 电子发烧友App
电子发烧友App


背景
如今,随着分解式存储和微服务架构的日益流行,在现代数据中心,高扇出和扇入的远程过程调用(RPC)产生了大部分的流量,据统计,在谷歌的数据中心网络中,超过95%的流量均由RPC产生。而RPC性能的好坏是应用性能的好坏的一个重要指标,因此,研究什么会影响RPC的性能至关重要。RPC在大多数情况下性能良好,但是,在网络负荷超载的情况下,网络负载可能是平常的8倍以上,RPC的时延是造成网络时延峰值的主要原因。在这时,网络的需求量大于容量,所以需要对重要的RPC提供网络时延SLO保证。RPC被分为3类:对时延敏感的性能重要RPC(Performance-critical,PC)、对吞吐敏感的非重要RPC(Non-critical,NC)和没有SLO要求的尽最大努力交付RPC(Best-effort,BE)。
相关工作
先前的工作中有基于优先级调度的方法。基于大小的优先级调度,如最小工作优先(Smallest Job First,SJF)和最小剩余时间优先(Smallest Remaining Time First,SRTF)可以减小平均RPC时延,但是RPC的大小不等同于RPC的优先级且这个方法在实际中很难实施。第二种是对RPC使用严格的优先级队列(Strict Priority Queue,SPQ),这种方法可以提供直接的优先级映射,但同时也会让每个人都倾向使用最高的优先级,且存在饥饿的问题。另一个方法,就是使用加权公平队列(Weighted-Fair Queuing,WFQ),很多包括谷歌在内的云服务提供商,使用的也是这种方法。这种方法有两个有点:第一,RPC的优先级可以直接对应到WFQ的QoS队列上;第二,WFQ已实际部署在商用交换机上了,使得大规模地部署很简单。但这方法也存在两种问题:第一,QoS的类别和SLO并不相关;第二,应用层面上的优先级映射太粗粒度,其体现在PRC优先级和QoS级别的不一致。为了解决WFQ的两个问题,本文作者设计了Aequitas。
设计
Aequitas的设计目标,是为了解决上述提到的WFQ的两个问题,具体做法是将优先级映射从粗粒度调整到细粒度;管理不同QoS级别间的流量分布(QoS-mix),为重要的RPC提供有保障的SLO。流程如下图所示。 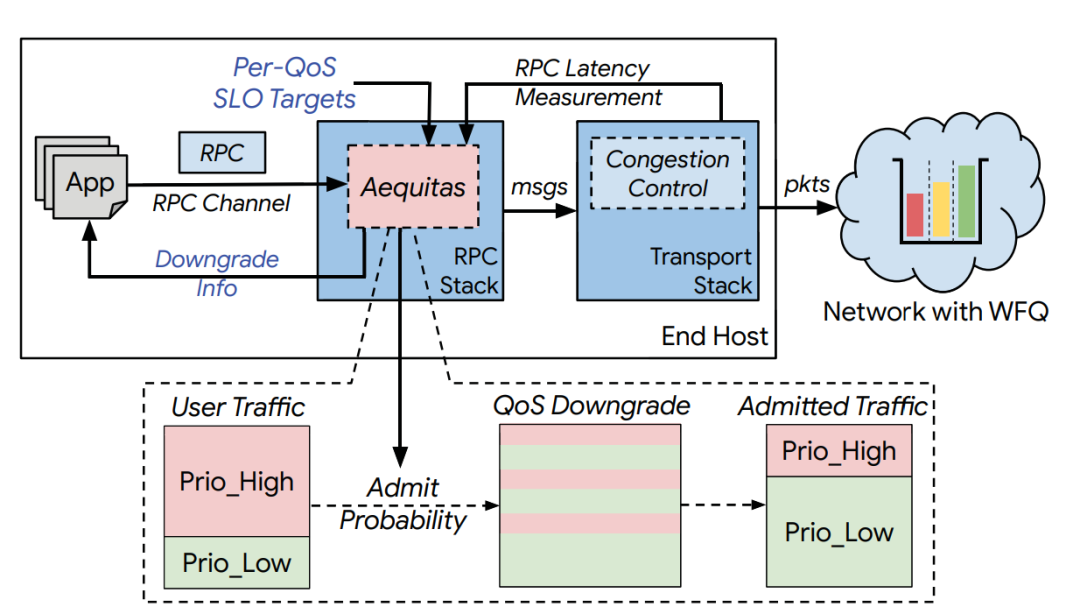 第一, 将优先级与WFS 的QoS在RPC的粒度上对应。具体来说,对每个应用的每个RPC设定优先级,并按照PC,NC,BE到高、中、低,依次进行映射。
第一, 将优先级与WFS 的QoS在RPC的粒度上对应。具体来说,对每个应用的每个RPC设定优先级,并按照PC,NC,BE到高、中、低,依次进行映射。 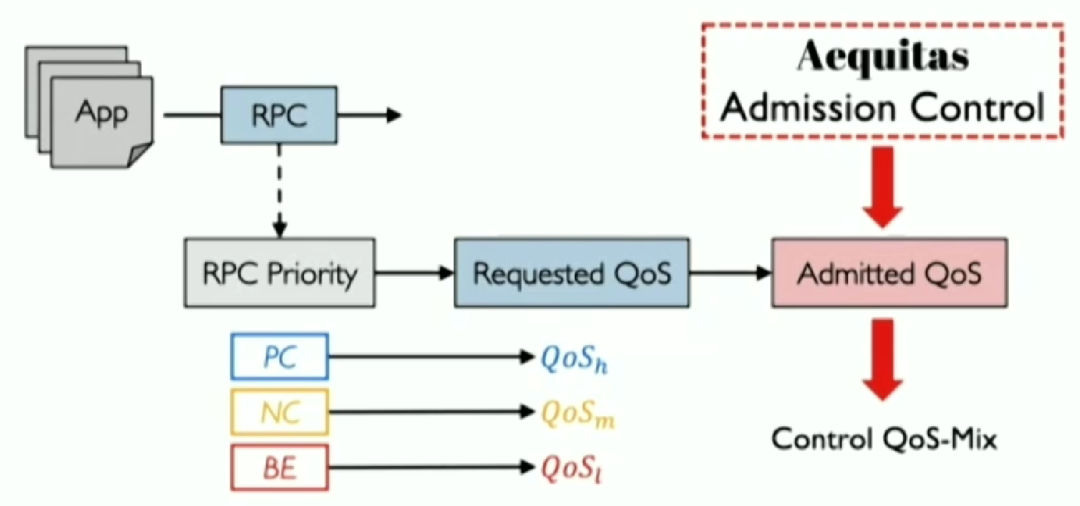 第二, 通过允许控制来直接控制QoS-mix。如下图所示,Aequitas通过概率允许控制机制,对所有的QoS进行调整:保持原来的QoS来传输或降到最低级,若发生了QoS降级,则会告知应用修改其不同等级QoS的分布。这样就能得到最终的QoS-mix。
第二, 通过允许控制来直接控制QoS-mix。如下图所示,Aequitas通过概率允许控制机制,对所有的QoS进行调整:保持原来的QoS来传输或降到最低级,若发生了QoS降级,则会告知应用修改其不同等级QoS的分布。这样就能得到最终的QoS-mix。 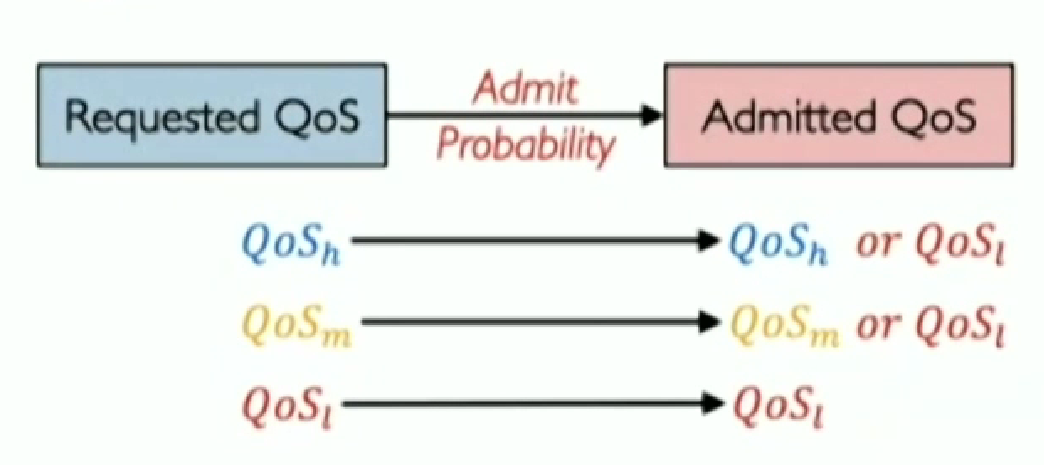 Aequitas的概率允许机制是一个分布式的算法,概率的调整方式为加法增加和乘法减小(Additive Increase Multiplicative Decrease, AIMD)。具体来说,在各终端主机上,对每个(源地址,目的地址,要求QoS)这样的元组,维持着一个允许概,测量并收集网络中RPC的时延(RPC Network Latency,RNL)。如果RNL小于目标SLO,则将允许概率加上增加窗口的大;反之,则乘法减小允许概率。
Aequitas的概率允许机制是一个分布式的算法,概率的调整方式为加法增加和乘法减小(Additive Increase Multiplicative Decrease, AIMD)。具体来说,在各终端主机上,对每个(源地址,目的地址,要求QoS)这样的元组,维持着一个允许概,测量并收集网络中RPC的时延(RPC Network Latency,RNL)。如果RNL小于目标SLO,则将允许概率加上增加窗口的大;反之,则乘法减小允许概率。
实验评估
本文的评估实验包括模拟、测试集实验和实际生产应用的结果。重点在两个方面,首先是通过控制99%或99.9%的RNL,测试Aequitas是否仍然符合正确性;其次是在不论流量如何分布的情况下,Aequitas是否提供接近理想的流量。 从下图实验结果可以看出,不论高优先级的流量占比多少,Aequitas都能提供较好的SLO保证(蓝色线为Aequitas结果,黄色线为SLO目标,二者很接近)。与其他调度算法,如SPQ相比,Aequitas效果显著(红色线为SPQ算法的调度结果,其与SLO相差甚远)。由此可见,Aequitas可以在网络过载情况下,保证SLO。 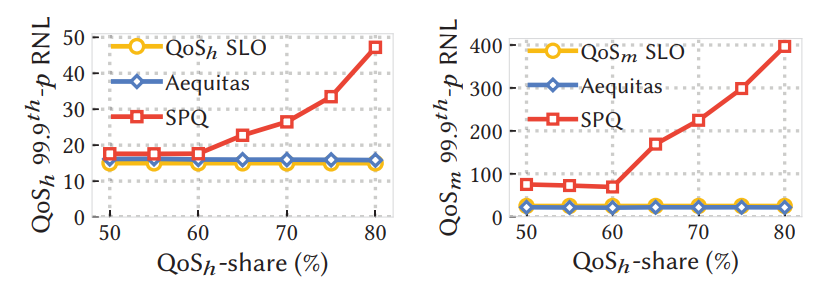
个人观点
在网络过载的情况下,要求高QoS的RPC数据量远超网络的传输能力,在这时就要在时延和服务质量之间做出取舍。在这篇论文中,Aequitas通过牺牲尾时延来获取更低的99%(99.9%)时延,即牺牲一小部分来获取整体性能的提升。
Time-division TCP for reconfigurable data center networks
Shawn Shuoshuo Chen (Carnegie Mellon University), Weiyang Wang (MIT), Christopher Canel (Carnegie Mellon University), Srinivasan Seshan (Carnegie Mellon University), Alex C. Snoeren (UC San Diego), Peter Steenkiste (Carnegie Mellon University)
本篇文章由卡内基梅隆大学、麻省理工学院以及加州大学圣地亚哥分校的研究者合作完成。本论文提出了时分TCP(TDTCP),这是专门为可重构网络设计的TCP新变体,旨在充分利用RDCN提供的额外容量。
背景
大多数数据中心网络大多基于Clos拓扑,并提供单个全平分网络的“big switch”抽象,以应对通过高带宽、低延迟结构连接大量终端主机的挑战。但随着主机数量的增加以及摩尔定律的放缓,这种方法达到极限。为了应对宽带供需差距的不断扩大,一些研究者提出了基于optical circuit switch的可重构数据中心网络。该方法可以动态分配可用的网络资源,成本更低,扩展性更好。但由于TCP的拥塞控制不适用于延迟和带宽剧烈变化的网络,现有的TCP变体无法充分利用RDCN提供的额外容量。为了充分利用RDCN提供的额外容量,该论文提出了时分TCP (TDTCP),这是专门为可重构网络设计的TCP新变体。作者的灵感来自于以下发现—“只要网络在不同的配置之间清晰移动,就足以在每个配置中分别有效地运行”。具体来说,完整的算法是单个模型的分段函数,TDTCP随着时间的推移复用独立的网络状态,随着网络从一种配置转移到另一种配置,发送者在网络模型之间切换。
设计
(1) TDN 变化通知 RDCN的光学配置时间大约为几个RTT,主机几乎没有时间对新的网络环境做出反应。作者利用终端主机连接的ToR交换机直接参与重新配置网络结构来解决这一个挑战。具体来说,作者让ToR交换机在路径发生变化时直接通知其连接的主机。该信令使得终端主机能够将可重构网络视为一系列周期性变化的时分网络 (TDN) 。具体来说,作者使用ICMP数据包来携带该通知,ICMP数据包仅使用一个整数索引,指示当前活动的网络路径。因为ToR交换机和终端主机处于同一机架内,通知延迟可以保持在较低的水平。 (2) 序列空间与包重排序 当网络重新配置时,传输中的数据包可能属于多个时分网络 (TDN)。例如,数据包可能会穿越与其ACK不同的TDN,或者延迟的减少可能会重新排序数据包。TDTCN需要区分瞬态重新排序与真正的丢失,防止不必要的重新传输,提高传输效率。为了应对这一挑战,TDTCP跟踪与每个TDN关联的序列空间,并使用启发式和选择性确认来避免TDN转换期间的严重性能损失。具体来说,TDTCP采用单个连接级序列号空间,而不是使用MPTCP的子流两级设计。使用这一设计有三个原因。首先是为了避免TDN切换后流量控制停止;其次是为了消除子流之间协调的需要,减少不必要的性能开销;与此同时,该设计可以减少接受端的额外大量处理。 在TCP采用单个连续级序列号空间的基础上,让我们看一下作者如何解决包重排序问题。 传统的TDP Reno快速重传启发式算法RDCN网络。具体来说,在RDCN网络中,大多数重新排序是跨TDN重新排序,数据包以及相应的ACK会以不同的延迟遍历TDN,跨TDN重新排序不会表示丢失;由于增加的路径延迟,ACK被简单地延迟,如果TDTCP遵循TCP Reno快速重传启发式算法,它将在每次TDN转换时虚假地重传大量数据包。 为了避免频繁的虚假重传,TDTCP在per-TDN状态和SACK支持的帮助下放松了三重dupACK启发式。下图说明了TDTCP的宽松重排序检测启发式算法。当通过 TDN 1 发送的(粉红色)段在来自 TDN 0 的未完成(蓝色)段之前得到确认时,SACK 标记成功确认的段并调用快速恢复。snduna 指针和最高 SACKed 序列号(虚线矩形)之间的所有段都可能丢失,并且可能需要重新传输。但是,TDTCP 会检查这些数据包的相关 TDN ID,并将它们与 TDN 更改指针进行比较。来自 TDN 0 的(蓝色虚线)段被忽略,因为它们属于不同的 TDN,并且它们的 ACK 很可能只是延迟了。只有属于 TDN 1 的一个(粉红色虚线)段被确认为真正的丢失,将被重传。TDN 0 保持打开状态,允许继续全速发送;另一方面,TDN 1 由于丢失而进入恢复状态。 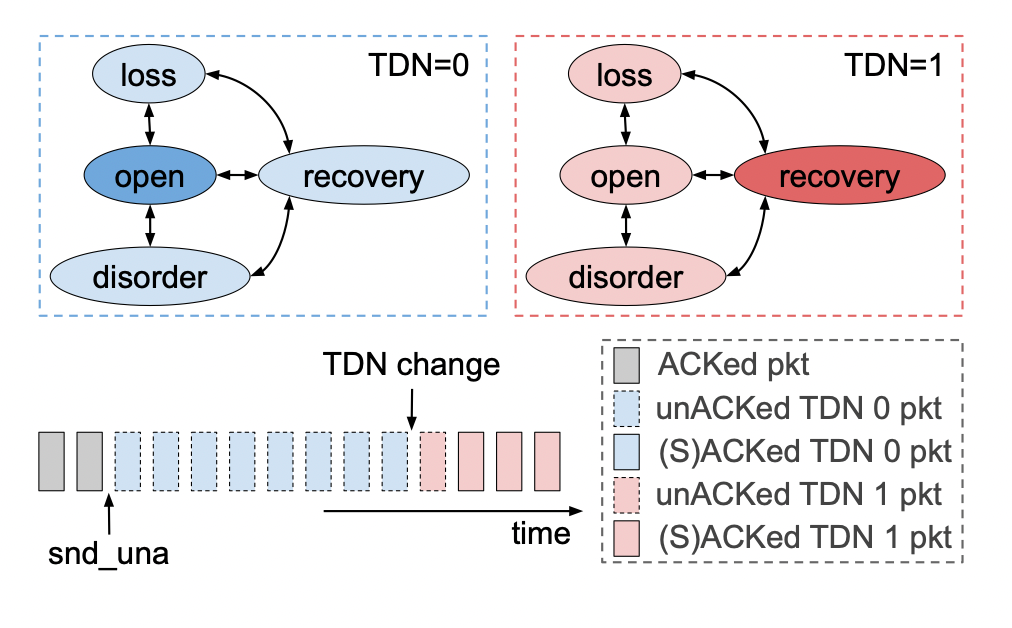 (3)实现与限制 在现代操作系统内核中实现TDTCP具有挑战性,因为拥塞控制状态紧密集成到网络堆栈中。论文研究者确定了必须跨TDN复制的CUBIC拥塞控制状态子集,并优化了TDN切换过程,以确保及时通知终端主机网络转换。TDCN的主要限制是它的运行机制。TDTCP仅在网络条件以一定的频率变化时才有用。TDTCP最适合在TDN变化周期在1-100x路径RTT的网络中运行。
(3)实现与限制 在现代操作系统内核中实现TDTCP具有挑战性,因为拥塞控制状态紧密集成到网络堆栈中。论文研究者确定了必须跨TDN复制的CUBIC拥塞控制状态子集,并优化了TDN切换过程,以确保及时通知终端主机网络转换。TDCN的主要限制是它的运行机制。TDTCP仅在网络条件以一定的频率变化时才有用。TDTCP最适合在TDN变化周期在1-100x路径RTT的网络中运行。
实验评估
作者针对内核中现有的TCP 变体以及 MPTCP 和 reTCP评估 TDTCP 的性能。实验结果表明,长寿命流在 TDTCP 下实现了更好的吞吐量:在一种代表性的 RDCN 设置中比单路径 CUBIC 和 DCTCP 高 24%,比 MPTCP 高 41%。此外,TDTCP 与 reTCP 的吞吐量性能相匹配,同时表现出较低的交换机缓冲区占用率,并且不依赖于主动交换机缓冲区管理。
总结
TDTCP 是一种新的 TCP 变体,旨在有效利用最新 RDCN 提供的额外容量。TDTCP 使用 TCP 状态变量的独立副本监控不同时分网络的路径特征,利用交换机生成的路径更改通知快速收敛到最佳拥塞状态,并放宽 TCP 的快速恢复启发式算法以避免在网络条件下出现虚假重传改变。作者在 Linux 内核 5.8 中实现了 TDTCP,并在小规模(模拟)RDCN 测试平台上评估了它的性能。结果表明,对于长寿命流,TDTCP 显著降低了网络中的队列占用率,并且优于传统的单路径 TCP 变体,例如 CUBIC 和 DCTCP。TDTCP 可与 reTCP 竞争,但不需要交换机像 reTCP 那样动态调整缓冲区大小。
个人观点
个人认为,本论文比较有意思的点是“packet reordering”部分的描写。首先举例说明为什么传统的快速重传算法不适用于TDTCP,然后在快速重传算法的基础之上,设计了宽松的检测启发式算法,并且举了个例子说明算法是如何运行的。这一部分从描写叙述到举例说明再到算法的设计都是比较精彩的。
背景与问题
网络设备配备了一个缓冲区,以避免在瞬时拥塞期间下降,并吸收突发流量。为了降低成本和最大化利用率,on-chip缓冲区在其队列之间被共享。这种共享自然会导致各种问题。具体地说,一个队列的过度增长可能会损害另一个队列的性能,这可能会缺乏、剥夺吞吐量等。更糟糕的是,这种有害的干扰可能发生在看似独立的队列之间,例如,映射到不同端口的队列或由独立的应用程序形成的队列。 网络设备通常采用分层的分组接纳控制来协调共享空间的使用。首先,缓冲区管理(BM)算法动态分割缓冲区空间。第二,主动队列管理(AQM)算法通过选择性地允许传入的数据包来管理BM分配给每个单独队列的缓冲区片。BM旨在通过管理设备级别上的缓冲区的空间分配来实现跨队列的隔离。直观地说,BM的目标是避免长时间的队列饥饿,有效地在稳定状态下加强公平。相反,AQM的目标是通过管理队列级别上的缓冲区的时间分配来保持稳定的排队延迟。直观地说,AQM通过避免数据包在缓冲区中停留“太久”的来防止缓冲区膨胀。 虽然BM和AQM在过去是合理和成功的,因为它允许BM和AQM方案进一步发展,但最近的两个数据中心趋势使它们之间的协调变得紧迫。首先,缓冲区的大小没有跟上交换机容量的增加。实际上,BM不再有足够的可用缓冲区来为每个队列提供隔离。其次,随着流量变得更加突发的场景更加普遍,缓冲区的瞬态需要控制在设备级。为了跟上这些趋势,缓冲区共享方案需要提供隔离、有界排空时间和高突发容差。但是今天的BM和AQM方案根本不能独立地满足这些要求。在这一见解的驱动下,作者提出了ABM,一种主动缓冲区管理算法,它结合了来自BM和AQM的见解,以在不牺牲吞吐量的情况下实现高突发流量吸收。 本文的做法旨在建模,综合考虑了多种因素来为每个队列分配一定长度的缓冲区空间和时间方面的问题。
动机
优秀的缓冲区管理方案属性: 为了最大限度地提高共享缓冲区的利用率,缓冲区共享方案需要满足三个关键属性:(1) isolation; (2) bounded drain time; and (3) predictable burst tolerance。 (1)Isolation 由于缓冲区是跨多个队列共享的,因此一小组队列过度使用缓冲区可能会干扰交换机中的其他队列使用共享缓冲区的能力。如果相互竞争的队列属于不同的流量优先级,那么这种干扰可能特别有害。我们要求每个优先级必须在任何给定时间占用可配置的最小缓冲区数量,独立于缓冲区状态。形式上,让Tp(t)表示在任何时间t中所有优先级P的集合中分配给优先级p(P中元素)的总缓冲区。然后,Bp(min)必须始终大于可配置的静态值。但是,由于总缓冲空间有限,所以总分配必须在总缓冲区内。因此,每个优先级也必须是其分配的上限Bp(max),以防止独占缓冲区。
(2)Bounded drain time 缓冲区有限的排空时间减少了缓冲区内的数据包(或流量)的排队延迟。为了避免高排队延迟的有害后果,缓冲区共享方案需要绑定每个队列的排空时间。具体地说,缓冲区共享方案需要通过一个可配置的静态值q(t)来绑定具有服务速率u(t)的队列中被占用的缓冲区A。实际上下面的条件总结了缓冲区膨胀问题:所需的属性是为了避免数据包在缓冲区中停留“太长时间”。
Bounded drain time: q(t)/u(t)<=A
(3)Predictable burst tolerance 如果预留大量的缓存空间以应对突发的数据包或者等突发数据包到来时直接占用现有的缓存区,虽然足以应对突发事件,但这可能会产生不利影响。一方面,始终保持突发大小的空缓冲区数量会剥夺队列中宝贵的缓冲区,从而导致潜在的吞吐量损失。另一方面,将所有新释放的缓冲区(从引流队列)分配给传入突发将耗尽引流队列(删除每个传入数据包)。总之,提供可预测的突发容忍性避免缓冲浪费,缓冲共享方案需要结合考虑隔离和限制排空时间。 最先进方法动态阈值存在的不足: 典型的设备使用分层的数据包进入控制方案:首先,一个缓冲区管理(BM)方案决定在设备级别上每个队列的最大长度,然后一个活动队列管理(AQM)方案决定哪些数据包缓冲在队列中。不幸的是,两种控制方案之间缺乏合作导致(i)由于缺乏隔离而造成的跨队列的有害干扰;(ii)由于忽略了每个排队的排空时间,增加了排队延迟;(iii)不可预测的突发流量的容忍性。当今数据中心交换机中使用的最先进的缓冲区管理算法动态阈值(DT)根本无法实现上面描述的理想属性,而且也具备上述缺陷。
设计
ABM同时满足了隔离、排空时间和可预测的突发流量的容忍三个属性。在论文附录A有完整的证明。 ABM算法: ABM为每个队列分配阈值,同时考虑空间的、缓冲区范围的和时间范围的、每个队列的统计信息。Tpi(t):在端口上的优先级为p的队列i的阈值。
Tpi(t)=a(p) x 1/n(p) x (B-Q(t)) x U(pi)/b
a(p)是操作员需要在ABM中配置的唯一参数。其值越高,平均分配值就越高。它定义了每个优先级可用的最小和最大缓冲区。 n(p)表示优先级p的拥塞队列数。如果队列长度接近相应的阈值,则ABM考虑队列拥塞。在本文的评估中,如果一个队列的长度大于或等于其阈值的0.9,我们就认为它是拥塞的。 U(pi)/b表示标准化排空率,其中U(pi)为队列的排空率,b为每个端口的带宽。 (B-Q(t))表示剩余的缓冲区空间。
BM: a(p) x 1/n(p) x (B-Q(t)) AQM:U(pi)/b
ABM具备实践性:
(1)ABM使用了当今交换机可用的统计数据。 (2)ABM讲述了关于如何配置α的基本经验。 (3)DT已经部署于数据中心,而ABM可在DT之上近似地使用。
性能评估
本文的评估是基于网络模拟器NS3,将ABM与数据中心设置中的最先进的方法DT动态阈值进行了比较。作者做了大规模模拟结果表明,与现有的BM和AQM方案相比,ABM将短流量的流量完成时间提高了高达94。此外,ABM不仅兼容先进的拥塞控制算法(如及时、DCTCP和PowerTCP),而且在繁重的工作负载下,它们的尾部fct的性能提高了高达76。最后,作者证明了与传统的缓冲区管理方案不同,ABM在不同大小的缓冲区大小上工作良好,包括浅缓冲区。
总结
问题场景: 今天的网络设备跨队列共享缓冲区,以避免在瞬时拥塞期间下降,并吸收突发。随着数据中心中缓冲区带宽单元的减少,对最佳缓冲区利用率的需求变得更加迫切。 ABM核心观点: 它结合了来自BM和AQM的见解。具体地说,ABM利用了设备级别的总缓冲区占用率和单个队列的占用时间。本质上,ABM是缓冲区的空间(BM使用)和时间(AQM使用)特征的函数。ABM同时考虑了总缓冲区占用率(通常由BM使用)和队列排空时间(通常由AQM使用)。 性能结果: 作者分析证明了ABM提供隔离、有界缓冲排空时间,并在不牺牲吞吐量的情况下实现可预测的突发流量吸收。
个人观点
研究依据明确和方法创新 论文作者观察到当今数据中心的网络带宽与内存buffer问题,并且关注了现代数据中心的流量特征,例如突发流量。以此展开研究动态阈值方法的限制性,再通过数学建模提出自己的创新方法。这种研究路线在许多数据中心相关研究中大多有所体现。首次把缓存和活动队列统一于一个建模公式中,一个框架内,提出新方法。 ABM的实践性理由不能令人信服 文中提及了它具备实践性的理由,首先,模拟和使用特定的数据不会具备普适性。而且,在测试的情况下,本文所提议的解决方案也没有使用当前的硬件进行部署,例如FPGA实现或ASIC。尽管ABM可以近似实现动态阈值的方法,但是没有实际部署,没有使用现在的硬件,那成本便难以确定。
背景
过去十年,数据中心网络的传输层设计有两个目标:短流低延迟,长流高吞吐量。这方面的进展有:DCTCP、D3、PDQ、D2TCP、HULL、Timely、pHost、NDP、Homa、HPCC、Swift等,这些方法解决了短流接近最优的延迟。但是,如何同时实现短流的低延迟和长流的高网络利用率,这个问题仍然十分挑战,这主要由于:1. 长流可能和短流竞争;2. 长流可能和网络中的其他长流竞争;3. 长流可能和主机中其他长流竞争。
设计
作者观察到现代数据中心和switch fabrics在拓扑、工作负载上的相似性,提出应用交换机上的PIM算法到数据中心,叫做dcPIM。dcPIM是一种基于匹配的设计,即每个发送端和唯一一个接收端配对。PIM用多轮控制信息来计算免冲突的输入端口和输出端口之间的配对,每一轮都包括三个阶段:request stage,grant stage和accept stage。在每一轮开始,每个没有匹配的输入端口给其有输出数据的端口发动一个request(request stage);然后,每个没有匹配的输出端口从接收到的request中随机选择一个,发送grant信息(grant stage);最后,没有匹配的输入端口从接收到的grants中随机选择一个,发送accept信息,接收到accept信息的输出端口和相应的输入端口实现了配对。直接应用PIM到数据中心有3个挑战:高延迟、低带宽利用率和异常处理机制。 dcPIM和PIM类似,包括两个阶段:匹配阶段和数据传输阶段。为了克服上面的3个挑战,dcPIM实现了4个关键的设计:
理论分析结果表明,dcPIM可以用更少的匹配轮数实现接近最优的网络利用;
为了处理over subscription和failure,dcPIM使用接收端驱动的单包admission control机制;
为了处理数据中心的匹配阶段的高延迟,dcPIM流水化处理匹配和数据传输阶段;
流水化匹配和数据传输后,为了保证两个阶段的时间匹配,dcPIM扩展PIM的算法:为每一个发送端匹配多个接收端,也为每个接收端匹配了多个发送端。
实验评估
作者在pHost上实现了dcPIM。使用了3种拓扑:leaf-spine,fattree,和oversubscibed。3种工作负载:IMC10,Web Search和Data Mining。3种traffic patterns:all-to-all,bursty,dense traffic matrix。评估的协议有:Homa Aeolus,NDP,HPCC。评估的metrics:slowdown,utilization。链路属性:end-hosts使用100Gbps,leaf-spine的交换机间使用400Gbps,FatTree的交换机间使用100Gbps。交换机属性:每个端口buffer是500KB,交换机buffer是16MB,450ns处理延迟和包传播。 结论如下:
dcPIM实现了接近最优的尾延迟和网络利用率;
基于匹配的设计使dcPIM快速收敛到高网络利用率;
dcPIM可以实现比理论bound更有的网络利用率。
总结
从pHost,NDP和Homa的设计出发,dcPIM提取了connection-less design, per-packet load balancing,packet priorition和fast loss recovery。为短流实现了接近最优的延迟。从现代数据中心和交换机fabrics的相似性出发,dcPIM处理了包括适配数据中心大规模拓扑,隐藏数据中心RTT,扩大到100Gbps规模,处理网络内拥塞,从而实现了数据中心的吞吐量最优的调度机制。
个人观点
本文改进了PIM,提升了数据中心短流低延迟,长流高利用率。个人第一次接触PIM方法,对把PIM应用到数据中心吞吐量调度方法感到有趣。
Jupiter evolving: transforming google's datacenter network via optical circuit switches and software-defined networking
Leon Poutievski, Omid Mashayekhi, Joon Ong, Arjun Singh, Mukarram Tariq, Rui Wang, Jianan Zhang, Virginia Beauregard, Patrick Conner, Steve Gribble, Rishi Kapoor, Stephen Kratzer, Nanfang Li, Hong Liu, Karthik Nagaraj, Jason Ornstein, Samir Sawhney, Ryohei Urata, Lorenzo Vicisano, Kevin Yasumura, Shidong Zhang, Junlan Zhou, Amin Vahdat
本论文由Google团队完成,主要回顾了Google数据中心网络Jupiter近十年的发展历程。
背景
虽然使用商用芯片构建的软件定义网络和Clos拓扑使得建筑规模数据中心网络成为云基础设施的基础,并且在其他方面也影响巨大,但是很少有人关注如何管理建筑性规模网络的异构性和增量演进。云基础设施以增量方式增长,每次增加一个机架或者一个服务器,填满一座空置的建筑物通常需要几个月到几年的时间。建筑物装满之后,就会对建筑物立面的基础设施进行更新,通常每次使用最新一代的服务器硬件更新一个机架。指数级增长和不断变化的业务需求的现实意味着最好的放置计划很快就会变得不高效甚至过时,这使得增量和自适应进化成为必要。 对于计算和存储基础设施的增量更新相对简单——每次使用新一代硬件更新一个机架上的基础设施。网络基础设施的增量更新相对更难,需要预先为整个Clos结构的网络构建主干层,这样会将数据中心的带宽限制为在主干部署时可用的网络带宽。如下图所示,一个通用的3层Clos架构包括带有ToR交换机的机架、连接机架的聚合块以及连接聚合块的主干块。 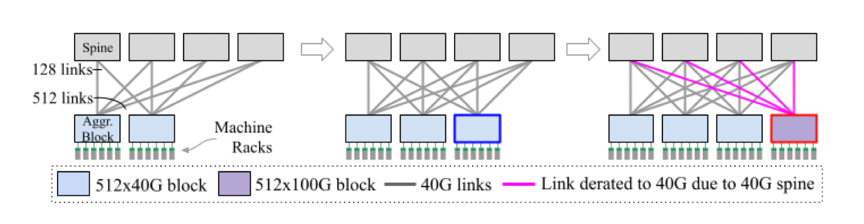 举个例子,使用40Gbps技术,每个主干块可以支持512x40Gbps=20Tbps的突发带宽。随着下一代100Gbps的推出,更新的聚合块可以支持512x100Gbps=51.2Tbps的突发带宽,但是由于先前主干块的40Gbps的带宽限制,每个聚合块的突发带宽仍为20Tbps。网络带宽的不足会使得服务和存储容量降低。如果要增加网络中心的带宽,需要更新整个建筑规模的主干,这也是不可取的,因为代价昂贵、耗时、需要重新布线。 为了应对这一问题,论文提出了一种新的端到端设计。
举个例子,使用40Gbps技术,每个主干块可以支持512x40Gbps=20Tbps的突发带宽。随着下一代100Gbps的推出,更新的聚合块可以支持512x100Gbps=51.2Tbps的突发带宽,但是由于先前主干块的40Gbps的带宽限制,每个聚合块的突发带宽仍为20Tbps。网络带宽的不足会使得服务和存储容量降低。如果要增加网络中心的带宽,需要更新整个建筑规模的主干,这也是不可取的,因为代价昂贵、耗时、需要重新布线。 为了应对这一问题,论文提出了一种新的端到端设计。
设计
本论文利用optical circuit switch将Jupiter从Clos架构迁移到块级直连结构,从而消除了主干交换层及其相关挑战。这使得Juptiter能够整合40Gbps、100Gbps及更高的网络带宽速度。除此之外,本论文将直连架构与网络管理、流量和拓扑工程技术相结合,使得Juptiter能够应对流量的不确定性、大量的结构异构性,并且可以在不需要任何停机或服务消耗的情况下进行演进更新。具体来说,Jupiter数据中心互连层采用基于微机电系统 (MEMS) 的光电路开关 (OCS) 来实现:
动态拓扑重新配置;
用于流量工程的集中式软件定义网络 (SDN) 控制;
用于增量容量交付和拓扑工程的自动化网络操作。
性能评估
与静态的Clos结构相比,本论文的设计在速度、容量和额外的灵活性方面提高了5倍,并且降低了30%的成本以及41%的功耗。
总结
本文回顾了 Google 数据中心网络 Jupiter 近十年的发展历程。这一旅程的核心是基于 MEMS 的光电路交换机、软件定义网络和自动安全操作作为关键的支持技术。借助这些底层技术,Jupiter 转变为可增量部署的结构,其中异构网络块共存并以模块化方式更新。 Jupiter 从一个标准的 Clos 拓扑开始,它为任意可接受的流量模式提供最佳吞吐量。为了利用生产网络中的闲置的容量并解决 Clos 结构中的主干块的技术更新挑战,作者将 Jupiter 演变为直接连接拓扑,并为观察到的块级流量模式启用动态流量和拓扑工程。与传统的 Clos 方法相比,这样做可以实现相当的吞吐量和更短的平均路径,此外还可以节省大量的资本支出和运营支出。



















 工商网监
工商网监
评论