 电子发烧友App
电子发烧友App


RFID(Radio Frequency Identif-ication)是一种利用射频通信实现非接触式自动识别的技术,是物联网的关键技术之一。RFID标签本身具有一定存储和计算能力,采用无线射频方式进行通信,具有体积小、寿命长、可重复使用等特点,从而被广泛应用于生产、物流、交通、运输、医疗、金融、防伪、跟踪、设备和资产管理、校园一卡通等领域。但是随着RFID应用的推广,其安全性也倍受关注。RFID的安全威胁主要来自标签和阅读器内部的安全威胁以及通信链路上的安全威胁[1]。
针对RFID系统通信链路上的安全问题,一些安全协议被提出,如Hash-Lock协议、随机化Hash-Lock协议、分布式RFID询问—应答协议、基于树型结构的安全协议等[2,3]。本文在对现有安全协议分析的基础上,对分组索引协议进行了改进,提出了最优分组索引的RFID安全协议,使标签的索引时间复杂度降低为。同时,通过采用随机数、Hash函数、标签与后端数据库共享密钥机制等,使协议具有隐私保护,防止跟踪、欺骗攻击和妥协攻击的能力,可以保证RFID系统的前向安全性和后向安全性。
1.相关工作
1.1 RFID系统及其安全性分析
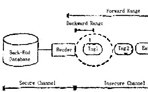
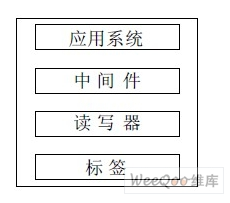
RFID系统一般由标签(Tag)、阅读器(Reader)和后端数据库3个基本部分构成,如图1所示。通常情况下,我们认为在阅读器与后端服务器之间的是安全信道,即不被攻击者窃听或篡改的;而在阅读器与标签之间的数据传输是开放的无线通信链路,所以为不安全信道,即其间发送的数据易被攻击者窃听或篡改。阅读器向标签发送信息的信道称之为前向信道,标签向阅读器发送信息的信道称之为反向信道[2,3]。
从图1所示的RFID系统模型可以看出,RFID安全威胁首先来自标签和阅读器本身的安全缺陷。由于成本所限,标签本身很难具备能够足以保证安全的能力。阅读器往往只能提供用户业务接口,而不能提供能够让用户自行提升安全性能的接口。
其次,RFID的数据通信链路是开放的无线通信链路,攻击者可以利用合法或非法的阅读器,直接与标签进行通信,监听标签和读写器间的数据交互,从而获取标签数据,通过其它技术手段和方法进一步获取合法用户的隐私信息,对标签实施破解和复制、跟踪、伪造、重传、拒绝服务、欺骗等攻击行为,威胁RFID系统的安全。
1.2 现有RFID安全协议分析
1.2.1 Hash-Lock协议
Hash-Lock协议是由Sarma等人提出的[4-6],后端数据库分配一个随机密钥key给标签,标签进行hash函数运算,得到metaID=H(key),并将其存储在标签中,然后锁定标签。此时标签只对通过metaID认证的阅读器产生响应,从而增强了无线通信链路和物理接触信道的安全性。
Hash-Lock协议流程如下:
(1)阅读器向标签发送Query认证请求;
(2)标签将metaID发送给标签阅读器;
(3)阅读器将metaID转发给后端数据库;
(4)后端数据库通过查询,如果找到与metaID相配的项,则将该项的(key,ID)发送给阅读器,其中ID为待认证标签的标识,否则,认证失败;
(5)阅读器将接收的后端数据库信息key发送至标签;
(6)标签验证metaID=H(key)是否成立,如果成立,则将其ID发送给阅读器;
(7)阅读器比较自标签接收到的ID是否与后端数据库发送过来的ID一致,如果一致,则认证通过;否则,认证失败。
从Hash-Lock协议的流程可以看出,由于后端数据库与阅读器之间为安全信道,攻击者不可能同时获得(key,ID)。如果攻击者向标签发送Query认证请求,可以窃取标签的metaID,进一步冒充合法标签,只能通过后端数据库获得key,而不能获得标签ID,所以不能通过标签认证。这样阻止了攻击者冒充合法标签与阅读器的通信,从而增强了无线通信链路和物理接触信道的安全性。但是由于标签的metaID没有使用动态更新机制,故容易被攻击者通过截获的metaID进行跟踪定位。同时在合法标签在认证的过程中,key和ID是明文传送的,攻击者如果全程窃听其认证过程,则有可能同时获得(key,ID),那么该协议的安全性将彻底瓦解。
1.2.2 随机Hash-Lock协议
为了克服Hash-Lock协议容易被攻击者跟踪的不足,Weis等人提出了随机Hash-Lock协议[6],每个标签不仅包含自身ID,还有一个随机数产生器。标签将随机数产生器产生的随机数R和ID一起用Hash函数加密,加密后的值为C=H(ID||R)。标签将C、R一起发送给阅读器,阅读器将获取的信息发给后端数据处理中心。后端数据库通过查询数据库中所有ID,看其中有没有一个IDk(1≤k≤n),使得H(ID||R)=C成立,如果有,则此认证通过,并将IDk发送给标签;标签收到IDk后验证与标签本身的ID是否相等,如果相等,则认证通过。
该协议通过采用随机数,使得每次对阅读器的应答C=H(ID||R)都不相同,从而解决了标签被跟踪的问题。但是在认证过程中仍然以明码的方式传递ID,若被攻击者截获,协议的安全性将不复存在。
1.2.3 分布式RFID询问—应答协议
Rhee等人提了一种适用于分布式数据库环境的RFID认证协议,它是典型的询问-应答型双向认证协议[7]。该协议的流程如下:
(1)阅读器生成一随机数RR,向标签发送Qu-ery认证请求,并将RR发送给标签;
(2)标签生成一随机数RT,计算H(ID||RR||RT),并将其和RT一起发送给阅读器;
(3)阅读器将(H(ID||RR||RT),RR,RT)发给后端数据库;
(4)后端数据库检查是否有某个IDj(1≤j ≤n),使得(H(IDj||RR||RT)=(H(ID||RR||RT)成立,如果有,则认证通过,并将H(IDj||RT)发送给阅读器;
(5)标签验证H(IDj||RT)和H(ID||RT)是否相同,如相同,则认证通过。
该协议在双向认证过程中,除了阅读器生成的随机数RR为明文传输,其它均为密文传输,故其在安全方面没有存在明显的漏洞。但是执行一次认证过程,标签需要进行两次Hash运算,标签电路中需要集成随机数发生器和Hash函数模块,因此不适合于低成本RFID系统。
1.2.4 基于树型结构的SPA安全协议
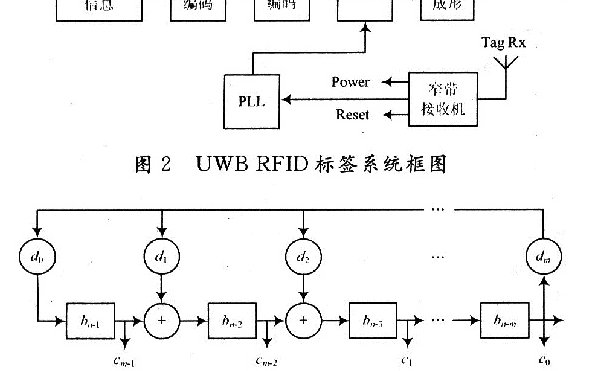
考察前面讨论几种协议的索引效率,后端数据库为了完成对标签的一次认证,最大的索引次数为n,即索引的时间复杂度均为O(n),这样的索引效率在大规模RFID系统中是难以接受的。针对上述协议索引效率低下的问题,Molnar和Wagner最先提出了基于树型结构的RFID安全协议[8]。该协议的基本思想是构造一颗树型结构的密码组来提高其在大规模数据中的索引效率。在树型结构中,每个树节点都有一个密码值,所有的标签都在叶子节点上。针对树上的任何一个节点,从树根到叶子节点都有唯一的路径,且其密码组就是这个路径上各个叶子节点的密码值组合。如图2所示,标签T1的密码组为(k0,k1,1,k2,1,k3,1),标签T2的密码组为(k0,k1,2,k2,4,k3,8)。
此协议虽然大大的提高了其搜索效率,使其索引的时间复杂度降为O(log n),但是其中任意两个标签至少共享了一个密码值,因而存在明显的漏洞。攻击者只要截获任意一个标签的密码值,就可以知道其上层标签的密码值和相邻节点标签的共享密码值,导致严重的安全问题。
1.2.5 基于分组索引的RFID安全协议
由于树型结构的RFID协议存在严重的安全性问题,而非树型结构的RFID安全协议又存在索引效率低下的问题,一些研发团队开始研究既能够保证协议安全,又可以提高索引效率的安全协议。付小丽提出了分组索引的RFID安全协议[9],此协议在开始前要对RFID后端系统和标签进行初始化。分组索引就是将后端数据库中储存的n个标签均分成m组,每个组有n/m个标签,其中同一个组的标签共享一个索引码IID,而每个标签含有一个自己的安全密码SID,并且每个SID是不相同的。协议的主要流程如下:
(1)阅读器生成一随机数RR,向标签发送询问请求,并将RR发送给标签。
(2)标签接收到询问请求后,生成一个随机数RT,计算C=h(SID||RR||RT),并将信息C、IID、RT发送给阅读器。
(3)阅读器接收到信息C、IID、RT后,将其转发送给后端数据库。
(4)后端数据库接收到信息后,查询出所有索引为IID的标签,然后再在这些标签中搜索是否有一个标签的SIDj使得h(SIDj||RR||RT)=C成立,如果有,则通过认证;否则,认证失败。若通过认证,则将SIDj更新为h(SIDj),并将h(SIDj||RT)发送给标签。
(5)标签验证h(SIDj||RT)=h(SID||RT)是否成立,如果成立,则认证通过,且将SID更新为h(SID)。
在该协议中,所有传送的信息除了IID外都进行了加密处理,而IID不是哪个标签独有的,攻击者仅知道IID无法确定具体是哪个标签;同时,在认证过程中所传递的密文C=h(SID||RR||RT)和h(SIDj)每次认证都是不同的,并采用了SID更新机制,攻击者根据当前SIDt很难推导出前面的SIDt-1,所以可以保证其前向安全性。但攻击者可根据当前SIDt推导出以后的SIDt+1,所以不能保证其后向安全性。
2.最优分组索引的RFID安全协议
在1.2.5描述中基于分组索引的RFID安全协议,将索引的时间复杂度减少为O(m+n/m),提高了索引效率。但是该协议并没有提到具体如何分组,才能使时间复杂度降至最低,同时存在后向安全性问题。本文针对这些不足,提出了最优分组索引的RFID安全协议,从而进一步提高了索引效率,同时通过标签和后端数据库共享密码key解决了其后向安全问题。
2.1 最优分组索引原理
分组索引的过程是在m个分组中先找到索引码为IID的标签所在的组,然后在该组中n/m个标签中找到特定的标签SID,故整个过程中后端数据索引的次数为m+n/m,如果使之达到最小,则其时间复杂度最低,此时为最优分组索引。
m为整数,取整,所以,最优分组索引的时间复杂度为。例如,后端数据库中总共存有10000个标签,我们把这些标签均分成100个组,则每组有100个标签,同时,每组共享一个索引码IID。在整个索引的过程中,前100次是找到索引码为IID的那个组,后100次是在同一索引码IID的标签中找到目标标签,最多需要索引200次就可以寻找到目标标签。
2.2 最优分组索引的安全协议流程
最优分组索引将后端数据库中储存的n个标签均分成组,每个组有int(n/m)个标签。其中每个组的标签共享一个索引码IID,且包含一个自己的安全密码SID和一个与后端数据库的共享密码key,并且每个SID和key是不相同的。协议流程如图3所示。
协议执行过程描述如下:
(1)阅读器生成一随机数RR,向标签发送询问请求,并将RR发送给标签;
(2)标签接收到询问请求后,生成一个随机数RT,计算C=h(SID||RR||RT),并将信息C、IID、RT发送给阅读器;
(3)阅读器接收到信息C、IID、RT后,将其与RR转发送给后端数据库;
(4)后端数据库接收到信息后,查询出所有索引为IID的标签,然后再在这些标签中搜索是否有一个标签的SIDj使得h(SIDj||RR||RT)=C成立,如果有,则通过认证;否则,认证失败。若通过认证,则将SIDj更新为h(SIDj||key),并将h(SIDj||RT)发送给标签。
(5)标签验证h(SIDj||RT)=h(SID||RT)是否成立,如果成立,则认证通过,且将SID更新为h(SID||key)。
3.分析
3.1 安全分析
(1)隐私保护:在本协议中,所有传送的信息除了IID、随机数RR和RT以外,都进行了加密处理,而IID不是某一个标签独有的,所以不会暴露用户隐私。同时hash函数是单向的,因此攻击者很难根据hash值得出标签的SID。
(2)跟踪:产生被跟踪的根本原因是标签发送给阅读器的信息含有一些固定的信息,且这些信息对于标签是唯一的,从而使得攻击者很容易根据标签发送的信息跟踪标签。而在本协议中,由于RR和RT每次都不相同,故标签每次发送的加密信息C=h(SID||RR||RT)也是不一样的,因此跟踪信息C不可能。而发送的信息中,虽然IID是明文,但它不是某个标签独有的,因此攻击者根据IID无法确定某个具体的标签,进而不能达到跟踪的目的。
(3)欺骗攻击:在复制或欺骗攻击中,攻击者会先向标签发送询问信息并记录标签返回的信息。然后攻击者将标签返回的信息发送给阅读器以达到冒充合法标签进行欺骗的目的。在本协议的每次认证过程中,标签和阅读器都产生一个随机数,并通过hash函数形成密文C=h(SID||RR||RT)。攻击者不可能事先知道当前认证过程中阅读器生成的随机数RR,而由他自己询问标签所产生的C和RR在后端数据库是不能通过认证的,因此无法使用欺骗攻击。
(4)前向安全:如果攻击者在t时刻攻破了秘密信息C=h(SIDt||RR||RT),就可以获得当前时刻标签的SIDt。本协议在每次认证成功后,都更新了SID,所以攻击者根据当前SIDt不能推导出前面的SIDt-1,从而保证了前向安全性。
(5)后向安全:如果攻击者获得当前时刻标签的SIDt,但本协议在认证的过程中,攻击者无论从明文或者密文中都无法获得标签与数据库的共享密码key,所以攻击者根据当前SIDt不能推导出下一次标签的SIDt+1=h(SIDt||key),从而保证了后向安全性。
(6)妥协攻击:在本协议中,虽然多个标签共享一个IID,但是这个IID本身就是明文发送的,攻击者并不能据此判定具体是哪个标签。同时,如果某个标签的SID泄漏后,攻击者也不能据此得到其他标签的SID。因此,本协议不会发生妥协攻击。
3.2 协议比较分析
本文安全协议与其它安全协议的性能比较见表1。从表1的比较中可以看出,本文协议除了索引效率仅次于基于树型的SPA协议外,各项性能指标均优于其它安全协议。
4.结束语
本文讨论了已有的几种RFID协议,分析了这些协议中存在的安全缺陷和漏洞。针对基于分组索引的RFID安全协议所存在的问题,提出了最优分组方案,将标签分成组,利用同组同索引码的方法,将其时间复杂度降为,同时,采用随机数、Hash函数、标签与后端数据库共享密钥机制等,解决了RFID中的隐私保护、跟踪、欺骗攻击、前向安全、后向安全、妥协攻击等安全性问题。
本协议的不足之处在于,标签的SID更新必须和后台数据库同步,需要对数据一致性问题展开进一步研究。
责任编辑:ct














 工商网监
工商网监
评论