 电子发烧友App
电子发烧友App


作者:李豪 本文精读《Congestion Control for Large-Scale RDMA Deployments》论文,就是在这篇论文中微软和Mellanox提出DCQCN拥塞控制算法,打开了RDMA在数据中心规模化部署的大门。虽然距论文发表已有八、九年,经典仍值得回味,今天我们细细阅读之。

01 摘要和背景介绍
现代(2015年)数据中心应用需要网络具备:1. 高吞吐量(40Gbps) ,2. 超低延迟(每跳 < 10 µs)、3. 低CPU开销。标准TCP/IP协议栈不满足这些要求,但是RDMA(Remote Direct Memory Access)技术可以。 当前RDMA在数据中心部署主要使用RoCE v2协议,该协议依赖PFC(Priority-based Flow Control)来保证网络的无损,即不发生丢包。但是PFC性能表现不佳,主要缺点包括:1. 对头阻塞(head-of-line blocking) 2. 不公平。 网络无损是需要付出代价的! 为了解决这些问题,我们引入DCQCN算法,这是一个端到端的拥塞控制算法,专门为RoCE v2量身打造;同时我们对于如何调参给出一些建议,包括交换机buffer水线配置以及该算法的其他参数。 端到端(end-to-end),从发送方到接收方,比如从client到server。点到点(point-to-point),网络上相邻的一跳,比如相邻两个交换机。 虽然RDMA技术在HPC领域使用悠久且广泛,但是在数据中心部署RDMA却很有挑战。,其中一个重要挑战是拥塞控制,数据中心的RDMA对拥塞控制有如下要求:
在无损网络环境下可以有效工作
简单到可以实现在网卡上(而非操作系统里)
RDMA最早使用Infiniband技术实现,IB使用私有的协议栈、专用硬件。IB在数据链路层(L2)使用逐跳(hop-by-hop)的credit-based流控来避免丢包,基于这个不丢包的L2,IB的传输层(L4)可以非常简单和高效。 难就难在IB的这套协议栈和硬件设备不能直接照搬到数据中心,因为数据中心网络是以太网,二者不兼容。如果同时在数据中心搭建两套网络又太贵,所以RoCE v2横空出世,允许基于传统以太网实现RDMA,具体做法是将IB的传输层作为UDP的payload,完全不使用IB的数据链路层。 IP头用来做路由,UDP头用来做ECMP。
虽然RoCE v2不再依赖IB的数据链路层,但却继承了IB的无损网络约束,因此提出了PFC(Priority-based Flow Control)。PFC通过让直接上游暂停发送数据的方式来避免交换机buffer溢出。 直接告诉上游端口,立即暂停发送任何数据!非常的粗暴。这里的上游可以是交换机或者网卡。 PFC是交换机端口级别的,不区分具体的流(flow,即连接),一旦暂停就会暂停端口上所有的连接。这种粒度显然太粗了,会导致拥塞扩散,进而导显著的致性能下降。虽然PFC可以区分交换机队列(交换机的每个端口有8个队列),但也于事无补,因为不可能给每个链接都是用一个单独的队列。 解决 PFC 局限性的根本办法是采用流级别的拥塞控制协议,协议需要满足以下要求:
在无损、L3 路由(网络层,即IP层)、数据中心网络上运行。
主机端低CPU开销。
起步速度要快,即无拥塞的时候流满速启动。
(2015年)当前常见的拥塞控制算法均无法满足以上要求,比如QCN,DCTCP,iWarp, TCP-Bolt等。
QCN不支持L3层网络
DCTCP和iWarp起步速度太慢(slow start)
DCTCP和TCP-Bolt使用软件实现,CPU占用太高
因此DCQCN横空出世,该算法值依赖交换机的RED和ECN功能,算法其余的部分都是现在主机侧的网卡上,该算法的特点为:
快速收敛到公平
高链路利用率
较低的队列堆积
较低的队列震荡
02 DCQCN的必要性
传统TCP堆栈性能不佳
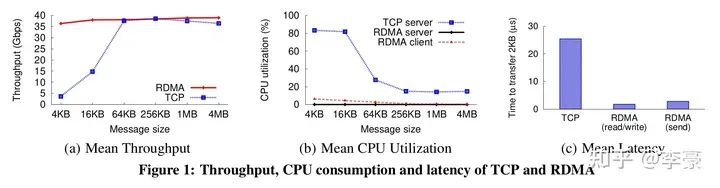
TCP协议栈在吞吐、CPU消耗、延迟等方面全面落后于RDMA。
图(a):吞吐方面,小包的时候TCP无法打满带宽,因为此刻CPU成为了瓶颈。而RDMA在小包时也可以打满带宽。
图(b):CPU占用方面,为了打满40G带宽,TCP使用了16个线程,总共占用了整机20%的CPU时间。而RDMA的client侧 CPU占用不超过3%,server侧CPU几乎没有CPU占用。
图(c):延迟方面,TCP的延迟为25.4微秒,而RDMA READ/WRITE延迟为1.7微秒,RDMA SEND延迟为2.8微秒。
PFC 有局限
RoCE v2依赖PFC来保障不发生丢包,PFC可以避免以太网交换机和网卡出现缓冲区溢出。具体做法是:交换机或者网卡监测自己的ingress队列,一旦队列超过特定阈值则发送一个PAUSE消息给相邻上游,上游收到PAUSE消息之后会停止整个端口的报文发送,直到收到RESUME消息再重新开始。 PFC有八个队列,每个队列都可以独立进行上述步骤。 这里主要的问题是作用于端口(+优先级)而不是作用于流(flow,即链接),这可能会导致head-of-line blocking等问题,导致网络性能变差。
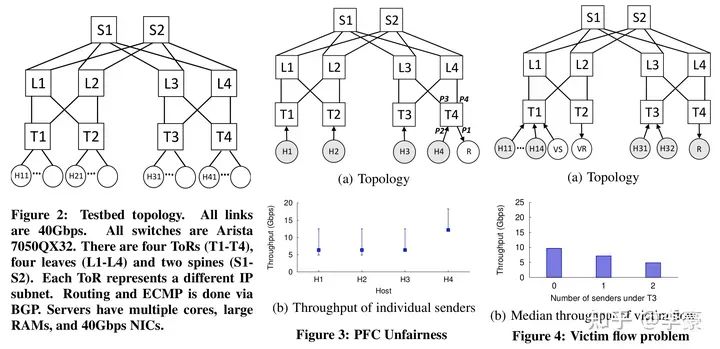
PFC的问题
不公平问题(unfairness):因为PFC没有区分具体的流,而是无脑的停掉整个端口流量,这会导致多个发送方之间的不公平问题。上图中Figure 3展示的是4个发送方的吞吐情况,非常的不均衡。 无辜流问题(victim flow):这个是指一组发送方-接收方之间(Figure4中的VS和VR)本没有拥塞,但是由于受到另一组有拥塞的发送方-接收方(H1~H32和R)的干扰,进而导致VS发生降速。这主要是因为PFC有级联效应,一个没有拥塞的流可能被别的拥塞路径波及到。 而已有方案都不能解决上述PFC导致的问题,因此本文提出DCQCN算法。
ECMP(Equal-cost multi-path routing)不足以解决上述问题:虽然ECMP会使得流在交换机链路上尽可能均匀分布,但不能保证没有冲突。
PFC的多队列机制也不够:因为PFC只有8个队列,单个队列内的流仍然会遇到上述问题。
03 DCQCN算法
算法过程
DCQCN 是一种基于速率的端到端拥塞协议,它建立在 QCN 和 DCTCP 之上。DCQCN 的大部分功能是现在网卡上(而不是交换机上,或者操作系统上)。如前文所述,DCQCN有以下特点:
在无损、L3 路由(网络层,即IP层)、数据中心网络上运行。
主机端低CPU开销。
起步速度要快,即无拥塞的时候流满速启动。
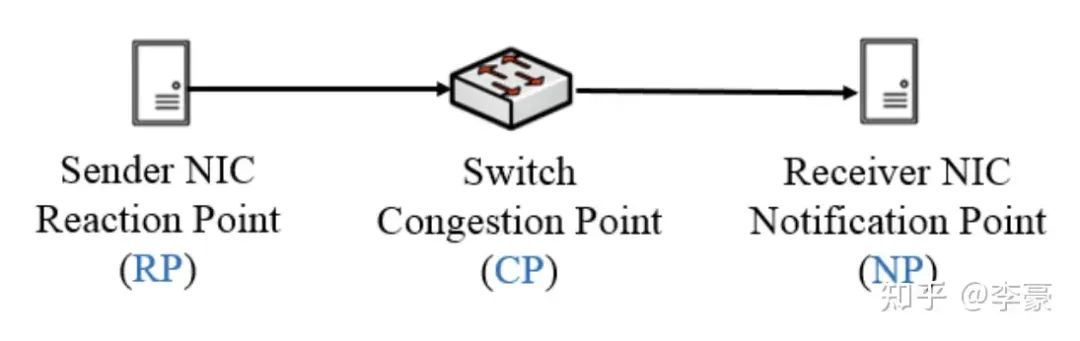
DCQCN中的三种角色 DCQCN中有三个角色,分别是:
RP(reaction point): 即发送方网卡
CP(congestion point): 即交换机
NP(notification point): 即接收方网卡
上述三种角色上的具体算法分别为: CP交换机上的算法:交换机上的算法和DCTCP一样,当交换机的egress队列超过特定阈值时开始对到来的报文(按照一定概率)标记ECN。这通过交换机的RED(Random early detection)功能完成,几乎所有的交换机都支持该功能,因此DCQCN不需要对交换机做改动。
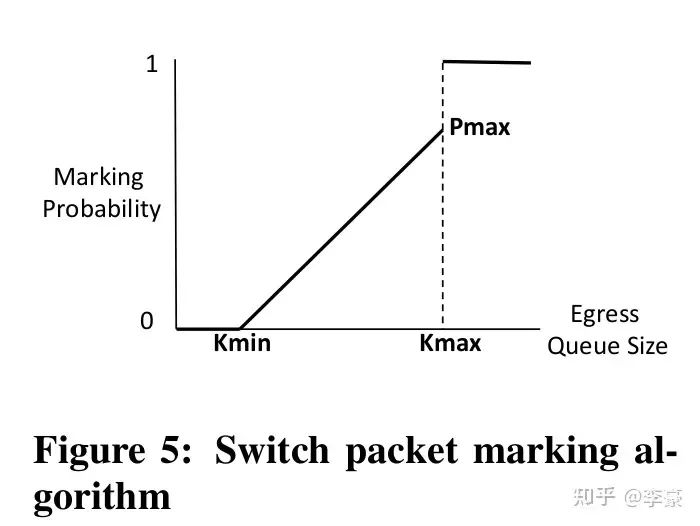
CP交换机上的算法 NP接收方网卡上的算法:当ECN标记后的报文到达接收方网卡,这表明网络上发生了拥塞,接收方网卡将该信息转换为CNP(Congestion Notification Packets)后反馈给发送方。CNP是RoCE v2规范中定义的拥塞通知方式。 NP上的算法主要用于决定CNP报生成的频率,比如可以每收到一个ECN就反馈一个CNP,也可以规定50us内最多反馈一个CNP。 CNP是区分流的,对于每个流NP算法流程如下图:
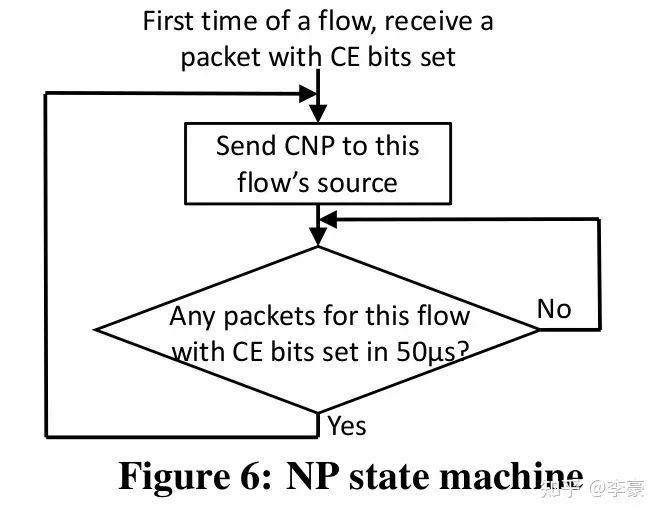
NP状态机
RP发送方网卡上的算法:这是DCQCN的重头戏。分为降速过程,升速过程,更新alpha三个部分。 降速过程:当RP上的一个流收到了CNP,该流会按照如下公式降速,并更新target rate和alpha值。
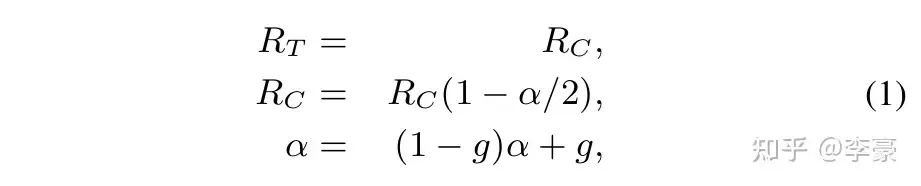
DCQCN降速过程
alpha更新过程:如果RP经过K个时间单位之后没有收到NP发来的CNP,则RP更新一次alpha值,更新公式如下。该公式的目的是在没有拥塞的时候逐渐降低alpha值,alpha的值区间是0~1。
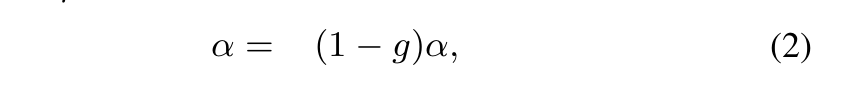
alpha更新过程 注意K要比CNP生成的周期要长一些,本文中选择K=55us 升速过程:RP采用和QCN相同的升速方式,即采用一个timer和一个byte counter决定升速的节奏。每收到B个字节之后byte counter触发升速,每隔T个时间单位之后timer触发升速。这两个参数都是可调的,以便控制升速节奏。 有三种升速方式,通常按照以下顺序发生:
快速恢复(fast recover)
加性增(additive increase)
超快速增(hyper increase)
注意这里没有slow start,一个新的流起速就按照全速发送,这么做是基于如下事实:大多数时候流传输的数据较少切网络无拥塞,因此全速发送也不会造成网络拥塞(如果真的拥塞了,最终还有PFC兜底)。
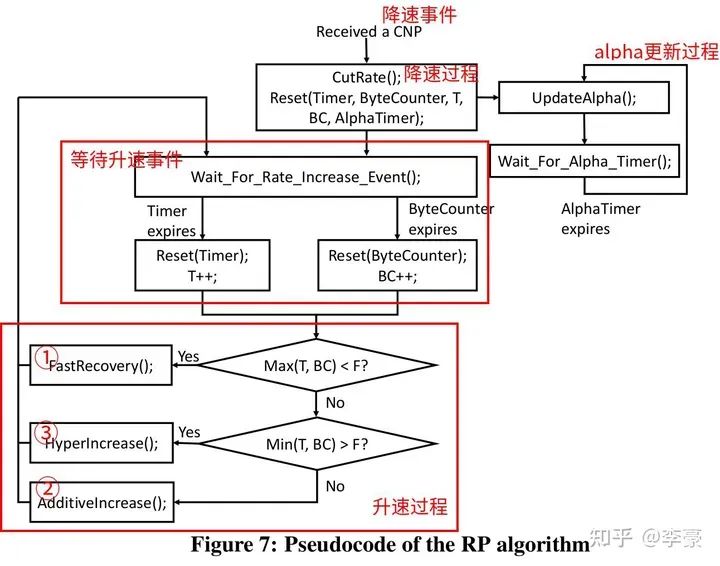
DCQCN 发送方算法 不同于PFC作用于端口,DCQCN是作用于流的,即每个流都独立进行上述的算法过程。下图表明DCQCN很好的解决了公平性问题和无辜流问题(unfairness and victim flow)。
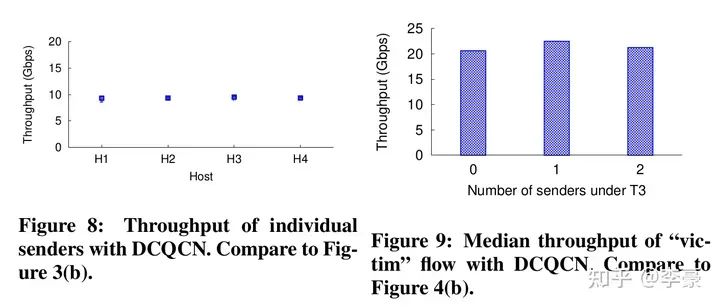
DCQCN实际表现
一些关键点讨论
CNP生成:我们以高优先级发送CNP以确保更快速的收敛。注意,通常在没有拥塞的情况下不会生成CNP。 基于速率的拥塞控制:DCQCN是一种基于速率的拥塞控制方案。我们采用基于速率的算法,因为它比基于窗口的算法更容易实现,并且允许更细粒度的控制。 参数设置:DCQCN 基于 DCTCP 和 QCN,但在关键方面有所不同。因此DCTCP和QCN推荐的参数设置不能盲目地与DCQCN一起使用。 PFC仍然是必需的:DCQCN 并不能消除对 PFC 的依赖,仍需要使用PFC做兜底来避免丢包,只是DCQCN会大大降低PFC发生的频率。 硬件实现:NP和RP(分别指接收方和发送方)的状态机都是现在网卡上(而非操作系统里),RP状态机的实现需要为每个流维护以下资源:
一个定时器:即Timer
一个计数器:即ByteCounter
跟alpha值相关的状态
RP上的限速是针对每个数据包粒度的。 NP主要用于产生CNP报文,在ConnectX-3 Pro每生成一个CNP需要花费1~5微秒。对于40Gbps网络,1500B MTU下接收方每50微秒最多收到166个网络报文,所以NP可以同时为10~20个流生成CNP,ConnectX-4可以同时为200个流生成CNP。 CNP生成是一个开销比较大的动作。上面一段话的意思是,每个流在发生拥塞是至少要在50微秒内生成1个CNP报文,而每次生成一个CNP需要消耗5微秒,即50微秒内只能生成10个CNP,因此ConnectX-3网卡最多并发为10个流生成CNP。 04 交换机缓冲区设置 DCQCN需要考虑以下两个相互冲突的约束,并基于此设置交换机缓冲区的阈值:
PFC不能触发的太早,至少不能早于ECN。
PFC不能触发的太晚,否则会导致丢包。
PFC生成时机主要是由交换机buffer阈值控制,本节讨论阈值设置问题。 Headroom buffer t_flight:发送到上游设备的PAUSE消息需要一段时间才能到达并生效。为了避免数据包丢失,PAUSE 发送方必须保留足够的缓冲区来处理在此期间可能收到的任何数据包。这包括发送 PAUSE 时正在传输的数据包,以及上游设备在处理 PAUSE 消息时发送的数据包。 PFC阈值 t_PFC:这是在PAUSE消息发送到上游之前(即上游停止发送之前),交换机的ingress队列可以增长的最大值,每个PFC优先级都有自己的ingress队列(8个优先级队列),因此如果交换机的总buffer大小为B,交换机的端口数量为n,则 : 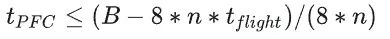 ECN阈值 t_ECN:一旦交换机的egress队列超过这个阈值,则交换机开始按照一定概率标记ECN。显然这个值要设置的比较合理,必须保证ECN先于PFC触发。 注意,PFC看的是ingress队列,ECN看的是egress队列!入口队列和出口队列的一个主要关系是:多个入口队列可以将数据发往同一个出口队列,这取决于实际流的目的地。 为了确保ECN先于PFC触发,必须考虑以下极端情况:全部egress队列的消息都来自同一个ingress队列,这种情况下出队列的压力最小,入队列的压力最大。因此需要保证:
ECN阈值 t_ECN:一旦交换机的egress队列超过这个阈值,则交换机开始按照一定概率标记ECN。显然这个值要设置的比较合理,必须保证ECN先于PFC触发。 注意,PFC看的是ingress队列,ECN看的是egress队列!入口队列和出口队列的一个主要关系是:多个入口队列可以将数据发往同一个出口队列,这取决于实际流的目的地。 为了确保ECN先于PFC触发,必须考虑以下极端情况:全部egress队列的消息都来自同一个ingress队列,这种情况下出队列的压力最小,入队列的压力最大。因此需要保证: 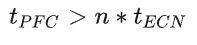 以上所有讨论并不是为了避免触发PFC,只是为了保证ECN先于PFC触发。DCQCN仍然依赖PFC做兜底。 DCQCN算法只是基于ECN/CNP让发送方降速而不是停止发送,而PFC的PAUSE消息比较狠,直接让上游端口停止发送任何数据。因此PFC总是能快速消除拥塞。 05 性能评测 DCQCN实际效果见下图,论文中最多评测了10打1的incast流量:
以上所有讨论并不是为了避免触发PFC,只是为了保证ECN先于PFC触发。DCQCN仍然依赖PFC做兜底。 DCQCN算法只是基于ECN/CNP让发送方降速而不是停止发送,而PFC的PAUSE消息比较狠,直接让上游端口停止发送任何数据。因此PFC总是能快速消除拥塞。 05 性能评测 DCQCN实际效果见下图,论文中最多评测了10打1的incast流量:
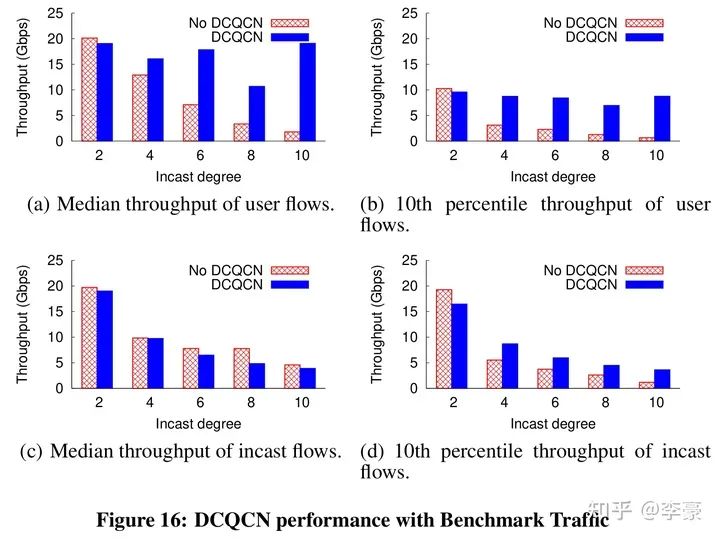
06 总 结
本文详细翻译和介绍了DCQCN论文的关键章节。在有DCQCN之前,RoCE v2只能通过PFC做拥塞控制,有了DCQCN之后RDMA技术才开始在数据中心广泛应用。
审核编辑:黄飞





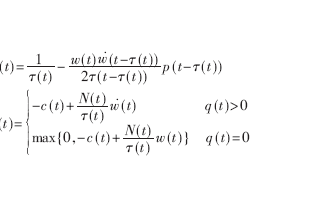







 工商网监
工商网监
评论