 电子发烧友App
电子发烧友App


经过了多年的努力,在 6 月 6 号,IETF (互联网工程任务小组) 正式发布了 HTTP/3 的 RFC, 这是超文本传输协议(HTTP)的第三个主要版本,完整的 RFC 超过了 20000 字,非常详细的解释了 HTTP/3。
HTTP 历史
1991 HTTP/1.1
2009 Google 设计了基于TCP的SPDY
2013 QUIC
2015 HTTP/2
2018 HTTP/3
HTTP3是在保持QUIC稳定性的同事使用UDP来实现高速度, 同时又不会牺牲TLS的安全性.
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
QUIC 协议概览
QUIC(Quick UDP Internet Connections, 快速UDP网络连接)是基于UDP的协议, 利用了UDP的速度和效率, 同时整合TCP, TLS和HTTP/2的优点并加以优化. 用一张图可以清晰的表示他们之间的关系.
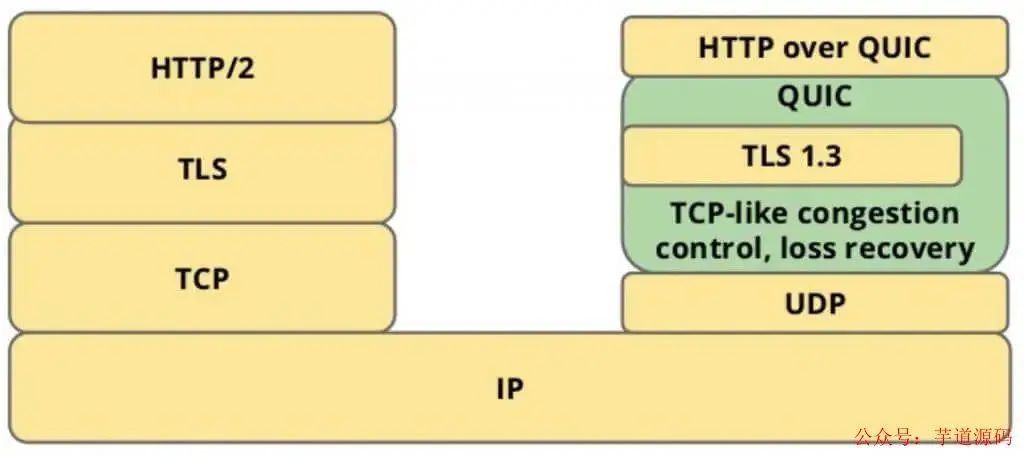
QUIC是用来替代TCP, SSL/TLS的传输层协议, 在传输层之上还有应用层. 我们熟知的应用层协议有HTTP, FTP, IMAP等, 这些协议理论上都可以运行在QUIC上, 其中运行在QUIC之上的协议被称为HTTP/3, 这就是HTTP over QUIC即HTTP/3的含义
因此想要了解HTTP/3, QUIC是绕不过去的, 下面是几个重要的QUIC特性.
RTT建立连接
RTT: round-trip time, 仅包括请求访问来回的时间
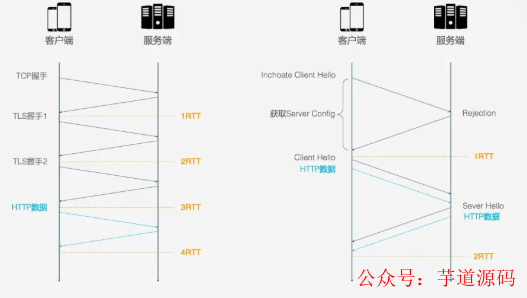
HTTP/2的连接建立需要3 RTT, 如果考虑会话复用, 即把第一次握手计算出来的对称密钥缓存起来, 那也需要2 RTT. 更进一步的, 如果TLS升级到1.3, 那么HTTP/2连接需要2RTT, 考虑会话复用需要1RTT. 如果HTTP/2不急于HTTPS, 则可以简化, 但实际上几乎所有浏览器的设计都要求HTTP/2需要基于HTTPS.
HTTP/3首次连接只需要1RTT, 后面的链接只需要0RTT, 意味着客户端发送给服务端的第一个包就带有请求数据, 其主要连接过程如下:
首次连接, 客户端发送Inchoate Client Hello, 用于请求连接;
服务端生成g, p, a, 根据g, p, a算出A, 然后将g, p, A放到Server Config中在发送Rejection消息给客户端.
客户端接收到g,p,A后, 自己再生成b, 根据g,p,a算出B, 根据A,p,b算出初始密钥K, B和K算好后, 客户端会用K加密HTTP数据, 连同B一起发送给服务端.
服务端接收到B后, 根据a,p,B生成与客户端同样的密钥, 再用这密钥解密收到的HTTP数据. 为了进一步的安全(前向安全性), 服务端会更新自己的随机数a和公钥, 在生成新的密钥S, 然后把公钥通过Server Hello发送给客户端. 连同Server Hello消息, 还有HTTP返回数据.
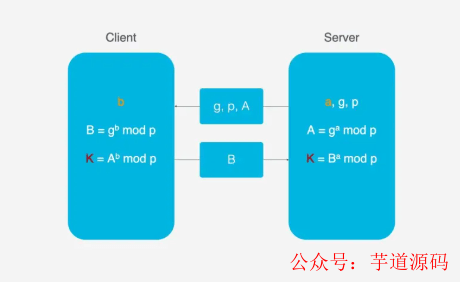
这里使用DH密钥交换算法, DH算法的核心就是服务端生成a,g,p3个随机数, a自己持有, g和p要传输给客户端, 而客户端会生成b这1个随机数, 通过DH算法客户端和服务端可以算出同样的密钥. 在这过程中a和b并不参与网络传输, 安全性大大提升. 因为p和g是大数, 所以即使在网络传输中p, g, A, B都被劫持, 靠现在的计算力算力也无法破解.
连接迁移
TCP连接基于四元组(源IP, 源端口, 目的IP, 目的端口), 切换网络时至少会有一个因素发生变化, 导致连接发送变化. 当连接发送变化是, 如果还是用原来的TCP连接, 则会导致连接失败, 就得等到原来的连接超时后重新建立连接, 所以我们有时候发现切换到一个新的网络时, 即使网络状况良好, 但是内容还是需要加载很久. 如果实现的好, 当检测到网络变化时, 立即建立新的TCP连接, 即使这样, 建立新的连接还是需要几百毫秒时间.
QUIC不受四元组的影响, 当这四个元素发生变化时, 原连接依然维持. 原理如下:
QUIC不以四元素作为表示, 而是使用一个64位的随机数, 这个随机数被称为Connection ID, 即使IP或者端口发生变化, 只要Connection ID没有变化, 那么连接依然可以维持.
队头阻塞/多路复用
HTTP/1.1和HTTP/2都存在队头阻塞的问题(Head Of Line blocking).
TCP是个面向连接的协议, 即发送请求后需要收到ACK消息, 以确认对象已接受数据. 如果每次请求都要在收到上次请求的ACK消息后再请求, 那么效率无疑很低. 后来HTTP/1.1提出了Pipeline技术, 允许一个TCP连接同时发送多个请求. 这样就提升了传输效率.
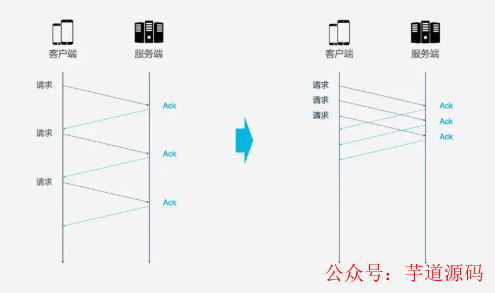
在这样的背景下, 队头阻塞发生了. 比如, 一个TCP连接同时传输10个请求, 其中1,2,3个请求给客户端接收, 但是第四个请求丢失, 那么后面第5-10个请求都被阻塞. 需要等第四个请求处理完毕后才能被处理. 这样就浪费了带宽资源.
因此, HTTP一般又允许每个主机建立6个TCP连接, 这样可以更加充分的利用带宽资源, 但每个连接中队头阻塞的问题还是存在的.
HTTP/2的多路复用解决了上述的队头阻塞问题. 在HTTP/2中, 每个请求都被拆分为多个Frame通过一条TCP连接同时被传输, 这样即使一个请求被阻塞, 也不会影响其他的请求.
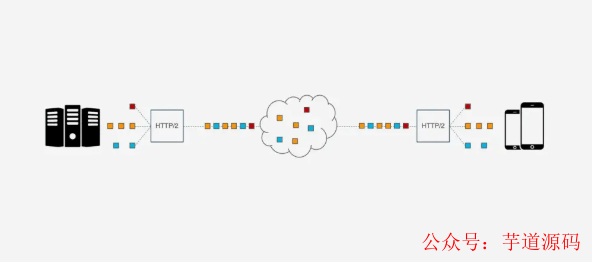
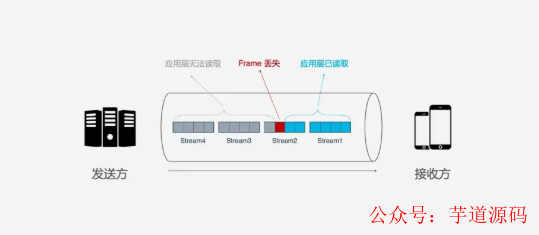
但是, HTTP/2虽然可以解决请求这一粒度下的阻塞, 但HTTP/2的基础TCP协议本身却也存在队头阻塞的问题. HTTP/2的每个请求都会被拆分成多个Frame, 不同请求的Frame组合成Stream, Stream是TCP上的逻辑传输单元, 这样HTTP/2就达到了一条连接同时发送多个请求的目标, 其中Stram1已经正确送达, Stram2中的第三个Frame丢失, TCP处理数据是有严格的前后顺序, 先发送的Frame要先被处理, 这样就会要求发送方重新发送第三个Frame, Steam3和Steam4虽然已到达但却不能被处理, 那么这时整条链路都会被阻塞.
不仅如此, 由于HTTP/2必须使用HTTPS, 而HTTPS使用TLS协议也存在队头阻塞问题. TLS基于Record组织数据, 将一对数据放在一起加密, 加密完成后又拆分成多个TCP包传输. 一般每个Record 16K, 包含12个TCP包, 这样如果12个TCP包中有任何一个包丢失, 那么整个Record都无法解密.
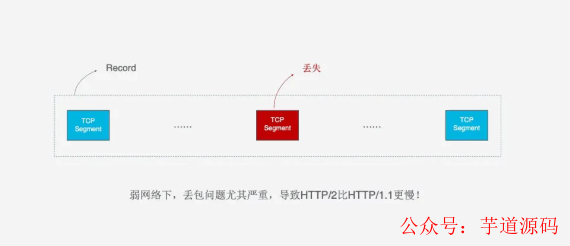
队头阻塞会导致HTTP/2在更容易丢包的弱网络环境下比HTTP/1.1更慢.
QUIC是如何解决队头阻塞的问题的? 主要有两点:
QUIC的传输单位是Packet, 加密单元也是Packet, 整个加密, 传输, 解密都基于Packet, 这就能避免TLS的阻塞问题.
QUIC基于UDP, UDP的数据包在接收端没有处理顺序, 即使中间丢失一个包, 也不会阻塞整条连接. 其他的资源会被正常处理.
拥塞控制
拥塞控制的目的是避免过多的数据一下子涌入网络, 导致网络超出最大负荷. QUIC的拥塞控制与TCP类似, 并在此基础上做了改进. 先来看看TCP的拥塞控制.
慢启动: 发送方像接收方发送一个单位的数据, 收到确认后发送2个单位, 然后是4个, 8个依次指数增长, 这个过程中不断试探网络的拥塞程度.
避免拥塞: 指数增长到某个限制之后, 指数增长变为线性增长
快速重传: 发送方每一次发送都会设置一个超时计时器, 超时后认为丢失, 需要重发
快速恢复: 在上面快速重传的基础上, 发送方重新发送数据时, 也会启动一个超时定时器, 如果收到确认消息则进入拥塞避免阶段, 如果仍然超时, 则回到慢启动阶段.
QUIC重新实现了TCP协议中的Cubic算法进行拥塞控制, 下面是QUIC改进的拥塞控制的特性:
1. 热插拔
TCP中如果要修改拥塞控制策略, 需要在系统层面今次那个操作, QUIC修改拥塞控制策略只需要在应用层操作, 并且QUIC会根据不同的网络环境, 用户来动态选择拥塞控制算法.
2. 前向纠错 FEC
QUIC使用前向纠错(FEC, Forword Error Correction)技术增加协议的容错性. 一段数据被切分为10个包后, 一次对每个包进行异或运算, 运算结果会作为FEC包与数据包一起被传输, 如果传输过程中有一个数据包丢失, 那么就可以根据剩余9个包以及FEC包推算出丢失的那个包的数据, 这样就大大增加了协议的容错性.
这是符合现阶段网络传输技术的一种方案, 现阶段带宽已经不是网络传输的瓶颈, 往返时间才是, 所以新的网络传输协议可以适当增加数据冗余, 减少重传操作.
3. 单调递增的Packer Number
TCP为了保证可靠性, 使用Sequence Number和ACK来确认消息是否有序到达, 但这样的设计存在缺陷.
超时发生后客户端发起重传, 后来接受到了ACK确认消息, 但因为原始请求和重传请求接受到的ACK消息一样, 所以客户端就不知道这个ACK对应的是原始请求还是重传请求. 这就会造成歧义.
RTT: Round Trip Time, 往返事件
RTO: Retransmission Timeout, 超时重传时间
如果客户端认为是重传的ACK, 但实际上是右图的情形, 会导致RTT偏小, 反之会导致RTT偏大.
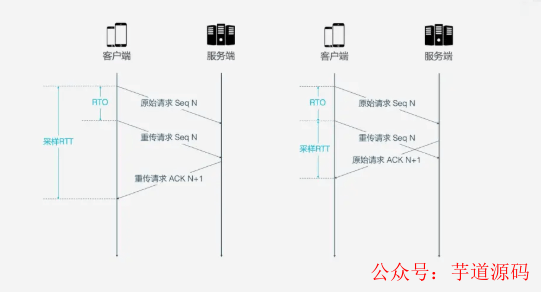
QUCI解决了上面的的歧义问题, 与Sequence Number不同, Packet Number严格单调递增, 如果Packet N丢失了, 那么重传时Packet的标识就不会是N, 而是比N大的数字, 比如N+M, 这样发送方接收到确认消息时, 就能方便的知道ACK对应的原始请求还是重传请求.
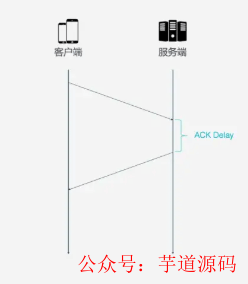
4. ACK Delay
TCP计算RTT时没有考虑接收方接受到数据发发送方确认消息之间的延迟, 如下图所示, 这段延迟即ACK Delay. QUIC考虑了这段延迟, 使得RTT的计算更加准确.
5. 更多的ACK块
一般来说, 接收方收到发送方的消息后都应该发送一个ACK恢复, 表示收到了数据. 但每收到一个数据就返回一个ACK恢复实在太麻烦, 所以一般不会立即回复, 而是接受到多个数据后再回复, TCP SACK最多提供3个ACK block. 但在有些场景下, 比如下载, 只需要服务器返回数据就好, 但按照TCP的设计, 每收到三个数据包就要返回一个ACK, 而QUIC最多可以捎带256个ACK block, 在丢包率比较严重的网络下, 更多的ACK可以减少重传量, 提升网络效率.
浏览控制
TCP会对每个TCP连接进行流量控制, 流量控制的意思是让发送方不要发送太快, 要让接收方来得及接受, 不然会导致数据溢出而丢失, TCP的流量控制主要通过滑动窗口来实现的. 可以看到, 拥塞控制主要是控制发送方的发送策略, 但没有考虑接收方的接收能力, 流量控制是对部分能力的不起.
QUIC只需要建立一条连接, 在这条连接上同时传输多条Stream, 好比有一条道路, 量都分别有一个仓库, 道路中有很多车辆运送物资. QUIC的流量控制有两个级别: 连接级别(Connection Level)和Stream 级别(Stream Level).
对于单条的Stream的流量控制: Stream还没传输数据时, 接收窗口(flow control recevice window)就是最大接收窗口, 随着接收方接收到数据后, 接收窗口不断缩小. 在接收到的数据中, 有的数据已被处理, 而有的数据还没来得及处理. 如下图, 蓝色块表示已处理数据, 黄色块表示违背处理数据, 这部分数据的到来, 使得Stream的接收窗口缩小.
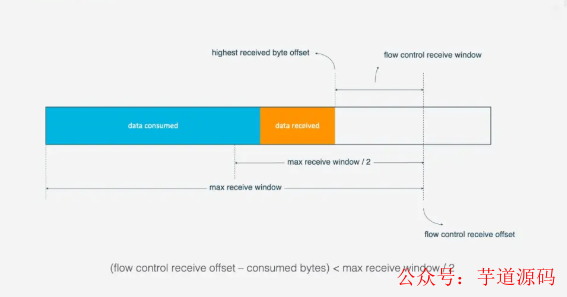
随着数据不断被处理, 接收方就有能力处理更多数据. 当满足(flow control receivce offset - consumed bytes) < (max receive window/2)时, 接收方会发送WINDOW_UPDATE frame告诉发送方你可以再多发送数据, 这时候flow control receive offset就会偏移, 接收窗口增大, 发送方可以发送更多数据到接收方.
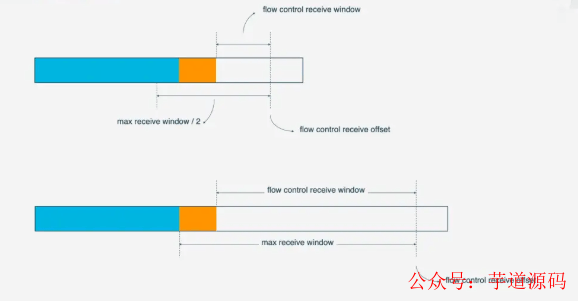
Stream级别对防止接收端接收过多数据作用有限, 更需要借助Connection级别的流量控制. 理解了Stream流量那么也很好理解Connection的流控. Stream中,
接收窗口=最大接受窗口 - 已接收数据
而对于Connection来说:
接收窗口 = Stream1 接收窗口 + Stream2 接收窗口 + ... + StreamN 接收窗口
编辑:黄飞













 工商网监
工商网监
评论