 电子发烧友App
电子发烧友App



一、容器网络概述
容器这一两年火的不行,可以说是独领IT风骚,一时风光无二。相比于虚拟机来说,容器更轻,一台服务器上可以运行成百上千的容器,这意味着更为密集的计算资源,因此基于容器运行工作负载的模式深受云服务提供商们的青睐。
然而对于云管理员来说,管理容器确是一件相当头疼的事情,容器的生命周期更短了,容器的数量更多了,容器间的关系更复杂了。为了简化大规模容器集群的运维,各路容器管理与编排平台应运而生,Docker社区开发了Swarm+Machine+Compose的集群管理套件,Twitter主推Apache的Mesos,Google则开源了自己的Kubernetes。这些平台为大规模的容器集群提供了资源调度、服务发现、扩容缩容等功能,然而这些功能都是策略向的,真正要实现大规模的容器集群,网络才是最基础的一环。
相比于虚拟机网络,容器网络主要具有以下特点,以及相应的技术挑战:
1、虚拟机拥有完善的隔离机制,虚拟网卡与硬件网卡在使用上没有什么区别,而容器则使用network namespace提供网络在内核中的隔离,因此为了保障容器的安全性,容器网络的设计需要更为慎重的考虑。
2、出于安全考虑,很多情况下容器会被部署在虚拟机内部,这种嵌套部署(nested deployment)需要设计新的网络模型。
3、容器的分布不同于虚拟机,一个虚拟机的运行的业务可能要被拆分到多个容器上运行,根据业务不同的需要,这些容器有时候必须放在一台服务器中,有时候可以分布在网络的各个位置,两种情况对应的网络模型也很可能不尽相同。
4、容器的迁移速度更快,网络策略的更新要能够跟得上速度。
5、容器数量更多了,多主机间的ARP Flooding会造成大量的资源浪费。
6、容器生命周期短,重启非常频繁,网络地址的有效管理(IPAM)将变得非常关键。
不过,由于容器自身的特征使得它与应用的绑定更为紧密,从交付模式来看更倾向于PaaS而非IaaS,因此容器网络并没有成为业界关注的焦点。起步较晚,再加上上述诸多的技术挑战,使得容器网络相比于OpenStack Neutron来说发展的情况要落后不少。Docker在开始的很长一段时间内只支持使用linux bridge+iptables进行single-host的部署,自动化方面也只有pipework这类shell脚本。
幸运的是,目前业界已经意识到了可扩展、自动化的网络对于大规模容器环境的重要性:docker收购了容器网络的创业公司socketplane,随即将网络管理从docker daemon中独立出来形成libnetwork,并在docker 1.9中提供了多种network driver,并支持了multi-host;一些专业的容器网络(如flannel、weave、calico等)也开始与各个容器编排平台进行集成;OpenStack社区也成立了专门的子项目Kuryr提供Neutron network driver(如DragonFlow、OVN、Midolnet等)与容器的对接。
二、容器网络模型
这一节我们来介绍容器网络的基础,包括容器的接入,容器间的组网,以及几种容器网络的通用模型。
(一)容器的接入
1.和host共享network namespace
这种接入模式下,不会为容器创建网络协议栈,即容器没有独立于host的network namespace,但是容器的其他namespace(如IPC、PID、Mount等)还是和host的namespace独立的。容器中的进程处于host的网络环境中,与host共用L2-L4的网络资源。该方式的优点是,容器能够直接使用host的网络资源与外界进行通信,没有额外的开销(如NAT),缺点是网络的隔离性差,容器和host所使用的端口号经常会发生冲突。

2.和host共享物理网卡
2与1的区别在于,容器和host共享物理网卡,但容器拥有独立于host的network namespace,容器有自己的MAC地址、IP地址、端口号。这种接入方式主要使用SR-IOV技术,每个容器被分配一个VF,直接通过PCIe网卡与外界通信,优点是旁路了host kernel不占任何计算资源,而且IO速度较快,缺点是VF数量有限且对容器迁移的支持不足。

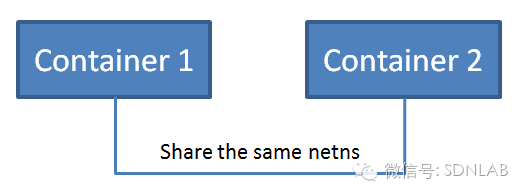
3.和另外一个容器共享network namespace
与1类似,容器没有独立的network namespace,但是以该方式新创建的容器将与一个已经存在的容器共享其network namespace(包括MAC、IP以及端口号等),网络角度上两者将作为一个整体对外提供服务,不过两个容器的其他namespace(如IPC、PID、Mount等)是彼此独立的。这种方式的优点是,network namespace相联系的容器间的通信高效便利,缺点是由于其他的namespace仍然是彼此独立的,因此容器间无法形成一个业务逻辑上的整体。
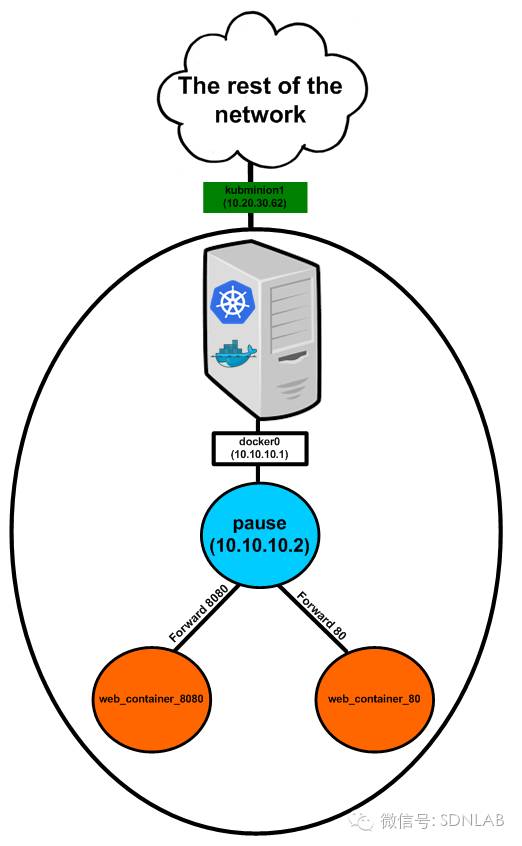
4.Behind the POD
这种方式是Google在Kubernetes中的设计中提出来的。Kubernetes中,POD是指一个可以被创建、销毁、调度、管理的最小的部署单元,一个POD有一个基础容器以及一个或一组应用容器,基础容器对应一个独立的network namespace并拥有一个其它POD可见的IP地址(以IP A.B.C.D指代),应用容器间则共享基础容器的network namespace(包括MAC、IP以及端口号等),还可以共享基础容器的其它的namespace(如IPC、PID、Mount等)。POD作为一个整体连接在host的vbridge/vswitch上,使用IP地址A.B.C.D与其它POD进行通信,不同host中的POD处于不同的subnet中,同一host中的不同POD处于同一subnet中。这种方式的优点是一些业务上密切相关的容器可以共享POD的全部资源(它们一般不会产生资源上的冲突),而这些容器间的通信高效便利,缺点是同一POD下的容器必须位于同一host中,从而限制了位置的灵活性。
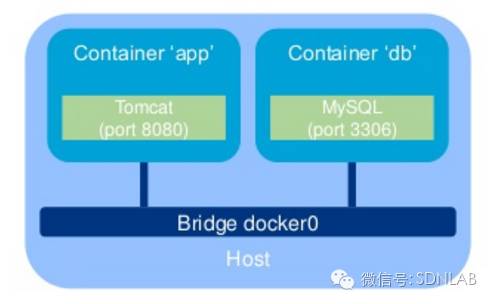
5.连接在的vbridge/vswitch上
这种方式是最为常见的,容器拥有独立的network namespace,通过veth-pair连接到vswitch上。这种方式对于网络来说是最为直接的,在vswitch看来,通过这种方式连接的容器与虚拟机并没有任何区别。vbridge/vswitch的实现有很多,包括linux bridge,Open vSwitch,macvlan等。这种方式的优点是vbridge/vswitch可实现的功能比较丰富,尤其是Open vSwitch可以支持VLAN、Tunnel、SDN Controller等,缺点是可能会造成很多额外的开销。
6.嵌套部署在VM中
这种方式在生产环境也比较常见,由于一台host中往往部署着多方的容器,存在安全隐患,因此许多用户会选择先启动自己的虚拟机,然后在自己的虚拟机上运行容器。这种方式其实是一种嵌套虚拟化,因此本质上来说,这种方式下容器的接入对于host可以是完全透明的,容器在虚拟机内部的接入可以采用上述1-5中任意的方法。不过这对于云平台来说就意味着失去了对容器接入的管理能力,为了保留这一能力,往往需要在虚拟机内部和host中分别部署vswitch并实现级联,由虚拟机内部的vswitch用来接入容器并对其进行特定的标记(云平台分配),以便host中的vswitch进行识别。一种常见的方式是使用Open vSwitch对容器标记vlan id。

(二)MultiHost组网
1.Flat
Flat主要可分为L2 Flat和L3 Flat。L2 Flat指各个host中所有的容器都在virtual+physical网络形成的VLAN大二层中,容器可以在任意host间进行迁移而不用改变其IP地址。L3 Flat指各个host中所有的容器都在virtual+physical网络中可路由,且路由以/32位的形式存在,使得容器在host间迁移时不需要改变IP地址。L2/L3 Flat下,不同租户的IP地址不可以Overlap,L3 Flat下容器的IP编址也不可与physical网络Overlap。L3 Flat简单示意如下。

2.L3 Hierarchy
L3 Hierarchy中各个host中所有的容器都在virtual+physical网络中可路由,且路由在不同层次上(VM/Host/Leaf/Spine)以聚合路由的形式存在,即处于相同CIDR的容器需要在物理位置上被组织在一起,因此容器在host间迁移时需要改变IP地址。L3 Hierarchy下,不同租户的IP地址不可以Overlap,容器的IP编址也不可与physical网络Overlap。下图是L3 Hierarchy中的IP地址规划示例。

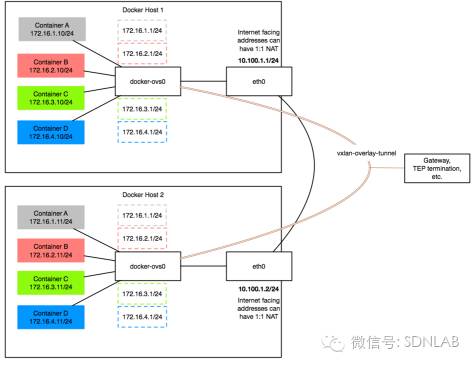
3.Overlay
Overlay主要可分为L2 over L3和L3 over L3,少部分实现L2/L3 over UDP。L2 over L3中,容器可以跨越L3 Underlay进行L2通信,容器可以在任意host间进行迁移而不用改变其IP地址。L3 over L3中,容器可以跨越L3 Underlay进行L3通信,容器在host间进行迁移时可能需要改变IP地址(取决于Overlay是L3 Flat还是L3 Hierarchy)。L2/L3 Overlay下,不同租户的IP地址也可以Overlap,容器的IP编址也可以与Underlay网络Overlap。L2 over L3(VxLAN实现)如下图所示。
(三)容器网络的两种通用设计
1.CNM
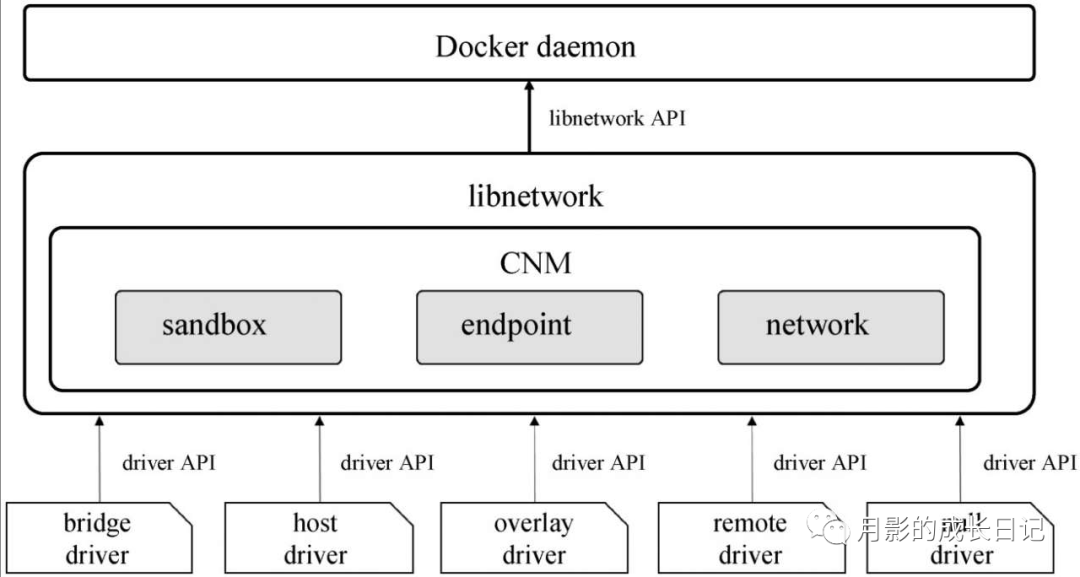
CNM(Container Network Model)是Cisco的一位工程师提出的一个容器网络模型(https://github.com/docker/docker/issues/9983),docker 1.9在libnetwork中实现了CNM(https://github.com/docker/libnetwork/blob/master/docs/design.md#the-container-network-model)。CNM的示意如下,主要建立在三类组件上Sandbox、Endpoint和Network。
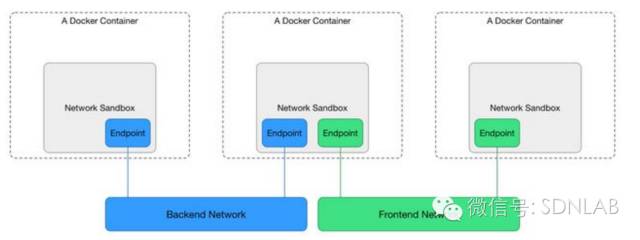
Sandbox:一个Sandbox对应一个容器的网络栈,能够对该容器的interface、route、dns等参数进行管理。一个Sandbox中可以有多个Endpoint,这些Endpoint可以属于不同的Network。Sandbox的实现可以为linux network namespace、FreeBSD Jail或其他类似的机制。
Endpoint: Sandbox通过Endpoint接入Network,一个Endpoint只能属于一个Network,but may only belong to one Sandbox(这句翻译不好)。Endpoint的实现可以是veth pair、Open vSwitch internal port或者其他类似的设备。
Network:一个Network由一组Endpoint组成,这些Endpoint彼此间可以直接进行通信,不同的Network间Endpoint的通信彼此隔离。Network的实现可以是linux bridge、Open vSwitch等。
Libnetwork对于CNM的实现包括以下5类对象:
NetworkController: 每创建一个Network对象时,就会相应地生成一个NetworkController对象,NetworkController对象将Network对象的API暴露给用户,以便用户对libnetwork进行调用,然后驱动特定的Driver对象实现Network对象的功能。NetworkController允许用户绑定Network对象所使用的Driver对象。NetworkController对象可以看做是Network对象的分布式SDN控制器。
Network: Network对象是CNM Network的一种实现。NetworkController对象通过提供API对Network对象进行创建和管理。NetworkController对象需要操作Network对象的时候,Network对象所对应的Driver对象会得到通知。一个Network对象能够包含多个Endpoint对象,一个Network对象中包含的各个Endpoint对象间可以通过Driver完成通信,这种通信支持可以是同一主机的,也可以是跨主机的。不同Network对象中的Endpoint对象间彼此隔离。
**
Driver:** Driver对象真正实现Network功能(包括通信和管理),它并不直接暴露API给用户。Libnetwork支持多种Driver,其中包括内置的bridge,host,container和overlay,也对remote driver(即第三方,或用户自定义的网络驱动)进行了支持。
Endpoint: Endpoint对象是CNM Endpoint的一种实现。容器通过Endpoint对象接入Network,并通过Endpoint对象与其它容器进行通信。一个Endpoint对象只能属于一个Network对象,Network对象的API提供了对于Endpoint对象的创建与管理。
**
Sandbox:** Sandbox对象是CNM Sandbox的一种实现。Sandbox对象代表了一个容器的网络栈,拥有IP地址,MAC地址,routes,DNS等网络资源。一个Sandbox对象中可以有多个Endpoint对象,这些Endpoint对象可以属于不同的Network对象,Endpoint对象使用Sandbox对象中的网络资源与外界进行通信。Sandbox对象的创建发生在Endpoint对象的创建后,(Endpoint对象所属的)Network对象所绑定的Driver对象为该Sandbox对象分配网络资源并返回给libnetwork,然后libnetwork使用特定的机制(如linux netns)去配置Sandbox对象中对应的网络资源。
2.CNI
CNI(Container Networking Interface)是CoreOS为Rocket(docker之外的另一种容器引擎)提出的一种plugin-based的容器网络接口规范(https://github.com/containernetworking/cni/blob/master/SPEC.md),CNI十分符合Kubernetes中的网络规划思想,Kubernetes采用了CNI作为默认的网络接口规范,目前CNI的实现有Weave、Calico、Romana、Contiv等。
CNI没有像CNM一样规定模型的术语,CNI的实现依赖于两种plugin:CNI Plugin负责将容器connect/disconnect到host中的vbridge/vswitch,IPAM Plugin负责配置容器namespace中的网络参数。
CNI要求CNI Plugin支持容器的Add/Delete操作,操作所需的参数规范如下:
1、Version:使用的CNI Spec的版本。
2、Container ID:容器在全局(管理域内)唯一的标识,容器被删除后可以重用。Container ID是可选参数,CNI建议使用。
3、Network namespace path:netns要被添加到的路径,如/proc/[pid]/ns/net。
4、Network configuration:一个JSON文件,描述了容器要加入的网络的参数。
5、Extra arguments:针对特定容器要做的细粒度的配置。
6、Name of the interface inside the container:容器interface在容器namespace内部的名称。
其中,Network configuration的schema如下:
1、cniVersion:使用的CNI Spec的版本。
2、name:网络在全局(管理域内)唯一的标识。
3、type:CNI Plugin的类型,如bridge/OVS/macvlan等。
4、ipMasq:boolean类型,host是否需要对外隐藏容器的IP地址。CNI Plugin可选地支持。
5、ipam:网络参数信息
5.1、type:分为host-local和dhcp两种
5.2、routes:一个route列表,每一个route entry包含dst和gw两个参数。
6、dns:nameservers+domain+search domains+options
为了减轻CNI Plugin的负担,ipam由CNI Plugin调用IPAM Plugin来实现,IPAM Plugin负责配置容器namespace中的网络参数。IPAM的实施分为两种,一种是host-local,在subnet CIDR中选择一个可用的IP地址作为容器的IP,route entry(可选)在host本地配置完成。另一种是dhcp,容器发送dhcp消息请求网络参数。
Add操作后,会返回以下两个结果:
lIPs assigned to the interface:IPv4地址/IPv6地址/同时返回IPv4和IPv6地址
lDNS information:nameservers+domain+search domains+options
三、Docker网络
Docker是当下最为火热的容器引擎,为实现大规模集群,docker推出了Swarm+Machine+Compose的集群管理套件。然而,docker的原生网络在很长一段时间内都是基于linux bridge+iptables实现的,这种方式下容器的可见性只存在于主机内部,这严重地限制了容器集群的规模以及可用性。其实,社区很早就意识到了这个问题,不过由于缺乏专业的网络团队支持,因此docker的跨主机通信问题始终没有得到很好的解决。另外,手动配置docker网络是一件很麻烦的事情,尽管有pipework这样的shell脚本工具,但是以脚本的自动化程度而言,用来运维大规模的docker网络还是too naïve。
2015年3月,docker收购了一家 SDN初创公司socketplane,随即于5月宣布将网络管理功能从libcontainer和docker daemon中抽离出来作为一个单独的项目libnetwork,由原socketplane团队成员接手,基于GO语言进行开发。2015年11月发布的docker 1.9中libnetwork架构初步形成,支持多种nework driver并提供跨主机通信,并在后续的1.10、1.11两个版本中修复了大量bug。目前,libnetwork处于0.6版本。
(1)Docker0
Docker 1.9之前,网络的实现主要由docker daemon来完成,当docker daemon启动时默认情况下会创建docker0,为docker0分配IP地址,并设置一些iptables规则。然后通过docker run命令启动容器,该命令可以通过—net选项来选择容器的接入方式(参见“容器的网络模型”),docker 1.9之前的版本支持如下4种接入方式。
1、bridge:新建容器有独立的network namespace,并通过以下步骤将容器接入docker0
1)创建veth pair
2)将veth pair的一端置于host的root network namespace中,并将其关联docker0
3)将veth pair的另一端置于新建容器的network namespace中
4)从docker0所在的subnet中选一个可用的IP地址赋予veth pair在容器的一端
2、host:新建容器与host共享network namespace,该容器不会连接到docker0中,直接使用host的网络资源进行通信
3、container:新建容器与一个已有的容器共享network namespace,该容器不会连接到docker0中,直接使用host的网络资源进行通信
4、none:新建容器有独立的network namespace,但是不会配置任何网络参数,也不会接入docker0中,用户可对其进行任意的手动配置
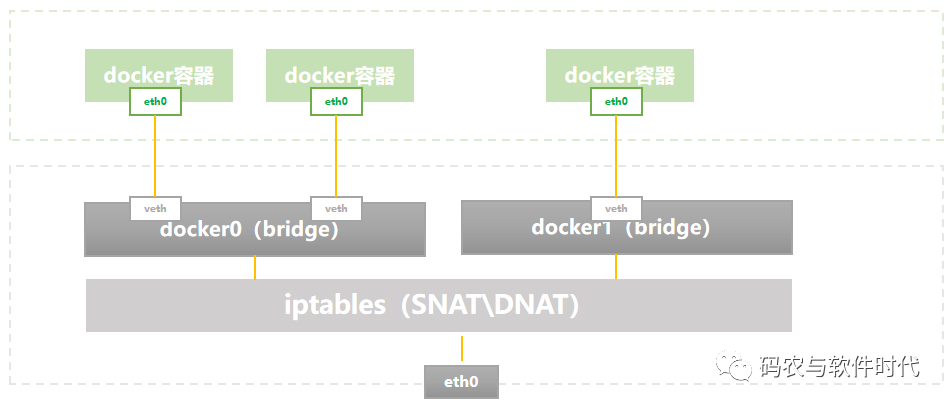
后3种没什么好说的,下面介绍一下bridge方式。Docker0由linux bridge实现,容器通过veth设备接入docker0,本地容器都处于同一subnet中,彼此间通信通过docker0交换,与外界通信以docker0的IP地址作为网关。Docker0的IP地址可以看做是内置连接在linux bridge上的设备(类似于ovs br上的同名internal port),位于host的root namespace中,容器与外界的通信要依赖于host中的Iptables MASQUERADE规则来做SNAT,容器对外提供服务要依赖于host中的Iptables dnat规则来暴露端口。因此这种方案下,容器间的跨主机通信其实用的都是host的socket,容器本身的IP地址和端口号对其它host上的容器来说都是不可见的。

这个方案非常原始,除了不能支持直接可见的跨主机通信以外,NAT还会导致很多其它不合意的结果,如端口冲突等。另外,对于一些复杂的需求,如IPAM、多租户、SDN等均无法提供支持。
(2)Pipework
容器就是namespace,docker0就是linux bridge,再加上一些iptables规则,实际上容器组网就是调用一些已有的命令行而已。不过,当容器数量很多,或者是频繁地启动、关闭时,一条条命令行去配就显得不是很合意了。于是,Docker公司的工程师Jerome Patazzoni就写了一个shell脚本来简化容器网络的配置,主要就是对docker/ip nets/ip link/brctl这些命令行的二次封装。Jerome Patazzoni自己认为pipework是SDN tools for container,虽然有点too naïve了,但是从实用性的角度来看,确实倒也可以满足一些自动化运维的需要。
当然pipework相比于docker0,除了提供了命令行的封装以外,还是具备一些其他的优势的,比如支持多样的network driver如OVS和macvlan,支持在host上开dhcp-server为容器自动分配IP地址,支持免费ARP,等等。
具体的实现这里就不讲了,因为这东西其实完全说不上高深,总共加起来也就400多行代码。
(3)Libnetwork
Socketplane是一家做容器网络的startup,2014年4季度创建,2015年3月份就被docker收购了,可以看到当时docker对于原生的网络管理组件的需求是有多么迫切,而且socketplane团队的这帮子人是SDN科班出身的,docker也总算有了搞网络的正规军。不过,socketplane和libnetwork的设计在架构上还是有很大不同的,我们先来看看socketplane的设计。
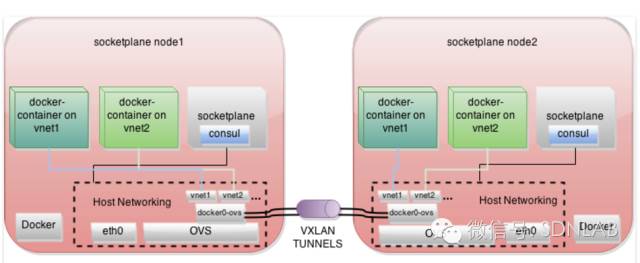
架构上,数据平面是OVS VxLAN,南向协议是OVSDB,控制平面是基于consul的分布式k/v store,北向是socketplane CLI。控制平面的部署细节上,consul是放在一个socketplane容器中的,该容器通过host模式与host共享network namespace,consul通过eth0去做服务发现和状态同步,状态主要就是指容器与host IP的映射关系了。数据平面的流表情况,就是match MAC+IP,actions就是送到本地的容器或者远端的tunnel peer上,有点奇怪的是socketplane没有使用tunnel_id,而是用了vlan_id标识vnet,这与RFC 7348是有冲突的。另外,根据为数不多的资料来看,socketplane在被收购前只完成了L2的east-west,还没有考虑routing和south-north。
可以看到,socketplane的设计并不复杂。但是被收购进docker后,麻烦事可就多了——首先,数据平面决计不能演化为ovs monopolic,linux bridge要有,第三方driver也得玩得转;其次,控制平面k/v store也要可插拔,起码要支持zookeeper和etcd,最好还要把自家的集群工具swarm集成进来;另外,要考虑老用户的习惯,原有的网络设计该保留还要保留;最后,还要遵循社区提出的容器网络模型CNM(https://github.com/docker/docker/issues/9983)。
于是,docker网络在1.9变成了下面这个样子(图中只画了一个host),libkv提供swarm的服务发现,以及overlay network的k/v store,每个host上开启docker daemon并加入swarm cluster,libcontainer负责管理容器,libnetwork负责管理网络。libnetwork支持5种网络模式,none/host/bridge/overlay/remote,图中从左到右依次显示了后4种,其中overlay和一些remote可以支持multi-host。

Overlay是libnetwork默认的multi-host网络模式,通过VxLAN完成跨主机。Libnetwork会把overlay driver放在单独的network namespace中,默认的overlay driver为linux bridge。当容器(Sandbox)接入overlay(Network)时,会被分到两个网卡(Endpoint),eth0连在vxlan_driver上,eth1连在docker_gwbridge上。Vxlan_driver主要负责L2的通信,包括本地流量和跨主机流量,docker_gwbridge的实现原理和docker0一样,负责处理Service的通信,包括不同网络容器间,以及容器与Internet间两类流量。Eth0和eth1各有一个IP地址,分属于不同网段,eth0默认以10开头,eth1默认以172开头,L2和L3的通信直接通过容器内部的路由表分流,送到不同的设备上处理。
Remote是libnetwork为了支持其它的Driver而设计的一种pluggble框架,这些Driver不要求一定支持multi-host。除了一些第三方的Driver外(如weave、calico等),目前libnetwork还原生提供了对macvlan driver和ipvlan driver的支持。当然,就像Neutron的ML2一样,为了打造生态,plugin driver的接口还是要libnetwork自己来规范的,具体请参考https://github.com/docker/libnetwork/blob/master/docs/remote.md。
既然说是引入SDN,那么API的规范对于libnetwork来说就十分重要了,不过目前libnetwork的接口封装还处于相当初级的阶段,基本上就是对Network和Endpoint的创建、删除以及连接(https://github.com/docker/libnetwork/blob/master/docs/design.md), 并没有提供很友好的业务API。
对于libnetwork的介绍就是这些了。尽管libnetwork实现了千呼万唤的multi-host,也为docker网络带来了一定的灵活性与自动化,但就目前来说,它的API尚不够友好,Driver的生态还不够成熟,而且并不具备任何高级的网络服务。因此,libnetwork相比于老大哥neutron来说,仍然存在着较大的差距。
其他网络容器选手速览
其实,早在docker社区将libnetwork提上日程之前,就已经有不少人在为容器的multi-host操心了。除了socketplane以外,如CoreOS为k8s的网络模型设计的flannel,通过P2P的控制平面构建overlay的weave net,通过BGP RR构建Flat L3的Calico,等等。最近,又有两个开源项目开始琢磨新的容器组网办法,一个是通过优化IPAM逻辑来构建Hierarchy L3的Romana,另一个是Cisco ACI派系的Contiv。当然,网络规模不大时,直接手配OVS也是个可行的方案。
这一节我们就来对上述容器网络选手来一个阅兵,先来介绍它们的架构,再来对它们做一个简单的对比。
1.Flannel
在k8s的网络设计中,服务以POD为单位,每个POD的IP地址,容器通过Behind the POD方式接入网络(见“容器的网络模型”),一个POD中可包含多个容器,这些容器共享该POD的IP地址。另外,k8s要求容器的IP地址都是全网可路由的,那么显然docker0+iptables的NAT方案是不可行的。
实现上述要求其实有很多种组网方法,Flat L3是一种(如Calico),Hierarchy L3(如Romana)是一种,另外L3 Overlay也是可以的,CoreOS就采用L3 Overlay的方式设计了flannel, 并规定每个host下各个POD属于同一个subnet,不同的host/VM下的POD属于不同subnet。我们来看flannel的架构,控制平面上host本地的flanneld负责从远端的ETCD集群同步本地和其它host上的subnet信息,并为POD分配IP地址。数据平面flannel通过UDP封装来实现L3 Overlay,既可以选择一般的TUN设备又可以选择VxLAN设备(注意,由于图来源不同,请忽略具体的IP地址)。

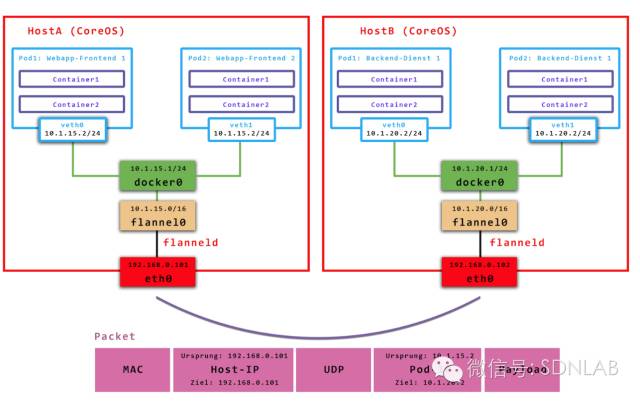
Flannel可说的不多,做得比较早,技术选型也十分成熟,已经可以用于大规模部署。下面是控制信道上通信内容的一个实例。

2.Weave
Weave是Weaveworks公司的容器网络产品,大家都叫惯了weave,实际上目前该产品的名字叫做Weave Nets,因为Weaveworks现在并不是一家只做网络的公司,最近它又做了两款其它的容器管理产品,GUI+集群。不过,为大家所熟悉的还是它网络口的产品。
不同于其它的multi-host方案,Weave可以支持去中心化的控制平面,各个host上的wRouter间通过建立Full Mesh的TCP链接,并通过Gossip来同步控制信息。这种方式省去了集中式的K/V Store,能够在一定程度上减低部署的复杂性,Weave将其称为“data centric”,而非RAFT或者Paxos的“algorithm centric”。
不过,考虑到docker libnetwork是集中式的K/V Store作为控制平面,因此Weave为了集成docker,它也提供了对集中式控制平面的支持,能够作为docker remote driver与libkv通信。

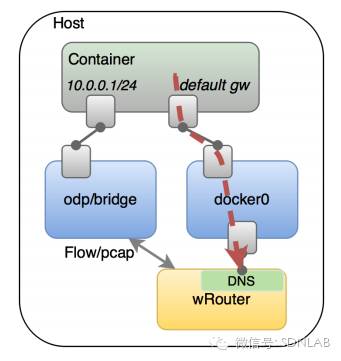
数据平面上,Weave通过UDP封装实现L2 Overlay,封装支持两种模式,一种是运行在user space的sleeve mode,另一种是运行在kernal space的 fastpath mode。Sleeve mode通过pcap设备在Linux bridge上截获数据包并由wRouter完成UDP封装,支持对L2 traffic进行加密,还支持Partial Connection,但是性能损失明显。Fastpath mode即通过OVS的odp封装VxLAN并完成转发,wRouter不直接参与转发,而是通过下发odp 流表的方式控制转发,这种方式可以明显地提升吞吐量,但是不支持加密等高级功能。


这里要说一下Partial Connection的组网。在多DC的场景下一些DC Sites无法直连,比如Peer 1与Peer 5间的隧道通信,中间势必要经过Peer 3,那么Peer 3就必须要支持做隧道的中间转发。目前sleeve mode的实现是通过多级封装来完成的,目前fastpath上还没有实现。

上面主要介绍的是weave对multi-host L2的实现。关于Service的发布,weave做的也比较完整。首先,wRouter集成了DNS功能,能够动态地进行服务发现和负载均衡,另外,与libnetwork 的overlay driver类似,weave要求每个POD有两个网卡,一个就连在lb/ovs上处理L2 流量,另一个则连在docker0上处理Service流量,docker0后面仍然是iptables作NAT。
3.Calico
Calico是一个专门做DC网络的开源项目。当业界都痴迷于Overlay的时候,Calico实现multi-host容器网络的思路确可以说是返璞归真——pure L3,pure L3是指容器间的组网都是通过IP来完成的。这是因为,Calico认为L3更为健壮,且对于网络人员更为熟悉,而L2网络由于控制平面太弱会导致太多问题,排错起来也更加困难。那么,如果能够利用好L3去设计DC的话就完全没有必要用L2。
不过对于应用来说,L2无疑是更好的网络,尤其是容器网络对二层的需求则更是强烈。业界普遍给出的答案是L2 over L3,而Calico认为Overlay技术带来的开销(CPU、吞吐量)太大,如果能用L3去模拟L2是最好的,这样既能保证性能、又能让应用满意、还能给网络人员省事,看上去是件一举多得的事。用L3去模拟L2的关键就在于打破传统的Hierarchy L3概念,IP不再以前缀收敛,大家干脆都把32位的主机路由发布到网络上,那么Flat L3的网络对于应用来说即和L2一模一样。
这个思路不简单,刨了L3存在必要性的老底儿,实际上如果不用考虑可扩展性、也不考虑private和public,IP地址和MAC地址标识endpoint的功能上确实是完全冗余的,即使考虑可扩展性,一个用L3技术形成的大二层和一个用L2技术形成的大二层并没有本质上的差距。而且,L3有成熟的、完善的、被普遍认可接受的控制平面,以及丰富的管理工具,运维起来要容易的多。
于是,Calico给出了下面的设计。L3选择的是BGP,控制平面是开源的Bird做BGP RR,etcd集群+Felix做业务数据同步,数据平面直接是Linux kernel做vRouter,FIB全是/32的v4或者/128的v6。具体来说,etcd接受业务数据,Felix向etcd同步后向host本地的路由表注入32/128位的主机路由,以及iptables的安全规则,然后Bird BGP Client将host的本地路由发送给Bird BGP RR,然后再由RR发布到其它host。
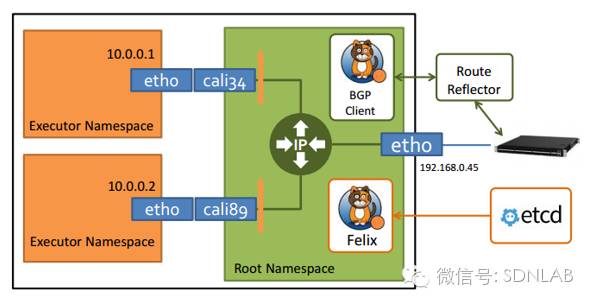
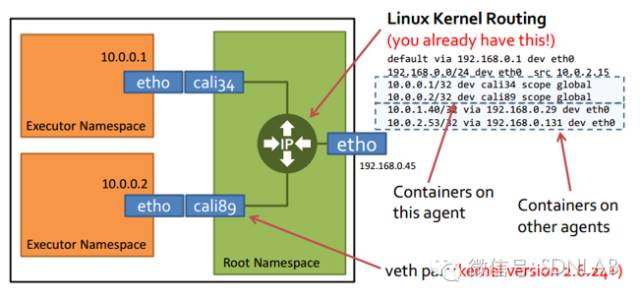
这个架构没什么好说的,技术成熟、高性能、易维护,看起来是生产级别的容器网络环境最好的选择。但是,也有不如意的地方:
1、没有了外面的封装,就谈不上VRF,多租户的话地址没法Overlap
2、L2和L3的概念模糊了,那么network级别的安全就搞不了,port级别的安全难搞因为需要的规则都是1:1的,数量上实在是太多了
不过,这都不是什么严重的问题。但有一点严重的是,Calico控制平面的设计要求物理网络得是L2 Fabric,这样vRouter间都是直接可达的,路由不需要把物理设备当做下一跳。如果是L3 Fabric,控制平面的问题马上就来了:下一跳是物理设备,那么它的IP是多少?物理设备如果要存32位的路由,能存多少?
这绝对是个难题。因此,为了解决以上问题,Calico不得不采取了妥协,为了支持L3 Fabric,Calico推出了IPinIP的选项,但是这明显属于自己打自己的脸,这么玩的话还不如用VxLAN来的实在呢。不过,对于使用L2 Fabric、没有多租户需求的企业来说,用Calico上生产环境应该是不错的选择。
4.Romana
说完了Calico的Flat L3,再来看看Romana给出的Hierarchy L3的方案。Romana是Panic Networks在2016年新提出的开源项目,旨在解决Overlay方案给网络带来的开销,虽然目标和Calico基本一致,但是采取的思路却截然不同,Romana希望用Hierarchy L3来组织DC的网络——没有大二层什么事儿了。
当然,Romana想要的是SDN的Hierarchy L3,因此控制平面的路由比较好控制了,不用搞RR这种东西了,不过IPAM的问题就比较关键了。IP地址有32位,哪些用来规划leaf-spine?哪些用来规划host?哪些用来规划VM?哪些用来规划POD?如果要多租户,哪些用来规划Tenant/Segment?可以说,这些如果有规划好的可能,而且都可以动态调整,那么Romana会是个“很SDN”的方案。
不过,这可不是说笑的,想要规划好谈何容易啊?问题归根结底我认为有如下几点:
1、要表示好DC中那么复杂的网络资源,32的地址空间捉襟见肘,无论你系统设计的多么精妙,巧妇难为无米之炊
2、如果不用Overlay,想要IPAM能够SDN化,边缘的host没问题,物理设备怎么办?一旦规模扩大了,或者组网有了新的需求,造成原有的地址规划不合适了,host说改也就改了,物理网络谁来搞动态调整?
3、另外,关键的关键是,大二层不要了,迁移怎么弄?
可以看一看Romana的slides里面给的IPAM实例,255 hosts、255 tenants、255 endpoints,对于对于IDC、云服务提供商、容器用户,是不是都显得局促了一些呢?
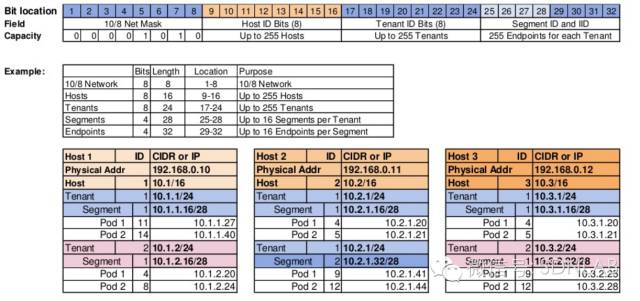
因此从网络设计的角度来说,个人目前还没有想到Romana能够支持大规模容器网络的理由,至于项目具体会发展成什么样子,仍需观察。
下面来看一看它的架构。倒也画的比较简单,managers是控制端,agent在设备端。控制端几个组件的功能,看了名字也就知道了,这里不再解释。设备端接受调度,给容器配IP,在host上配路由,也没什么好说的了。
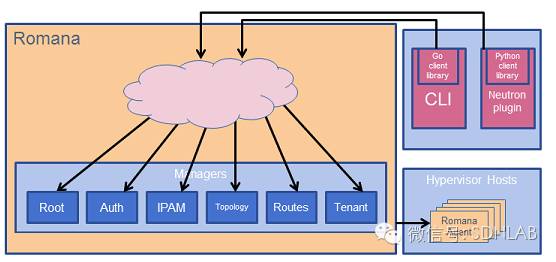
5.Contiv
Cisco在2015年搞的开源项目,准备把ACI那一套EPG的东西用到容器网络中来,号称要做容器的micro-segment。具体的没什么能讲的,因为Github上确实也还没有什么东西,而且Cisco做开源向来是奔着让人捉摸不透去的。Cisco的人说会集成到docker libnetwork中去,但项目的模样能不能出来,还得看未来的进展。项目链接在这:https://github.com/contiv/netplugin。
Neutron对容器网络的集成
眼看着容器一步一步火起来,几乎抢走了虚拟机的所有风头,OpenStack也按耐不住要做集成了。有Magnum做Swarm、K8S这些COE(Container Orchestration Engine)的前端,OpenStack就有了编排大规模容器集群的入口,而除了编排以外,网络侧的集成也是一个大头。其实从network driver的角度来看,容器和虚拟机倒也没什么特别大的差别,那么再搞一套Neutron for Container显然是没有必要(也不现实)的了。于是,Kuryr项目应运而生,旨在将现有Neutron的network driver衔接到容器网络中。
Kuryr是捷克语“信使”的意思,顾名思义,就是要把容器网络的API转化成Neutron API传递给Neutron,然后仍然由Neutron来调度后端的network driver来为容器组网。要做成这件事情,主要得解决三个问题:
1、建立容器网络模型,如CNM和CNI,和Neutron网络模型的映射关系
2、处理容器和Neutron network driver的端口绑定
3、容器不同于虚拟机的特征,可能会对现有Neutron network造成影响
第一个问题,通俗点说就是要做好翻译工作。以docker libnetwork举例,用户调了libnetwork的API要新建一个(CNM模型中的)Network对象,那Kuryr就得翻译成Neutron能听得懂的API——帮我起一个(Neutron)Subnet。这要求Kuryr作为remote driver,于是Neutron和Neutron driver对于libnetwork就是完全透明的了。

上面举了一个好理解的例子,不好办的是当两侧的模型不一致,尤其是左边有新概念的时候。比如,现在要为部署在VM中的Nested Container搞一个Security Group,但是Neutron目前只能管到host上,是看不见这个藏起来的家伙的,那这时就要对Neutron做扩展了,思路就是为Neutron Port新扩展一个属性来标记VM中这个Nested Container,这样做识别的时候带上这个标记就行了。
从实现上来讲,Kuryr要负责管理两侧的资源实例的ID的映射关系,以保证操作的一致性,否则会直接带来用户间的网络入侵。另外,IPAM现在在两侧都被独立出来了,IPAM的API也要能衔接的上。
至于第二个问题,拍脑袋想似乎是不应该存在的。但是,目前绝大多数Neutron network driver在绑定端口时的动作只有更新数据库,并不会为容器做plug。这个做法的原因在于,之前在处理虚拟机的时候,plug被看作是虚拟机启动时自带的动作,因此plug就放在了Nova的poweron函数里面。改network driver自然是不好的,于是Kuryr就得负责起处理这个历史遗留问题的任务了。
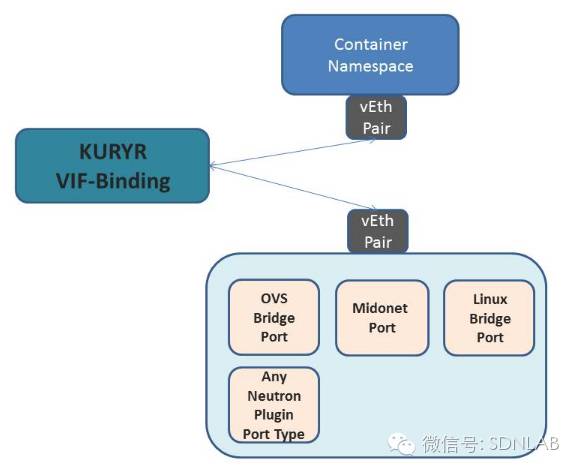
第三个问题可就是学问了。讲道理的话,业务的API没问题了,容器也都接入网络了,而转发的逻辑都是network driver写好的,跟接的是容器还是虚拟机也没有一毛钱关系,那不就应该万事大吉了吗?可是现实确很有可能不是这样的,比如:由于容器作为工作负载,其特征与虚拟机完全不同,因此业务对二者需求也是大相径庭。容器都是批量批量的起,而且它们的生命周期可能很短——需要来回来去的起,而Neutron的API都是走软件的消息总线的,而过于密集的API操作很有可能会造成消息总线崩溃掉。一个新建容器的API等了1分钟失败了,那么可能业务的需求就过去了(比如抢票),这个损失自然是不可接受的。
类似的问题可能都在潜伏着,如果Kuryr要走上生产环境,可就需要Gal Sagie多动脑筋了。
虽然Kuryr是OpenStack中比较新的项目,但目前Kuryr进展的还不错,对libnetwork和k8S的集成都有demo出来了。一旦Kuryr成熟后,这意味着Neutron下面的各路vendor们都可以不费吹灰之力直接上容器了,这对于Weave、Calico这些靠容器起家的vendor不可算是个好消息。

看来,云网络vendor间的竞争最后也都将演变为OpenStack、K8S、Mesos这些大部头对于DCOS的争夺了,毕竟胳膊拧不过大腿啊。
审核编辑:郭婷













 工商网监
工商网监
评论