 电子发烧友App
电子发烧友App


在本教程中,我们将使用 Arduino 33 BLE Sense 和 Edge Impulse Studio 构建咳嗽检测系统。它可以区分正常的背景噪音和实时音频中的咳嗽。我们使用 Edge Impulse Studio 训练咳嗽和背景噪声样本数据集,并构建高度优化的 TInyML 模型,该模型可以实时检测咳嗽声音。
所需组件
Arduino 33 BLE 感知
引领
跳线
软件
边缘脉冲工作室
Arduino IDE
电路原理图
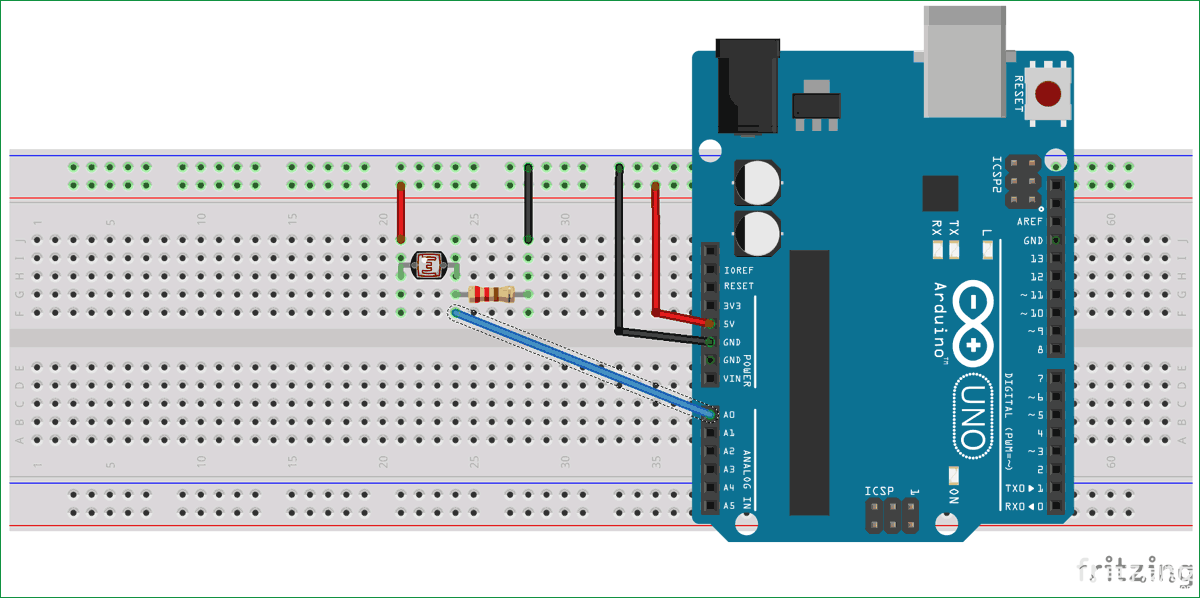
下面给出了使用 Arduino 33 BLE Sense进行咳嗽检测的电路图。Arduino 33 BLE 的 Fritzing 部件不可用,所以我使用了 Arduino Nano,因为它们具有相同的引脚。
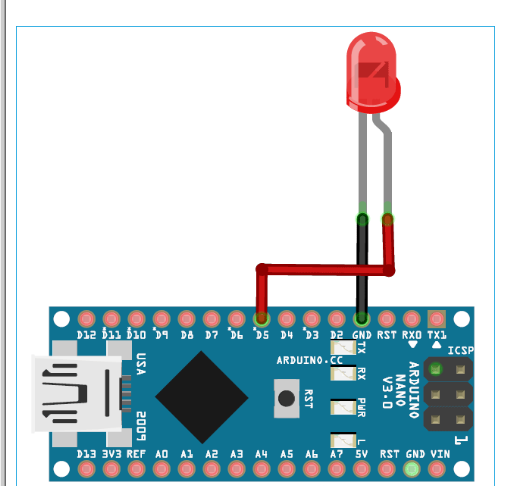
LED 的正极引线连接到 Arduino 33 BLE sense 的数字引脚 4,负极引线连接到 Arduino 的 GND 引脚。

为咳嗽检测机创建数据集
如前所述,我们正在使用 Edge Impulse Studio 来训练我们的咳嗽检测模型。为此,我们必须收集一个数据集,其中包含我们希望能够在 Arduino 上识别的数据样本。由于目标是检测咳嗽,因此您需要收集其中的一些样本和其他一些噪声样本,以便区分咳嗽和其他噪声。
我们将创建一个包含“咳嗽”和“噪音”两个类别的数据集。要创建数据集,请创建一个Edge Impulse帐户,验证您的帐户,然后开始一个新项目。您可以使用手机、Arduino 板加载样本,也可以将数据集导入边缘脉冲帐户。将样本加载到您的帐户中的最简单方法是使用您的手机。为此,您必须将您的手机与 Edge Impulse 连接。
要连接您的手机,请单击“设备”,然后单击“连接新设备”。
现在在下一个窗口中,单击“使用您的手机”,将出现一个二维码。使用 Google Lens 或其他 QR 码扫描仪应用程序使用您的手机扫描 QR 码。
这会将您的手机与 Edge Impulse studio 连接起来。
将手机与 Edge Impulse Studio 连接后,您现在可以加载样本。要加载样本,请单击“数据采集”。现在在数据采集页面上,输入标签名称,选择麦克风作为传感器,然后输入样本长度。单击“开始采样”,开始采样 40 秒样本。您可以使用不同长度的在线咳嗽样本,而不是强迫自己咳嗽。共记录 10 到 12 个不同长度的咳嗽样本。
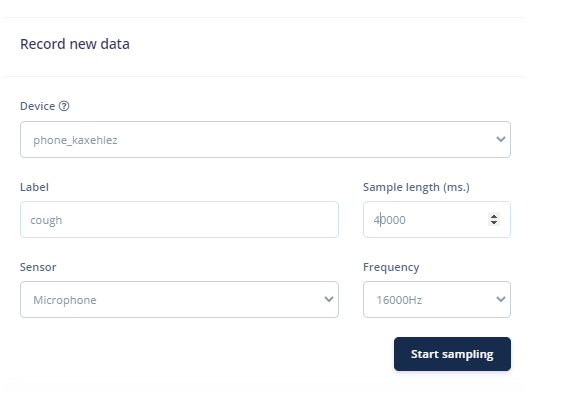
上传咳嗽样本后,现在将标签设置为“噪声”并再收集 10 到 12 个噪声样本。
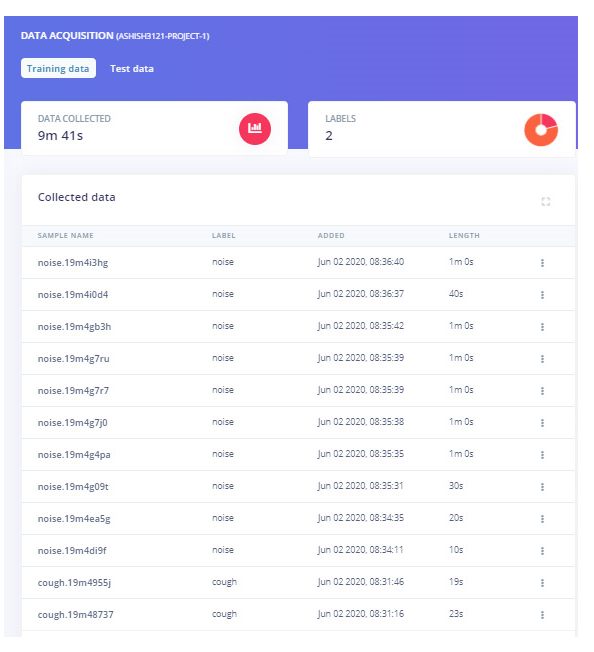
这些样本用于训练模块,在接下来的步骤中,我们将收集测试数据。测试数据至少应该是训练数据的 30%,所以收集 3 个样本的“噪音”和 4 到 5 个样本的“咳嗽”。
您可以使用 Edge Impulse CLI Uploader 将我们的数据集导入您的 Edge Impulse 帐户,而不是收集您的数据。
要安装 CLI Uploader,首先,在您的笔记本电脑上下载并安装Node.js。之后打开命令提示符并输入以下命令:
npm install -g edge-impulse-cli
现在下载数据集(数据集链接)并将文件解压缩到您的项目文件夹中。打开命令提示符并导航到数据集位置并运行以下命令:
edge-impulse-uploader --clean
edge-impulse-uploader --category training training/*.json
edge-impulse-uploader --category training training/*.cbor
edge-impulse-uploader --category testing testing/*.json
edge-impulse-uploader --category testing testing/*.cbor
训练模型并调整代码
随着数据集准备就绪,现在我们将为数据创建一个脉冲。为此,请转到“创建冲动”页面。
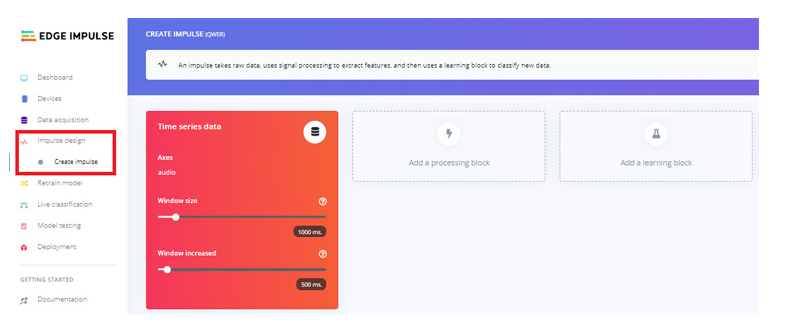
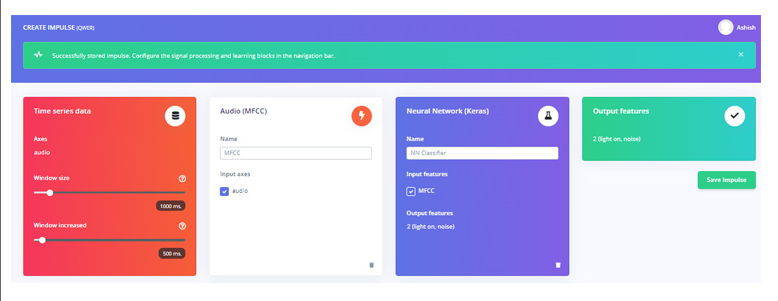
现在在“创建冲动”页面上,单击“添加处理块”。在下一个窗口中,选择音频 (MFCC) 块。之后单击“添加学习块”并选择神经网络(Keras)块。然后点击“保存冲动”。
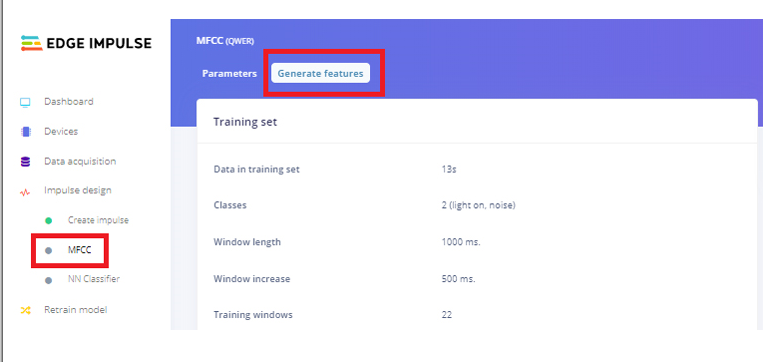
在下一步中,转到 MFCC 页面,然后单击“生成功能”。它将为我们所有的音频窗口生成 MFCC 块。
之后进入“ NN Classifier”页面,点击“ Neural Network settings”右上角的三个点,选择“ Switch to Keras (expert) mode”。
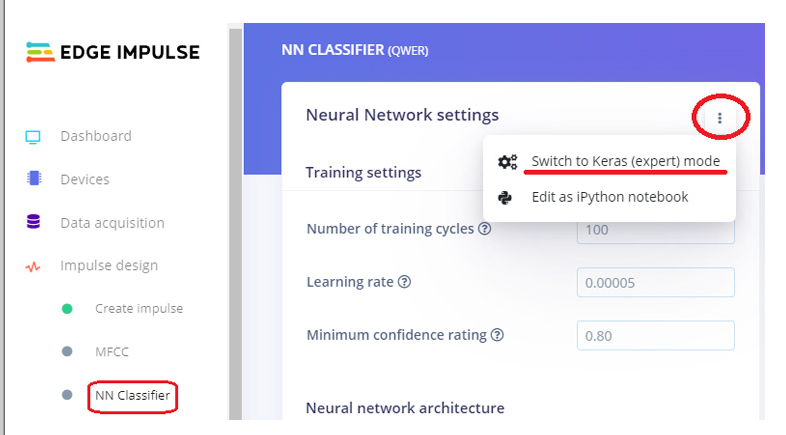
将原始代码替换为以下代码,并将“最低置信度评级”更改为“0.70”。然后单击“开始培训”按钮。它将开始训练您的模型。
将张量流导入为 tf
从 tensorflow.keras.models 导入顺序
从 tensorflow.keras.layers 导入 Dense、InputLayer、Dropout、Flatten、Reshape、BatchNormalization、Conv2D、MaxPooling2D、AveragePooling2D
从 tensorflow.keras.optimizers 导入 Adam
从 tensorflow.keras.constraints 导入 MaxNorm
# 模型架构
模型=顺序()
model.add(InputLayer(input_shape=(X_train.shape[1], ), name=‘x_input’))
model.add(Reshape((int(X_train.shape[1] / 13), 13, 1), input_shape=(X_train.shape[1], )))
model.add(Conv2D(10, kernel_size=5, activation=‘relu’, padding=‘same’, kernel_constraint=MaxNorm(3)))
model.add(AveragePooling2D(pool_size=2, padding=‘same’))
model.add(Conv2D(5, kernel_size=5, activation=‘relu’, padding=‘same’, kernel_constraint=MaxNorm(3)))
model.add(AveragePooling2D(pool_size=2, padding=‘same’))
model.add(展平())
model.add(密集(类,activation=‘softmax’,name=‘y_pred’,kernel_constraint=MaxNorm(3)))
# 这控制了学习率
选择 = 亚当(lr=0.005,beta_1=0.9,beta_2=0.999)
# 训练神经网络
model.compile(loss=‘categorical_crossentropy’,优化器=opt,metrics=[‘accuracy’])
model.fit(X_train,Y_train,batch_size=32,epochs=9,validation_data=(X_test,Y_test),详细=2)
训练模型后,将显示训练性能。对我来说,准确率是 96.5%,损失是 0.10,这很好。
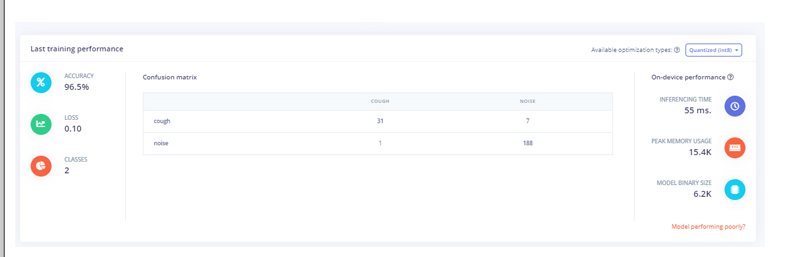
现在我们的咳嗽检测模型已经准备就绪,我们将把这个模型部署为 Arduino 库。在将模型下载为库之前,您可以通过转到“实时分类”页面来测试性能。
转到“部署”页面并选择“ Arduino Library”。现在向下滚动并单击“构建”以开始该过程。这将为您的项目构建一个 Arduino 库。
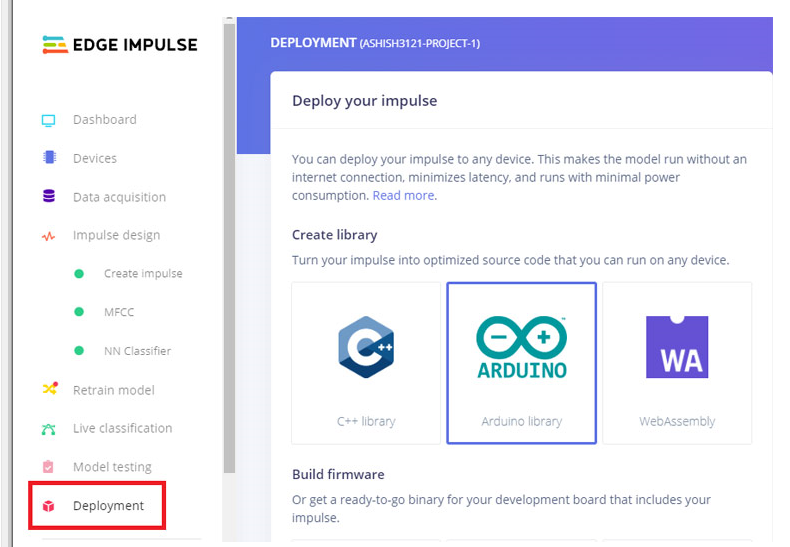
现在在您的 Arduino IDE 中添加库。为此,打开 Arduino IDE,然后单击Sketch 》 Include Library 》 Add.ZIP library。
然后,通过转到 文件 》 示例 》 您的项目名称 - Edge Impulse 》 nano_ble33_sense_microphone 来加载示例。
我们将对代码进行一些更改,以便在 Arduino 检测到咳嗽时发出警报声。为此,Arduino 连接了一个蜂鸣器,当它检测到咳嗽时,LED 会闪烁 3 次。
这些更改是在打印噪音和咳嗽值的void loop()函数中进行的。在原始代码中,它同时打印标签及其值。
对于 (size_t ix = 0; ix 《 EI_CLASSIFIER_LABEL_COUNT; ix++) {
ei_printf(“%s: %.5f\n”, result.classification[ix].label, result.classification[ix].value);
}
我们将把噪声值和咳嗽值保存在不同的变量中,并比较噪声值。如果噪声值低于 0.50,则表示咳嗽值大于 0.50,它会发出声音。用这个替换原来的 for loop()代码:
对于(size_t ix = 1;ix 《 EI_CLASSIFIER_LABEL_COUNT;ix++){
Serial.print(result.classification[ix].value);
浮动数据=结果。分类[ix]。值;
如果(数据 《 0.50){
Serial.print(“检测到咳嗽”);
警报();
}
}
进行更改后,将代码上传到您的 Arduino。以 115200 波特率打开串行监视器。
所以这就是咳嗽检测机器的构建方式,它不是找到任何 COVID19 嫌疑人的非常有效的方法,但它可以在一些拥挤的区域很好地工作。
#define EIDSP_QUANTIZE_FILTERBANK 0
#include
#include
#define LED 5
/** 音频缓冲区、指针和选择器 */
类型定义结构{
int16_t *缓冲区;
uint8_t buf_ready;
uint32_t buf_count;
uint32_t n_samples;
} inference_t;
静态推理_t推理;
静态布尔记录就绪=假;
静态有符号短样本缓冲区[2048];
静态 bool debug_nn = false; // 将此设置为 true 以查看例如从原始信号生成的特征
无效设置()
{
// 把你的设置代码放在这里,运行一次:
序列号.开始(115200);
pinMode(LED,输出);
Serial.println("边缘脉冲推理演示");
// 推理设置摘要(来自 model_metadata.h)
ei_printf("推理设置:\n");
ei_printf("\tInterval: %.2f ms.\n", (float)EI_CLASSIFIER_INTERVAL_MS);
ei_printf("\t帧大小: %d\n", EI_CLASSIFIER_DSP_INPUT_FRAME_SIZE);
ei_printf("\t样本长度: %d ms.\n", EI_CLASSIFIER_RAW_SAMPLE_COUNT / 16);
ei_printf("\tNo. of classes: %d\n", sizeof(ei_classifier_inferencing_categories) / sizeof(ei_classifier_inferencing_categories[0]));
if (microphone_inference_start(EI_CLASSIFIER_RAW_SAMPLE_COUNT) == false) {
ei_printf("ERR: 设置音频采样失败\r\n");
返回;
}
}
无效循环()
{
ei_printf("2秒后开始推理...\n");
延迟(2000);
ei_printf("正在录制...\n");
bool m = 麦克风推理记录();
如果(!米){
ei_printf("ERR: 录音失败...\n");
返回;
}
ei_printf("录制完成\n");
signal_t 信号;
signal.total_length = EI_CLASSIFIER_RAW_SAMPLE_COUNT;
signal.get_data = µphone_audio_signal_get_data;
ei_impulse_result_t 结果 = { 0 };
EI_IMPULSE_ERROR r = run_classifier(&signal, &result, debug_nn);
如果(r!= EI_IMPULSE_OK){
ei_printf("ERR: 分类器运行失败(%d)\n", r);
返回;
}
// 打印预测
ei_printf("预测 (DSP: %d ms., 分类: %d ms., 异常: %d ms.): \n",
result.timing.dsp,result.timing.classification,result.timing.anomaly);
对于(size_t ix = 1;ix < EI_CLASSIFIER_LABEL_COUNT;ix++){
Serial.print(result.classification[ix].value);
浮动数据=结果.分类[ix].值;
如果(数据 < 0.50){
Serial.print("检测到咳嗽");
警报();
}
}
//for (size_t ix = 0; ix < EI_CLASSIFIER_LABEL_COUNT; ix++) {
// ei_printf(" %s: %.5f\n", result.classification[ix].label, result.classification[ix].value);
// }
#if EI_CLASSIFIER_HAS_ANOMALY == 1
ei_printf("异常分数:%.3f\n", result.anomaly);
#万一
}
void ei_printf(const char *format, ...) {
静态字符 print_buf[1024] = { 0 };
va_list 参数;
va_start(参数,格式);
int r = vsnprintf(print_buf, sizeof(print_buf), 格式, args);
va_end(args);
如果 (r > 0) {
Serial.write(print_buf);
}
}
静态无效 pdm_data_ready_inference_callback(void)
{
int bytesAvailable = PDM.available();
// 读入样本缓冲区
int bytesRead = PDM.read((char *)&sampleBuffer[0], bytesAvailable);
if (record_ready == true || inference.buf_ready == 1) {
for(int i = 0; i < bytesRead>>1; i++) {
inference.buffer[inference.buf_count++] = sampleBuffer[i];
if(inference.buf_count >= inference.n_samples) {
inference.buf_count = 0;
inference.buf_ready = 1;
}
}
}
}
静态布尔mic_inference_start(uint32_t n_samples)
{
inference.buffer = (int16_t *)malloc(n_samples * sizeof(int16_t));
如果(推理。缓冲区 == NULL){
返回假;
}
inference.buf_count = 0;
inference.n_samples = n_samples;
inference.buf_ready = 0;
// 配置数据接收回调
PDM.onReceive(&pdm_data_ready_inference_callback);
// 可选设置增益,默认为 20
PDM.setGain(80);
//ei_printf("扇区大小: %d nblocks: %d\r\n", ei_nano_fs_get_block_size(), n_sample_blocks);
PDM.setBufferSize(4096);
// 使用以下命令初始化 PDM:
// - 一个通道(单声道模式)
// - 16 kHz 采样率
if (!PDM.begin(1, EI_CLASSIFIER_FREQUENCY)) {
ei_printf("启动 PDM 失败!");
}
记录就绪=真;
返回真;
}
静态布尔麦克风推理记录(无效)
{
inference.buf_ready = 0;
inference.buf_count = 0;
而(inference.buf_ready == 0){
延迟(10);
}
返回真;
}
静态 int 麦克风_音频_信号_get_data(size_t 偏移量,size_t 长度,浮点 *out_ptr)
{
arm_q15_to_float(&inference.buffer[offset], out_ptr, length);
返回0;
}
静态无效麦克风推理结束(无效)
{
PDM.end();
免费(推理。缓冲区);
}
#if !defined(EI_CLASSIFIER_SENSOR) || EI_CLASSIFIER_SENSOR != EI_CLASSIFIER_SENSOR_MICROPHONE
#error “电流传感器的型号无效。”
#万一
无效警报(){
for (size_t t = 0; t < 4; t++) {
数字写入(领导,高);
延迟(1000);
数字写入(领导,低);
延迟(1000);
// digitalWrite(led, HIGH);
// 延迟(1000);
// digitalWrite(LED, LOW);
}
}


























 工商网监
工商网监
评论