 电子发烧友App
电子发烧友App


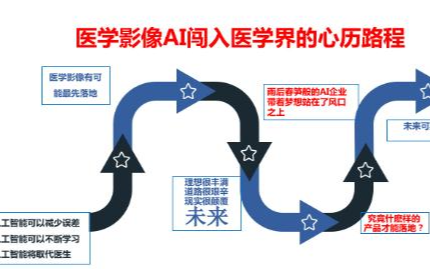
在深度学习进入瓶颈之际,医学影像AI科研人员分为两大派:理论派和工程派。
理论派希望解决深度学习“短缺”的部分,通过预先构建先验知识,在不过度依赖大数据的前提下,开发出一个可解释的、高精度、可解决诸多长尾问题的“智能模型”。
工程派的做法则是进一步发挥深度学习自身的优势,利用更多标注数据,去训练出一个能够学习更多维度特征的“经验模型”。
“深度学习正走向两极化,大部分研究深度学习的人员会偏向于工程化,包括建立更加全面、便捷、快速、可视化的深度学习平台,‘暴力’地将深度学习应用到更加多的领域。小部分的深度学习研究者会偏向于理论化,解决深度学习的理论瓶颈包括可解释性等问题。”
密歇根州立大学汤继良教授曾如此总结到。
医疗AI热潮,无疑离不开这波深度学习的发展,但由于深度学习的天然局限性和医疗领域的特殊性,使得医疗AI这一交叉的领域,也在进入瓶颈期。
随着深度学习即将触及天花板,医学影像分析科研人员也随之分为两大派别:理论派和工程派。
理论派的初衷,是解决深度学习“短缺”的部分,强调人工设计和数学论证,通过预先构建先验知识,在不过度依赖大数据的前提下,开发出一个可解释的、高精度、可解决诸多长尾问题的“智能模型”。不少专家认为,医疗AI中有大量Mission Critical和长尾问题,这对研究人员的整体系统设计能力要求非常高,因此人的作用就显得尤为重要,而基于黑箱统计模型的深度学习,显然存在太多的弊病。
工程派的做法,则是进一步发挥深度学习自身的优势,扬长避短,获取更多标注数据,设置更多参数,用更强大的算力,训练出一个能够学习更多维度特征的“经验模型”。其本质是建立某种学习和搜索的Meta Method,依靠摩尔定律带来的指数增长的算力,让机器自行构建复杂的知识系统。
前者强调人工设计,后者依靠机器自主构建。
后深度学习时代的医疗AI研究走向,正朝着这两个看似极端的方向发展,工者愈工,理者愈理。
前者的难度在于理论的突破,从某种程度上取决于个别人的开创性研究成果;而后者在很大程度上取决于整个行业的数据标准化、开放化和监管进度。
二者虽殊途,但目的是同归。
深度学习+医学影像的瓶颈
电子科技大学教授李纯明曾在接受雷锋网AI掘金志采访时谈到,深度学习吸引人的地方在于,原则上它在不同的应用中均可以使用同样的训练算法框架。
只需替换训练数据和相应的标注进行训练,即可得出一个具有某种输入输出关系的多层神经网络。
输入一个数据,系统就输出一个结果,应用过程可以做到全自动。
但这种看起来一劳永逸的框架,在实际应用中还有一些局限。
以医学影像分析为例,由于医学影像数据复杂多变,不同器械商的成像设备、不同的成像参数选择、成像设备的更新换代等因素,都会导致图像性质(如信噪比、分辨率和伪影等等)的变化,以及不同病人与病情的差异也会导致图像特征的变化。
训练数据如果不够“大而全”,一旦遇到跟训练数据有一定差异的数据,加入一点噪音,神经网络输出的结果可能就会出很大的错误。
但训练数据要多“大”多“全”?也并未有一个客观的量化标准。
深度学习需要用医生手工标注的数据,还要求训练数据和手工标注符合一定的标准。
但数据的标准化,还尚未提出通用的法则遵循。而在算法层,深度学习的调参也并没有规律可循,调参难题至今未得到实质性解决。
这些都可能会给深度学习的应用带来诸多不确定性,致使其在不同数据集上的性能可能会截然不同,鲁棒性较差。
在医疗领域的应用上,深度学习的不可解释性也是个无法回避的问题。
医生和病人都很难接受这种不可解释的诊断结果和治疗方案,而当前工科会议的论文,基于不可解释的深度学习研究成果几乎是主流。
“数据驱动的深度学习只是数据处理的工具之一,它在医疗领域离真正的落地还有相当大的距离,还需在理论和技术上有所突破。学术界研究深度学习不应太工程化,应该多研究一些基础性的理论问题,提出更有原创性的算法。”李纯明谈到。
“我认为,从眼前来讲,不应该一窝蜂都用数据驱动的深度学习。一些医学图像算法的开发也应该针对不同的应用,去设计不同的算法,开发者尽可能在算法中融入领域知识,设计出针对特定应用的个性化的方法,而不是对每个病种都在TensorFlow或Pytorch等开源框架上用不同的数据进行训练和调参。由于深度学习这种数据驱动的学习过程,是一种较少利用领域知识的机制,因此技术的开发也就几乎不需要开发者与医生的交流。医生在技术开发的过程中只起到了对训练数据手工标注的作用,也就是说医生被当作人工智能背后的‘标注工人’来用。”
“从长期来讲,数据为王的医学影像AI研究方法,在未来遇到的问题将会越来越多。当前多数学者更多停留在简单的工程问题,缺乏在基础研究上的突破性进展,企业界的技术开发也因此遭遇瓶颈。”
与此同时,现在的深度学习其实是一个有问题的框架,用大量标注数据做训练的方法,在过去几年很成功,但在解决医疗这类拥有诸多“非封闭”和”长尾”问题的领域,当前的深度学习主流研究,并不代表是正确的方向。
现阶段,计算机视觉系统是一个Training System,而不是一个Learning System,我们需要从Training System变成Learning System,让机器主动,并结合数据的结构、时间空间结构去学习,而不是被动地用人工训练来标注它。
目前行业走的是粗放型发展路线,是靠堆积数据和计算资源来换取高性能,这是资源而不是效率的竞赛。在大家把医学影像分析聚焦于Data Set的大环境下,虽然在工业界已有一定的成果,但理论派认为,原创性技术和基础研究,更值得工科人去关注和投入。
AI理论创新之外的解决方法
正是由于深度学习遭遇的种种问题,也促使优秀科学家加大了对基础理论的研究。
而另一方面,在部分临床问题中,也可通过在非技术层的行业标准构建等方法,来逐步推动医学影像AI辅助诊断的发展。
第一步,则需定义好要解决的问题。
上海长征医院影像医学与核医学科主任刘士远在2018中国医学人工智能大会的演讲中指出,现在的AI医疗产品遇到的首个问题便是实用性差,如现在常见的影像AI产品大多是基于单病种图像标注形成的模型,尚未符合临床实用场景的产品,而且大多数产品性能的自报数据与实际检测数据不符,鲁棒性有待提高。
AI产品往往只是集中在少数几个病种,难以覆盖全部医学影像问题。
其次,行业现在普遍缺乏标准化高质量的训练数据,国内外虽然有很多公开的数据库,但是存在同质化和人种差异等问题。
而且众多人工智能企业和机构采用的训练数据集标准多样,系统偏差较大,行业缺乏医学图像和疾病征像的统一认识。
整个行业的医疗数据保护和监管措施也有一定的缺失,数据不能被溯源,缺乏合法性和可分享性。
同时业内也缺乏对数据使用标准的判断依据,在现有的法律基础上寻找合规使用和分享数据的渠道,也是迫在眉睫的一件事情。
刘士远建议到,构建标准库,离不开医生的参与。
要形成与AI研发相关的标准和数据,需要在图像采集环节、标准库构建环节、病种的分布以及各种描述术语等层面,都要达成一定的共识。
2018年9月,国家颁布了《国家健康医疗大数据标准、安全和服务管理办法(试行)》。此外,在肺结节领域,中检院肺结节AI检验数据库标定专家组已经完成肺结节标准数据集建设。
这些均为标准的建设,做好了铺垫。
当然,图像标注环节也存在很多问题,以肺结节标注过程为例,其主要存在以下问题:标注者队伍混乱,资质不一;图像征象认识不统一;图像标注方法不统一;图像分割方法不统一;图像量化方法不统一。
据了解,中检院在构建肺结节标准库的过程中,从全国招了250名5年以上经验的影像科医生志愿者,对他们进行了简单的测试,使用了30例结节,结果准确率只有30%,说明如果没有共识和基础培训,医生的标注准确率很低,非影像科医生甚至不是医生的准确率更难以想象。
而标注的方式,有紧密包裹法、区域标注法等,不同的标注方法输出的结果也不尽相同。
“图像分割如果没有统一的标准,结论的差别也会非常巨大。
还有量化的方法,到底是测直径,还是测体积,还是测质量,怎么测,行业都需要形成一致意见。
在医学影像AI模型检测阶段,也会存在生产过程不规范,模型效果和安全性缺乏公正评价,缺乏产品检测标准库和评价体系,缺乏相关法律法规、质控检查和管理制度等问题。
在AI模型使用阶段,受欢迎程度,对医生的影响,过多的假阳性,伦理和法规,是否匹配医院和医生的需求等问题也尚待解决。”
另外,也需考虑其他问题:
产品应游离于信息系统之外,还是融合于信息系统之内?
年轻医生对AI产品产生依赖之后,是否会导致业务能力下降?
数据的伦理和产品的伦理问题:数据的伦理就是数据的所有权、许可权和隐私权都需要制定规范,现在卫计委已经发布了相关标准和规范。第二个则是产品的伦理问题,随着产品的逐渐落地,产品的责任和影响都需要伦理的相关准则来考虑。
刘士远教授还强调,影像诊断是全链条、多维度的工作,工作内容不仅仅是图像识别,需要充分发挥医生在医学影像AI研发过程中的作用。
在数据上,医生可以建立大样本的单病种数据库,提高训练数据质量,并在此基础上规范化标注,形成高质量训练集,还要学会在法律法规下分享和使用数据。
医生还应当成为质量控制和标准的制定者和执行者。如制定图像采集和图像质量的标准,制定数据库建设的构成比例、病种分布、病灶类型等专家共识,并形成各单病种影像征象和描写属于以及单病种AI模型数据标记专家共识。建立一套正确的基本伦理准则来指导AI的设计、管理和应用。
医学影像AI的未来
无论是AI理论创新,或是非理论层的行业标准建立,其均是医学影像AI成功的必备条件。
2019年7月13日,由中国计算机学会、雷锋网、香港中文大学(深圳)联合举办的CCF-GAIR全球人工智能与机器人峰会,将开设“AI医疗”论坛。










 工商网监
工商网监
评论