 电子发烧友App
电子发烧友App


HTTP 协议在网络知识中占据了重要的地位,HTTP 协议最基础的就是请求和响应的报文,而报文又是由报文头(Header)和实体组成。大多数 Http 协议的使用方式,都是依赖设置不同的 HTTP 请求/响应 的 Header 来实现的。
本系列《实用 HTTP》就抛开常规的 Header 讲解式的表述方式,从实际问题出发,来分析这些 HTTP 协议的使用方式,到底是为了解决什么问题?同时讲解它是如何设计的和它实现原理。
HTTP 协议是一种无状态的“松散协议”,它不会记录不同请求的状态,并且因为它本身包含了两端(客户端和服务端),根据请求和响应来区分,它大部分的内容都只是一个建议,其实双边是可以不遵守此建议的。
“这里写了建议零售价 2 元…”
“哦,不接受建议!”
在上一篇文章中,聊到了 HTTP 的缓存机制,其实缓存的主要起因就是为了减少网络请求次数,来达到快速响应的目的。而除了减少网络请求之外,其实我们还可以通过对实体内容,进行编码压缩的方式,减少传输的内容大小,从而加快响应的速度。
本文就就继续来聊聊 HTTP 的实体内容压缩编码机制。
HTTP 的内容编码
2.1 为什么要对内容进行编码?
编码的目的就是为了压缩报文实体内容的大小,而通过压缩服务器响应报文传输的内容实体,在一定程度上就可以加快响应的速度。
毕竟传输一个 10kb 的内容,会比传输一个 100kb 的内容快很多。这就是需要使用内容编码进行压缩的原因。
2.2 压缩编码
说到压缩编码,就先简单聊聊压缩算法,对于压缩算法而言,分为两类:
无损压缩算法
有损压缩算法
从名称上就可以理解,无损压缩意味着它是可以被还原的,通常被应用在文本,而有损压缩会对原始数据进行修改,以加大压缩率的目的,对文件进行有损失的压缩,这是一种不可逆的操作,通常一些对质量要求不高的图片和视频上,虽然压缩以后可能会导致文件模糊,但是勉强还可以看。
而在 HTTP 协议中,通常我们只会对文本内容,进行压缩编码。一个主要的原因在于,压缩本身是会消耗服务器资源的,而文件比多媒体文件轻便了很多。并且多媒体文件多数情况下,本身就已经是高度压缩的二进制格式,再次进行压缩的意义也不大。
2.3 设计一个“压缩协议”
前面提到,HTTP 协议是一种松散的 “协商协议”,需要客户端和服务端双端配合,才可以生效。而压缩算法有很多种,到底应该选择哪一种,也是需要双方协商的。
如果我们尝试设计一下这个 HTTP 的 “压缩协议”,主要需要关注这两点。
1. 通知服务端,客户端支持的压缩算法
一个 HTTP 事务,总是由客户端发起请求,而服务端将响应返回。那么客户端就要在发起请求的时候,率先告知服务端,当前客户端支持的压缩算法。
通常客户端会支持多种压缩算法,为了让服务端有选择的空间,应该允许传递多个支持的压缩算法。既然有多选的空间,那么就一定要有优先级的概念。
类似于我们在市场上交易,我接受人民币、美元、比特币的交易,但是因为我使用人民币更方便,所以我需要指明交易方,如果方便的话最好通过人民币交易。
2. 服务端选择支持的压缩算法压缩内容
服务端接受到客户端的请求后,辨识出客户端支持的压缩算法,现在当前环境最优的一种压缩算法对响应内容体进行压缩,然后将压缩后的内容返回。
为了让客户端接收到响应后,能明确知道服务端使用的压缩算法,还需要在响应中明确指明,当前的响应实体的数据使用的压缩算法(当然也可以不压缩)。
2.4 HTTP 的“压缩协议”
前面我们自己设计的两个条件,都是基于 HTTP 报文中的报文头来实现的。接下来我们看看 HTTP 协议中,是如何设计“压缩协议”的。
1. 请求头中的 Accept-Encoding
客户端为了告知服务端当前支持的压缩编码,可以在请求头中,增加 Accept-Encoding 这个头部字段,用来指定当前客户端支持的压缩编码,如果有多个可以使用逗号 , 进行分割。
为了满足优先级,其实是可以通过 , 分割的顺序来指定的。HTTP 协议中,还可以使用 Q 值来说明编码的优先级,Q 值的取值范围是 0.0 ~ 1.0。0.0 表示客户端不想接受此编码,而 1.0 则表示希望使用此编码,不过通常我们不需要明确的指定它,大家了解一下即可。
2. 响应头中的 content-encoding
服务端为了在响应报文里体现当前对内容压缩使用的编码格式,会在响应头中使用 Content-Encoding 标记,它是一个明确值,所以只可能有一个。
编码的目的就是为了压缩,所以当服务端选择压缩内容实体的时候,同时还会修改 Content-Length 来明确表示当前实体被编码压缩后的长度。
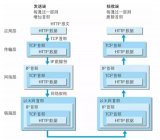
发两张压缩前和压缩后的流程图,就清晰了。
压缩前:
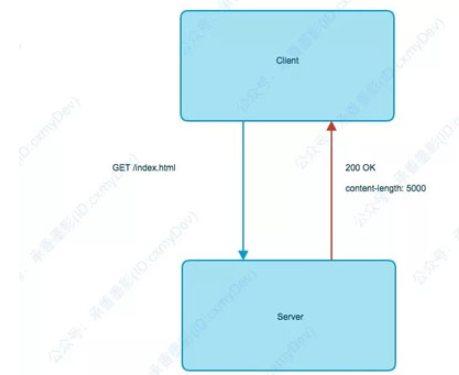
压缩后:
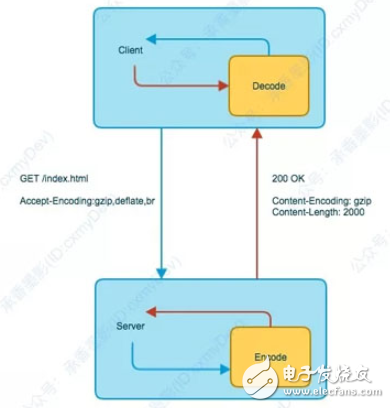
HTTP 的编码类型
3.2 HTTP 编码类型
HTTP 定义了一些标准的内容编码类型,并且可以扩展更多的编码类型。由互联网号码分配机构(IANA)对各种编码进行标准化,它给每个内容编码算法分配一个唯一的代号。
Content-Encoding 就是用这些标准化的代号来说明编码使用的算法。
比较常用的算法有:
gzip:表明实体采用 GNU zip 编码。
compress:表明实体采用 Unix 的文件压缩程序。
deflate:表明使用是用 zlib 的格式压缩的。
br:表明实体使用 Brotli 算法的压缩格式。
identity:表明没有对实体进行编码,为默认值。
在这些算法中,除了 identity 之外,都是无损压缩,他们都是需要可还原成原始的文本内容的。gzip 通常是效率最高的,使用最广泛的。
但是 gzip 对媒体文件的压缩效果相对较差,本身 JPG/PNG 这类文件已经是一种高度压缩的二进制文件,开启 gzip 效果甚微还会浪费大量 CPU 资源。
浏览器的默认实现中,这些压缩编码通常只会作用在文本内容上,就是 Content-Type 为 text/Xxx 的请求上,而对于一些媒体文件,则不会使用这种方式对其进行压缩。
3.2 GZIP
既然 gzip 是 HTTP 的内容编码中,比较常用的一种编码方式,这里抛砖引玉,简单介绍一些 gzip,其他编码方式,有兴趣的可以自行查阅相关资料。
gzip 编码是采用的 GNU Zip 编码,是一种无损的压缩算法,用于减少传输报文实体的大小,它是可逆的压缩算法,不会导致信息损失。
gzip 的压缩效率相对较高,并且使用也是最为广泛的,我们在工作中如果不特殊说明,说到的 HTTP 压缩,通常就是指的 gzip。
gzip 的原理,简单来说,就是会去扫描整个文本的字符串,找到一样的字符串,就只保留一个并分配一个标识,然后将其他相同的字符串使用这个标识替换,使整个文件变小。在还原的时候,只需要将每个标识代表的字符串,替换还原,就可以还原成最初的内容实体。
这种压缩算法,非常适用于现在的互联网产品,HTML、CSS、JavaScript 以及 Json 中,都包含了大量重复的字符串,所以在这里使用 gzip 是非常合适的。
gzip 具体能压缩多少,完全取决于压缩的实体内容,内容文本中,包含越多相同的字符串,压缩率就越高,相反则越低。在理想状态下,gzip 的压缩率能高达 70%。
四、内容编码的完整过程
到此我们就算了解清楚 HTTP 对内容编码的完整流程了。大致流程如下图。
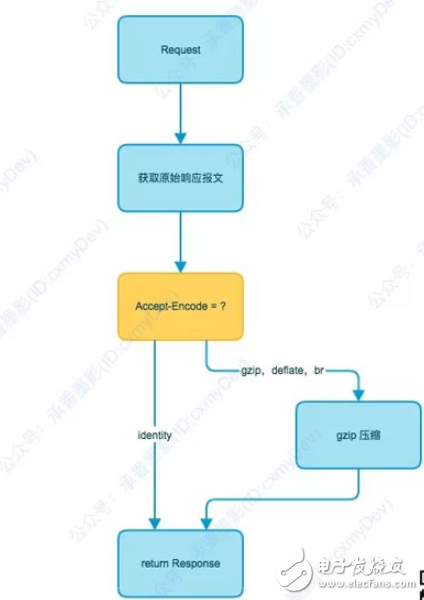
再总结几个关键点:
1. 请求头中,通过 Accept-Encoding 来指定客户端支持的内容编码格式。
2. 服务端选择一个支持的内容编码去压缩原始响应内容实体。
3. 修改响应头,增加 Content-Encoding 用于指定使用的编码方式,并且修改 Content-Length 来表明压缩后的内容大小。
4. 内容压缩的算法有很多,但是 gzip 是最常用的。
5. 内容压缩算法,都是基于无损压缩,最终都需要在客户端将内容还原。
小结
一个报文通常会包含报文头部和报文实体,而本文介绍的 HTTP 压缩编码,主要是针对报文实体内容中,文本内容的压缩编码,并为涉及到报文头部的压缩。主要是因为在 HTTP/1中,报文头部始终是以 ASCII 文本传输,没有经过任何压缩,而在 HTTP/2 中才对其实现了解决方案,所以 HTTP 的编码压缩只是针对报文实体的,这句话并不全对,这个有机会以后再说。
除了内容编码之外,HTTP 还有传输编码,这个同样也是有机会再说。















 工商网监
工商网监
评论