完善资料让更多小伙伴认识你,还能领取20积分哦,立即完善>
标签 > SVM
SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
Vapnik等人在多年研究统计学习理论基础上对线性分类器提出了另一种设计最佳准则。其原理也从线性可分说起,然后扩展到线性不可分的情况。甚至扩展到使用非线性函数中去,这种分类器被称为支持向量机(Support Vector Machine,简称SVM)。支持向量机的提出有很深的理论背景。支持向量机方法是在后来提出的一种新方法。SVM的主要思想可以概括为两点:
它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。
SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。
Vapnik等人在多年研究统计学习理论基础上对线性分类器提出了另一种设计最佳准则。其原理也从线性可分说起,然后扩展到线性不可分的情况。甚至扩展到使用非线性函数中去,这种分类器被称为支持向量机(Support Vector Machine,简称SVM)。支持向量机的提出有很深的理论背景。支持向量机方法是在后来提出的一种新方法。SVM的主要思想可以概括为两点:
它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。
例子
如右图:将1维的“线性不可分”上升到2维后就成为线性可分了。⑵它基于结构风险最小化理论之上在特征空间中建构最优分割超平面,使得学习器得到全局最优化,并且在整个样本空间的期望风险以某个概率满足一定上界。在学习这种方法时,首先要弄清楚这种方法考虑问题的特点,这就要从线性可分的最简单情况讨论起,在没有弄懂其原理之前,不要急于学习线性不可分等较复杂的情况,支持向量机在设计时,需要用到条件极值问题的求解,因此需用拉格朗日乘子理论,但对多数人来说,以前学到的或常用的是约束条件为等式表示的方式,但在此要用到以不等式作为必须满足的条件,此时只要了解拉格朗日理论的有关结论就行。
一般特征
⑴SVM学习问题可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值。而其他分类方法(如基于规则的分类器和人工神经网络)都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解。⑵SVM通过最大化决策边界的边缘来控制模型的能力。尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等。⑶通过对数据中每个分类属性引入一个哑变量,SVM可以应用于分类数据。⑷SVM一般只能用在二类问题,对于多类问题效果不好。
原理介绍
SVM方法是通过一个非线性映射p,把样本空间映射到一个高维乃至无穷维的特征空间中(Hilbert空间),使得在原来的样本空间中非线性可分的问题转化为在特征空间中的线性可分的问题.简单地说,就是升维和线性化.升维,就是把样本向高维空间做映射,一般情况下这会增加计算的复杂性,甚至会引起“维数灾难”,因而人们很少问津.但是作为分类、回归等问题来说,很可能在低维样本空间无法线性处理的样本集,在高维特征空间中却可以通过一个线性超平面实现线性划分(或回归).一般的升维都会带来计算的复杂化,SVM方法巧妙地解决了这个难题:应用核函数的展开定理,就不需要知道非线性映射的显式表达式;由于是在高维特征空间中建立线性学习机,所以与线性模型相比,不但几乎不增加计算的复杂性,而且在某种程度上避免了“维数灾难”.这一切要归功于核函数的展开和计算理论.选择不同的核函数,可以生成不同的SVM,常用的核函数有以下4种:⑴线性核函数K(x,y)=x·y;⑵多项式核函数K(x,y)=[(x·y)+1]^d;⑶径向基函数K(x,y)=exp(-|x-y|^2/d^2)⑷二层神经网络核函数K(x,y)=tanh(a(x·y)+b).
应用
SVM可用于解决各种现实世界的问题:
支持向量机有助于文本和超文本分类,因为它们的应用程序可以显著减少对标准感应和转换设置中标记的训练实例的需求。
图像的分类也可以使用SVM进行。实验结果表明,只有三到四轮的相关性反馈,支持向量机的搜索精度要比传统的查询优化方案高得多。图像分割系统也是如此,包括使用Vapnik建议的使用特权方法的修改版SVM的系统。
使用SVM可以识别手写字符。
SVM算法已广泛应用于生物科学和其他科学领域。它们已被用于对高达90%正确分类的化合物进行蛋白质分类。已经提出基于SVM权重的置换测试作为解释SVM模型的机制。支持向量机权重也被用于解释过去的SVM模型。Posthoc解释支持向量机模型为了识别模型使用的特征进行预测是一个比较新的研究领域,在生物科学中具有特殊的意义。
手把手教你实现SVM算法
机器学习是研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。
机器学习的大致分类:
1)分类(模式识别):要求系统依据已知的分类知识对输入的未知模式(该模式的描述)作分析,以确定输入模式的类属,例如手写识别(识别是不是这个数)。
2)问题求解:要求对于给定的目标状态,寻找一个将当前状态转换为目标状态的动作序列。
SVM一般是用来分类的(一般先分为两类,再向多类推广一生二,二生三,三生万物哈)
问题的描述
向量表示:假设一个样本有n个变量(特征):Ⅹ= (X1,X2,…,Xn)T
样本表示方法:
SVM线性分类器
SVM从线性可分情况下的最优分类面发展而来。最优分类面就是要求分类线不但能将两类正确分开(训练错误率为0),且使分类间隔最大。SVM考虑寻找一个满足分类要求的超平面,并且使训练集中的点距离分类面尽可能的远,也就是寻找一个分类面使它两侧的空白区域(margin)最大。
过两类样本中离分类面最近的点且平行于最优分类面的超平面上H1,H2的训练样本就叫做支持向量。
图例:
问题描述:
假定训练数据 :![]()
可以被分为一个超平面:![]()
进行归一化:![]()
此时分类间隔等于:![]()
即使得:最大间隔最大等价于使![]() 最小
最小
下面这两张图可以看一下,有个感性的认识。那个好?
看下面这张图:
下面我们要开始优化上面的式子,因为推导要用到拉格朗日定理和KKT条件,所以我们先了解一下相关知识。在求取有约束条件的优化问题时,拉格朗日乘子法(Lagrange Multiplier) 和KKT条件是非常重要的两个求取方法,对于等式约束的优化问题,可以应用拉格朗日乘子法去求取最优值;如果含有不等式约束,可以应用KKT条件去求取。当然,这两个方法求得的结果只是必要条件,只有当是凸函数的情况下,才能保证是充分必要条件。KKT条件是拉格朗日乘子法的泛化。之前学习的时候,只知道直接应用两个方法,但是却不知道为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够起作用,为什么要这样去求取最优值呢?
拉格朗日乘子法和KKT条件
定义:给定一个最优化问题:
最小化目标函数:![]()
制约条件:![]()
定义拉格朗日函数为:
求偏倒方程
可以求得![]() 的值。这个就是神器拉格朗日乘子法。
的值。这个就是神器拉格朗日乘子法。
上面的拉格朗日乘子法还不足以帮我们解决所有的问题,下面引入不等式约束
最小化目标函数:![]()
制约条件变为:
定义拉格朗日函数为:
可以列出方程:
新增加的条件被称为KKT条件
KKT条件详解
对于含有不等式约束的优化问题,如何求取最优值呢?常用的方法是KKT条件,同样地,把所有的不等式约束、等式约束和目标函数全部写为一个式子L(a, b, x)= f(x) + a*g(x)+b*h(x),KKT条件是说最优值必须满足以下条件:
1. L(a, b, x)对x求导为零;
2. h(x) =0;
3. a*g(x) = 0;
求取这三个等式之后就能得到候选最优值。其中第三个式子非常有趣,因为g(x)《=0,如果要满足这个等式,必须a=0或者g(x)=0. 这是SVM的很多重要性质的来源,如支持向量的概念。
二。 为什么拉格朗日乘子法(Lagrange Multiplier) 和KKT条件能够得到最优值?
为什么要这么求能得到最优值?先说拉格朗日乘子法,设想我们的目标函数z = f(x), x是向量, z取不同的值,相当于可以投影在x构成的平面(曲面)上,即成为等高线,如下图,目标函数是f(x, y),这里x是标量,虚线是等高线,现在假设我们的约束g(x)=0,x是向量,在x构成的平面或者曲面上是一条曲线,假设g(x)与等高线相交,交点就是同时满足等式约束条件和目标函数的可行域的值,但肯定不是最优值,因为相交意味着肯定还存在其它的等高线在该条等高线的内部或者外部,使得新的等高线与目标函数的交点的值更大或者更小,只有到等高线与目标函数的曲线相切的时候,可能取得最优值,如下图所示,即等高线和目标函数的曲线在该点的法向量必须有相同方向,所以最优值必须满足:f(x)的梯度 = a* g(x)的梯度,a是常数,表示左右两边同向。这个等式就是L(a,x)对参数求导的结果。(上述描述,我不知道描述清楚没,如果与我物理位置很近的话,直接找我,我当面讲好理解一些,注:下图来自wiki)。
而KKT条件是满足强对偶条件的优化问题的必要条件,可以这样理解:我们要求min f(x), L(a, b, x) = f(x) + a*g(x) + b*h(x),a》=0,我们可以把f(x)写为:max_{a,b} L(a,b,x),为什么呢?因为h(x)=0, g(x)《=0,现在是取L(a,b,x)的最大值,a*g(x)是《=0,所以L(a,b,x)只有在a*g(x) = 0的情况下才能取得最大值,否则,就不满足约束条件,因此max_{a,b} L(a,b,x)在满足约束条件的情况下就是f(x),因此我们的目标函数可以写为 min_x max_{a,b} L(a,b,x)。如果用对偶表达式: max_{a,b} min_x L(a,b,x),由于我们的优化是满足强对偶的(强对偶就是说对偶式子的最优值是等于原问题的最优值的),所以在取得最优值x0的条件下,它满足 f(x0) = max_{a,b} min_x L(a,b,x) = min_x max_{a,b} L(a,b,x) =f(x0),我们来看看中间两个式子发生了什么事情:
f(x0) = max_{a,b} min_x L(a,b,x) = max_{a,b} min_x f(x) + a*g(x) + b*h(x) = max_{a,b} f(x0)+a*g(x0)+b*h(x0) = f(x0)
可以看到上述加黑的地方本质上是说 min_x f(x) + a*g(x) + b*h(x) 在x0取得了最小值,用Fermat定理,即是说对于函数 f(x) + a*g(x) + b*h(x),求取导数要等于零,即
f(x)的梯度+a*g(x)的梯度+ b*h(x)的梯度 = 0
这就是KKT条件中第一个条件:L(a, b, x)对x求导为零。
而之前说明过,a*g(x) = 0,这时KKT条件的第3个条件,当然已知的条件h(x)=0必须被满足,所有上述说明,满足强对偶条件的优化问题的最优值都必须满足KKT条件,即上述说明的三个条件。可以把KKT条件视为是拉格朗日乘子法的泛化。
上面跑题了,下面我继续我们的SVM之旅。
经过拉格朗日乘子法和KKT条件推导之后
最终问题转化为:
最大化:![]()
条件:
这个是著名的QP问题。决策面:![]() 其中
其中 ![]() 为问题的优化解。
为问题的优化解。
松弛变量(slack vaviable)
由于在采集数据的过程中,也可能有误差(如图)
所以我们引入松弛变量对问题进行优化。
![]() 式子就变为
式子就变为![]()
最终转化为下面的优化问题:
其中的C是惩罚因子,是一个由用户去指定的系数,表示对分错的点加入多少的惩罚,当C很大的时候,分错的点就会更少,但是过拟合的情况可能会比较严重,当C很小的时候,分错的点可能会很多,不过可能由此得到的模型也会不太正确。
上面那个个式子看似复杂,现在我带大家一起推倒一下
……
…(草稿纸上,敲公式太烦人了)
最终得到:
最大化:
条件:
呵呵,是不是感觉和前面的式子没啥区别内,亲,数学就是这么美妙啊。
这个式子看起来beautiful,但是多数情况下只能解决线性可分的情况,只可以对线性可分的样本做处理。如果提供的样本线性不可分,结果很简单,线性分类器的求解程序会无限循环,永远也解不出来。但是不怕不怕。我们有杀手锏还没有出呢。接着咱要延伸到一个新的领域:核函数。嘻嘻,相信大家都应该听过这厮的大名,这个东东在60年代就提出来,可是直到90年代才开始火起来(第二春哈),主要是被Vapnik大大翻出来了。这也说明计算机也要多研读经典哈,不是说过时了就不看的,有些大师的论文还是有启发意义的。废话不多说,又跑题了。
核函数
那到底神马是核函数呢?
介个咱得先介绍一下VC维的概念。
为了研究经验风险最小化函数集的学习一致收敛速度和推广性,SLT定义了一些指标来衡量函数集的性能,其中最重要的就是VC维(Vapnik-Chervonenkis Dimension)。
VC维定义:对于一个指示函数(即只有0和1两种取值的函数)集,如果存在h个样本能够被函数集里的函数按照所有可能的2h种形式分开,则称函数集能够把h个样本打散,函数集的VC维就是能够打散的最大样本数目。
如果对任意的样本数,总有函数能打散它们,则函数集的VC维就是无穷大。
看图比较方便(三个点分类,线性都可分的)。
如果四个点呢?哈哈,右边的四个点要分为两个类,可能就分不啦。
如果四个点,一条线可能就分不过来啦。
一般而言,VC维越大, 学习能力就越强,但学习机器也越复杂。
目前还没有通用的关于计算任意函数集的VC维的理论,只有对一些特殊函数集的VC维可以准确知道。
N维实数空间中线性分类器和线性实函数的VC维是n+1。
Sin(ax)的VC维为无穷大。
对于给定的学习函数集,如何计算其VC维是当前统计学习理论研究中有待解决的一个难点问题,各位童鞋有兴趣可以去研究研究。
咱们接着要说说为啥要映射。
例子是下面这张图:
下面这段来自百度文库http://wenku.baidu.com/view/8c17ebda5022aaea998f0fa8.html
俺觉得写的肯定比我好,所以咱就选择站在巨人的肩膀上啦。
我们把横轴上端点a和b之间红色部分里的所有点定为正类,两边的黑色部分里的点定为负类。试问能找到一个线性函数把两类正确分开么?不能,因为二维空间里的线性函数就是指直线,显然找不到符合条件的直线。
但我们可以找到一条曲线,例如下面这一条:
显然通过点在这条曲线的上方还是下方就可以判断点所属的类别(你在横轴上随便找一点,算算这一点的函数值,会发现负类的点函数值一定比0大,而正类的一定比0小)。这条曲线就是我们熟知的二次曲线,它的函数表达式可以写为:
问题只是它不是一个线性函数,但是,下面要注意看了,新建一个向量y和a:
这样g(x)就可以转化为f(y)=《a,y》,你可以把y和a分别回带一下,看看等不等于原来的g(x)。用内积的形式写你可能看不太清楚,实际上f(y)的形式就是:
g(x)=f(y)=ay
在任意维度的空间中,这种形式的函数都是一个线性函数(只不过其中的a和y都是多维向量罢了),因为自变量y的次数不大于1。
看出妙在哪了么?原来在二维空间中一个线性不可分的问题,映射到四维空间后,变成了线性可分的!因此这也形成了我们最初想解决线性不可分问题的基本思路——向高维空间转化,使其变得线性可分。
而转化最关键的部分就在于找到x到y的映射方法。遗憾的是,如何找到这个映射,没有系统性的方法(也就是说,纯靠猜和凑)。具体到我们的文本分类问题,文本被表示为上千维的向量,即使维数已经如此之高,也常常是线性不可分的,还要向更高的空间转化。其中的难度可想而知。
为什么说f(y)=ay是四维空间里的函数?
大家可能一时没看明白。回想一下我们二维空间里的函数定义
g(x)=ax+b
变量x是一维的,为什么说它是二维空间里的函数呢?因为还有一个变量我们没写出来,它的完整形式其实是
y=g(x)=ax+b
即
y=ax+b
看看,有几个变量?两个。那是几维空间的函数?
再看看
f(y)=ay
里面的y是三维的变量,那f(y)是几维空间里的函数?
用一个具体文本分类的例子来看看这种向高维空间映射从而分类的方法如何运作,想象一下,我们文本分类问题的原始空间是1000维的(即每个要被分类的文档被表示为一个1000维的向量),在这个维度上问题是线性不可分的。现在我们有一个2000维空间里的线性函数
f(x’)=《w’,x’》+b
注意向量的右上角有个 ’哦。它能够将原问题变得可分。式中的 w’和x’都是2000维的向量,只不过w’是定值,而x’是变量(好吧,严格说来这个函数是2001维的,哈哈),现在我们的输入呢,是一个1000维的向量x,分类的过程是先把x变换为2000维的向量x’,然后求这个变换后的向量x’与向量w’的内积,再把这个内积的值和b相加,就得到了结果,看结果大于阈值还是小于阈值就得到了分类结果。
你发现了什么?我们其实只关心那个高维空间里内积的值,那个值算出来了,分类结果就算出来了。而从理论上说, x’是经由x变换来的,因此广义上可以把它叫做x的函数(有一个x,就确定了一个x’,对吧,确定不出第二个),而w’是常量,它是一个低维空间里的常量w经过变换得到的,所以给了一个w 和x的值,就有一个确定的f(x’)值与其对应。这让我们幻想,是否能有这样一种函数K(w,x),他接受低维空间的输入值,却能算出高维空间的内积值《w’,x’》?
如果有这样的函数,那么当给了一个低维空间的输入x以后,
g(x)=K(w,x)+b
f(x’)=《w’,x’》+b
这两个函数的计算结果就完全一样,我们也就用不着费力找那个映射关系,直接拿低维的输入往g(x)里面代就可以了(再次提醒,这回的g(x)就不是线性函数啦,因为你不能保证K(w,x)这个表达式里的x次数不高于1哦)。
万幸的是,这样的K(w,x)确实存在(发现凡是我们人类能解决的问题,大都是巧得不能再巧,特殊得不能再特殊的问题,总是恰好有些能投机取巧的地方才能解决,由此感到人类的渺小),它被称作核函数(核,kernel),而且还不止一个,事实上,只要是满足了Mercer条件的函数,都可以作为核函数。核函数的基本作用就是接受两个低维空间里的向量,能够计算出经过某个变换后在高维空间里的向量内积值。几个比较常用的核函数,俄,教课书里都列过,我就不敲了(懒!)。
回想我们上节说的求一个线性分类器,它的形式应该是:
现在这个就是高维空间里的线性函数(为了区别低维和高维空间里的函数和向量,我改了函数的名字,并且给w和x都加上了 ’),我们就可以用一个低维空间里的函数(再一次的,这个低维空间里的函数就不再是线性的啦)来代替,
又发现什么了?f(x’) 和g(x)里的α,y,b全都是一样一样的!这就是说,尽管给的问题是线性不可分的,但是我们就硬当它是线性问题来求解,只不过求解过程中,凡是要求内积的时候就用你选定的核函数来算。这样求出来的α再和你选定的核函数一组合,就得到分类器啦!
明白了以上这些,会自然的问接下来两个问题:
1. 既然有很多的核函数,针对具体问题该怎么选择?
2. 如果使用核函数向高维空间映射后,问题仍然是线性不可分的,那怎么办?
第一个问题现在就可以回答你:对核函数的选择,现在还缺乏指导原则!各种实验的观察结果(不光是文本分类)的确表明,某些问题用某些核函数效果很好,用另一些就很差,但是一般来讲,径向基核函数是不会出太大偏差的一种,首选。(我做文本分类系统的时候,使用径向基核函数,没有参数调优的情况下,绝大部分类别的准确和召回都在85%以上。
感性理解,映射图:
常用的两个Kernel函数:
多项式核函数:![]()
高斯核函数:![]()
定义:![]()
将核函数带入,问题又转化为线性问题啦,如下:
求![]() ,其中
,其中![]()
式子是有了,但是如何求结果呢?不急不急,我会带着大家一步一步的解决这个问题,并且通过动手编程使大家对这个有个问题有个直观的认识。(PS:大家都对LIBSVM太依赖了,这样无助于深入的研究与理解,而且我觉得自己动手实现的话会比较有成就感)

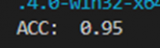
同时根据测试精度,可以看出,通过添加第一次训练多得到的支持向量,而非将全体数据进行二次训练,能够达到同样的效果。

之前为大家带来了两篇关于SVM的介绍与基于python的使用方法。相信大家都已经上手体验,尝鲜了鸢尾花数据集了吧。

面部识别是一个经常讨论的计算机科学话题,并且由于计算机处理能力的指数级增长而成为人们高度关注的话题。

说到机器学习,大相信大家自然而然想到的就是现在大热的卷积神经网络,或者换句话来说,深度学习网络。对于这些网络或者模型来说,能够大大降低进入门槛,具体而言...
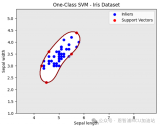
上一篇本着回归传统的观点,在这个深度学习繁荣发展的时期,带着大家认识了一位新朋友,英文名SVM,中文名为支持向量机,是一种基于传统方案的机器学习方案,同...
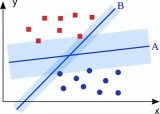
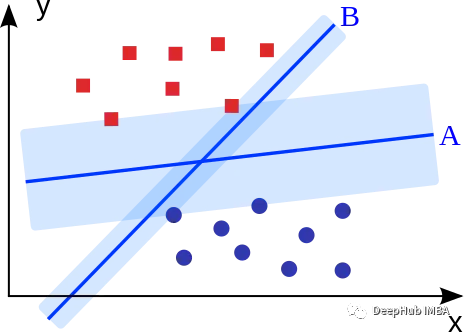
支持向量机的目标是拟合获得最大边缘的超平面(两个类中最近点的距离)。可以直观地表明,这样的超平面(A)比没有最大化边际的超平面(B)具有更好的泛化特性和...
可穿戴传感器可将人体各种生理信号转换为可直接观测的电信号,为了解人体健康提供丰富的信息,有望为人体实时活动、健康状况提供预测平台。
本文将首先简要概述支持向量机及其训练和推理方程,然后将其转换为代码以开发支持向量机模型。

这篇文章将介绍一种新的调制方法,空间矢量调制 (Space Vector Modulation),简称 SVM。
在机器学习中,机器学习的效率在很大程度上取决于它所提供的数据集,数据集的大小和丰富程度也决定了最终预测的结果质量。目前在算力方面,量子计算能超越传统二进...
类别:模型|Macromodel 2021-04-26 标签:算法SVM模型
4、结果分析 4.3 不同分类方法比较与分析 4.3.1基于SVM方法的分类结果比较 在不同SVM分类方法中,由于其所采用的分类模型和输入特征差异影响,...

细胞变形性(Cellular deformability)是医学上评价细胞生理状态的一种很有前景的生物标志物。
类皮肤柔性传感器在医疗保健和人机交互中发挥着至关重要的作用。然而,一般目标集中在追求类皮肤传感器本身固有的静态和动态性能,同时伴随着各种试错尝试。这种前...
河南作为小麦玉米的主要产粮区,对小麦玉米方面的研究颇为深入。针对小麦灌浆期易受天气等因素影响,造成小麦倒伏的情况,需快速准确评估作物倒伏灾情状况,需及时...
什么叫AI计算?AI计算力是什么? 随着科技的不断发展,人工智能(AI)已经成为当今最热门的技术之一。而在人工智能中,AI计算是非常重要的一环。那么,什...
机器学习算法总结 机器学习算法是什么?机器学习算法优缺点? 机器学习算法总结 机器学习算法是一种能够从数据中自动学习的算法。它能够从训练数据中学习特征,...

微塑料污染已成为全球关注的问题,据估计,海洋上层约有24.4万亿个微塑料碎片,这突显了这种污染物在海洋环境中的广泛存在。
简介 支持向量机基本上是最好的有监督学习算法了。最开始接触SVM是去年暑假的时候,老师要求交《统计学习理论》的报告,那时去网上下了一份入门教程,里面讲的...
【编者按】这是一篇关于机器学习工具包Scikit-learn的入门级读物。对于程序员来说,机器学习的重要性毋庸赘言。也许你还没有开始,也许曾经失败过,都...
很多开发者说自从有了 Python/Pandas,Excel 都不怎么用了,用它来处理与可视化表格非常快速。但是这样还是有一大缺陷,操作不是可视化的表格...
 换一批
换一批
编辑推荐厂商产品技术软件/工具OS/语言教程专题
| 电机控制 | DSP | 氮化镓 | 功率放大器 | ChatGPT | 自动驾驶 | TI | 瑞萨电子 |
| BLDC | PLC | 碳化硅 | 二极管 | OpenAI | 元宇宙 | 安森美 | ADI |
| 无刷电机 | FOC | IGBT | 逆变器 | 文心一言 | 5G | 英飞凌 | 罗姆 |
| 直流电机 | PID | MOSFET | 传感器 | 人工智能 | 物联网 | NXP | 赛灵思 |
| 步进电机 | SPWM | 充电桩 | IPM | 机器视觉 | 无人机 | 三菱电机 | ST |
| 伺服电机 | SVPWM | 光伏发电 | UPS | AR | 智能电网 | 国民技术 | Microchip |
| 开关电源 | 步进电机 | 无线充电 | LabVIEW | EMC | PLC | OLED | 单片机 |
| 5G | m2m | DSP | MCU | ASIC | CPU | ROM | DRAM |
| NB-IoT | LoRa | Zigbee | NFC | 蓝牙 | RFID | Wi-Fi | SIGFOX |
| Type-C | USB | 以太网 | 仿真器 | RISC | RAM | 寄存器 | GPU |
| 语音识别 | 万用表 | CPLD | 耦合 | 电路仿真 | 电容滤波 | 保护电路 | 看门狗 |
| CAN | CSI | DSI | DVI | Ethernet | HDMI | I2C | RS-485 |
| SDI | nas | DMA | HomeKit | 阈值电压 | UART | 机器学习 | TensorFlow |
| Arduino | BeagleBone | 树莓派 | STM32 | MSP430 | EFM32 | ARM mbed | EDA |
| 示波器 | LPC | imx8 | PSoC | Altium Designer | Allegro | Mentor | Pads |
| OrCAD | Cadence | AutoCAD | 华秋DFM | Keil | MATLAB | MPLAB | Quartus |
| C++ | Java | Python | JavaScript | node.js | RISC-V | verilog | Tensorflow |
| Android | iOS | linux | RTOS | FreeRTOS | LiteOS | RT-THread | uCOS |
| DuerOS | Brillo | Windows11 | HarmonyOS | harmonyos |
关注我们的微信

下载发烧友APP

电子发烧友观察

版权所有 © 湖南华秋数字科技有限公司
长沙市望城经济技术开发区航空路6号手机智能终端产业园2号厂房3层(0731-88081133)
电子发烧友 (电路图) 湘公网安备43011202000918 工商网监
湘ICP备2023018690号-1
工商网监
湘ICP备2023018690号-1

