 电子发烧友App
电子发烧友App


随着计算机网络和多媒体技术的发展,数字视频的应用越来越广泛,如DVD、网络会议服务、数字电视等。在这些视频处理与通信中,有效的视频编码是其关键技术。
H.264/AVC是ITU-T视频编码专家组和ISO/IEC运动图像专家组联合提出的最新一代的视频编码标准。H.264具有许多优良的性能[1]:压缩比更高,与现有编码标准(H.263、MPEG-4 Simple Profile)相比,在相同视频质量下,能节省大约50%的码流,图像质量更好,适应性更广,能较好地满足实时(视频会议)及非实时(存储、广播等)等各种应用。在DSP上实现H.264的实时编码具有较大的工程意义及经济价值。
1 H.264标准简介及DSP平台
1.1 H.264标准简介
H.264是ITU-T和ISO/IEC联合制定的最新的视频编码标准,于1997年由ITU-T提出,2003年3月形成最终标准草案。它包含了视频压缩领域的许多最新研究成果,主要采用了下面的技术[1]:
(1) 将编码分为编码层VCL(Video Coding Layer)和传输层NAL(Network Abstraction Layer)。将编码层和传输层分离,有利于H.264的扩展。
(2) H.264采用了空域内的帧内预测,共两种预测模式:intra16×16和intra4×4。其中intra16×16有四种预测方式,intra4×4有九种预测方式。
(3) 对于帧间预测,增加了预测模式,共七种预测模式。预测块从16×16可以最小细分为4×4。
(4) 增加了参考帧的数目,使预测更为准确。
(5) 将去块效应滤波放在编码环内,提高图像的主观质量。
(6) B帧可以作为参考帧,同时将图像的解码顺序与显示顺序分离。
(7) 采用整系数变换,提高变换速度。
(8) 采用CAVLC、CABAC等新的熵编码方法以提高编码效果。
(9) 提高了码流的抗误码能力,如对编码数据进行分割,一帧图像可以灵活地分为几个slice等。
1.2 基于Blackfin533的DSP平台
Blackfin533是ADI公司Blackfin系列中的一款高性能视频处理芯片。其主频最高能达600MHz,每秒可处理1200M次乘加运算。具有大量针对视频的专用指令,可以并行处理多条指令。
从总体上看,Blackfin533分为内核和系统接口两大部分。内核指处理器、L1存储器、事件控制器、内核定时器等;系统接口指SPORT接口、PPI接口、SPI接口、外部存储控制器、DMA控制器及与它们接口的外部资源等。
Blackfin533开发平台原理图如图1所示。摄像头输出的模拟视频信号经7113视频芯片转化为数字信号,此信号从Blackfin533的PPI接口进入Blackfin533,压缩后的码流由PCI桥传给PC机。此系统通过Flash启动,编码过程中的原始图像、参考帧及其他变量存储在SDRAM中。
图2为H.264编码系统的视频输入模块。7113芯片从视频端子读入摄像头输出的模拟信号,通过并口将数字信号输出给Blackfin533。Blackfin533通过I2C总线对7113进行配置,使其输出YUV模式、ITU656模式及增强ITU656模式等。

图1 Blackfin533平台总体框架图
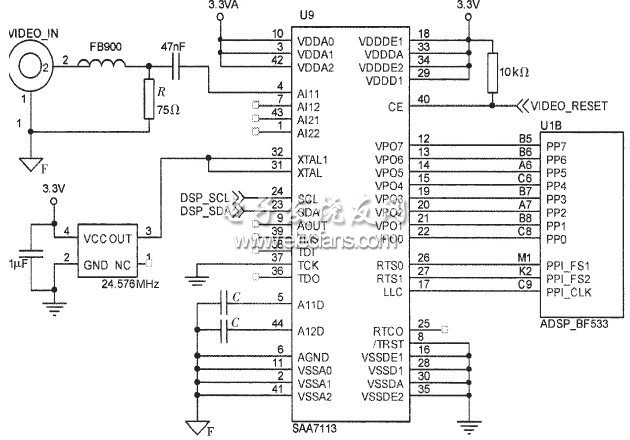
图2 视频输入模块
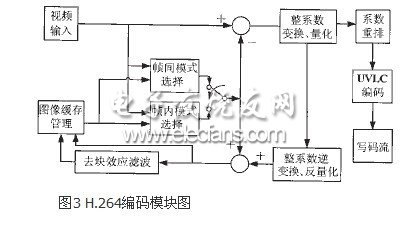
图3 H.264编码模块图
2 H.264编码器的优化
2.1 总体优化
总体优化主要包括两部分内容:程序模块化的设计及数据结构的设计。
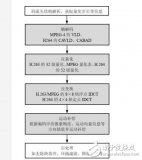
程序模块化设计时,既要考虑模块的独立性,又要考虑模块的完整性。笔者的H.264的模块关系图如图3所示。视频输入模块负责图像序列的读取,从PPI口进入的图像首先保存到外部存储器,再进行编码。读入的图像经帧间模式选择和帧内模式选择模块,得到每个宏块的预测模式。整系数变换、量化模块对预测后的残差进行整系数变换及量化处理。量化后的系数经过扫描后,在编码模块中进行UVLC编码。最后由写码流模块输出。其中,去块效应滤波模块对反量化、整系数逆变换后的重建图像进行滤波;图像缓存管理模块负责管理对参考图像的存取。从图3中可以看出,整系数变换与量化结合在一起作为一个模块。主要因为:一方面H.264中,量化和整系数变换本身就部分结合在一起;另一方面这样可以在寄存器中一起完成变换、量化,有助于减少数据的存储次数和读取时间。对于反量化、整系数逆变换,采用相似的设计思路。
数据结构的设计是H.264编码的重要组成部分。合理的数据结构既有利于提高数据访问的速度又有利于程序的不同平台的移植。主要有以下原则:尽可能连续存放数据,这样有利于用DMA方式对数据进行读取;每种数据结构完成相对简单的功能,这样便于对不同数据结构的数据进行管理。如表示帧间模式的InterMode、帧内模式的IntraMode需要放在片内存储器中以加快读取速度,而参考帧的数据ImgData由于数据太大则需要放在片外存储器中;尽可能使用短的数据类型,节省DSP的存储空间。
2.2 各程序模块的优化
各程序模块的优化主要指各模块的C代码优化及部分代码的汇编优化。
C代码的优化对H.264编码器有着重要意义,它既有利于提高编码的速度,又有利于编码器的跨平台移植。C代码优化有下面的原则:
(1) 使编码器代码线性化,这样有利于DSP的流水线满负荷运行,更充分地发挥DSP的数据处理能力。
(2) 取消循环中的数据依赖。数据依赖是指后面指令的输入数据依赖于前面指令的输出数据。许多DSP芯片都提供了硬件循环指令,Blackfin533有两个硬件循环器,可提供两层的硬件循环。硬件循环实现了零开销的循环判断,能大大提高循环指令的执行速度,然而数据依赖的存在会阻止硬件循环的使用。所以要尽可能消除循环中的数据依赖。
(3) 将除法转化为乘法或查表方式。Blackfin533提供了硬件乘法器,但没有硬件除法器。执行除法指令会花费几十或上百个指令周期。将除法转化为乘法或查表,能大大减少这种开销。
(4) 减少对片外存储器的访问次数。片外存储器相对于片内存储器是低速设备,片外存储器的读取时间是片内存储器的几倍至十几倍。对于片外存储器的数据要做到一次读取,完成多次计算。
Blackfin芯片的开发环境VisualDSP本身已经带有汇编器,但由于种种原因,对于某些运算量大、调用频繁的函数仍需要进行手动汇编优化。进行汇编优化时,应注意以下几点:
(1) 节省寄存器资源。Blackfin533提供了8个32位数据寄存器以及一系列的地址寄存器。对于这些寄存器,应尽可能做到一个寄存器多次使用;同时在能用较短的数据类型的情况下用短的数据类型,如能用short则不用int,这样每个32位寄存器可以作为两个16位寄存器使用,相当于增加了寄存器的数量。
(2) 使用专用指令。Blackfin533提供了求最大值、最小值、绝对值、CLIP及大量视频专用指令,通过使用这些指令,能大大提高代码的执行速度。
(3) 使用并行指令。对于大多数指令都存在相对应的并行指令,如一条运算指令可以并行两条数据读取指令。并行指令的使用能成倍提高代码的执行速度。
(4) 将内层循环展开等。
对于不同的图像帧(I、P),各模块所占的比例各不相同。对于I帧,帧内模式选择和去块效应滤波占较大的比例;对于P帧,帧间模式选择则占较大的比例。总之,模式选择及去块效应滤波是H.264编码的瓶颈,需要对这两部分进行优化。
进行模式选择时会调用绝对差值求和函数(SAD)及hadamard变换后再绝对值求和函数(SATD)。这两个函数虽然较简单,但调用较频繁,对这两个函数进行汇编优化,能较大提高模式选择的速度。对于绝对差值求和函数(SAD),通过使用Blackfin的专用视频指令SAA,可以大大提高运算速度,具体见汇编优化统计表1和表2。
表1 优化前后函数所占时钟周期数对比表
| 优化函数 | 优化前(时钟周期数) | 优化后(时钟周期数) | 提高倍数 |
| SAD | 1385 | 55 | 25 |
| SATD | 1964 | 84 | 23 |
| GetStrength | 50214 | 4983 | 10 |
| EdgeLoopY | 61227 | 5032 | 12 |
| EdgeLoopUV | 52110 | 4173 | 12 |
表2 优化后的H.264各模块性能
| 占用时间(时钟周期数M) | 所占比例 | |
| 模式选择(包含插值) | 11.26 | 53.6% |
| 变换、量化 | 1.87 | 8.9% |
| 反量化、反变换 | 1.93 | 9.2% |
| 编码(UVLC) | 0.90 | 4.3% |
| 去块效应滤波 | 2.73 | 13% |
| 其他 | 2.31 | 11% |
表3 压缩后的CIF图像的质量
| H.264编码器 | ||||
|
视频序列 (100帧) |
平均峰值信噪比PSNR(dB) | 码率(kbit/s) | ||
| 亮度Y | 色度U | 色度V | ||
| Foreman | 36.57 | 41.23 | 43.39 | 503 |
| Shanlin | 34.00 | 39.95 | 41.30 | 1035 |
| tempete | 30.47 | 35.81 | 37.60 | 1059 |
| mobile | 30.58 | 34.48 | 34.24 | 1587 |
去块效应滤波在编码中占有较大的比重。主要包括:计算滤波强度和行列滤波两部分,需要针对这两个子模块进行优化。去块效应滤波中有较多的判断语句,判断语句会打断DSP的流水线,使DSP不能充分发挥其性能,优化时应尽可能将判断转移到循环外面去,以提高执行效率。同时去块效应滤波需要频繁地访问待滤波数据,减少对这些数据的访问次数也能较大地提高去块效应滤波的速度。
SAD()的函数原型及其汇编代码[2]:
for(i=0;i<16*16;i++)
result +=abs( *pSrc++ - *pRef++);
LSETUP(row_start,row_end) LC0=P1; //利用Blackfin的硬件循环实现SAD的循环
row_start:
R3 = [I1++]; //读取数据
SAA(R1:0,R3:2) || R1= [I0++] || R2= [I1++]; //计算R1:0和R3:2的SAD
SAA(R1:0,R3:2)(R) || R0= [I0++] || R3= [I1++]; //执行SAA的同时,读取数据
SAA(R1:0,R3:2) || R1= [I0++] || R2= [I1++];
row_end:SAA(R1:0,R3:2)(R) || R0=[I0++] || R2= [I1++];
3 实验结果
笔者使用600MHz时钟的Blackfin533,对于低、中运动复杂度的图像序列,能够实现25帧/秒的实时编码;对于高运动复杂度的图像序列,能实现20帧/秒左右的准实时编码。其各模块所占时间比例见表2。
编码器的性能指标如下:1个参考帧;帧间模式采用16×16、16×8、8×16、8×8模式;帧内模式对16×16采用4种预测模式,对于4×4采用9种预测模式;1/4像素的运动估计;熵编码采用CAVLC编码方式。
表3为不同图像序列压缩效果的比较。每种序列压缩100帧图像,采用IPPPP....的编码模式。综上所述,在Blkfin533平台上实现了H.264的CIF图像的准实时编码。该系统具有码流低、延时小、图像质量高等优点。












 工商网监
工商网监
评论