 电子发烧友App
电子发烧友App


在号码携带系统中,CSMS(集中管理系统)汇总着全国所有运营商号码携带用户的基本数据和号码携带规则,扮演着号码携带业务提供管理者和仲裁者的角色,地位十分重要。CSMS和运营商的号码携带营业生产系统一起,实时为用户提供号码携带申请业务,必须按照电信级系统的要求,提供24h×7d×365d时间内99.99%的服务可用性。因此,CSMS系统的高可用性方案十分重要。
高可用性(High Availability)一般是指通过尽量缩短系统停机时间,提高系统和应用的可用性。为了提高系统可用性,一种方法是提高计算机各个部件的可靠性,但这种方法并不可靠,因为单一服务器可靠性再高也存在单点故障的潜在隐患,所以目前业界比较成熟的做法是采用集群(CluSTer)的方案。它通过加入冗余设备使得在一个设备出错而停止服务的时候,这些冗余的设备可以继续提供服务。本文中,高可用性的含义还包括“快速恢复”,即一旦由于系统中止并重启后,业务应用能够尽快恢复。
本文主要介绍了在CSMS中为了实现系统的整体高可用性,在各个层面可以采用的集群技术。
2 系统高可用技术的应用范围
在号码携带系统中,从和运营商接口侧到CSMS的核心数据层主要包括以下功能层,高可用方案主要围绕这些层面来展开。
(1)网络层:是和运营商连接的部分,主要需要考虑,如何避免传输单点故障,如何避免网络设备单点故障?
(2)Web服务器层:如何保证Web服务器的单点故障?如果提供多台Web服务器,如何在之间进行资源协调?
(3)应用服务器层:Web服务器提交请求给应用服务器后,如何避免应用服务器的单点故障及多台应用服务器的资源协调?
(4)数据库服务器层:应用服务器向数据库服务器提交请求时,如何避免数据库服务器的单点故障及多台之间的资源协调?
(5)应用软件:即使我们采取了各种措施,还是存在服务器硬件宕机的可能性。在系统重启后,我们应用软件如何设计保证系统能快速恢复?
(6)数据层:如何保证数据存储安全可靠?
为了回答上述问题,我们需要对各种高可用性技术进行研究和总结。
3 高可用性技术研究
3.1 CSMS系统架构
图1所示的是CSMS系统组织架构。
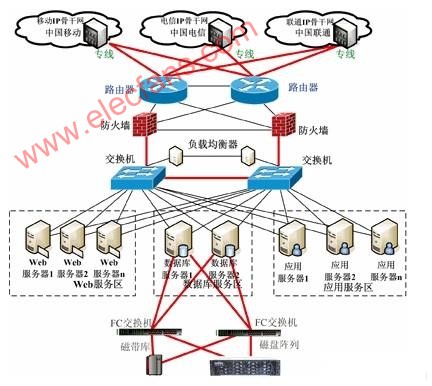
图1 CSMS系统组织架构
为了保证系统的高可用性,防止出现单点故障,系统的每个功能层在硬件设备上都采用冗余配置,同时通过各种软件方案设计,实现系统高可用性。
3.2 网络方案
在网络方案上,系统和每个运营商之间的专线采用155M POS或者MSTP双光缆接入,利用传输网络的冗余和自愈能力,保证系统物理接入线路的高可用性。每个运营商的两条光缆分别接入到系统的两台接入路由器上,尽量避免路由器设备的单点故障。每台路由器分别配置了多个网卡分别接入多个运营商的专线,防止出现单板卡故障影响到更多的运营商接入。
在路由器对运营商侧的方案设计上,需要采用动态路由协议,当某台路由器到某个运营商的某条缺省配置路由出现故障时(比如线路故障或板卡故障),需要将备选路由广播到所有相关设备上,新的通信连接则按照新的路由进行通信。在路由器对防火墙的方案设计上,需要采用VRRP协议进行动态IP地址绑定,即两台路由器下联到防火墙的IP为一个虚拟地址,缺省时绑定在某个路由器的实际地址上,当需要切换时,将虚拟地址绑定在另外一台路由器的实际地址上,而对于防火墙来说,不需要做任何改变就完成了通信的切换过程。
3.3 Web服务器的负载均衡器方案
从客户端的请求经过网络设备后,将首先到达Web服务器。从系统的高可用性设计角度出发,系统将部署多台Web服务器进行集群。Web服务器之间进行集群包括Web负载均衡和会话的失败转移两个方面。
负载均衡可以采用多种技术,比如采用硬件负载均衡器,也可以在某个Web服务器上部署负载均衡软件,由这台Web服务器兼作负载均衡器。负载均衡器最主要的特征包括:
(1)单点接入
从客户端的角度看,多台Web服务器只有一个地址,就是负载均衡器的服务地址。这样做的好处有两点:一是客户端不需要配置多个Web服务器地址,比较方便;二是可以向客户端网络屏蔽网内具体的设备的地址信息,对网络保护具有一定作用。
(2)实现负载均衡算法
当客户端请求到来的时候,负载均衡器能够决定把这个请求转发到后台的哪个Web服务器进行处理。主流算法包括:轮循算法,随机算法和权重算法,无论哪种算法,负载均衡器总是试图让每个服务器实例分担等同的压力。
(3)健康检查
一旦某一个Web服务器停止工作,负载均衡器能够检测到并且不再把请求转发到这个服务器。同样,当这个失败的服务器重新开始工作的时候,负载均衡器也能够检测到,并且开始向它转发请求。
(4)会话粘滞
所有的Web应用都会有一些会话状态,比如号码携带系统中某个流程是否结束的信息,某条请求消息是否接收到对应的ACK信息或者响应信息等。因为HTTP协议本身是无状态的,所以会话状态就需要记录在某个地方,并且和客户端关联,以便于下次请求的时候能够很方便地取出来。当进行负载均衡的时候,对于某一个确定的会话来说,把请求转发到上一次它所请求到的服务器实例是一个很好的选择,否则的话,可能会导致应用不能正常工作。
因为一般来说会话状态是存储在某个Web服务器实例的内存中的,所以对于负载均衡器来说,“会话粘滞”的特征非常重要。但是,如果某个Web服务器由于某种原因失败,那么在这个服务器上的会话状态就会全部丢失。负载均衡器能够检测到这个错误并且不再把请求转发到这个服务器,但是由于会话状态的丢失,可能会引发其他错误。因此,负载均衡器必须还要有另一个重要功能“会话失败转移”。
(5)会话失败转移
会话失败转移的实现机制是在某个Web服务器在收到某个客户端请求后,将会话对象备份到某个地方,以保证服务器失败的时候会话状态不会丢失。
如何备份会话数据也有不同的方案,比较主流的方案包括数据库方案和内存复制方案。
数据库方案就是在合适的时间让Web服务器将会话数据存储到数据库中。当失败转移发生时,另外可用的Web服务器实例接替失败的服务器,从数据库中将会话状态恢复加载进来。数据库方案的优点是:
●易于实现。将请求处理和会话备份分离开来使得集群更健壮、更易于管理。
●即使整个集群都失败了,会话数据仍然可以保存下来,可以在系统重启时继续使用。
数据库事务的缺点是比较消耗资源,当会话中的数据量较大时就会受到性能的限制。
内存复制方案是在备用服务器的内存中保存会话信息,而不是在数据库中进行持久化。和数据库方案相比,这种方案的性能较高,在原始服务器和备份服务器之间直接进行网络通讯的消耗很小,这种方案节省了会话数据“恢复”的阶段,因为会话信息已经在备份服务器的内存中了。
3.4 应用服务器基于J2EE的方案
介绍应用服务器的集群方案之前,有必要介绍一下J2EE,因为J2EE已经是一个分布式企业级应用开发与部署的事实标准,应用服务器的集群方案实际上是基于J2EE的某些标准实现的。
在J2EE中,业务逻辑被封装成可复用的组件,组件在分布式服务器的组件容器中运行,容器间通过相关的协议进行通讯,实现组件间的相互调用。所以,我们看到的网络上客户端或者Web服务器和应用服务器之间的通信过程,在J2EE实现上是组件之间的调用或者是组建对容器服务的调用。这种调用在J2EE的规范中分为两个阶段,一是对JNDI服务器访问,获得要调用的EJB组件的代理(EJB Stub),二是对EJB组件的调用。
对JNDI访问的集群方案分为共享全局JNDI树方案,独立的JNDI方案和具有高可用性的中央集中JNDI方案,每种方案都可以实现JNDI服务提供的高可用性。
而在对EJB组件的调用阶段,客户端实际上只能调用一个叫做“Stub”的本地对象,这个本地的“Stub”和远程的EJB有相同的接口,起到代理的作用。Stub知道如何通过RMI/IIOP协议在网络上找到真正的对象。对于在调用EJB Stub过程中的集群方案,主要有以下3种方式:
●Smart Stub:在Stub代码中加入特殊的行为,但是这些代码对于客户端而言又是透明的(客户端程序对这些代码一无所知),这些代码包含了一个可访问的目标服务器的列表,也能够检测到目标服务器的失败,同时还包含了很复杂的负载均衡和失败转移的逻辑来分发请求。
●IIOP运行库:负载均衡和失败转移的逻辑集成在IIOP运行库中,这样就使得Stub很小并且不掺杂其他代码。
●LSD(LocatiON Service Daemon):LSD的作用是EJB客户端的代理,在这种方案中,EJB客户端通过查找JNDI获取一个Stub,这个Stub中包含的路由信息指向LSD,而不是指向真正的拥有这个EJB的应用服务器。所以,LSD收到客户端的请求之后,根据其负载均衡和失败转移的逻辑将请求分发到不同的应用服务器实例。
3.5 数据库服务器方案
对于数据库服务器的集群方案,一般的方法有两种:一种是基于操作系统提供的集群软件,比如各种HA软件等;另一种是数据库软件本身提供的集群软件。
3.5.1 HA软件
HA软件的工作过程大致如下:
(1)在一个HA网络环境中,将网络分成TCP/IP网络和非TCP/IP网络。TCP/IP网络即应用客户端和服务器之间互相通*问的公共网,非TCP/IP网络是HA软件的私有网络,最简单的可以是一条“Heart-Beat”线,HA技术利用私有网络,对HA环境中的各节点进行监控替代TCP/IP的通讯路径。
(2)在一个HA网络上,各个节点上的TCP/IP网络、非TCP/IP网络会不断地发送并接收Keep-Alive消息,一旦向某个HA节点连续发送一定数量包都丢失后就可确认对方节点发生故障。当某个节点的主用网卡(Service Adapter)发生故障时,该节点的HA代理就会进行网卡切换,将原来Service Adapter的IP地址转移到新的Standby Adapter上,而Standby的地址转移到故障网卡上,同时进行网络上其他节点的ARP的刷新,这样就实现了网卡的可靠性保证。
(3)如果TCP/IP网络和非TCP/IP网络上的K-A全部丢失,则HA软件判断该节点发生故障,并产生资源接管,即共享磁盘陈列上的资源由备份节点接管;同时发生IP地址接管,即HA软件将故障节点的Service IP AddrESS转移到备份节点上,使网络上的Client仍然使用这个IP地址。同样发生应用接管,该应用在接管节点上自动重启,从而使系统能继续对外服务。
3.5.2 数据库集群软件
我们以ORACLE的真正应用集群(Real Application Cluster,RAC)软件为例,介绍数据库集群软件的主要特点。
(1)共享磁盘
与Single-Instance Oracle的存储方式最主要的不同之处在于RAC存储必须将所有RAC中数据文件存放在共享设备中,以便访问相同Database的Instance能够共享。同时,为了能够使每个Instance能够独立操作,也为了系统恢复时其他Instance能找到相关的操作痕迹,RAC数据库与单实例数据库在存储结构上还存在以下不同:
(1)每一个Instance都有自己的SGA(系统全局区)。
(2)每一个Instance都有自己的Background Process。
(3)每一个Instance都有自己的Redo Logs。
(4)每一个Instance都有自己的Undo表空间。
RAC也不能使用传统的文件系统,因为传统的文件系统不支持多系统的并行挂载,必须将文件存储在没有任何文件系统的裸设备或是支持多系统并发访问的文件系统中。
RAC操作要求在所有Instance中对控制共享资源的访问进行同步。RAC使用Global Resource Directory来记录Cluster Database中资源的使用信息,Global Cache Service(GCS)和Global Enqueue Service(GES)管理GRD中的信息。每个Instance在进行读写操作后,要由GCS或者GES按照严格的流程同步到其他Instance的Buffer中。
(2)缓存融合(Cache Fusion)
在RAC环境中,每个实例的内存结构和后台进程都是相同的,它们看起来像单一系统的一样。每个实例的SGA内有一个缓冲区,使用Cache Fusion技术,每个实例就像使用单一缓存一样使用集群实例的缓存来处理数据库。Cache Fusion技术可以最大限度地降低磁盘I/O,优化数据读写。节点之间会产生不小的网络通信和CPU的开销,因此双节点RAC的性能不会是单节点性能的两倍。
(3)透明应用切换
当RAC群集中的一个节点发生了故障,故障节点上所有保存在内存中运行的事务会丢失,Oracle将故障节点所拥有数据块的控制权限重新转交给正常节点,此过程称为全局缓存服务重置。在全局缓存服务重置发生时,RAC中所有服务器都会被冻结,所有应用程序将被挂起,GCS将不会响应群集中任何节点发出的请求;重置后,Oracle读取日志记录,确定并锁定需要恢复的页面,并执行回滚,此时数据库恢复可用。
3.6 应用软件的系统恢复方案
即使我们采取了前面所有的措施,也需要考虑在前面方案失败的情况下,即系统底层软件或者硬件发生错误而导致系统重启时的处理办法。
系统在重启前,系统中正在运行的有若干个流程,每个流程都处于不同的状态,应用软件的恢复方案就是要保证系统重启后,这些状态都能够恢复并自动运行到结束状态。为此,系统在运行过程中,所有消息和流程的状态都需要在修改的时候保存在数据库中,而不能仅仅保存在内存中,在System Recover的时候,需要检查数据库中所有没有到最终状态的消息和流程并进行后续处理。
CSMS在System Recover后实现过程如下:
(1)恢复所有消息:恢复CSMS发出的消息,恢复CSMS收到的消息。
(2)恢复申请流程。
(3)恢复注销流程。
(4)恢复停机相关流程。
(5)恢复审计流程。
(6)检查当天的生效广播。
(7)检查当天的同步。
(8)检查当月的同步。
系统恢复的关键就是要清楚每个流程的不同状态,比如在消息的恢复中,对于从CSMS发送出去的NP消息,状态包括:
●Init(初始)。
●Sending(发送中):该消息已经发送给SOA/LSMS,等待ACK。
●Wait Send(等待发送):ACK超时重发。
●Sent(发送成功):收到ACK信息。
●Complete(完成):收到该NP消息(请求/指示)的回复(响应/确认),并已经成功发送相应的ACK。
对于CSMS接收到的NP消息,状态包括:
●Init(初始)。
●Processing(处理中):表示系统正在处理该NP消息,主要包括将该NP消息保存入系统,根据该NP消息的类型,选择需要处理的方式。
●Processed(处理结束):表示系统已经处理结束该NP消息。
●Replying(正在发送回复消息):系统将组织好的NP回复消息已经发送到SOA/LSMS,该消息没有收到ACK。
●Wait Reply(等待回复):ACK超时等待重发。
●Complete(完成):系统收到该消息的ACK信息。
对于系统的其他恢复流程,方法类似不再赘述。
3.7 磁盘阵列的RAID和磁带库备份方案
系统高可靠性最后的考虑就是存储设备,以目前的技术而言,有效的存储方案不仅可以保证存储数据的安全可靠,还能够提高硬盘读写的速度,常用的技术就是RAID。
RAID技术按照级别可以分为RAID0,RAID1,RAID5等,不同级别RAID的存储效率不同,当硬盘出现故障时能够恢复的时间也不相同,具体技术可以参考相关技术文档。
为了进一步增加数据存储的保护功能,系统一般还会有其他介质的备份方案,如磁带库备份。磁盘阵列的数据按照一定的规则备份到磁带库上,一方面可以增加存储设备的容量,同时对数据保护又增加了一层保障。
4 结束语
作为号码携带集中管理系统的重要性能指标之一,高可用性具有十分重要的意义。因为高可用性需要考虑到系统的各个层面,相对也比较复杂。尤其在各种新的IT技术层出不穷的今天,研究各种高可用性技术,选择合适的高可用性技术方案,应作为系统架构设计者和相关技术研究人员的重点研究内容。本文仅作为抛砖引玉,对号码携带集中管理系统的各种高可用技术进行了简单的分析和总结,相信这些高可用性技术对类似系统的设计具有一定的参考意义。












 工商网监
工商网监
评论