 电子发烧友App
电子发烧友App


为了不被踢出AI的队伍,视觉深度模型都开始接私活了?
只要是成熟且完成度较高的技术,慢慢就不会被大家当做智能来看待了。
比如我问身边的老母亲老父亲老阿姨们,手机指纹解锁、手写输入、地图导航、游戏NPC、美颜相机等等是不是人工智能,他们纷纷流露出了质疑的小眼神儿:
这么常见朴素不做作,怎么能是AI呢,最起码也得挑战一下那些看起来不可能完成的任务吧,比如能撒娇的智能客服,360度旋转跳跃闭着眼的机器人,扫一眼就能看病的大白,动不动就血虐人类的智能体什么的。
行……吧……如此看来,最“危险”的要数计算机视觉了。
估计再过不久,人脸识别、看图识物、假脸生成,就要被“开除”出AI的队伍了。
近年来,深度神经网络彻底升级了计算机视觉模型的表现。在很多领域,比如视觉对象的分类、目标检测、图像识别等任务上,深度神经网络(Deep Neural Network,DNN)完成的比人类还要出色,相关技术解决方案也开始频繁出现在普通人的生活细节之中。
这就够了嘛?并没有!视觉模型表示自己除了在图像任务里很好用,非图像任务也是一把好手。
前不久,深度学习开发者,Medium知名博主 Max Pechyonkin在其博客中,介绍了将视觉深度学习模型应用于非视觉领域的一些创造性应用。
咱们就通过一篇文章,来了解一下求生欲极强的视觉模型是如何在其他领域发光发热的吧。
生活不易,DNN卖艺
由于有迁移学习和优秀的学习资源,DNN在计算机视觉领域的应用落地远超于其他任务类型。
加上各种开放平台和公开的预训练模型加持,任何人都可以在数天甚至数小时内,将视觉深度学习模型应用于其他领域。
两年前,就有外国农民开发出了自动检测黄瓜的智能程序,北京平谷的桃农也用上了自动检桃机。
背后的技术逻辑也很容易理解:先选用一个简单的卷积神经网络(CNN)模型(可以在开放平台上轻松地找到),将各种带有标签的图片扔进去,跑出一个baseline,主要是为了确定数据集是否合适,图像质量和标签是否正确,需不需要调试等等。
OK以后,就可以投喂处理过的图像数据集了,一般图像越多、标注质量越高,模型的性能和准确率就越好。
听起来是不是学过高中数学就能搞定?
既然技术门槛并不高,其应用范围自然也就被无限延伸。面对很多非视觉类的原始训练数据,视觉模型也表示“不怂”。
其中有几个比较有意思的应用案例:
1.帮石油工业提高生产效率
石油工业往往依赖于一种名叫“磕头机”的设备开采石油和天然气,通过游梁活动让抽油杆像泵一样将油从地下输送到表面。高强度的活动也使抽油机极容易发生故障。
传统的故障检测方式是,邀请非常专业的技术人员检查抽油机上的测功计,上面记录了发动机旋转周期各部分的负载。通过卡片上的图像,判断出哪个部位出现故障以及需要采取什么措施来修复它。
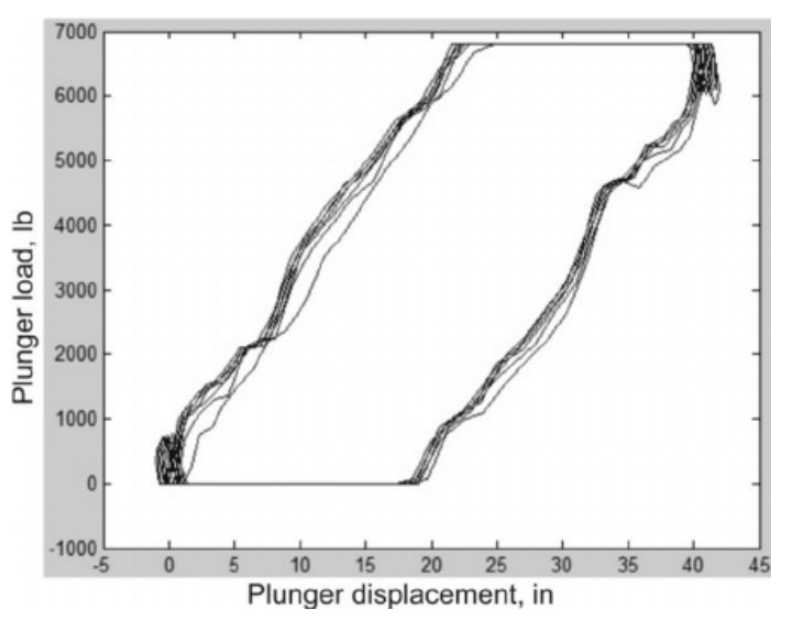
这个过程不仅耗时,而且只能“亡羊补牢”,无法预先排除风险。
而石油公司正在试验,将视觉深度学习应用到故障检测中。
贝克休斯(Baker Hughes)公司就将测功计转换成图像,然后作为数据集传给ImageNet预训练好的模型中。结果显示,只需采用预训练好的模型并用新数据对其进行微调,机器自动检测故障的准确率就达到了93%,进一步优化则接近97%!

(左侧是输入图像,右侧是故障模式的实时分类。系统在便携设备上运行,分类时间显示在右下角)
应用了视觉算法训练出来的新模型,不需要等待专业人员的排期和诊断,就可以自行判断绝大多数故障并立即开始修复。听起来是不是很棒很奈斯?
2.帮金融网站进行在线风控
金融网站与欺诈团伙的斗智斗勇,往往是一场“道高一尺魔高一丈”的技术军备竞赛。想要区分访问者是普通客户还是潜在风险客户,仅仅依靠IP过滤、验证码等互联网技术显然不够了。
但如果金融网站的系统能够根据鼠标使用模式来识别用户行为,就能够预先规避欺诈交易的发生。要知道,欺诈者使用电脑鼠标的方式是独一无二而且非常异常的。
但如何得到一个深度学习鉴别模型呢?Splunk就将每个用户在每个网页上的鼠标活动转换为单个图像。用不同的颜色编码代表鼠标移动的速度,红点和绿点则代表使用了鼠标键。这样,就得到了大小相同、且能够应用图像模型的原始数据了。

Splunk用了一个由2000张图片组成的训练集,进行了2分钟的训练后,系统就能识别出普通客户和非客户,准确率达到80%以上。
对于某个特定用户,系统还能够判断出哪些是用户自己发出的,哪些是模仿的。这次只用了360张图片就训练出了78%左右的准确率。麻麻再也不用担心我的理财账户被盗了。
3.通过声音检测进行动物研究
2018年10月,谷歌的研究人员使用视觉CNN模型对一段录音进行了分析,检测到了其中座头鲸的声音。
然后使用了Resnet-50架构来训练这个模型。有90%的鲸鱼歌声音频被系统正确归类。而如果一首录音是鲸鱼的,也有90%的几率它会被贴上正确的标签。
这项研究成果可以用来跟踪单个鲸鱼的运动、歌曲的特性、鲸鱼的数量等。
同样的实验也适用于人类语音、工业设备录音等等。使用类似librosa这样的音频分析软件,就可以用CPU生成时频谱。
至此,可以总结一下视觉深度学习模型“跨次元”应用的基本操作了:
1.将原始数据转换成图像;
2.使用预训练的CNN模型或从头训练一个新模型进行训练。
由此得到一个能够解决非视觉问题的新模型。
开脑洞才是最难的
当然,上述都是作者分享的一些已经在实践中取得成效的应用,我们还可以将其应用于很多有趣、有意义的场景之中。前提是,能够找到一种将非视觉数据转换成图像的方法。
比如儿童餐食的健康问题,仅靠学校食堂和家长自学营养学显然不是一个足够效率、且能大规模推广的办法。
利用视觉模型,可以对餐盘的自动扫描与检测,对图像中的餐食特征和瑕疵点进行提取,以此推测出餐盘和饮食的洁净度是否合格,营养搭配是否符合基本要求。
再比如,通过智能摄像头将零售商超中的人群分布和动线转化为图像,进行分析和检测,可以判断出不同社区的需求和消费特征,从而有针对性地进行选品和陈设,进一步提升坪效。或者是通过汽车行驶轨迹来预测和优化不同时段的路况及定价。
总而言之,目前计算机视觉模型早已从实验室和科学家案头,帮助越来越多的现实问题寻找解决方案。
由此也可以看出,在AI落地中并不缺成熟、可落地的算法,大开脑洞的创造力才是最难的。
当然也有隐患
作为一个负责任的“AI吹”,故事显然不能在“AI好AI妙AI呱呱叫”中戛然而止。
虽然计算机视觉表现出了极大的适应性,但在实际应用时,有一些缺点是其本身也没有解决的, 这也导致很长一段时间内,图像识别、生成等应用还能被当做展示人工智能的神奇能力而被夸耀着。
首先,是视觉神经网络对于图像变化和背景过于敏感。无论是转换非视数据,还是直接训练原始图片,机器视觉的处理逻辑都是将图像转换为系统可理解的“数字”,再进行对比和识别。因此,将背景和变化等噪音识别成其他物体也就不足为奇了。
(在照片中增加不同的物体,会影响照片中原有的猴子的识别结果)
既然是通过视觉模型进行训练,那就需要大量有标注的高质量数据,而在现实应用中,一些非图像的原始数据,比如用户鼠标习惯、零售店动向等等,包含了多个维度、不同数量的数据点,不仅标记数据集的工作耗时耗力,而且训练这些庞大的数据也需要大量的GPU资源。
但遗憾的是,受标注质量、模型准确率、专业领域知识等影响,最终的成果在真实世界中的体验也可能非常糟糕。想要让商业机构冒着投资打水漂的风险进行尝试,恐怕还有很多工作要做。
更何况,视觉深度模型并不是一种放之四海而皆准的解决方案,有些任务是难以进行视觉化标注,或者实现成本很高的,短时期内也只能望AI兴叹了。
总而言之,视觉深度学习模型的成熟和非视觉场景的试探,给AI开发带来了新的故事和想象力,比起千箱一面的智能语音、人手一个的人脸识别,更令人惊喜,实用性也值得期待。
不过本质上讲,一切技术问题最后都是经济学问题。只要不计成本,总能搞得出来。《三体》中,秦始皇不也用三千万大军搞出了能计算太阳运行轨道的人形计算机队列吗?
这也和如今的人工智能产业现状悄然重合,技术不是关键性问题,没钱又不会搞工程的项目,就别让AI背锅了吧……





















 工商网监
工商网监
评论