10大经典算法的详细资料讲解主要内容包括了:1、C4.5,2、The k-means algorithm3、SVM 4、Apriori算法5、最大
2018-12-14 15:03:5026 在手机、平板电脑等电子媒介的人均持有率大于一的今天,网络自媒体的传播达到了前所未有的巅峰。本文通过基于Hadoop平台的mahout数据挖掘框架,选用经过Canopy算法优化后的K-means
2018-12-19 17:08:4913 聚类分析是将研究对象分为相对同质的群组的统计分析技术,聚类分析的核心就是发现有用的对象簇。K-means聚类算法由于具有出色的速度和良好的可扩展性,一直备受广大学者的关注。然而,传统的K-means
2018-12-20 10:28:2910 和排序、查找、图论、安全、聚类等相关的 26 个基础算法,内容涉及冒泡排序、二分查找、广度优先搜索、哈希函数、迪菲 - 赫尔曼密钥交换、k-means 算法等。本书没有枯燥的理论和复杂的公式,而是通过大量的步骤图帮助读者加深对数据结构原理和算法执行过程
2019-09-11 08:00:00102 和排序、查找、图论、安全、聚类等相关的 26 个基础算法,内容涉及冒泡排序、二分查找、广度优先搜索、哈希函数、迪菲 - 赫尔曼密钥交换、k-means 算法等。本书没有枯燥的理论和复杂的公式,而是通过大量的步骤图帮助读者加深对数据结构原理和算法执行过程
2020-05-08 08:00:0013 粗糙K- Means及其衍生算法在处理边界区域不确定信息时,其边界区域中的数据对象因与各类簇中心点的距离相差较小,导致难以依据距离、密度对数据点进行区分判断。提岀一种新的粗糙K- Means算法
2021-03-22 16:40:0013 K- means算法初始中心点选择的随机性以及对噪声点的敏感性,使得聚类结果易陷亼局部最优解,为获得最佳初始聚类中心,提岀一种基于距离和密度的并行二分K- means算法。计算数据集的平均样本距离
2021-03-22 16:44:2217 和朴素贝叶斯等四个门类。 1. 聚类算法:k-means 聚类算法的目标:观察输入数据集,并借助数据集中不同样本的特征差异来努力辨别不同的数据组。聚类算法最强大之处在于,它不需要本文中其他算法所需的训练过程,您只需简单地提供数据,告诉算法你想创造多少簇(样本的组别)
2021-03-24 16:14:317349 现有聚类算法面向高维稀疏数据时多数未考虑类簇可重叠和离群点的存在,导致聚类效果不理想。为此,提出一种可重叠子空间K- Means聚类算法。设计类簇子空间计算策略,在聚类过程中动态更新每个类簇的属性
2021-03-25 14:07:1013 聚类分析是数据挖掘与分析最重要的方法之一。它把相似的数据对象归类到一个簇,把不同的数据对象尽可能分到不同的簇。其中k- means聚类算法,由于其简单性和高效性,被广泛运用于解决各种现实问题,例如
2021-04-28 16:43:551 为降低并均衡无线传感器网络(WSN)中传感器节点的能量消耗,提出一种基于最优传输距离和 K-means聚类的WSN分簇算法。根据层次聚类算法建立聚类特征树,将聚类特征树中的叶节点视为一个簇,并使每个
2021-05-26 14:50:172 传统的协同过滤算法存在数据稀疏、可扩展性弱和用户兴趣度偏移等冋题,算法运行效率和预测精度偏低。针对上述问题,提出一种改进的 Mini batch K- Means时间权重推荐算法。采用
2021-06-03 16:28:0512 K-means 是一种聚类算法,且对于数据科学家而言,是简单且热门的无监督式机器学习(ML)算法之一。
2022-06-06 11:53:555202 在聚类技术领域中,K-means可能是最常见和经常使用的技术之一。K-means使用迭代细化方法,基于用户定义的集群数量(由变量K表示)和数据集来产生其最终聚类。例如,如果将K设置为3,则数据集将分组为3个群集,如果将K设置为4,则将数据分组为4个群集,依此类推。
2022-10-28 14:25:212219 我们不用手工选择 anchor boxes,而是在训练集的边界框上的维度上运行 K-means 聚类算法,自动找到良好的 anchor boxes 。 如果我们使用具有欧几里得距离的标准 K-means,那么较大的框会比较小的框产生更多的误差。
2023-01-11 15:40:362567 ”物以类聚,人以群分“!这句话的核心思想就是聚类!聚类是典型的无监督学习方法。不同于分类,分类是有监督学习,样本都有标签,分类模型重点考查的是模型的泛化能力,而聚类是按要求给样本加标签,重点考查模型聚类的效果,通常无训练集与测试集的划分。 什么是聚类?所谓数据聚类是指根据数据的内在性质将数据分成一些聚合类,每一聚合类中的元素尽可能具有相同的特性,不同聚合类之间的特性差别尽可能大。 聚类分析的目的是分析
2023-02-10 08:45:051181 继续讲解! 程序来啦! 最后看一下程序示例!看看如何用K-means算法实现数据聚类的过程。程序很简单,侧重让大家了解和掌握 K-means算法 聚类的过程! 看代码吧!程序由三部
2023-02-11 07:20:04859 继续讲解!程序如何优化呢?需要增强其实用性!这是程序走向实用化的过程!毕竟写出的程序不是让人看的,而是实实在在能产生作用的。那么在实际环境中使用,自然会考虑很多因素。首先要在程序中加入阈值的概念!它可以防止死循环!!!做产品的人一定要懂得提前假设! 阈值的作用在于控制循环是否继续! 之前的程序是怎么控制的呢? 大家可以比较一下,那种方法更实用?还有其他方法吗?有的!直接规定循环次数!当然要保证在次数内已
2023-02-12 15:20:04933 of Arrival)。不管是什么方式,其技术实现大致是一样的:都是通过测量接收信号中的某些特征值,比如信号强度、角度、时间等,再采用相关算法来实现对目标的定位。下面分别介绍这三类算法:
2023-05-06 17:56:234792 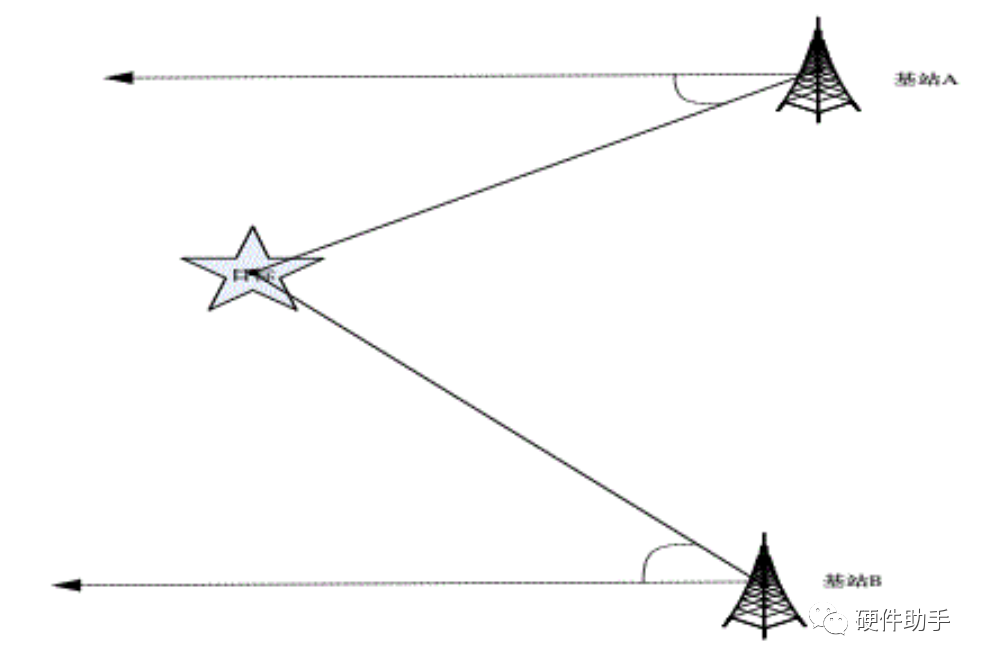
DBSCAN: Density Based Spatial Clustering of Applications with Noise; DBSCAN是基于密度的聚类方法,对样本分布的适应能力比K-Means更好。
2023-05-09 14:35:562513 
无监督学习算法主要用于聚类和关联规则挖掘。聚类问题是指将数据集合划分成相似的组,而关联规则挖掘问题是指发现数据集合中经常一起出现的数据项。常见的无监督学习算法包括K-means、谱聚类、Apriori等。
2023-08-14 13:51:266584 图像分割:利用图像的灰度、颜色、纹理、形状等特征,把图像分成若干个互不重叠的区域,并使这些特征在同一区域内呈现相似性,在不同的区域之间存在明显的差异性。然后就可以将分割的图像中具有独特性质的区域提取出来用于不同的研究。
2023-09-07 16:59:043400 
 电子发烧友App
电子发烧友App













 工商网监
工商网监
评论