 电子发烧友App
电子发烧友App


网格结构化的布线模块可以让数据中心管理员最大限度地利用网络投资。
在过去十年中,随着网络规模的增长,我们可以看到网络从传统的三层网络架构向更平坦、更宽的脊叶架构的转变。凭借其完全网状的连接方式,脊叶架构为我们提供了我们所渴望的可预测的高速网络性能,以及网络交换结构中的可靠性。
但是在有诸多优点的同时,脊叶结构在结构化布线方面也提出了挑战。在本文中,我们将研究如何构建和扩展一个4路脊柱,并逐步发展到更多的脊柱网络(如16路脊柱),并在网络发展过程中保持线速度切换能力和冗余。我们也将在结构化布线的主要区域内,探讨两种方法的优点和缺点:一种方法使用传统的光纤跳线,另一种使用光学网格模块。
发展简史
自20世纪80年代作为局域网(LAN)协议问世以来,以太网以其简单的算法和低廉的制造成本,一直是数据中心和互联网发展的推动力。以太网交换机在切换之前会查看它接收到的每一个包。它只打开外层信封来读取第2层的地址,而不用读取IP地址。这允许以太网交换机非常快速地移动数据包。
尽管以太网效率很高,但随着网络规模的增大,它也存在一些缺点。在一个由多个以太网交换机组成的网络中,为了阻止地址解析协议(ARP)请求等广播包在网络中泛滥和循环,使用了一种称为生成树协议(STP)的技术。STP阻塞冗余链接以防止网络中发生循环。在STP技术上运行的网络在主链路失败时使用冗余链路作为故障转移。这为基础结构提供了弹性,代价是可用带宽的利用率仅为一半。
过去很长的一段时间,我们都在使用生成树的逻辑来构建网络,直到我们遇到了一系列新的问题。第一个问题是我们的双核网络有限,没有增长空间(为了服务越来越多的客户,我们的网络需要相应地增长)。第二个问题是延迟。如果我们有一个大的网络,我们通常把它们分成更小的网络,我们称之为虚拟局域网(VLAN)。这将导致不同类型的数据流量具有不同的延迟。与通过第3层核心的不同VLAN之间的流量相比,在单个VLAN中通过第2层网络的流量具有不同的延迟。
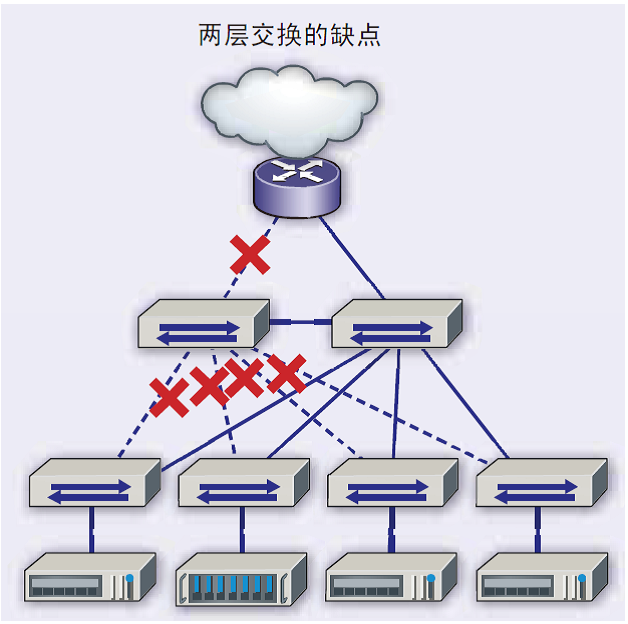
支持生成树协议的典型三层网络。冗余链接被阻止,以防止网络循环。
脊叶架构简介
现代电子商务、社交媒体和云应用程序大多使用分布式计算为客户服务。分布式计算是指服务器与服务器进行对话并并行工作,以创建动态web页面并回答客户问题;它需要相同的延迟。等待结果会让客户不满意。我们需要一个网络架构,它可以均匀地增长,并为现代应用程序提供统一的延迟。
这些问题的解决方案来自于一种网络架构,即今天所说的“脊叶架构”。自1952年Charles Clos首次引入多级电路交换网络(也称为Clos网络)以来,这个想法就一直存在。这种网络架构的主干称为脊(Spin),每个叶(Leaf) 都通过脊连接到进一步扩展的网络资源。只需添加更多的脊或叶交换机,网络就可以均匀地增长,而不会改变网络性能。
与传统的3层架构相比,网络的脊部分水平增长,约束了网络的层数。例如,通过双向脊网络,我们可以建立网络,支持多达6000台主机,通过4路脊网络,我们可以建立网络多达12000台主机,通过16路脊网络,我们可以超过100,000台10-GbE主机。
其次,所有的叶交换机都连接到架构中每个可用的脊交换机。这种完全网格化的架构允许任何连接到叶的主机只使用两个跃点连接其他主机,即交换机到交换机连接。例如,从叶交换机1到脊交换机1,然后从脊交换机1到叶交换机10。因为整个脊层是用冗余方式构建的(在脊或叶交换机宕机的情况下),所以可以自动使用替代路径和资源。
建立脊叶结构网络的基本规则如下:
主要构建模块是网络叶交换机和网络脊交换机。
所有主机只能连接到叶交换机。
叶交换机控制服务器之间的流量。
脊交换机在第2层或第3层的叶子交换机之间沿着最佳路径向前切换流量。
叶交换机上的上行端口数量决定了脊交换机的最大数量。
脊交换机端口数量决定叶交换机的最大数量
这些原则影响交换机制造商设计其设备的方式。
仔细观察一下脊交换机。如果我们观察一个典型的脊交换机,第一眼我们注意到多个扩展槽,例如4或8个来接受不同的线卡,用于连接叶交换机上行链路。
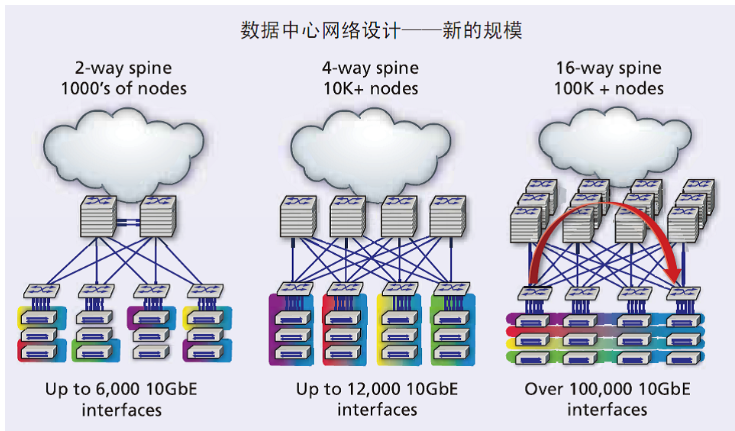
在一个脊叶网络结构中,叶交换机控制服务器之间的流量,而脊交换机沿着叶交换机之间的最佳路径转发流量。一个被称为16路脊的架构可以扩展到支持超过100,000个10千兆位以太网主机。
板卡可以有不同的类型,例如36x40G QSFP(用于40-Gig)端口或32x100G QSFP28(用于100-Gig)端口。QSFP (Quad small form pluggable)和QSFP28端口是空的,因此必须分别购买单模或多模收发机或有源光缆(AOC),或双绞电缆。一般规则是,脊交换机上可用端口的数量决定可以连接到脊的叶交换机的数量,从而决定可以连接到网络的最大服务器数量。
接下来,我们将看到监控模块监控和管理整个交换机的操作。电源支持层提供充裕的电力,在脊交换机的背面,我们通常有网络模块,来协调不同线卡之间的流量。在脊交换机的板卡上,均匀分布叶交换机的上行链路连接,减少了通过结构模块的数据量,从而显著提高交换机性能。
这增加了端到端包裹交付时间,也就意味着延迟,并需要采购额外的交叉板卡,而这意味着额外的成本。在接下来的章节中,我们将讨论如何使用布线解决这些问题。
仔细观察叶交换机。当讨论叶交换机时,主要考虑的是上行端口的数量,它决定了可以连接到多少个脊交换机,以及下行端口的数量,它决定了可以连接到叶交换机的主机数量。上行链路端口可以支持40/100G速度,下行链路端口可以根据您计划使用的模块在10G/25G/40G/50G之间进行选择。
扩展具有冗余和线速交换的脊叶网络。让我们考虑一下这种情况。我们有两个脊交换机,每个脊交换机上有四张板卡,但是每个叶交换机上只有四个上行端口。是否可以将这4个上行链路分布在8个板卡中,以保持冗余和线速交换?
如果我们使用40G SR4收发器,我们知道它们实际上是由4 x10G SR收发机组成的,一个40G- SR4端口可以被视为四个独立的10G端口。这称为端口分开应用(port break-out application)。端口分开允许我们扩展和冗余,因为我们扩展网络的方式,传统技术上做不到。例如,可以将2x40G SR4收发器拆分为8 x10G端口,并轻松地将它们分布在8个板卡上。
使用传统端口分开的方法进行交叉连接--为了表示这一点,让我们使用康宁EDGE? 解决方案端口分开模块创建一个10G的交叉连接。我们可以使用EDGE解决方案端口分开模块在脊层端接所有40G QSFP端口。我们可以对叶交换机做同样的处理。现在,我们可以简单地在各自的叶交换机和脊交换机之间做一个LC 跳线连接。通过这样做,我们可以分开所有40G端口,并将它们分布在4个不同的板卡上。
冗余得到保持,这意味着如果你丢失了一个板卡,你只损失了25%的带宽。我们通过确保所有的板卡上都连接了所有的叶交换机来维护线速交换,因此不需要通过垂直架构模块进行通信。每个黄色突出显示的端口代表一个40G QSFP端口。
这是最优的做事方式吗? 不。这被称为使用旧工具构建新网络。
用网格模块交叉连接--有更好的方法吗?
让我们考虑一下网格模块。这个网格模块连接到一侧的脊交换机和另一侧的叶交换机。脊交换机侧端口连接到脊交换机上的单板卡。每次我们在叶交换机侧连接一个叶交换机,它就会自动断开那个端口并将它们在网格模块上的脊交换机端口上重新连接,这些端口已经连接到单独的板卡上了。
我们不需要做任何LC跳线的修补。我们仍然实现了我们在上一个场景中尝试的重新连接,我们有完全的冗余,我们可以从交换机获得完全的性能。
在这个设置中,一个网格模块连接到一侧的脊交换机和另一侧的叶交换机。脊交换机侧端口连接到脊交换机上的单板卡。每当用户连接叶交换机一侧的叶端子交换机时,该端口就会自动断开,并在网格模块上的脊交换机端口之间来回移动--这些端口已经连接到单独的板卡上。不需要LC-LC跳线修补。
通过网格模块扩展网络--从双路脊交换机到4路脊交换机是容易的。我们只需要在每个脊交换机上使用一个网络模块,并将每个从叶交换机而来的40G上行链路分配到每个脊交换机的4个板卡上。
使用网格模块,扩展4路脊交换机是很容易的。我们将网格模块的脊交换机,连接到其他脊交换机。我们正在失去板卡级的冗余和交换效率,但我们通过将风险分布在16路脊交换机上而获得了更多的冗余。因此,我们还应该投资矩阵模块,因为在同一个机箱中,不同的板卡上有不同的叶交换机。通过此项最后的扩展,我们可以得到一个比4路脊交换机大四倍的网络。
使用网格模块有几个优点。我们可以降低45%的连接成本。通过用MTP接线代替LC接线,我们可以减少75%的拥塞。因为我们不需要配线架来进行LC断接和跳接,我们可以在设备主分布区 (MDA) 实现75%的空间节省。
历史告诉我们,随着每一个新的技术发展,我们必须发明新的做事方法。今天,这个行业正在向脊叶结构转变,交换机制造商已经为新一代的数据中心交换机架构设计了先进的交换机系统。这种架构的基本要求是构建网格结构的布线模型,使您能够从矩阵架构投资中获得最大的收益。
使用网格模块场景,我们可以超越双路脊柱,甚至超越4路脊柱,达到如图所示的16路脊柱。实现这种方法后,用户确实会丢失板卡级冗余和交换效率; 然而,通过将风险分散到16路脊柱,用户也获得了更多的冗余。对于这种类型的网络部署,值得在矩阵模块上进行投资,因为在这种情况下,同一机箱的不同板卡上连接着不同的叶交换机。
脊叶结构的网格连接可以使用标准MDA风格的结构化布线系统实现,我们可以将其与”使用旧工具构建新事物“的方法进行比较。使用网格模块作为构建下一代网络的新工具可以显著降低数据中心结构的复杂性和连接成本。
责任编辑:ct












 工商网监
工商网监
评论