 电子发烧友App
电子发烧友App


来自复旦大学、上海市智能信息处理重点实验室和香港大学的研究者提出了一种基于 DINO 知识蒸馏架构的分层级联 Transformer (HCTransformer) 网络。
小样本学习是指从非常少量的标记数据中进行学习的问题,它有望降低标记成本,实现低成本、快速的模型部署,缩小人类智能与机器模型之间的差距。小样本学习的关键问题是如何高效地利用隐藏在标注数据中的丰富信息中进行学习。近年来,视觉 Transformer (ViT [1]) 作为计算机视觉领域的新兴架构,因其在很多主流任务中都取得了反超 CNN 的表现而受到广泛关注。我们注意到 ViT 在训练时易于陷入过拟合的状态而表现出较差的性能,现有的研究大部分关注其在大、中型数据集上的表现,而几乎没有将其应用于针对更加敏感于过拟合的小样本任务上的相关研究。
为了缓解这一问题,提高小数据集下数据的利用效率,来自复旦大学、上海市智能信息处理重点实验室和香港大学的研究者提出了一种基于 DINO [2] 知识蒸馏架构的分层级联 Transformer (HCTransformer) 网络,通过谱聚类 tokens 池化以利用图像的内在结构来减少前景内容和背景噪声的模糊性,同时也提供了对不同数据集对于 patch token 切分大小的不同需求的适用性选择;并利用一种非传统的监督方式,通过标签的潜在属性在图像标签中找到更丰富的视觉信息,而非简单地学习由标签分类的视觉概念。实验表明,本文的方法在各个流行的 Few-Shot Classification 数据集上均取得了 SOTA 性能。

论文链接:https://arxiv.org/abs/2203.09064
代码链接:https://github.com/StomachCold/HCTransformers
目前,这项研究已被 CVPR2022 接收,完整训练代码及模型已经开源。 方法
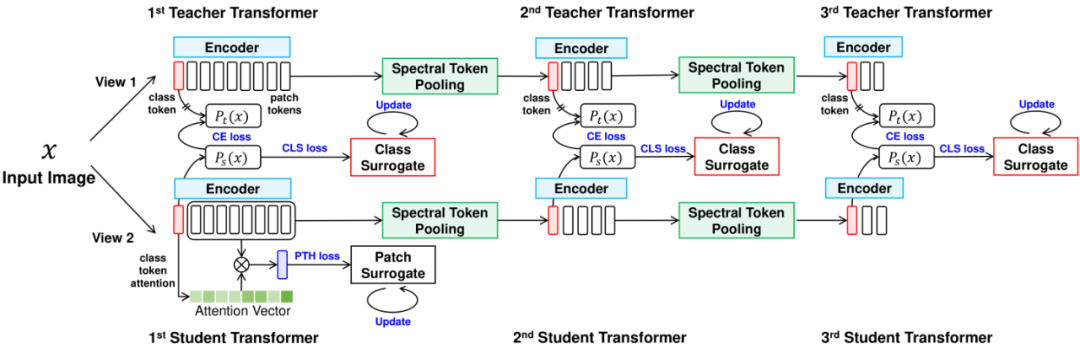
图 1:方法整体架构。包括三个级联的 Transformer 网络,每一阶段都是一个 teacher-student 的知识蒸馏结构。 DINO 自监督架构 DINO 是一种基于知识蒸馏架构的自监督网络,和 BYOL [3] 类似,但 DINO 使用 Transformer 代替了 BYOL 中的 CNN。其中 Student 模型和 Teacher 模型的结构是完全一样的。 在训练过程中,Teacher 模型并不通过输入来更新参数,它的权重更新是通过对 Student 模型权重的 EMA(exponential moving average ) 来更新的。此外,Teacher 和 Student 都有独立的数据增强方式。在这种设定下,整个网络会把 Teacher 网络的输出当作是 Student 网络的标签,从而指导全局更新。因为网络没有直接使用图片的类别标签,所以可以支持使用较高维度的特征(如 65536)而不必局限于图像的类别数量,使得网络可以学习到更加细腻的特征表示。但在自监督的架构下,由于小样本学习的数据集较小,直接应用 DINO 进行训练很难取得较好的效果。
属性代理监督
基于这一前提,本文设法将 DINO 改成有监督模型,但 Transformer 在小数据集上直接使用 one-hot 向量作为标签,不仅需要将网络输出维度改成图片类别数导致学习相对粗糙,而且会产生较严重的过拟合现象。因此,本文针对小样本任务,为 Transformer 设计了一种属性代理监督的传播方案,以避免传统监督带来的局限性。 具体来说,对于标签空间中的每个视觉概念 y,我们的目标是为其学习一个语义属性的代理向量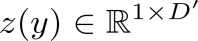 ,进而使同一个标签的输出均向这个代理向量在向量空间中靠拢,也同时影响到该代理向量的更新。其中,y 是输入数据的标签,D' 是整个网络的输出维度。
,进而使同一个标签的输出均向这个代理向量在向量空间中靠拢,也同时影响到该代理向量的更新。其中,y 是输入数据的标签,D' 是整个网络的输出维度。
在 Transformer 中,输入图片在通过 Encoder 后会得到一个 class token 和 N 个 patch tokens。一般来说在分类任务中,只会单一使用某一种token作为最终输出结果进行监督,而丢弃另一种token。相较于传统设计,本文将 class token 和 patch tokens 同时都用于监督,以更大限度提高数据利用率。
Class Token 监督
图片输入到 DINO 网络中,会经过 encoder 后生成一个 class token 和 N 个的 patch tokens,之后 class token 再通过一个 MLP 得到最终的输出。不同于传统监督方式,由于 DINO 本身的自监督设计,导致最终的输出并不是一个 one-hot 向量,而是一个更高维度的向量。因此我们为每一个标签设计了一个维度的可学习向量作为该类别的代理属性,通过 KL 散度将同一标签的输出聚拢。
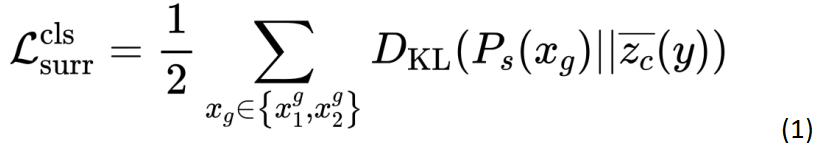
在公式 1 中,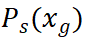 是 student 网络中的 class token 经过 MLP 的最终输出,是该标签对应的语义属性代理向量。
是 student 网络中的 class token 经过 MLP 的最终输出,是该标签对应的语义属性代理向量。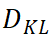 为 KL 散度计算。 Patch Tokens 监督 在 Transformer 中,由于缺少 patch 级别的标签信息,patch tokens 一般很难与 class token 同时用来监督网络。为了对 patch tokens 进行监督,我们把 N 个 patch tokens 用经过 softmax 操作后的注意力矩阵进行加权合并计算,得到一个全局 token,然后采用和 class token 相同的监督方式对该全局 token 进行监督。
为 KL 散度计算。 Patch Tokens 监督 在 Transformer 中,由于缺少 patch 级别的标签信息,patch tokens 一般很难与 class token 同时用来监督网络。为了对 patch tokens 进行监督,我们把 N 个 patch tokens 用经过 softmax 操作后的注意力矩阵进行加权合并计算,得到一个全局 token,然后采用和 class token 相同的监督方式对该全局 token 进行监督。
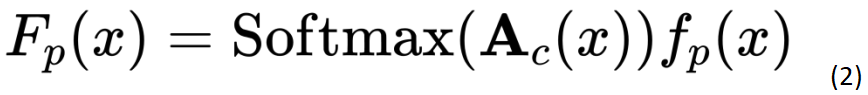
其中,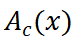 为 class token 对其他 patch tokens 的注意力矩阵,
为 class token 对其他 patch tokens 的注意力矩阵,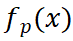 是 encoder 后输出的 patch tokens,
是 encoder 后输出的 patch tokens,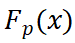 为加权合并后的全局 token。
为加权合并后的全局 token。
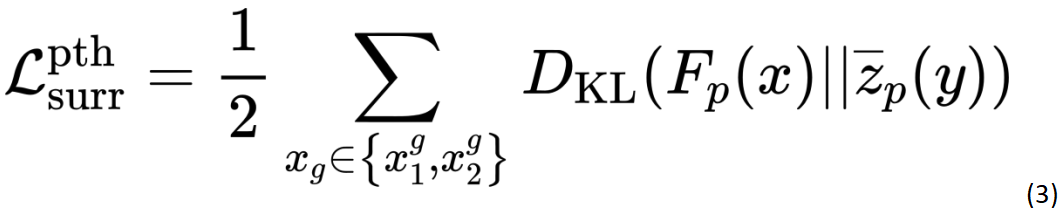
公式 3 与公式 1 采用相同的策略。 谱聚类 tokens 池化 许多工作, 如 GroupFPN [4] 和 GLOM [5] 都证明了多尺度层次结构对 CNN 和 Transformer 都有效。本文的设计目的是为了将层次结构嵌入到 Transformer 中来提高网络对特征的判别能力。与 Swin Transformer [4] 使用固定的网格池化方案不同,本文利用不规则网格池化方法来更灵活地匹配图像结构。由于 Transformer 将在 tokens 之间生成自注意力矩阵,因此它为谱聚类算法 [5] 提供了强大的先验经验,以根据语义相似性和空间布局对 tokens 进行分割合并。因此我们提出了一种基于谱聚类的池化方法,称为谱聚类 tokens 池化。 为了保持各 patch 之间原有的位置关系信息,本文对于 ViT 中的 N 个 patch tokens 之间的注意力矩阵加上了邻接限制,使每个 patch 只和相邻的 8 个 patch 有相似性。
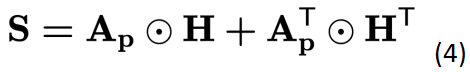
其中,A_p 是 patch tokens 的注意力矩阵,H 是包含位置信息的邻接矩阵。 然后我们对 S 矩阵做一个 softmax 操作得到我们最终需要的 S' 矩阵作为谱聚类 tokens 池化的输入。

如上算法所示,每一次池化后我们将得到同类聚类数量减半的新 tokens。 在本文的网络设计中,训练阶段首先会训练第一阶段的 Transformer 网络来得到一个有较好表征能力的特征生成器,随后再引入池化操作,加上二三阶段 Transformer 共同训练。最终在三阶段中通过验证集挑选出最优结果作为最终输出。

图 2:谱聚类池化的可视化图
实验结果
我们分别在四个流行的 Few-Shot Classification 数据集:mini-Imagenet, tiered-Imagenet, CIFAR-FS 和 FC100 上做了详尽的实验。
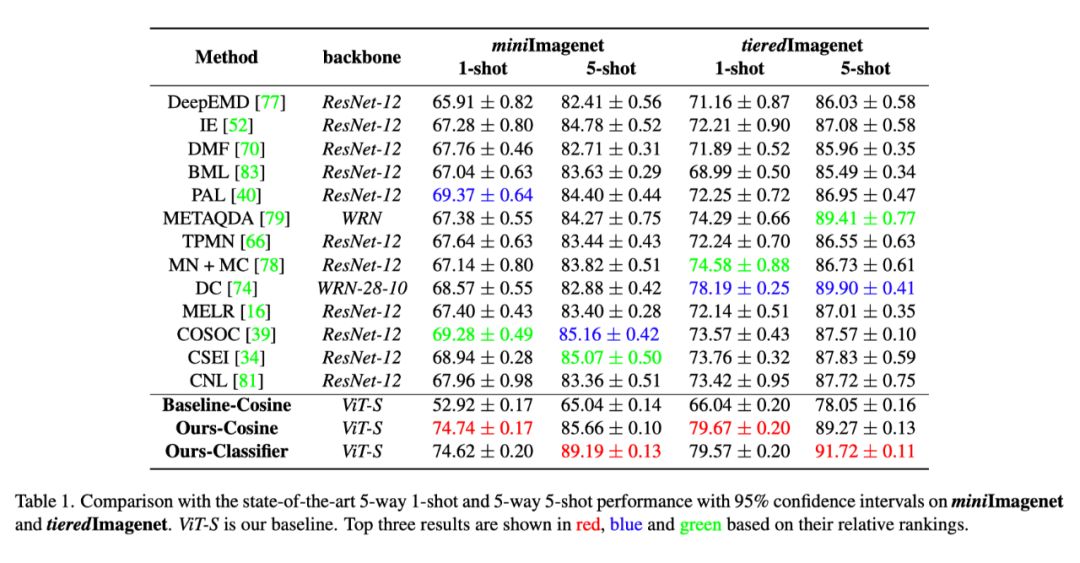

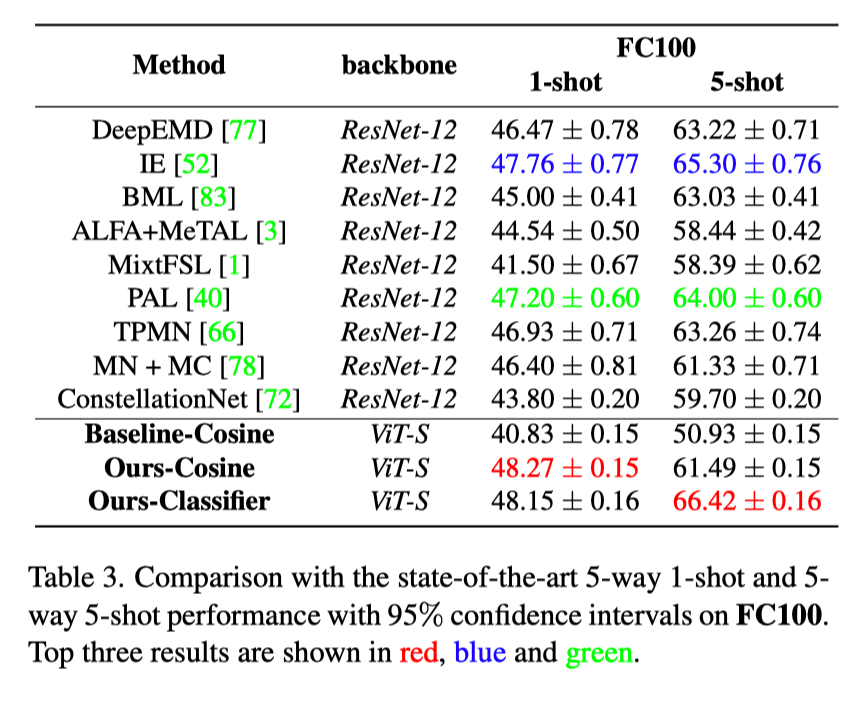
最终结果如表 1,2,3 所示:相比于现有的 SOTA 模型,HCTransformers 在 1-shot 和 5-shot 的结果上都显示出明显的性能优势。例如,如表 1 所示,在 miniImagnet 上,HCTransformers 比最优 SOTA 结果分别高出 5.37%(1-shot) 和 4.03%(5-shot)。在 tieredImagenet 上,我们的方法在 1-shot 和 5-shot 上的表现分别比最好的 DC [6] 方法高出 1.48% 和 1.81%。与 DC 相比,我们不需要从 base 训练集中借用类某类图像的统计信息,并且使用更轻量级的分类器。此外,我们的方法和第三好的方法之间的差距是 5.09%,这也进一步验证了我们的贡献。 这样令人印象深刻的结果要归功于我们的网络结构,它能学习到数据中固有的内在信息,并具有良好的泛化能力。表 2 和表 3 分别显示了在小分辨率数据集 CIFAR-FS 和 FC100 上的结果。HCTransformers 在这些低分辨率设置中显示出和 SOTA 类似或更好的结果: 在 CIFAR-FS 上提高了 1.02%(1-shot) 和 0.76%(5-shot); 在 FC100 上提高了 0.51%(1-shot) 和 1.12%(5-shot)。在小分辨率数据集上,我们并没有超越以前的 SOTA 方法很多,我们将其归因于 ViT 的 patch 机制:当图像分辨率较小时,如 32*32,每一个 patch 所包含的实际像素过少,很难提取出有用的特征表示。DeepEMD [7] 的实验也佐证了 patch cropping 会对小分辨率图像产生负面影响。即便如此,我们的方法仍然在这两个基准上都取得了新的 SOTA 结果。
参考文献
[1]. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov,Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner,Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An imageis worth 16x16 words: Transformers for image recognition at scale. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021.OpenReview.net,2021. 1, 2, 3, 7, 8
[2]. Mathilde Caron, Hugo Touvron, Ishan Misra, Herv´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. arXiv preprint arXiv:2104.14294, 2021. 3, 5
[3]. Jean-Bastien Grill, Florian Strub, Florent Altch´e, Corentin Tallec, Pierre H.Richemond, Elena Buchatskaya, Carl Doersch, Bernardo ´Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, Bilal Piot, Koray Kavukcuoglu, R´emi Munos, and Michal Valko. Bootstrap your own latent-A new approach to self-supervised learning. In Hugo Larochelle, Marc’Aurelio Ranzato, Raia Hadsell, Maria- Florina Balcan, and Hsuan-Tien Lin, editors, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. 3
[4]. Gangming Zhao, Weifeng Ge, and Yizhou Yu. Graphfpn:Graph feature pyramid network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2763–2772, 2021. 1
[5]. Geoffrey Hinton. How to represent part-whole hierarchies in a neural network. arXiv preprint arXiv:2102.12627, 2021. 1
[6]. Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. International Conference on Computer Vision (ICCV), 2021. 2, 4
[7]. Andrew Y Ng, Michael I Jordan, and Yair Weiss. On spectral clustering: Analysis and an algorithm. In Advances in neural information processing systems, pages 849–856, 2002. 1, 5
[8]. Shuo Yang, Lu Liu, and Min Xu. Free lunch for few-shot learning: Distribution calibration. In International Conference on Learning Representations (ICLR), 2021. 6
[9]. Chi Zhang, Yujun Cai, Guosheng Lin, and Chunhua Shen. Deepemd: Few-shot image classification with differentiable earth mover’s distance and structured classifiers. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020. 6, 7, 8









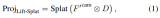





 工商网监
工商网监
评论