 电子发烧友App
电子发烧友App



浅压缩又称夹层压缩,是一种视频压缩级别,可以有效降低视频带宽,并能保持视频整体质量,压缩比通常为2:1到8:1。根据这一压缩比,4K、8K节目都可以用10G接口进行传输,这极大降低了网络设备成本。LiveVideoStackCon 2023上海站邀请到杨海涛老师为我们介绍AVS标准组以及上海海思等硬件厂商在无损质量等级视频浅压缩领域的实践与探索。
文/杨海涛
非常荣幸能够有机会和大家交流AVS最新制定的视频压缩标准——感知无损压缩。顾名思义,感知无损强调压缩图像的质量达到无损等级。最开始时起名是轻压缩,与重压缩相对,主要强调在编解码的过程中相对较低的计算复杂度。之后从效果考虑,又将其称为浅压缩,相对于深压缩,浅压缩更加强调较低的压缩比。在标准即将定稿时,AVS标准组内达成一致——PLC,即感知无损压缩,强调压缩视频的质量等级。 今天我将会从应用与需求、AVS PLC标准概述、高性能并行处理机制、底层编码工具、CVR码控与质量优化以及未来展望六个部分展开介绍。
-01-
应用与需求

浅压缩应用的场景是显示接口和内容制作。这两个场景平时H.265以及AVS系列压缩是没有涉及的。显示接口包括HDMI、DP等接口,包括有线无线的传输,它们共同的特点是信道的带宽非常充裕,随之而来要求无损的画质。在这些接口上传输的内容都达到了数字无损的质量等级,没有任何的失真。 既然质量这么好,为什么还要压缩呢? 以DP1.4标准为例,其带宽是32Gbps,在这样的带宽下,如果不做任何的压缩直接传输信号,可以传一路4K60帧每秒的数据。但如果做一个8K60帧每秒的数据传输,这样的物理信道没有办法承载。
面对这些问题,一种办法是将物理信道继续拓宽,将线加粗,但这种方法并不是特别的方便,线加粗了可能就没有办法弯折。另一个办法就是去进行压缩,减低物理带宽的要求,这就是接口压缩。在内容制作方面,通常前端的专业摄像机会采集yuv或者rgb格式的信号,传递到媒体工作站以后再编辑内容,所有的工作都在磁盘文件上进行,磁盘的读写是一个非常大的瓶颈。目前解决的办法是在信号到达媒体工作站以后转化成一种非常方便编辑的格式,这种格式要求必须是单张图片的编解码,而不允许图像间的预测编码。这样每张图片编辑之后,内容可以直接进行储存。
在技术需求上浅压缩与深压缩有很大的区别。浅压缩的内容不仅直接会在显示屏上显示,还会在后台进行分发域编码,从而作为母本使用。其色彩格式通常都是yuv444、rgb等非常高质量的格式。 浅压缩的色彩位深在标准里面是支持8-16比特。同时支持信号无损和视觉无损。浅压缩典型的压缩比是3倍到10倍,这与视频分发有显著的不同。在进行H.265编码时,典型的码率,例如1080p,通常会在2兆到4兆之间,这已经是非常高质量的视频了。典型压缩比在200:1,甚至500:1,这是所谓的深压缩或者重压缩。从这里就可以明显的看到使用浅压缩,即便压缩完其码率也会达到百兆或者千兆的量级。
另一个非常大的区别在于浅压缩要求非常低的延迟,特别是接口的压缩要求,做到行级的延迟。浅压缩还要求高并行度。浅压缩信号规格非常高,这样的内容做信号做实时处理一定要并行。还有一点值得一提,浅压缩因为要考虑成本以及在特定场景是否能真正使用,所以在标准制定的过程中,自身就带有码控算法。随机访问刚刚已经提到,不管是制作域还是接口,都要求单张图片的随机存取。低复杂度在显示接口和内容制作两个领域有一点不同。内容制作对于成本的要求相对宽松,因为其编解码器实现很多是基于工作站的软件实现。但是工作接口的标准实现最终是在芯片中,而芯片会广泛的嵌入到各种消费设备中,对于成本的约束非常紧,在标准指定中就需要控制算法的复杂度。在内容制作中还有一个特殊的要求,在多次迭代编码的过程中不引入显著的质量劣化。
-02-
AVS PLC标准概述
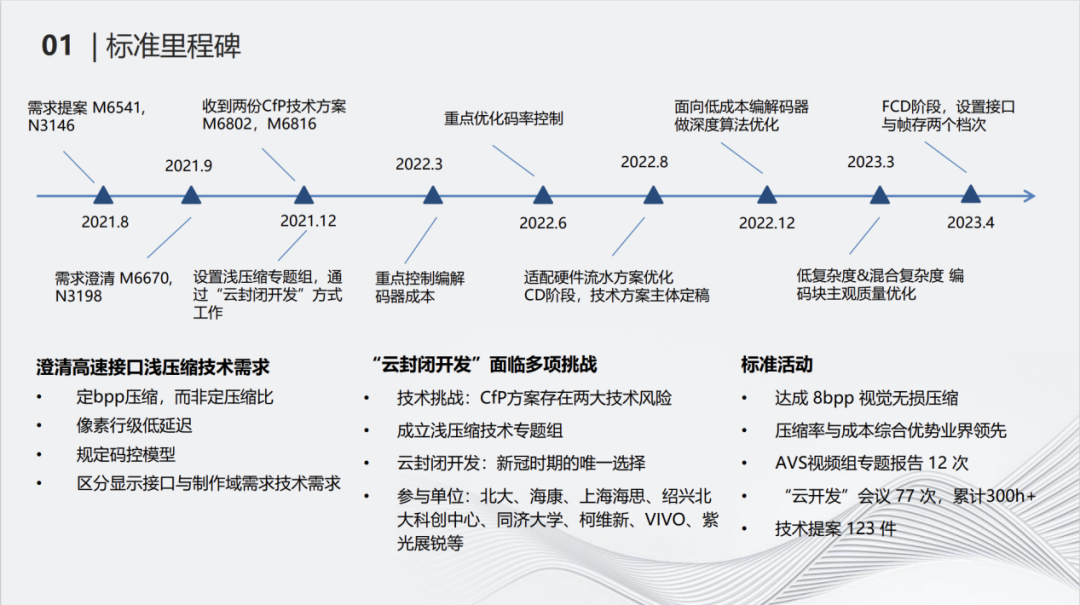
2021年8月的会议上,我们正式提出了标准的需求。AVS标准组之前没有为浅压缩制定过标准,国内也没有相应的标准。所以在制定标准的时候,仔细地讨论了不同应用的不同需求,提出了定bpp压缩而非定比压缩、像素行级地延迟、规定码控模型和区分显示接口与制作域需求技术需求四个方面的需求。 之后我们收到了两份CfP技术方案,这两个方案都是很好的尝试,但是在评估过程中发现了一些问题。首先我们提出的标准和码控是强结合的,但是收到的方案中并没有码控的部分。另外,方案应受到硬件的约束,以便在低成本的接口芯片中实现。在发现这些问题之后,我们成立了浅压缩专题组,通过“云封闭开发”的方式工作。 标准的制定可以分为如下几个阶段: 2022年3月,此时的重点在控制边解码器成本。6月份,我们完善了基础的码控算法,提供了一个CBR的码控模型。之后更进一步优化硬件流水方案。 在2022年年底的时候,再一次面向低成本进行一次收敛,成为业界最优的低成本方案。 2023年的3月份,针对扩展测试所发现的质量问题又进行了一轮技术的研讨和收敛。最后在4月,完成了标准制定并发布了FCD版本。

质量评估采用非常高质量的图片,包括RGB和YUV444两种格式,主要覆盖的位深为8比特和10比特,16比特也在后期的拓展中进行了非常充分的评估。 内容分为两类,一类是摄像机采集的自然内容,一类是计算机生成内容。具体的评估参考了ISO29170-2标准。该标准包含两部分:一部分是交替闪烁法,一部分是并排对比法。 交替闪烁法是指将编码前和编码后的图像,按照8赫兹交替播放,如果能看到任何闪烁,就说明图像质量不过关。
这是一个非常严格标准。在实际使用过程中,并没有条件去看到编码前的图像,所以并排对比法更为常用。该方法是在两个屏幕或者一个屏幕分为两半,展示相同的部分,同时指出失真的地方,即交替闪烁法闪烁的地方,让大家观看。如果大家看不到,则通过测试。在测试时对测试设备有一定的要求。首先要确认显示器、播放设备支持高比特位深,还要保证显示接口未对传输图像做任何处理,如果还不放心可以使用灰阶样图验证是否具有高位深显示能力。 在实际操作时发现,不管是8比特的显示器还是10比特的显示器,在发生失真的时候,交替闪烁法测试其失真强度都是一致的,所以在后续标准制定过程中,为了简化并且让更多的单位参与进来,就使用8比特的显示器进行所有的测试。
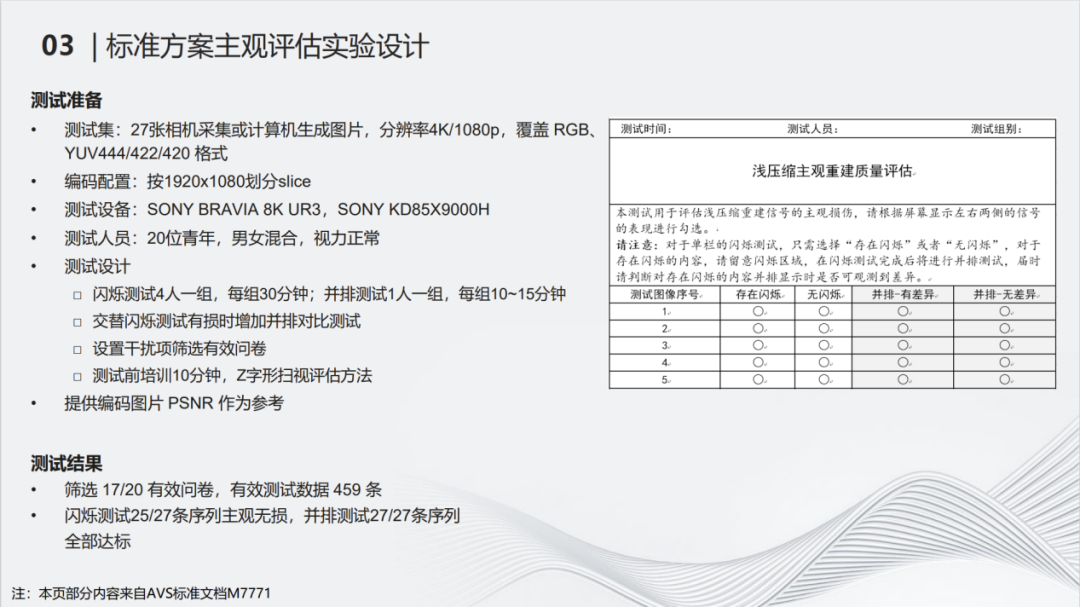
今年4月份AVS标准组在鹏城实验室组织了一场非常详细的测试:使用27张测试图片,包括相机采集以及计算机生成的图片,覆盖了RGB、YUV444等多种格式。经过数据的筛选和分析,最终27条内容中25条通过了闪烁测试,27条全部通过了并排对比测试。
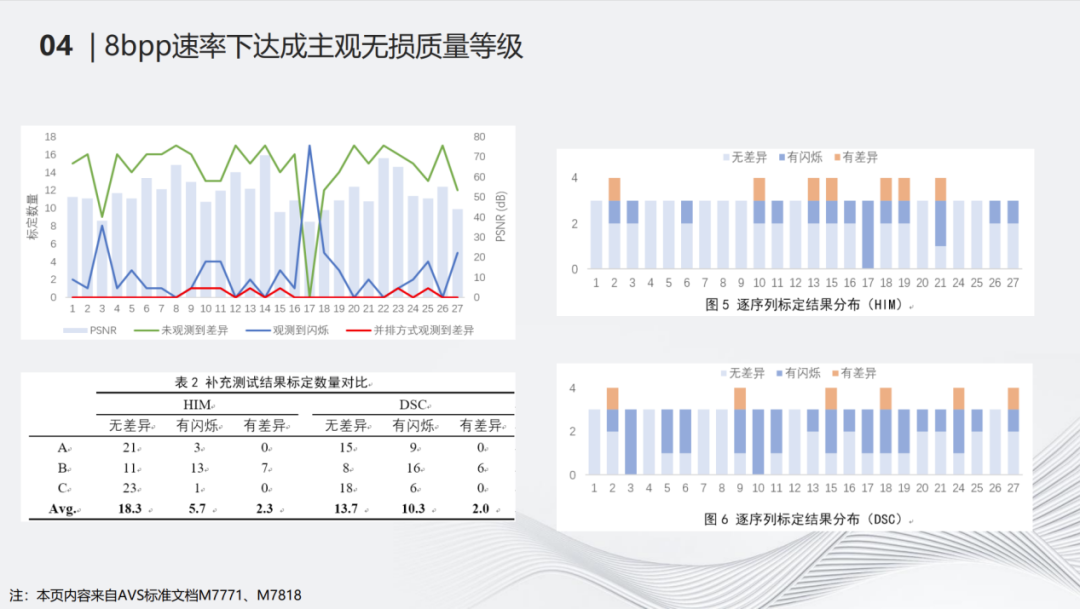
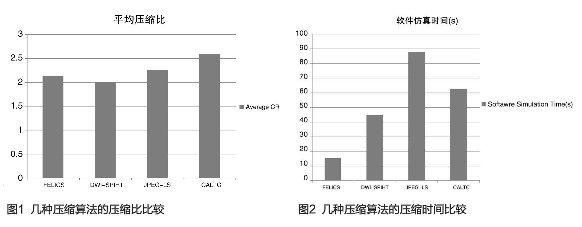
除了对PLC标准方案做通过性画质评估,也和业界已有的DSC规范进行了对比评估,评估结果如左下角的表格所示。
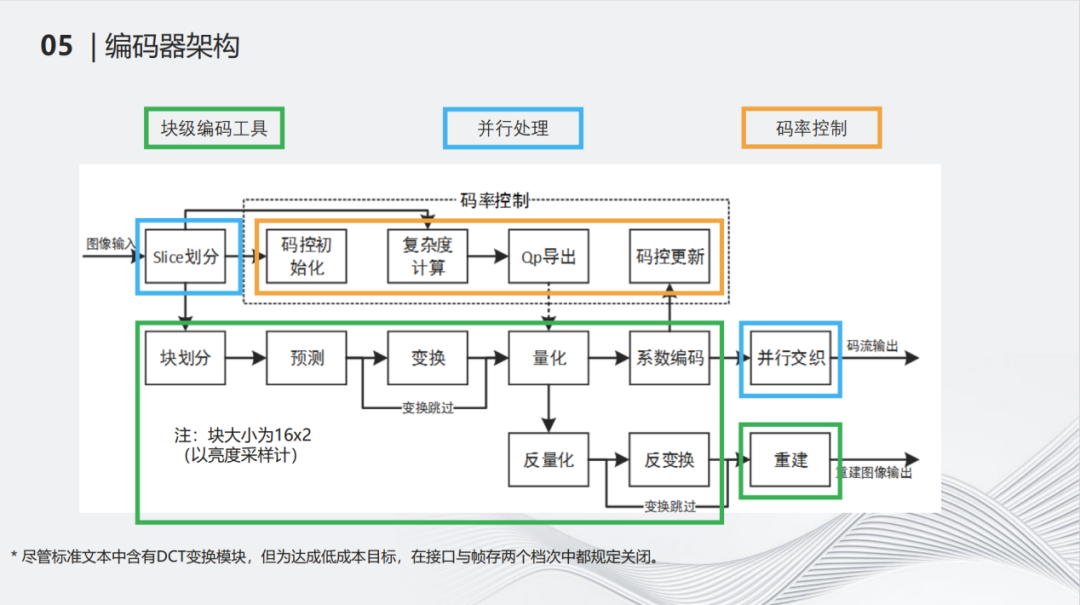
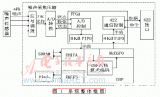
这是标准的架构图。整张图像传输进来以后,会进行Slice划分。由于块的高度决定缓存的行数,所以将其划分成16*2大小的CU。另外,尽管标准文本中含有DCT变换模块,但为达成低成本目标,在接口与帧存两个档次中都关闭了DCT。
-03-
高性能并行处理机制
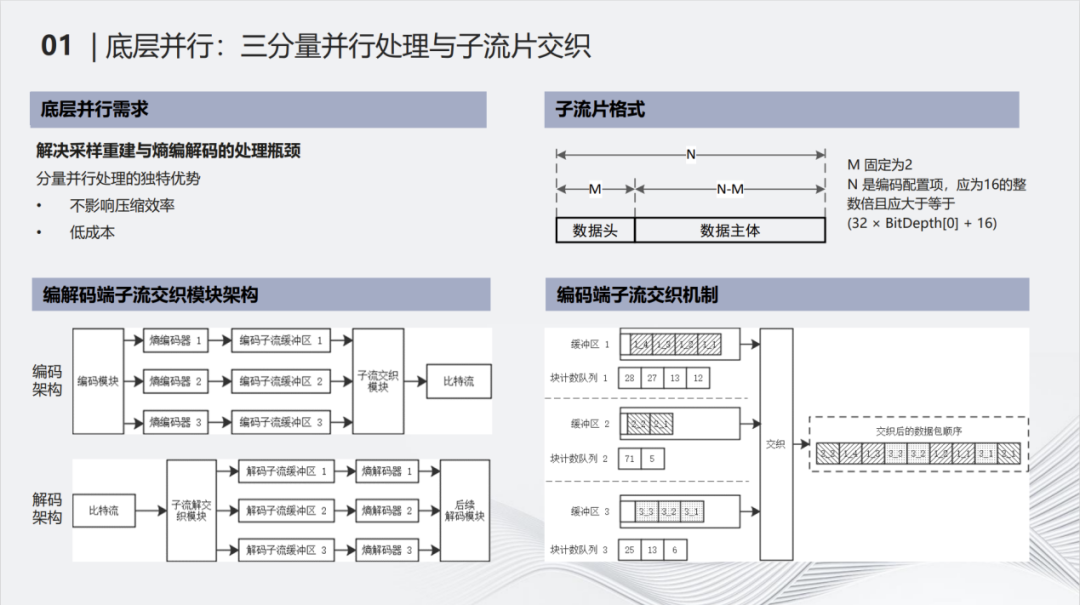
底层并行是指三个分量并行进行熵编码和熵解码的操作。 熵编码是视频编解码过程中的瓶颈所在,为了解决这样的瓶颈问题,真正达到8k 60帧或者120帧的实时编解码,就需要对各个分量进行并行处理。将每个分量的压缩码流独立打包,使得每个分量都有自己独立的熵编码器和熵解码器。再通过子流交织的操作,保证三个分量是同步的。
右上角是子流片的格式。子流片的大小和处理图像的位深有关。以16*2大小的CU为例,10比特的内容,乘以32,原始数值就是320比特。再加上16比特的头开销。在数据payload前会加一个二比特的数据头,这个数据头会说明子流片属于哪个YUV的分量,在解码的过程中就可以进行区分。在编码端输入图像之后,会输出YUV三个分量的语法元素。语法元素在等待进行熵编码的操作时,会分发到各自所属的熵编码器,编码完之后会打成子流片。然后放在三个分量各自的位流缓冲区里,在统一机制下,进行子流片的交织,形成单一的码流,传递到解码端,从而保证分量的同步,而不出现任何错误。解码端在接收到单一的码流之后,首先要做的事情就是解交织,解交织之后,把三个分量对应的子流片分别放到各自的位置缓冲区里解码,得到最终的重建的像素。
YUV的三个分量或者RGB编程YCOCG之后其信号复杂度是不同的。Y分量比较难编码,一个编码块编码后产生的Y分量与UV分量的子流片数量可能极不均衡。采用编码端的子流交织机制可保证解码端同时拿到一个编码块的三个分量的编码数据。编码端会根据YUV三个分量的复杂度进行缓冲,保证解码端不需要再做任何额外的缓冲。
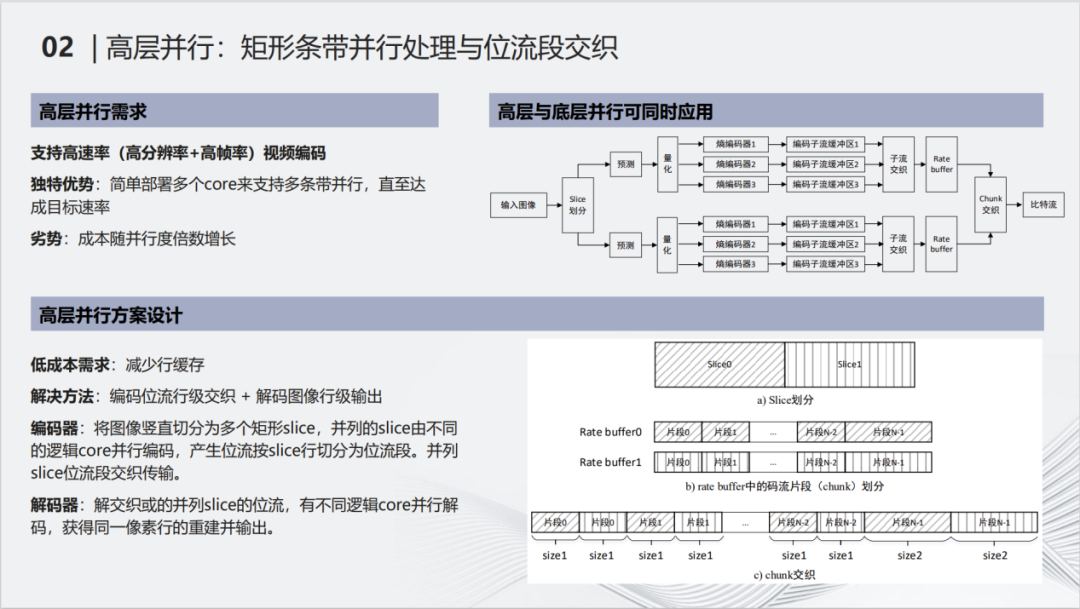
高层并行更好理解,指拿到图像之后,划成矩形的条带——slice。各个slice之间可以进行并行编码,本质上是一个可伸缩的架构,随着视频规格的上升,例如从4k到8k,从30帧到60帧,想支持更高的规格,在硬件设计时只要添加更多的处理单元或者硬件核即可。 需要特别提出,条带的划分只有在水平方向并排排列的条带才可以进行并行处理。核心原因在于硬件处理图像时是按照一行一行像素进行处理的。解码端需要保证解码完一行或者两行之后立刻进行输出。
这一行可能分属于不同的slice,例如slice0和slice1,这个时候就需要一些特殊的操作。简单的方法也有,每一行打一个slice,这样的方法当然可以,但是slice之间是没有空间预测的,压缩效率非常差,所以设置一个较大的slice仍然是必要的。Slice0 和slice1每编码完一个高度为2的块行,会进行码流的交织。接收端需要设置slice块行数据的位流缓冲区,这样才能保证同时将slice0和slice1的第1行数据送到不同的硬件核上进行解码。这是一个和硬件耦合非常紧密的设计。
-04-
底层编码工具
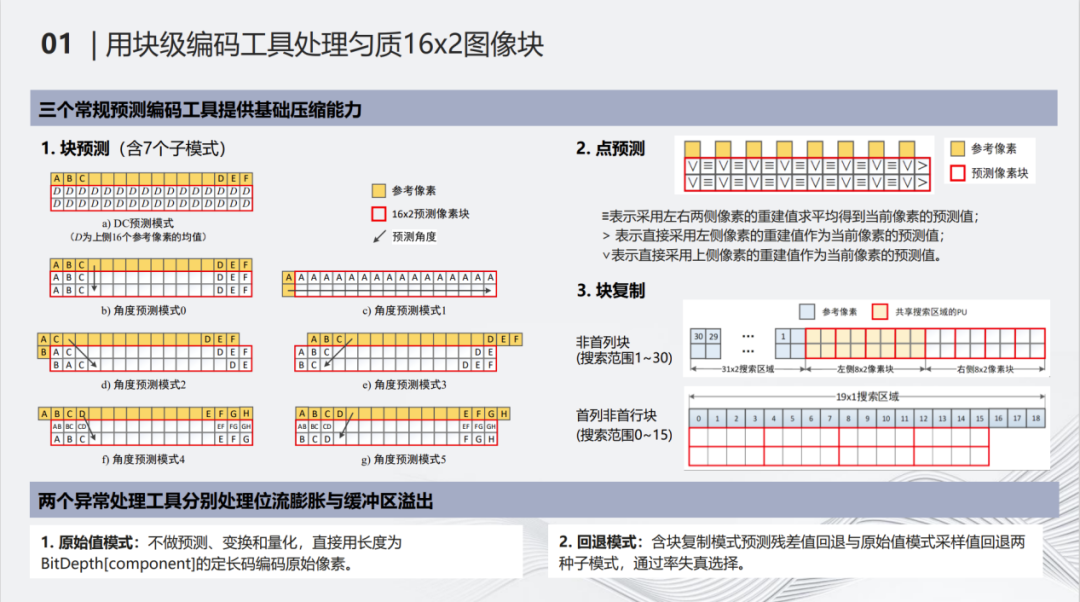
底层工具可以简单的分为两类,一类是常规的编码工具,一类是异常处理工具。 常规编码工具,主要用于提供基础的压缩效率。出于成本的考虑,我们选择了三种工具。首先块预测主要依靠上面一行的像素,以及左边重建的像素,进行方向性的角度预测。其优势在于具有非常高的并行度,框内所有像素都可以同时获得其预测值,但是在纹理变化区域就没有办法进行很好的适配。右上角的点预测则可以很好地处理这种复杂纹理的图像。通过在每一个像素点上进行独立的预测、残差编码和重建,第1个像素点的重建会被用作相邻的第2个像素点的预测。该方式的预测效率是最高的,但有一个非常致命的问题,其硬件性能非常差。为此我们进行了一些约束,在一个块所有像素进行处理时,保证其需要串行处理的像素数量最大为3。
首先进行偶数列的预测,使用黄色的像素点预测块里面第1行的像素。在获得第1行像素之后,再继续向下预测以获得第2行的像素。完成这两步之后利用左右的水平方向的预测进行所有奇数列像素点的预测和编码。最后一个工具是块复制,主要用于处理屏幕内容。面向显示的压缩所处理很多内容都是由计算机生成的,比如办公软件word、Excel等文档中的文字、表格边框等。这些内容的典型特征是有非常锐利的边缘以及非常丰富的高频,重复性也非常强。通过以2×2为块单位的块复制能够达到很好的效果,在典型内容上能够获得远高于块预测和点预测的压缩效率。三个常规工具组合在一起,提供了非常好的基础压缩效率支撑。 两个异常处理工具,第一个是原始值模式。这个模式就是 PCM模式,主要为了防止编码膨胀。
在一些特殊的情况下预测编码,反而会使得编码之后的比特数高于直接编码原始值的比特数,一旦发现这种情况就需要退回到原始值的编码。第二个模式是回退模式。因为我们耦合了一个CBR码控,码控的核心是确定QP,确定QP之后编码出来的比特其实与预计的目标还是有上下浮动的情况,即码控不可能做到比特级的精准。这就需要有一种机制能够强制地将压缩比特控制在一个阈值之下,避免buffer的溢出。这个回退模式更多的进行兜底处理。

在实践过程中,我们发现16x2块级的预测并不能够非常好的适配纹理内容突变的场景。通过不断探索,我们发现将预测做到子块级可以很好的解决上述的问题。 为此我们开发了相应的几个算法:第一个算法是直接划分更小的子块,每个子块独立进行DC预测,这样的扩展确实能够减轻主观失真。第二个算法是子块DC补偿。
一个编码完成后,如果它的平坦区域编码效果不理想,可以通过这样的补救措施,在4×2或者8×1的级别上额外的传输原始值与当前重建值的差值,在补偿之后效果明显提高,编码质量非常好。 在很多典型图像里,文字之间背景是平坦的,但文字之内是非常复杂的,通常会采用块复制的方式处理。如果文字间隔能够使用空间预测,例如竖直方向的预测等,可以显著改善文字之间水平方向的条状失真。右上角的子块插值预测是为了处理一种比较少见但对画质影响很大的情况。
如果当前编码块的所有预测方法都已失效,例如当前编码块是一个平坦的块,但无论是上方还是左方的参考都是噪声,没有办法获得有效的预测值,则可能在这个平坦区域带来人眼可察觉的编码失真。这个问题可以通过直接编码整个块的DC值,再去编码块里每个像素相对于DC值的差值。该模式下,当前图像块来是完全独立编码的,不依赖左侧和上方的像素。所有模式结合起来,在一些非常小的、非常容易忽略的地方,甚至特别敏感的平坦区,都会有很好的处理效果。
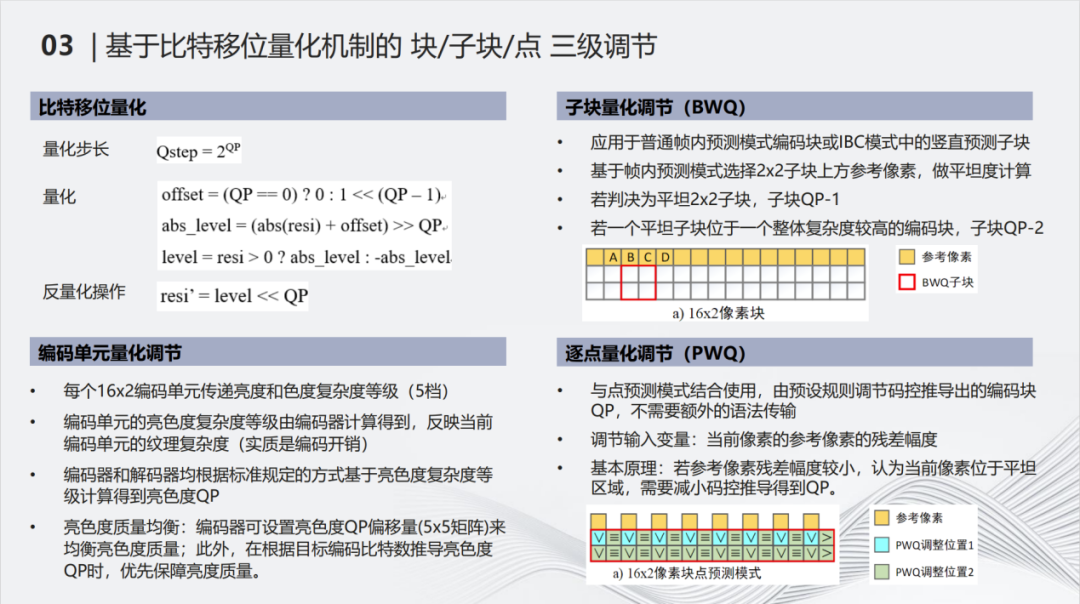
无论预测模式多差,如果能够用非常小的量化补偿进行处理,其主观效果都可以接受,无非多花一点比特而已。但这就对量化机制提出了要求,需要其支撑非常精细的调节。 与一般标准不同的是,我们的标准基于右移量化。以AVS为例,AVS2和AVS3是进行分数量化。QP每增加8,量化步长就会加倍。精细的调节一个量化操作,通常包含一个乘法和一个右移的操作。频繁的进行高性能处理,对于硬件来说是一个很大的问题。所以我们取消了乘法操作,把量化简单的化简为右移。没有乘法也就意味着量化步长就是不断q step加倍的过程。量化是分不同等级的。CU级量化会根据块的复杂度在编码端进行分析。分别分析亮度和色度,来划分其属于哪一个复杂度等级,从而推导出对应的QP。
QP的推导过程是编、解码端同时进行的,这与传统编解码标准不同。传统的分发域重压缩标准,QP会在编码端推导出来之后再传递给解码端。除了CU的基础QP,在每一个2×2的子块,还可以进行额外的调节。根据当前此块上参考的纹理复杂度分析,如果判断当前子块比较平坦,会额外在CU QP基础上进行减1或者减2的操作,用更高质量进行编码;如果子块比较复杂,就维持CU QP不变。 除了子块量化,还有逐点量化,逐点量化是跟上文提到的点预测组合应用的。如果一个点的残差比较大,就说明这个区域是难以预测的,QP需要相对分配的较大一点,反之则说明区域比较好预测,是一个平坦区域。平坦区域需要进行重点的保护,需要将QP进一步的减小。

系数编码的核心概念是在每个系数分组上进行半定长编码。在高性能处理中是没有办法进行变长编码的,处理性能不符合要求。半定长编码会在一个系数组中所包含的残差中寻找其公共码长,并在编码块的头信息里面传递。用同样的长度对系数组内所有残差做定长编码,对熵编码的性能有非常大的提升。

RDO计算是编码侧一种操作。这里需要特别指出,由于采用的是CBR码控,要保证buffer不溢出,在选择RDO的过程中更加倾向于低比特。RGB的内容会转化成YCoCg之后再进行编码。 在高层并行时,矩形slice需要进行并行处理。图像的宽和高都要和CU的16×2进行对齐。常见的对齐方法是大家所熟悉的padding。Padding有两种方法,一种是在图像的右侧进行,其优点在于复杂度较低,但编码可能会不均衡。第二种方法是在每个slice的右侧做,可以解决编码不均衡的问题,但同时会面临另外一个问题——每一个硬件的核心都需要进行填充,会带来额外的成本增加。标准中同时支持了两种padding的方式,大家可以按需选择。
-05-
CBR码控与质量优化
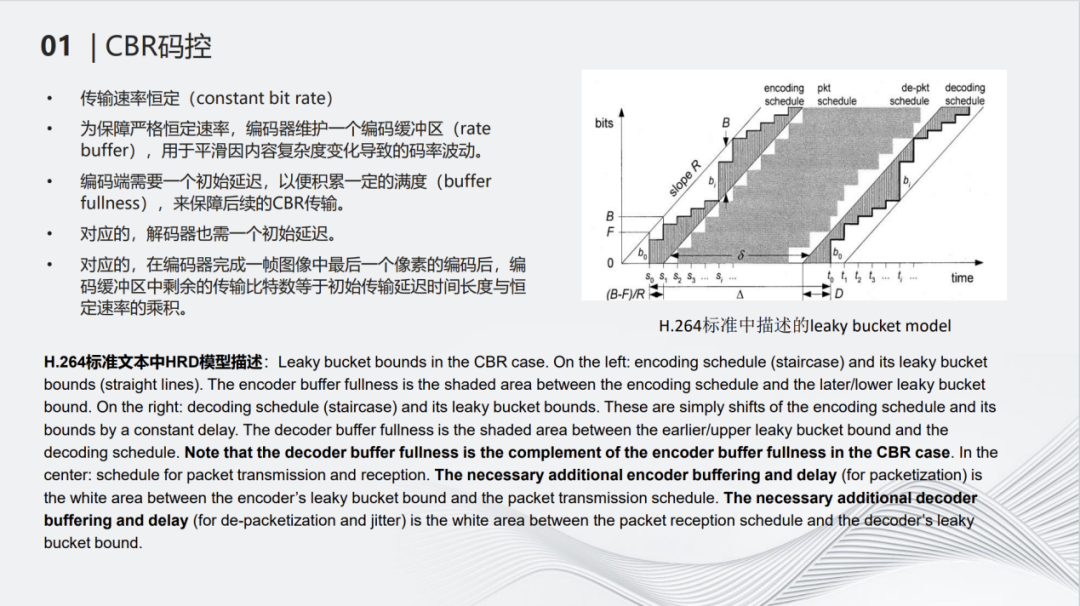
上图是H.264标准中描述的漏桶模型,编码一个块时会把它的编码比特输出到码控buffer里通过constant bit rate平滑处理。由于块的复杂度不断变化,有复杂的噪声区,也有很简单的平坦区,所以在定速率处理完每个块时,真正进入到buffer的码率是波动的。
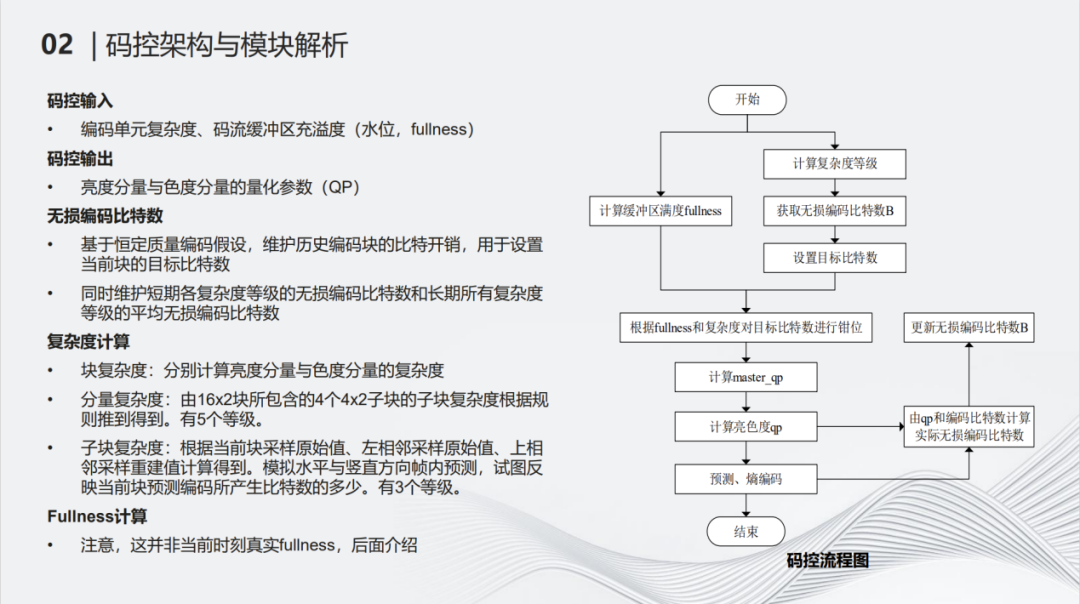
码控有两个主要的输入,第一个输入是当前块儿到底是复杂还是简单?第二个输入是buffer目前到底是空还是满?码控的输出是亮度分量与色度分量的QP。核心思想在于判断图像编码中一个编码块之前所有块整体是好编还是难编。当然只有这些信息是不够的,在前面所有块处理完之后,会对块的复杂度做一个简单的分类,将其分为5个复杂度等级。每一个等级会有对应预测编码比特,这样就有了较为充分的信息,从而对当前的块进行更好的码率规划以及码率分配。
码控对于最终的压缩效率影响可以达到10%甚至20%多,码控相对应也要进行一些调优。最开始分析块时,决定当前块是复杂还是简单。如何定义复杂与简单,并不是仅仅看纹理的复杂度,实质上复杂与简单,是好编与难编的同义词。即使是看起来很复杂的块,如果能够编成很小的块,它依然是一个简单块。为此我们进行了一个区分,如果一个屏幕内容能够用块复制很好去压缩,也会将其认为是一个简单块。这样的操作,对于质量的改善是非常明显的。 在整体码控中特别需要关注平坦区。在一个复杂区域中间的平坦区是最难处理的地方。在处理这些地方时,会首先判断目前buffer是否满,如果buffer不是很满,即便一个相对简单的内容,也会为其分配更多的比特来保证区域的质量。在加入上述码控调优之后,复杂区域中间的平坦区域的质量有非常显著的提升。

在码控最开始的时候,存在一个delay,其作用是为了在buffer里累积一定量的初始比特。这样在后面进行CBR传输时,可避免发生buffer下溢的情况。即便发生了buffer下溢,标准中也存在下溢填充的机制进行兜底。码控需要使用buffer充溢度作为输入。但是在slice初始与结尾时,真实水位并不匹配码控需求。这两个地方需要用虚拟的buffer充溢度进行码控调节。压缩非常依赖上方参考的像素行,如果上方像素行不可得,会出现较大的编码压力。如果上方像素行不可得,需要为第一行的像素分配更多的比特,使其有更好的质量,避免slice的边界出现失真。首列也存在相似的问题。首列左侧的像素也是不可得,这会对块复制产生影响。块复制向左搜不到时,会向上搜索以提升重建图像质量。
-06-
未来展望

目前已经启动了面向制作域的AVS422和AVS444的压缩。这里也分为两部分。一部分是摄像机侧,或者说采集域做视频压缩。可以扩展目前仅支持40的AVS3标准方案来支持42以及44色彩格式,从而可以使用专业摄像机采集并压缩更高色彩保真度的视频内容。具体到制作域,其压缩需求又有些许不同。AVS标准组也正计划做一个新的制作域标准,从而满足对软件非常友好的高并行度、低复杂度的制作域单帧编辑操作需求。另外在三维医学影像编码领域,要求做到数学无损,或者主观无损,从技术上也可以归到浅压缩,在这里AVS标准组进行了统一的标准规划。
编辑:黄飞












 工商网监
工商网监
评论