 电子发烧友App
电子发烧友App


磁盘阵列技术原理学习
【简 介】
我们为什么要使用磁盘阵列?使用磁盘阵列的好处,在于数据的安全、存取的速度及超大的存储容量。如何确保数据的安全,则取决于磁盘阵列的设计与品质。其中几个功能是必须考虑的:是否有环境监控器针对温度、电压、电源、散热风扇、硬盘状态等进行监控。
目前人们逐渐认识了磁盘阵列技术。磁盘阵列技术可以详细地划分为若干个级别0-5 RAID技术,并且又发展了所谓的 RAID Level 10, 30, 50的新的级别。RAID是廉价冗余磁盘阵列(Redundant Array of Inexpensive Disk)的简称。用RAID的好处简单的说就是:安全性高,速度快,数据容量超大。
某些级别的RAID技术可以把速度提高到单个硬盘驱动器的400%。磁盘阵列把多个硬盘驱动器连接在一起协同工作,大大提高了速度,同时把硬盘系统的可靠性提高到接近无错的境界。这些“容错”系统速度极快,同时可靠性极高。
由磁盘阵列角度来看
磁盘阵列的规格最重要就在速度,也就是CPU的种类。我们知道SCSI的演变是由SCSI 2 (Narrow, 8 bits, 10MB/s), SCSI 3 (Wide, 16bits, 20MB/s), Ultra Wide (16bits, 40MB/s), Ultra 2 (Ultra Ultra Wide, 80MB/s), Ultra 3 (Ultra Ultra Ultra Wide, 160MB/s),在由SCSI到Serial I/O,也就是所谓的 Fibre Channel (FC-AL, Fibre Channel - Arbitration Loop, 100 – 200MB/s), SSA (Serial Storage Architecture, 80 – 160 MB/s), 在过去使用 Ultra Wide SCSI, 40MB/s 的磁盘阵列时,对CPU的要求不须太快,因为SCSI本身也不是很快,但是当SCSI演变到Ultra 2, 80MB/s时,对CPU的要求就非常关键。一般的CPU, (如 586)就必须改为高速的RISC CPU, (如 Intel RISC CPU, i960RD 32bits, i960RN 64 bits),不但是RISC CPU, 甚至于还分 32bits, 64 bits RISC CPU 的差异。586 与 RISC CPU 的差异可想而知 ! 这是由磁盘阵列的观点出发来看的。
由服务器的角度来看
服务器的结构已由传统的 I/O 结构改为 I2O ( Intelligent I/O, 简称 I2O ) 的结构,其目的就是为了减少服务器CPU的负担,才会将系统的 I/O 与服务器CPU负载分开。Intel 因此提出 I2O 的架构,I2O 也是由一颗 RISC CPU ( i960RD 或I960RN ) 来负责 I/O 的工作。试想想若服务器内都已是由 RISC i960 CPU 来负责 I/O,结果磁盘阵列上却仍是用 586 CPU,速度会快吗 ?
由操作系统的角度来看
SCO OpenServer 5.0 32 bits
MicroSoft Windows NT 32 bits
SCO Unixware 7.x 64 bits
MicroSoft Windows NT 2000 32 bit 64 bits
SUN Solaris 64 bits ……..其他操作系统
在操作系统都已由 32 bits 转到 64 bits,磁盘阵列上的CPU 必须是 Intel i960 RISC CPU才能满足速度的要求。586 CPU 是无法满足的 !
磁盘阵列的功能
磁盘阵列内的硬盘连接方式是用SCA-II整体后背板还是只是用SCSI线连的?在SCA-II整体后背板上是否有隔绝芯片以防硬盘在热插拔时所产生的高/低电压,使系统电压回流,造成系统的不稳定,产生数据丢失的情形。我们一定要重视这个问题,因为在磁盘阵列内很多硬盘都是共用这同一SCSI总线!一个硬盘热插拔,可不能引响其它的硬盘!甚幺是热插拔或带电插拔?硬盘有分热插拔硬盘,80针的硬盘是热插拔硬盘,68针的不是热插拔硬盘,有没有热插拔,在电路上的设计差异就在于有没有保护线路的设计,同样的硬盘拖架也是一样有分真的热插拔及假的热插拔的区别。
磁盘阵列内的硬盘是否有顺序的要求?也就是说硬盘可否不按次序地插回阵列中,数据仍能正常的存取?很多人认为不是很重要,不太会发生,但是可能会发生的,我们就要防止它发生。假如您用六个硬盘做阵列,在最出初始化时,此六个硬盘是有顺序放置在磁盘阵列内,分为第一、第二…到第六个硬盘,是有顺序的,如果您买的磁盘阵列是有顺序的要求,则您要注意了:有一天您将硬盘取出,做清洁时一定要以原来的摆放顺序插回磁盘阵列中,否则您的数据可能因硬盘顺序与原来的不苻,磁盘阵列上的控制器不认而数据丢失!因为您的硬盘的SCSI ID号乱掉所致。现在的磁盘阵列产品都已有这种不要求硬盘有顺序的功能,为了防止上述的事件发生,都是不要求硬盘有顺序的。
我们将讨论这些新技术,以及不同级别RAID的优缺点。我们并不想涉及那些关键性的技术细节问题,而是将磁盘阵列和RAID技术介绍给对它们尚不熟悉的人们。相信这将帮助你选用合适的RAID技术。
RAID级别的定义
下表提供了6级RAID的简单定义,本书其后部分将对各级RAID进行更详尽的描述。

硬盘数据跨盘(Spanning)
数据跨盘技术使多个硬盘像一个硬盘那样工作,这使用户通过组合已有的资源或增加一些资源来廉价地突破现有的硬盘空间限制。
图2所示为4个300兆字节的硬盘驱动器连结在一起,构成一个SCSI系统。用户只看到一个有1200兆字节的C盘,而不是看到C, D, E, F, 4个300兆字节的硬盘。在这样的环境中,系统管理员不必担心某个硬盘上会发生硬盘安全检空间不够的情况。因为现在1200兆字节的容量全在一个卷(Volume)上(例如硬盘C上)。系统管理员可以安全地建立所需要的任何层次的文件系统,而不需要在多个单独硬盘环境的限制下,计划他的文件系统。
硬盘数据跨盘本身并不是RAID,它不能改善硬盘的可靠性和速度。但是它有这样的好处,即多个小型廉价硬盘可以根据需要增加到硬盘子系统上。

磁盘阵列分类
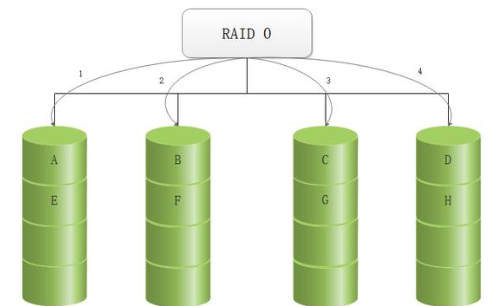
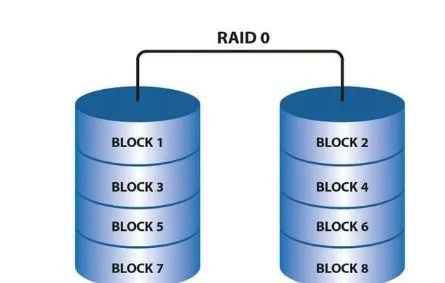
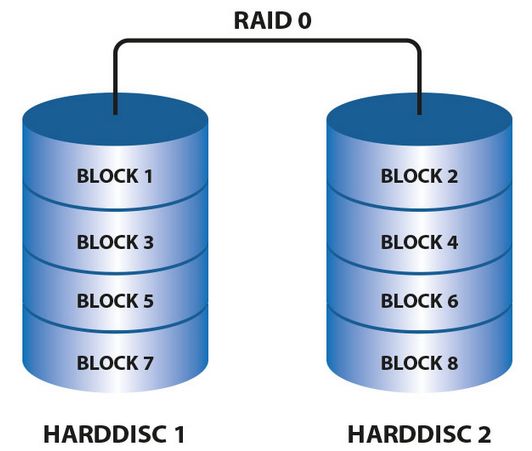
硬盘分段(Disk Striping, RAID 0)
硬盘分段的方法把数据写到多个硬盘,而不是只写到一个盘上,这也叫作RAID O,在磁盘阵列子系统中,数据按系统规定的“段”(Segment)为单位依次写入多个硬盘,例如数据段1写入硬盘0,段2写入硬盘1,段3写入硬盘2等等。当数据写完最后一个硬盘时,它就重新从盘0的下一可用段开始写入,写数据的全过程按此重复直至数据写完。
段由块组成,而块又由字节组成。因此,当段的大小为4个块,而块又由256个字节组成时,依字节大小计算,段的大小等于1024个字节。第1~1024字节写入盘0,第1025~2048字节写盘1等。假如我们的硬盘子系统有5个硬盘,我们要写20,000个字节,则数据将如图3那样存储。
磁盘阵列分类
硬盘分段(Disk Striping, RAID 0)
硬盘分段的方法把数据写到多个硬盘,而不是只写到一个盘上,这也叫作RAID O,在磁盘阵列子系统中,数据按系统规定的“段”(Segment)为单位依次写入多个硬盘,例如数据段1写入硬盘0,段2写入硬盘1,段3写入硬盘2等等。当数据写完最后一个硬盘时,它就重新从盘0的下一可用段开始写入,写数据的全过程按此重复直至数据写完。
段由块组成,而块又由字节组成。因此,当段的大小为4个块,而块又由256个字节组成时,依字节大小计算,段的大小等于1024个字节。第1~1024字节写入盘0,第1025~2048字节写盘1等。假如我们的硬盘子系统有5个硬盘,我们要写20,000个字节,则数据将如图3那样存储。

总之,由于硬盘分段的方法,是把数据立即写入(读出)多个硬盘,因此它的速度比较快。实际上,数据的传输是顺序的,但多个读(或写)操作则可以相互重迭进行。这就是说,正当段1在写入驱动器0时,段2写入驱动器1的操作也开始了;而当段2尚在写盘驱动器1时,段3数据已送驱动器2;如此类推,在同一时刻有几个盘(即使不是所有的盘)在同时写数据。因为数据送入盘驱动器的速度要远大于写入物理盘的速度。因此只要根据这个特点编制出控制软件,就能实现上述数据同时写盘的操作。
遗憾的是RAID 0不是提供冗余的数据,这是非常危险的。因为必须保证整个硬盘子系统都正常工作,计算器才能正常工作,例如,假使一个文件的段1(在驱动器0),段2(在驱动器1),段3(在驱动器2),则只要驱动器0, 1, 2中有一个产生故障,就会引起问题;如果驱动器1故障,则我们只能从驱动器物理地取得段1和段3的数据。幸运的是可以找到一个解决办法,这就是硬盘分段和数据冗余。下面一小节将讨论这个问题。
硬盘镜像(RAID 1)
硬盘镜像(RAID 1)是容错磁盘阵列技术最传统的一种形式,在工业界中相对地最被了解,它最重要的优点是百分之百的数据冗余。RAID 0通过简单地将一个盘上的所有数据拷贝到第二个盘上(或等价的存储设备上)来实现数据冗余,这种方法虽然简单且实现起来相对较容易,但它的缺点是要比单个无冗余硬盘贵一倍,因为必须购买另一个硬盘用作第一个硬盘的镜像。

硬盘镜像最简单的形式,是通过把二个硬盘连结在一个控制器上来实现的。图4说明了硬盘镜像。数据写在某一硬盘上时,它同时被写在相应的镜像盘上。当一个盘驱动器发生故障,计算器系统仍能正常工作,因为它可以在剩下的那块好盘上操作数据。
因为二个盘互为镜像,哪个盘出故障都无关紧要,二是盘在任何时间都包含相同的数据,任何一个都可以当作工作盘。在硬盘镜像这个简单的RAID方式中,仍能采用一些优化速度的方法,例如平衡读请求负荷。当多个用户同时请求得到数据时,可以将读数据的请示分散到二个硬盘中去,使读负荷平均地分布在二个硬盘上。这种方法可观地提高了读数据的性能,因为二个硬盘在同一时刻读取不同的数据片。但是硬盘镜像不能改善写数据的性能。被“镜像”的硬盘也可被镜像到其它存储设备上,例如可擦写光盘驱动器,虽然以光盘作镜像盘没有用硬盘的速度快,但这种方法比没有使用镜像盘毕竟减少了丢失数据的危险性。
总之,镜像系统容错性能非常好,并可以提高读数据的速度;它的缺点是需要双份硬盘,因此价格较高。
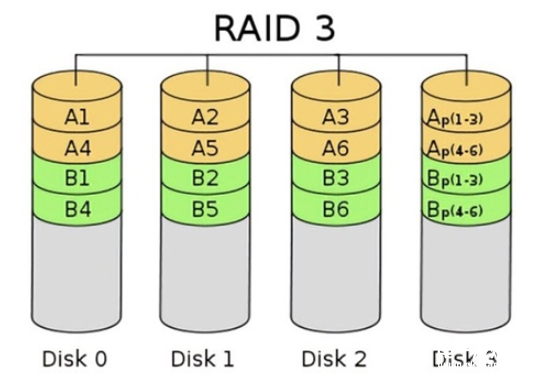
硬盘分段和数据冗余(RAID2~5)
硬盘分段改善了硬盘子系统的性能,因为向硬盘读写数据的速度与硬盘子系统中硬盘数目成正比地增加,但它的缺点是硬盘子系统中任一硬盘的故障都会导致整个计算器系统失败。整个分段的硬盘子系统部能作镜像,如果已经用了4个硬盘进行分段,我们可以再增加4个分段的硬盘作为原来4个硬盘的镜像。很明显这是昂贵的(虽然可能比镜像一个昂贵的大硬盘来得便宜)。可以不用镜像而用其它数据冗余的方法来提供高容错性能。可以选择一神奇偶码模式来实现上述方法,可以外加一个专作奇偶校验用的硬盘(如在RAID 3中),或者可把奇偶校验数据分散分布在磁盘阵列的全部硬盘中。分布式奇偶校验数据(RAID 5)的例子示于图5中。

不管用何种级别的RAID,磁盘阵列总是用异或(XOR)操作来产生奇偶数据,当子系统中有一个硬盘发生故障时,也是用异或操作重建数据。下列简单分析了XOR是怎样工作的。
硬盘 A B C 奇偶盘 (A, B, C 异或的结果)
数据 1 0 1 0
首先记住在XOR操作中,2个数异或的结果是真(即“1”)时,这二个数中有且一个数为1(另一个为0)。我们假设A, B, C中B盘故障,此时可将A, C和奇偶数据XOR起来,得到B盘失去的数据0;同样如C盘故障,我们可将A, B盘和奇偶盘的数据XOR,得到C盘原先的数据1。
如果推广到7个盘的硬盘子系统:
硬盘 A B C D E F 奇偶位
数据 0 0 0 1 0 1 0
如果丢失B盘数据,我们可以XOR A, C, D, E, F和奇偶位来得到失去的B盘数据0。而XOR A, B, C, D, E, F和奇偶位可恢复D盘的数据1。
采用专用的奇偶校验盘(如上所述,即RAID 3),当同时产生多个写操作时,每次操作都要对奇偶盘进行写入。这将产生I/O瓶颈效应。
RAID 5把奇偶位信息分散分布在硬盘子系统的所有硬盘上(而不是使用专用的校验盘0,这就改善了上述RAID 3中的奇偶盘瓶颈效应。图5说明了RAID 5的一种配置,图中奇偶信息散布在子系统的每个硬盘上。利用每个硬盘的一部分来组成校验盘,写入硬盘的奇偶位信息将较均匀地分布在所有硬盘上。所以某个用户可能把它的一个数据段写在硬盘A,而将奇偶信息写在硬盘B,第二个用户可能把数据写在硬盘C,而奇偶信息写在硬盘D。从这里也可看出RAID 5的性能会得到提高。
这种方法将提高硬盘子系统的事务处理速度。所谓事务处理,是指处理从许多不同用户来的多个硬盘I/O操作,由于可能同时有很多用户与硬盘打交道,迅速向硬盘写入数据,有时几乎是同时进行的,这种情况下,用分布式奇偶盘的方式比起用专用奇偶盘,瓶颈效应发生的可能性要小。
对硬盘操作来说,RAID 5的写性能比不上直接硬盘分段(指没有校验信息的RAID 0)。因为产生或存储奇偶码需要一些额外操作。例如,在修改一个硬盘上的数据时,其它盘上对应段的数据(即使是无关的数据)也要读入主机,以便产生必要的奇偶信息。奇偶段产生后(这要花一些时间),我们要将更新的数据段和奇偶段写入硬盘,这通常称为读-修改-写策略。因此,虽然RAID 5比RAID 0优越,但就写性能来说,RAID 5不如RAID 0。
镜像技术(RAID 1)和数据奇偶位分段(RAID 5)用于上述的硬盘子系统中时,都产生冗余信息。但在RAID 1中,所有数据都被复制到第二个相同的硬盘上。在RAID 5,数据的XOR码而不是数据本身被复制,因此可以用数据的非常紧凑的表现方式,来恢复由于某一硬盘故障而丢失的数据。
采用RAID 5时,对于5个硬盘的数组,有大约20%的硬盘空间用于存放奇偶码,而十个硬盘的数组只有约10%的空间存放奇偶码。在可用空间总的格式化空间的意义上来说,硬盘系统中的硬盘越多该系统就越省钱。
总之,RAID 5把硬盘分段和奇偶冗余技术的优点结合在一起,这样的硬盘子系统特别适合于事务处理环境,例如民航售票处,汽车出租站,销售系统的终端,等等。在某些场合,可优先考虑RAID 1(在那些写数据比读数据更频繁的情况)。但许多情况,RAID 5提供了将高性能,低价格和数据安全性综合在一起的解决办法。
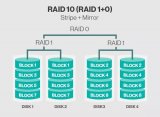
RAID Level 10

RAID Level 30

RAID Level 50

硬盘故障恢复
镜像和RAID提供了从硬盘故障中恢复数据的新方法。因为数据的所有部分都是有冗余的,数据有效性很高(即使在硬盘发生故障时)。另一重要优点是,恢复数据的工作不用立即进行,因为系统可以在一个硬盘有故障的情况下正常工作,当然在这种情况下,剩下的系统就不再有容错性能。要避免丢失数据就必须在第二个硬盘故障前恢复数据。更换故障硬盘后,要进行数据恢复。在镜像系统中“镜像” 盘上有一个数据备份,因此故障硬盘(主硬盘或镜像硬盘)通过简单的硬盘到硬盘的拷贝操作就能重建数据,如图6所示。这个拷贝操作比从磁带上恢复数据要快得多。

RAID 5硬盘子系统中,故障硬盘通过无故障硬盘上存放的纠错(奇偶)码信息来重建数据。正常盘上的数据(包括奇偶信息部分)被读出,并计算出故障盘丢失的那些数据,然后写入新替换的盘。这个过程示于图7,它比从磁带上恢复数据要快不少。
设计灵活的磁盘阵列可以重新配置,替换盘的地址不一定和故障盘的地址相同,见图8。这种灵活性使安装过程变得更为简单。备用盘甚至可以在硬盘故障前预先连在系统上。在那种情况下,它就成了随时可用的备份盘。这种盘通常称为“热备份”。


可靠性和可用性
这二个名词虽然相互关连,事实上却代表了硬盘故障的二个不同的方面,可靠性指的是硬盘在给定条件下发生故障的概率。可用性指的是硬盘在某种用途中可能用的时间。利用这二个名词,我们可以看到磁盘阵列是怎样把我们的硬盘系统可靠性提高到接近百分之百的程度的。
磁盘阵列可以改善硬盘系统的可靠性。因为某一硬盘中的数据可以从其它硬盘的数据中重新产生出来(例如RAID 5),所以很少会有机会使整个硬盘系统失效。硬盘子系统的可靠性因而大大改善了。
图表9是RAID硬盘子系统与单个硬盘子系统的可靠性比较:

我们还必须考虑系统的可用性。单一硬盘系统的可用性比没有数据冗余的磁盘阵列要好,而冗余磁盘阵列的可用性比单个硬盘的好得多。这是因为冗余磁盘阵列允许单个硬盘出错,而继续正常工作。此外,一个硬盘故障后的系统恢复时间也大大缩短(与从磁带恢复数据相比)。最后,因为发生故障时,硬盘上的数据是故障当时的数据,替后的硬盘也将包含故障时的数据(举例说,前天晚上的备份数据)。要得到完全的容错性能,计算器硬盘子系统的其它部件也必须有冗余例如提供二个电源,或者配备双份硬盘控制器。没有其它部件的冗余,即使有非常可靠的硬盘子系统,还是不能完全防止计算机系统的失效。
最佳化的容错系统
如先前所述,直接分段的子系统(RAID 0)可以大大提高读写速度(相对单个硬盘),因为数据分散在多个硬盘,硬盘操作可以同时进行。
把二个直接分段的硬盘子系统组成镜像,可以有效地构成全冗余的快速硬盘子系统。这样的子系统,其硬盘操作甚至比直接分段的硬盘子系统还快,因为该系统能同时执行二个读操作(每个硬盘一个读操作),而写操作的速度则与非镜像直接分段子系统几乎一样,因为把数据同时写入二个硬盘只需花费很少的额外开销。
通过我们前面所述的概念,例如双工:(双控制器,双电源等),可以进一步改善有关冗余方面的问题。双控制器还使我们得到更高的数据传输速度,因为控制器成为子系统性能瓶颈的可能性更小了。
磁盘阵列技术术语
硬盘镜像(Disk Mirroring):硬盘镜像最简单的形式是,一个主机控制器带二个互为镜像的硬盘。数据同时写入二个硬盘,二个硬盘上的数据完全相同,因此一个硬盘故障时,另一个硬盘可提供数据。
硬盘数据跨盘(Disk Spanning):利用这种技术,几个硬盘看上去像是一个大硬盘;这个虚拟盘可以把数据跨盘存储在不同的物理盘上,用户不需关心哪个盘上存有他需要的数据。
硬盘数据分段(Disk Striping):数据分散存储在几个盘上。数据的第一段放在盘0,第2段放在盘1,……直至达到硬盘链中的最后一个盘,然后下一个逻辑段将放在硬盘0,再下一个逻辑段放在盘1,如此循环直至完成写操作。
双控(Duplexing):这里指的是用二个控制器来驱动一个硬盘子系统。一个控制器发生故障,另一个控制器马上控制硬盘操作。此外,如果编写恰当的控制器软件,可实现不同的硬盘驱动器同时工作。
容错(Fault Tolerant):具有容错功能的机器有抗故障的能力。例如RAID 1镜像系统是容错的,镜像盘中的一个出故障,硬盘子系统仍能正常工作。
主机控制器(Host Adapter):这里指的是使主机和外设进行数据交换的控制部件(如SCSI控制器)。
热修复(Hot Fix):指用一个硬盘热备份来替换发生的故障的硬盘。要注意故障盘并不是真正地被物理替换了。用作热备份的盘被加载上故障盘原来的数据,然后系统恢复工作。
热补(Hot Patch):具有硬盘热备份,可随时替换故障盘的系统。
热备份(Hot Spare):与CPU系统电连接的硬盘,它能替换下系统中的故障盘。与冷备份的区别是,冷备份盘平时与机器不相连接,硬盘故障时才换下故障盘。
平均数据丢失时间(MTBDL-Mean Time Between Data Loss):发生数据丢失的事件间的平均时间。
平均无故障工作时间(MTBF-Mean Time Between Failure或MTIF):设备平均无故障运行时间。
廉价冗余磁盘阵列(RAID-Redundant Array of Inexpensive Drives):一种将多个廉价硬盘组合成快速,有容错功能的硬盘子系统的技术。
系统重建(Reconstruction or Rebuild):一个硬盘发生故障后,从其它正确的硬盘数据和奇偶信息恢复故障盘数据的过程。
恢复时间(Reconstruction Time):为故障盘重建数据所需要的时间。
单个大容量硬盘(SLED-Singe Expensive Drive)。
传输速率(Transfer Rate):指在不同条件下存取数据的速度。
虚拟盘(Virtual Disk):与虚拟存储器类似,虚拟盘是一个概念盘,用户不必关心他的数据写在哪个物理盘上。虚拟盘一般跨越几个物理盘,但用户看到的只是一个盘。













 工商网监
工商网监
评论