 电子发烧友App
电子发烧友App











 创作
创作 发文章
发文章 发帖
发帖  提问
提问  发资料
发资料 发视频
发视频资料介绍
在进行数据挖掘或者机器学习模型建立的时候,因为在统计学习中,假设数据满足独立同分布(i.i.d,independently and identically distributed),即当前已产生的数据可以对未来的数据进行推测与模拟,因此都是使用历史数据建立模型,即使用已经产生的数据去训练,然后使用该模型去拟合未来的数据。 在我们机器学习和深度学习的训练过程中,经常会出现过拟合和欠拟合的现象。训练一开始,模型通常会欠拟合,所以会对模型进行优化,然而等到训练到一定程度的时候,就需要解决过拟合的问题了。
一、模型训练拟合的分类和表现
如何判断过拟合呢?我们在训练过程中会定义训练误差,验证集误差,测试集误差(泛化误差)。训练误差总是减少的,而泛化误差一开始会减少,但到一定程序后不减反而增加,这时候便出现了过拟合的现象。
如下图所示,从直观上理解,欠拟合就是还没有学习到数据的特征,还有待继续学习,而过拟合则是学习进行的太彻底,以至于把数据的一些局部特征或者噪声带来的特征都给学到了,所以在进行测试的时候泛化误差也不佳。
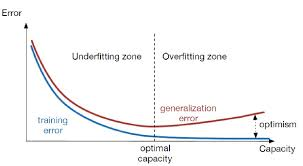
从方差和偏差的角度来说,欠拟合就是在训练集上高方差、高偏差,过拟合也就是训练集上高方差、低偏差。为了更加生动形象的表示,我们看一些经典的图:
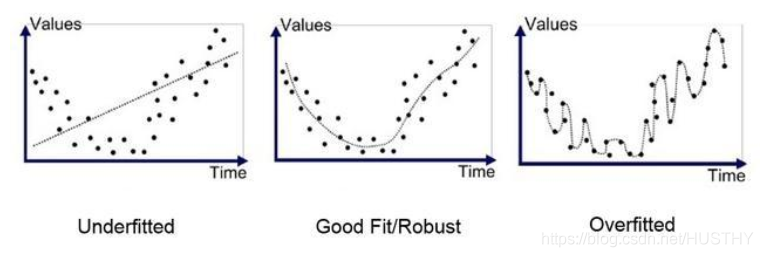
对比这几个图,发现图一的拟合并没有把大体的规律给拟合出来,这个就是欠拟合。图三则是拟合的太细致了,用的拟合函数太复杂了,在这些数据集上的效果很好,但是换到另外的一个数据集效果肯定可预见的不好。只有图二是最好的,把数据的规律拟合出来了,同时在更换数据集后,效果也不会很差。
仔细想想图片三中的模型,拟合函数肯定是一个高次函数,其参数个数肯定肯定比图二的要多,可以说图三的拟合函数比图二的要大,模型更加复杂。这也是过拟合的一个判断经验,模型是否太复杂。另外,针对图三,我们把一些高次变量对应的参数值变小,也就相当于把模型变简单了。这个角度上看,可以减小参数值,也就是一般模型过拟合,参数值整体比较大。从模型复杂性来讲,可以是:1、模型的参数个数;2、模型的参数值的大小。个数越多,参数值越大,模型就越复杂。
二、欠拟合
1、欠拟合的表现
针对模型过拟合这个问题,有没有什么方法来判定模型是否过拟合呢?其实一般都是依靠模型在训练集和验证集上的表现有一个大体的判断就行了。如果要有一个具体的方法,可以参考机器学中,学习曲线来判断模型是否过拟合。如下图:
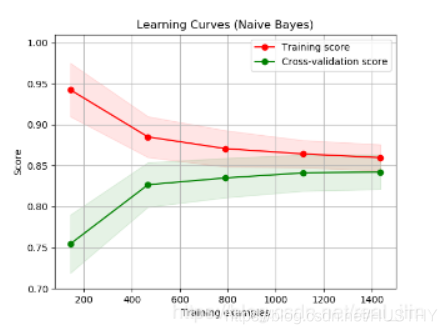
也就是看训练集合验证集随着样本数量的增加,他们之间的差值变化。如果训练集和测试集的准确率都很低,那么说明模型欠拟合。
2、欠拟合的解决方案
欠拟合是由于学习不足,可以考虑添加特征,从数据中挖掘出更多的特征,有时候还需要对特征进行变换,使用组合特征和高次特征。
模型简单也会导致欠拟合,例如线性模型只能拟合一次函数的数据。尝试使用更高级的模型有助于解决欠拟合,如使用SVM,神经网络等。
正则化参数是用来防止过拟合的,出现欠拟合的情况就要考虑减少正则化参数。
三、过拟合
1、过拟合的定义
模型在训练集上的表现很好,但在测试集和新数据上的表现很差。
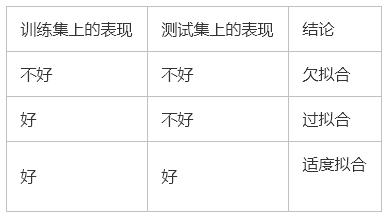
2、过拟合的原因
1)数据量太小
这个是很容易产生过拟合的一个原因。设想,我们有一组数据很好的吻合3次函数的规律,现在我们局部的拿出了很小一部分数据,用机器学习或者深度学习拟合出来的模型很大的可能性就是一个线性函数,在把这个线性函数用在测试集上,效果可想而知肯定很差了。
2)训练集和验证集分布不一致
训练集训练出一个适合训练集那样分布的数据集,当你把模型运用到一个不一样分布的数据集上,效果肯定大打折扣。这个是显而易见的。
3)模型复杂度太大
在选择模型算法的时候,首先就选定了一个复杂度很高的模型,然后数据的规律是很简单的,复杂的模型反而就不适用了。
4)数据质量很差
数据还有很多噪声,模型在学习的时候,肯定也会把噪声规律学习到,从而减小了具有一般性的规律。这个时候模型用来预测肯定效果也不好。
5)过度训练
这个是同第4个是相联系的,只要训练时间足够长,那么模型肯定就会吧一些噪声隐含的规律学习到,这个时候降低模型的性能是显而易见的。
3、解决方案
1)降低模型复杂度
处理过拟合的第一步就是降低模型复杂度。为了降低复杂度,我们可以简单地移除层或者减少神经元的数量使得网络规模变小。与此同时,计算神经网络中不同层的输入和输出维度也十分重要。虽然移除层的数量或神经网络的规模并无通用的规定,但如果你的神经网络发生了过拟合,就尝试缩小它的规模。
2)数据集扩增
在数据挖掘领域流行着这样的一句话,“有时候往往拥有更多的数据胜过一个好的模型”。因为我们在使用训练数据训练模型,通过这个模型对将来的数据进行拟合,而在这之间又一个假设便是,训练数据与将来的数据是独立同分布的。即使用当前的训练数据来对将来的数据进行估计与模拟,而更多的数据往往估计与模拟地更准确。因此,更多的数据有时候更优秀。但是往往条件有限,如人力物力财力的不足,而不能收集到更多的数据,如在进行分类的任务中,需要对数据进行打标,并且很多情况下都是人工得进行打标,因此一旦需要打标的数据量过多,就会导致效率低下以及可能出错的情况。所以,往往在这时候,需要采取一些计算的方式与策略在已有的数据集上进行手脚,以得到更多的数据。
通俗得讲,数据机扩增即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。
一般有以下方法:
- 从数据源头采集更多数据
- 复制原有数据并加上随机噪声
- 重采样
- 根据当前数据集估计数据分布参数,使用该分布产生更多数据等
3)数据增强
使用数据增强可以生成多幅相似图像。这可以帮助我们增加数据集规模从而减少过拟合。因为随着数据量的增加,模型无法过拟合所有样本,因此不得不进行泛化。计算机视觉领域通常的做法有:翻转、平移、旋转、缩放、改变亮度、添加噪声等等
4)正则化
正则化方法是指在进行目标函数或代价函数优化时,在目标函数或代价函数后面加上一个正则项,一般有L1正则与L2正则等。
L1惩罚项的目的是使权重绝对值最小化。公式如下:
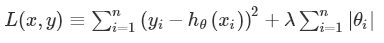
L2惩罚项的目的是使权重的平方最小化。公式如下:
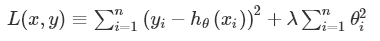
以下表格对两种正则化方法进行了对比:
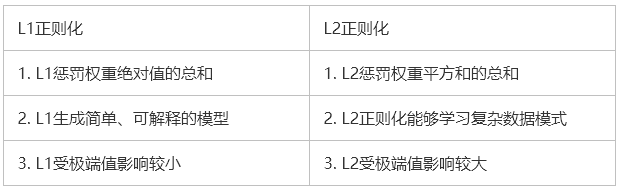
如果数据过于复杂以至于无法准确地建模,那么L2是更好的选择,因为它能够学习数据中呈现的内在模式。而当数据足够简单,可以精确建模的话,L1更合适。对于我遇到的大多数计算机视觉问题,L2正则化几乎总是可以给出更好的结果。然而L1不容易受到离群值的影响。所以正确的正则化选项取决于我们想要解决的问题。
总结
正则项是为了降低模型的复杂度,从而避免模型区过分拟合训练数据,包括噪声与异常点(outliers)。从另一个角度上来讲,正则化即是假设模型参数服从先验概率,即为模型参数添加先验,只是不同的正则化方式的先验分布是不一样的。这样就规定了参数的分布,使得模型的复杂度降低(试想一下,限定条件多了,是不是模型的复杂度降低了呢),这样模型对于噪声与异常点的抗干扰性的能力增强,从而提高模型的泛化能力。还有个解释便是,从贝叶斯学派来看:加了先验,在数据少的时候,先验知识可以防止过拟合;从频率学派来看:正则项限定了参数的取值,从而提高了模型的稳定性,而稳定性强的模型不会过拟合,即控制模型空间。
另外一个角度,过拟合从直观上理解便是,在对训练数据进行拟合时,需要照顾到每个点,从而使得拟合函数波动性非常大,即方差大。在某些小区间里,函数值的变化性很剧烈,意味着函数在某些小区间里的导数值的绝对值非常大,由于自变量的值在给定的训练数据集中的一定的,因此只有系数足够大,才能保证导数的绝对值足够大。
如下图(引用知乎):
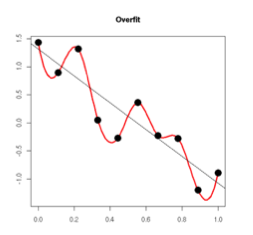
另外一个解释,规则化项的引入,在训练(最小化cost)的过程中,当某一维的特征所对应的权重过大时,而此时模型的预测和真实数据之间距离很小,通过规则化项就可以使整体的cost取较大的值,从而,在训练的过程中避免了去选择那些某一维(或几维)特征的权重过大的情况,即过分依赖某一维(或几维)的特征(引用知乎)。
L2与L1的区别在于,L1正则是拉普拉斯先验,而L2正则则是高斯先验。它们都是服从均值为0,协方差为1λ。当λ=0时,即没有先验)没有正则项,则相当于先验分布具有无穷大的协方差,那么这个先验约束则会非常弱,模型为了拟合所有的训练集数据,参数可以变得任意大从而使得模型不稳定,即方差大而偏差小。λ越大,标明先验分布协方差越小,偏差越大,模型越稳定。即,加入正则项是在偏差bias与方差variance之间做平衡tradeoff(来自知乎)。
下图即为L2与L1正则的区别:
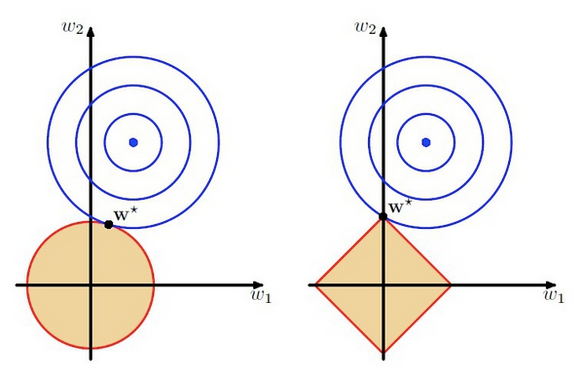
上图中的模型是线性回归,有两个特征,要优化的参数分别是w1和w2,左图的正则化是L2,右图是L1。蓝色线就是优化过程中遇到的等高线,一圈代表一个目标函数值,圆心就是样本观测值(假设一个样本),半径就是误差值,受限条件就是红色边界(就是正则化那部分),二者相交处,才是最优参数。可见右边的最优参数只可能在坐标轴上,所以就会出现0权重参数,使得模型稀疏。
其实拉普拉斯分布与高斯分布是数学家从实验中误差服从什么分布研究中得来的。一般直观上的认识是服从应该服从均值为0的对称分布,并且误差大的频率低,误差小的频率高,因此拉普拉斯使用拉普拉斯分布对误差的分布进行拟合,如下图:
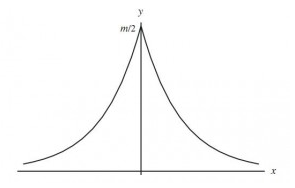
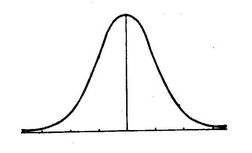
而拉普拉斯在最高点,即自变量为0处不可导,因为不便于计算,于是高斯在这基础上使用高斯分布对其进行拟合,如下图:
5)dropout
正则是通过在代价函数后面加上正则项来防止模型过拟合的。而在神经网络中,有一种方法是通过修改神经网络本身结构来实现的,其名为Dropout。该方法是在对网络进行训练时用一种技巧(trick),对于如下所示的三层人工神经网络:
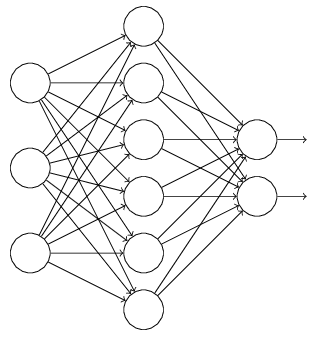
对于上图所示的网络,在训练开始时,随机得删除一些(可以设定为一半,也可以为1/3,1/4等)隐藏层神经元,即认为这些神经元不存在,同时保持输入层与输出层神经元的个数不变,这样便得到如下的ANN:
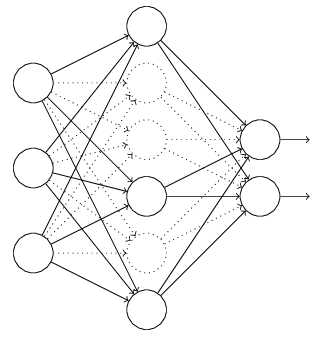
然后按照BP学习算法对ANN中的参数进行学习更新(虚线连接的单元不更新,因为认为这些神经元被临时删除了)。这样一次迭代更新便完成了。下一次迭代中,同样随机删除一些神经元,与上次不一样,做随机选择。这样一直进行瑕疵,直至训练结束。
这种技术被证明可以减少很多问题的过拟合,这些问题包括图像分类、图像切割、词嵌入、语义匹配等问题。
6)早停
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
Early stopping方法的具体做法是,在每一个Epoch结束时(一个Epoch集为对所有的训练数据的一轮遍历)计算validation data的accuracy,当accuracy不再提高时,就停止训练。这种做法很符合直观感受,因为accurary都不再提高了,在继续训练也是无益的,只会提高训练的时间。如下图所示,在几次迭代后,即使训练误差仍然在减少,但测验误差已经开始增加了。
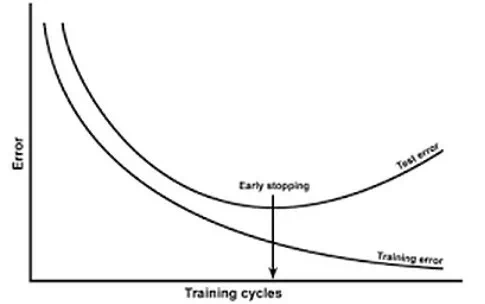
那么该做法的一个重点便是怎样才认为validation accurary不再提高了呢?并不是说validation accuracy一降下来便认为不再提高了,因为可能经过这个Epoch后,accuracy降低了,但是随后的Epoch又让accuracy又上去了,所以不能根据一两次的连续降低就判断不再提高。一般的做法是,在训练的过程中,记录到目前为止最好的validation accuracy,当连续10次Epoch(或者更多次)没达到最佳accuracy时,则可以认为accuracy不再提高了。此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-n”,n即Epoch的次数,可以根据实际情况取,如10、20、30……
7)重新清洗数据
把明显异常的数据剔除
8)使用集成学习方法
把多个模型集成在一起,降低单个模型的过拟合风险
参考
https://www.cnblogs.com/tsruixi/p/10693101.html
https://www.jianshu.com/p/f8b86af75020
https://blog.csdn.net/husthy/article/details/103883714
https://www.cnblogs.com/LXP-Never/p/13755354.html
本文转自:博客园 - 早起的小虫子,转载此文目的在于传递更多信息,版权归原作者所有。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。 举报投诉
- 基于多元拟合的卧室温湿度闭环调控系统 10次下载
- 基于局部熵拟合与全局信息的改进活动轮廓模型 5次下载
- 基于LSPIA的NURBS曲线拟合优化算法 10次下载
- 基于DFP优化的大规模数据点拟合方法 7次下载
- OpenCV进行椭圆拟合的程序免费下载 4次下载
- 高斯曲线拟合原理及实现的详细资料说明 2次下载
- 并网风电机组寿命分布拟合与维修方案评价 0次下载
- 算法大全_插值与拟合 0次下载
- Matlab数据拟合基础函数的使用 0次下载
- 基于LabVIEW晶体生长检测系统的圆弧拟合技术 22次下载
- 低轨卫星轨道拟合及预报方法研究 28次下载
- GPS高程拟合方法研究
- 基于GPS的路线测量与拟合
- 基于过拟合神经网络的混沌伪随机序列
- 基于G 的ANFIS在函数拟合中的应用
- 机器学习中的交叉验证方法 1338次阅读
- 深度学习模型中的过拟合与正则化 1076次阅读
- 深度学习模型训练过程详解 1418次阅读
- 深度学习的模型优化与调试方法 923次阅读
- 基于双级优化(BLO)的消除过拟合的微调方法 723次阅读
- 使用最小二乘法解决曲线拟合问题 1273次阅读
- 电化学交流阻抗拟合原理与方法 1596次阅读
- OpenCV中的直线拟合 3259次阅读
- 神经网络中避免过拟合5种方法介绍 2.4w次阅读
- 详解机器学习和深度学习常见的正则化 2354次阅读
- 欠拟合和过拟合是什么?解决方法总结 3.1w次阅读
- 过拟合的概念和用几种用于解决过拟合问题的正则化方法 1.5w次阅读
- 解析训练集的过度拟合与欠拟合 8231次阅读
- 正交多项式拟合-matlab 7948次阅读
- 理解神经网络中的Dropout 3815次阅读

 上传资料赚积分
上传资料赚积分下载排行
本周
- 1电子电路原理第七版PDF电子教材免费下载
- 0.00 MB | 1491次下载 | 免费
- 2单片机典型实例介绍
- 18.19 MB | 95次下载 | 1 积分
- 3S7-200PLC编程实例详细资料
- 1.17 MB | 27次下载 | 1 积分
- 4笔记本电脑主板的元件识别和讲解说明
- 4.28 MB | 18次下载 | 4 积分
- 5开关电源原理及各功能电路详解
- 0.38 MB | 11次下载 | 免费
- 6100W短波放大电路图
- 0.05 MB | 4次下载 | 3 积分
- 7基于单片机和 SG3525的程控开关电源设计
- 0.23 MB | 4次下载 | 免费
- 8基于AT89C2051/4051单片机编程器的实验
- 0.11 MB | 4次下载 | 免费
本月
- 1OrCAD10.5下载OrCAD10.5中文版软件
- 0.00 MB | 234313次下载 | 免费
- 2PADS 9.0 2009最新版 -下载
- 0.00 MB | 66304次下载 | 免费
- 3protel99下载protel99软件下载(中文版)
- 0.00 MB | 51209次下载 | 免费
- 4LabView 8.0 专业版下载 (3CD完整版)
- 0.00 MB | 51043次下载 | 免费
- 5555集成电路应用800例(新编版)
- 0.00 MB | 33562次下载 | 免费
- 6接口电路图大全
- 未知 | 30320次下载 | 免费
- 7Multisim 10下载Multisim 10 中文版
- 0.00 MB | 28588次下载 | 免费
- 8开关电源设计实例指南
- 未知 | 21539次下载 | 免费
总榜
- 1matlab软件下载入口
- 未知 | 935053次下载 | 免费
- 2protel99se软件下载(可英文版转中文版)
- 78.1 MB | 537793次下载 | 免费
- 3MATLAB 7.1 下载 (含软件介绍)
- 未知 | 420026次下载 | 免费
- 4OrCAD10.5下载OrCAD10.5中文版软件
- 0.00 MB | 234313次下载 | 免费
- 5Altium DXP2002下载入口
- 未知 | 233046次下载 | 免费
- 6电路仿真软件multisim 10.0免费下载
- 340992 | 191183次下载 | 免费
- 7十天学会AVR单片机与C语言视频教程 下载
- 158M | 183277次下载 | 免费
- 8proe5.0野火版下载(中文版免费下载)
- 未知 | 138039次下载 | 免费





 工商网监
工商网监
评论