 电子发烧友App
电子发烧友App



摘要:64B/66B编码技术是IEEE 802.3工作组为10G以太网提出的,目的是减少编码开销,降低硬件的复杂性,并作为8B/10B编码的另一种选择,以支持新的程序和数据。在本篇文章中,我将从它的提出背景、编码格式、编码原理、和8B/10B比较它的优缺点等方面和大家分享一下,在学习过程中有关64B/66B编码的心得笔记。
关键字:8B/10B,64B/66B,编码,扰码
1、 引言
① 经过之前的学习,我们知道,8b/10b编码最初由IBM公司于1983年发明,并应用于ESCON(200M互连系统)的一种编码方式。8B/10B编码不只应用于光纤通道,目前在许多高速串行总线。
我们知道的8b/10b编码的特性之一是保证DC 平衡。
采用8b/10b编码方式,可使得发送的“0”、“1”数量保持基本一致,连续的“1”或“0”不超过5位,即每5个连续的“1”或“0”后必须插入一位“0”或“1”,从而保证信号DC平衡,也就是说,在链路超时时不致发生DC失调。
通过8b/10b编码,可以保证传输的数据串在接收端能够被正确复原,除此之外,利用一些特殊的代码( 在PCI-Express总线中为K码) ,可以帮助接收端进行还原的工作,并且可以在早期发现数据位的传输错误,抑制错误继续发生。
然而,将原本8位的字节用10位来表示,会使8B/10B编码的开销太大,带宽利用率并不高。
于是,就有了一系列的优化编码方式,其中64B/66B就是其中的一种。
② 64B/66B编码技术是IEEE802.3工作组为10G以太网提出的,目的是减少编码开销,降低硬件的复杂性,并作为8B/10B编码的另一种选择,以支持新的程序和数据。它并不是真正的编码,而是一种基于扰码机制编解码方式,这种编码方式,是IEEE推荐的10G通信的标准编码方式。
当前,64B/66B编码主要应用于FiberChannel 10GFC和16GFC、10G以太网、100G以太网、10G EPON、InfiniBand、Thunderbolt和Xilinx的Aurora协议。
2、 64B/66B编码技术
64B/66B编码将64bit“数据或控制信息”编码成66bit块来进行传输,这66bit中,前两位表示同步头(2bit Sync Header),主要用于接收端的数据对齐和接收数据位流的同步。

00 编码错误
01 64 bit = 纯数据
10 64 bit = 混合的数据/控制信息
11 编码错误
也就是说,在没有发生错误的情况下,每66位的数据,就会出现至少一个“01”或者“10”的转换。
同步头有“01”和“10”两种:
“01“表示后面的64bit都是数据。
“10”表示后面的64bit是数据和控制信息的混合,其中紧挨着同步头的8b是类型域,后面的56bit是控制信息或者数据或者两者的混合。
① 对于纯数据Pure data

同步头:01,后面的信息:8*8=64bit数据
② 对对于纯控制Pure Control (Type = 0x1E)

同步头:10,后面的信息:8bit类型表示+7*8控制信息
③ 对于数据和控制信息的混合
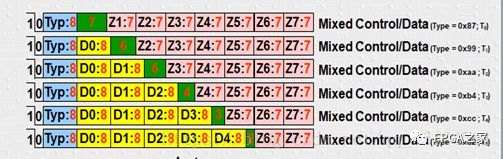
同步头:10,后面的信息:数据信息和控制信息的混合。
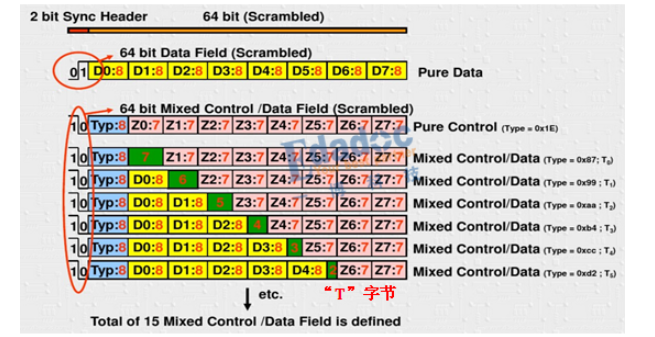
64B/66B编码格式图如下图所示:
其中,D表示数据编码,每个数据码8bit;Z表示控制码,每个控制码7bit;S表示包的开始,T表示包的结束。S只会出现在8字节中的第0和第4字节,T能够出现在任意的字节。
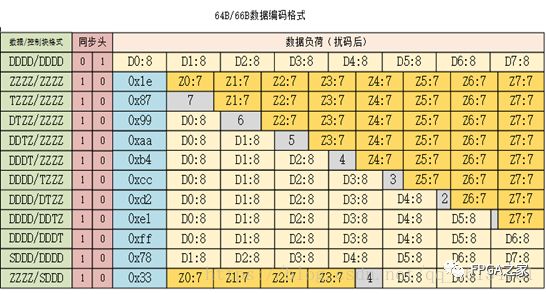
下面我们一起来看一个简单的例子,这个例子将帮助我们更好地理解数据帧和控制帧。
一个18 bytes的数据块的传输过程如下图所示:

这过程是怎么样的呢?我们一起来看一下,从图中我们可以直观的看到,在数据的传输过程中,我们需要用到两个控制帧,一个是开始部分的控制帧,用来告诉接收方这是某一个数据块的开始,还要有的是一个用来表示结束的控制帧,告诉接收方该数据块到此结束。
从图中我们可以知道,在开始和结束的控制帧之外,为纯数帧,一个纯数据帧,他能表示64bit的数据。不管是数据帧还是控制帧,每隔64bit,就会插入一个01或者10序列来分隔,我们还知道,他的DC平衡并不是由这两位01.10来完成的,相对于64bit这么大的数据块,10和01的平衡能力微乎其微,在学习的过程中,我们知道他用到的是扰码技术,这是我们下一个模块要讲述的内容。
3、 扰码传输技术
上面我们提到,除同步码外,64bit的数据必须经过扰码以后才能进行传输,在引言部分我们说过,64B/66B并不是真正的编码,而是一种基于扰码机制编解码方式。
我们知道8B/10B编码通过优化直流平衡,从8bit中插2个bit进去,这样能够使长0或者长1的位数不超过5位,达到很好的效果。那64B/66B编码方式呢?在从64个bit中仅加入2个bit,能够很好的解决长0长1的问题吗?作用似乎只是杯水车薪,2个bit相对于64个bit太少了。
当然,如果仅靠这2个bit来实现8B/10B的作用显然不太现实。其实上,这两个bit只是起一个同步头的作用,主要用于接收端的数据对齐和接收数据位流的同步。
那按照上面说的,新加的2个bit只是作为同步,那后面的数据可以如何优化呢?这里有一项区别于8B/10B编码的技术——扰码。
为此,我又去查资料看了一下,有关扰码的相关知识。
通过查资料我知道,扰一种将数据重新排列或者进行编码以使其最优化的方法,他的作用是对数字信号的比特级进行随机处理,减少连0和连1的出现,从而减少码间干扰和抖动,方便接收端的时钟提取;同时又扩展了基带信号频谱,起到加密的效果。
为了保证在任何情况下进入传输信道的数据码流中“0”与“1”的概率都能基本相等,传输系统会用一个伪随机序列对输入的传送码流进行扰乱处理,将二进制数字信息做“随机化”处理,变为伪随机序列,也能限制连“0”码或连“1”码的长度,这种“随机化”处理通常称为“扰码”。
扰乱虽然改变了原始传送码流,但这种扰乱是有规律的,因而也是可以解除的,在接收端解除这种扰乱的过程称为解扰。完成扰码和解扰的电路相应称为扰码器和解扰器。
64B/66B自同步扰码实现随机化,编码所使用的扰码器为: X58+X39+1
扰码的数学原理使用了多项式,多项式的选择通常是基于扰码的特性,包括生成数据的随机度,以及打乱连0和连1的能力。一个简单的扰码器包含一组排列好的触发器,用于移位数据流。大部分的触发器只需要简单地输出下一个比特流即可,但是在复杂的扰码电路中,触发器需要与数据流中的历史比特进行逻辑运算(与和或运算)。基本的扰码电路如下所示:
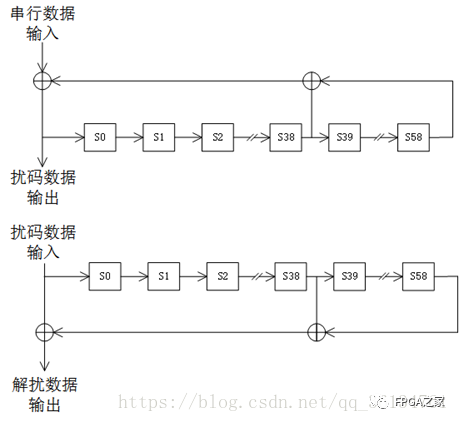
第39和第58位的异或运算,然后通过移位寄存器输出的码型结果。这是一个需要大量计算的过程,但对于我们的计算机来说,仅仅是异或和移位的操作是比较简单的,他可以很快就完成。
他的计算原理,我们通过一个简单的表达式的例子来讲解:X3+X2+1。
首先我们有一个初始状态“111”。我们就有了下面这么一个计算过程(画得不好,大家看内容就好)。简单说明一下,红色为异或运算过程,蓝色为每次移位后的bit,绿色为输出的数据bit,紫色说明绕一圈之后又回到了原先,循环了一次。
具体的计算过程,如下图,我们一起来看一下图。
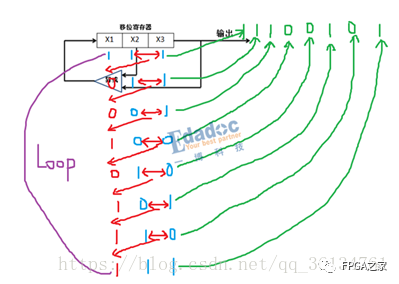
这是一个初始一直是111的例子,也就是说,我们的输入一直都是111.观察最终的输出结果我们可以看出,他得到了0,不再是全是1。
4、 编码过程
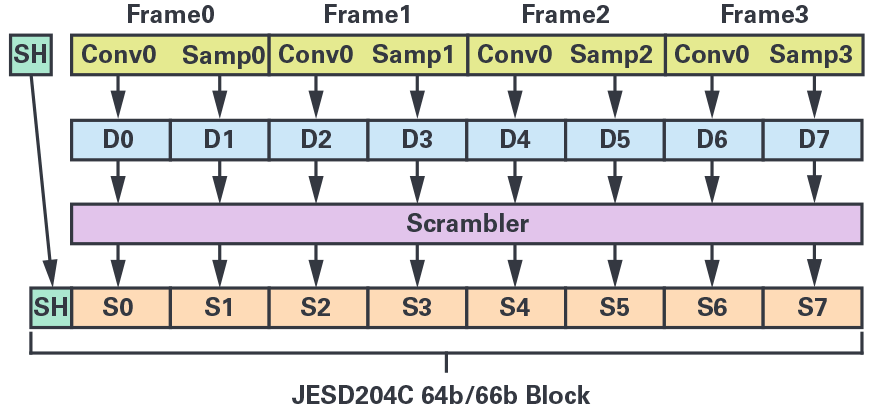
关于编码过程,我们先一起来看一个图:
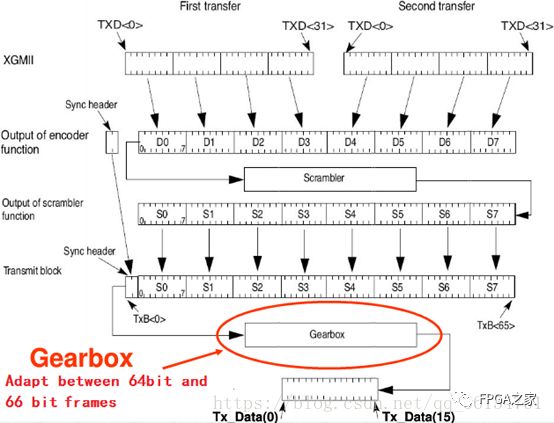
图中的CGMII是物理编码子层,output of encoder function为编码器的输出结果,outputof scrambler function为扰码器的输出结果,transmit block为传输块,Gearbox为变速箱。
我们一起来看一下这个过程,我们一些数据块要传输,假设说从物理编码子层传来的这两个块每个是32bit,加在一起才有64bit,经过encoder编码器进行编码,得到编码后的数据D0-D7,生成同步头01或者10,然后不含同步头的D0-D7,经过扰码器,得到表达式X58+X39+1扰码后的数据S0-S7。
在之后,将同步头和扰码后的数据S0-S7合并,生成一个传输块,将这个传输块经过GearBox处理后,完成编码。
5、 8B/10B、64B/66B简单比较
这里,我们一起来看一个比较的图:

在图中,我们分别从他们之中的连续的0和连续的1的个数、DC平衡能力、位同步时钟恢复能力,字同步能力控制块等方面进行了比较。
经过对比分析我们可以得知,8B/10B编码的连续0或者连续1的最大长度是5;8B/10B编码他有良好的DC平衡能力和位同步恢复能力,而64B/66B的这些能力都和扰码器有关,或者说他都决定于扰码所用的表达式。对于字同步,8B/10B编码有他自己的K码,而64B/66B编码用的是两位表示的同步头。对于控制码,8B/10B编码也是使用K码,而64B/66B编码用的是同步头为10 的控制码。
6、 结束语
64B/66B编码的这种扰码方式目标是使数据的“0”和“1”最大程度的随机分布,减小连续出现的情况,因此它可能并不能适用于所有的码型,不像8B/10B编码一样对所有的bit组合都有出色的表现,具体还要看扰码器接收器的能力。但是无可否认,它最大的好处是效率比较高,传输冗余的bit只有2位,开销大约只有3%,不像8B/10B编码需要20%的开销,这方面在更高速的传输环境下更具有优势。
参考资料:
【1】 存储技术基础 西安电子科技大学出版社刘凯 刘博 编著。
【2】 百度百科64B/66B编码8B/10B编码
【3】 CSDN博客 线路/信道编码技术(2)——64B/66B编码
编辑:黄飞










 工商网监
工商网监
评论