 多模态中NLP与CV融合的方式有哪些?
多模态中NLP与CV融合的方式有哪些?
最早接触多模态是一个抖音推荐项目,有一些视频,标题,用户点赞收藏等信息,给用户推荐作品,我当时在这个项目里负责用NLP部分上分,虽然最后用wide and deep 整个团队效果还可以,但是从a/b test 看文本部分在其中起到的作用为0... ( ) 现在看来还是wide and deep这种方式太粗暴了(对于复杂信息的融合),本文写写多模态扫盲基础和最近大家精巧的一些图像文本融合的模型设计,主要是在VQA(视觉问答)领域,也有一个多模态QA,因为在推荐领域,你也看到了,即使NLP的贡献为零,用户特征足够,效果也能做到很好了。
一. 概念扫盲
多模态(MultiModal)
多种不同的信息源(不同的信息形式)中获取信息表达
五个挑战
表示(Multimodal Representation)的意思,比如shift旋转尺寸不变形,图像中研究出的一种表示
表示的冗余问题
不同的信号,有的象征性信号,有波信号,什么样的表示方式方便多模态模型提取信息
表示的方法
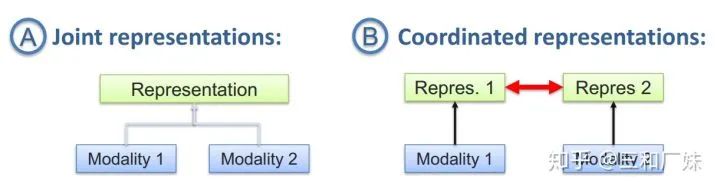
联合表示将多个模态的信息一起映射到一个统一的多模态向量空间
协同表示负责将多模态中的每个模态分别映射到各自的表示空间,但映射后的向量之间满足一定的相关性约束。
2. 翻译/转化/映射
信号的映射,比如给一个图像,将图像翻译成文字,文字翻译成图像,信息转化成统一形式后来应用
方式,这里就跟专门研究翻译的领域是重叠,基于实例的翻译,涉及到检索,字典(规则)等,基于生成方法如生成翻译的内容
3. 对齐
多模态对齐定义为从两个或多个模态中查找实例子组件之间的关系和对应,研究不同的信号如何对齐(比如给电影,找出剧本中哪一段)
对齐方式,有专门研究对齐的领域,主要两种,显示对齐(比如时间维度上就是显示对齐的),隐式对齐(比如语言的翻译就不是位置对位置)
4. 融合
比如情感分析中语气和语句的融合等
这个最难也是被研究最多的领域,比如音节和唇语头像怎么融合,本笔记主要写融合方式
二. 应用
试听语音识别,多媒体内容检索,视频理解,视频总结,事件监测,情感分析,视频会议情感分析,媒体描述,视觉问答等,应用其实很广,只不过被现在的智能程度大大限制了,whatever, 我觉得视觉也语言的结合比纯NLP,是离智能更近的一步。
三.VQA扫盲 and 常用方式
VQA(Visual Question Answering)
给定一张图片(视频)和一个与该图片相关的自然语言问题,计算机能产生一个正确的回答。这是文本QA和Image Captioning的结合,一般会涉及到图像内容上的推理,看起来更炫酷(不是指逻辑,就就指直观感受)。
目前VQA的四大方式
Joint embedding approaches,只是直接从源头编码的角度开始融合信息,这也很自然的联想到最简单粗暴的方式就是把文本和图像的embedding直接拼接(ps:粗暴拼接这种方式很work),Billiner Fusion 最常用了,Fusion届的LR
Attention mechanisms,很多VQA的问题都在attention上做文章,attention本身也是一个提取信息的动作,自从attention is all you need后,大家对attention的应用可以说是花式了,本文后面专门介绍CVPR2019的几篇
Compositional Models,这种方式解决问题的思路是分模块而治之,各模块分别处理不同的功能,然后通过模块的组装推理得出结果
比如在[1]中,上图,问题是What color is his tie?先选择出 attend 和classify 模块,并且根据推理方式组装模块,最后得出结论 4.Models using external knowledge base利用外部知识库来做VQA和很好理解,QA都喜欢用知识库,这种知识储备一劳永逸,例如,为了回答“图上有多少只哺乳动物”这样的问题,模型必须得知道“哺乳动物”的定义,而你想从图像上去学习到哺乳动物是有难度的,因此把知识库接进来检索是种解决方式,例如在[2]
四. 多模态中CV和NLP融合的几种方式
1. Bilinear Fusion 双线性融合 and Joint embedding Bilinear Fusion 双线性融合是最常见的一种融合方式了,很多论文用这种方式做基础结构,在CVPR2019一遍VQA多模态推理[3]中,提出的CELL就是基于这个,作者做关系推理,不仅对问题与图片区域的交互关系建模,也对图片区域间的联系建模。并且推导过程是逐步逼近的过程。
作者提出的MuRel,Bilinear Fusion 将每个图像区域特征都分别与问题文本特征融合得到多模态embedding(Joint embedding ),后者对这些embedding进行成对的关系建模。
第一部分双线性融合,所谓双线性简单来讲就是函数对于两个变量都是线性的,参数(表达两种信息关联)是个多为矩阵,作者采用的MUTAN模型里面的Tucker decomposition方法, 将线性关系的参数分解大大减小参数量 第二部分Pairwise relation学习的是经过融合后节点之间的两两关系(主要是图像的关系),然后和原始text 信息有效(粗暴)拼接 最后如下图放在网络,进行迭代推理。实验结果显示在跟位置推断类的问题中,这种结构表现比较好。
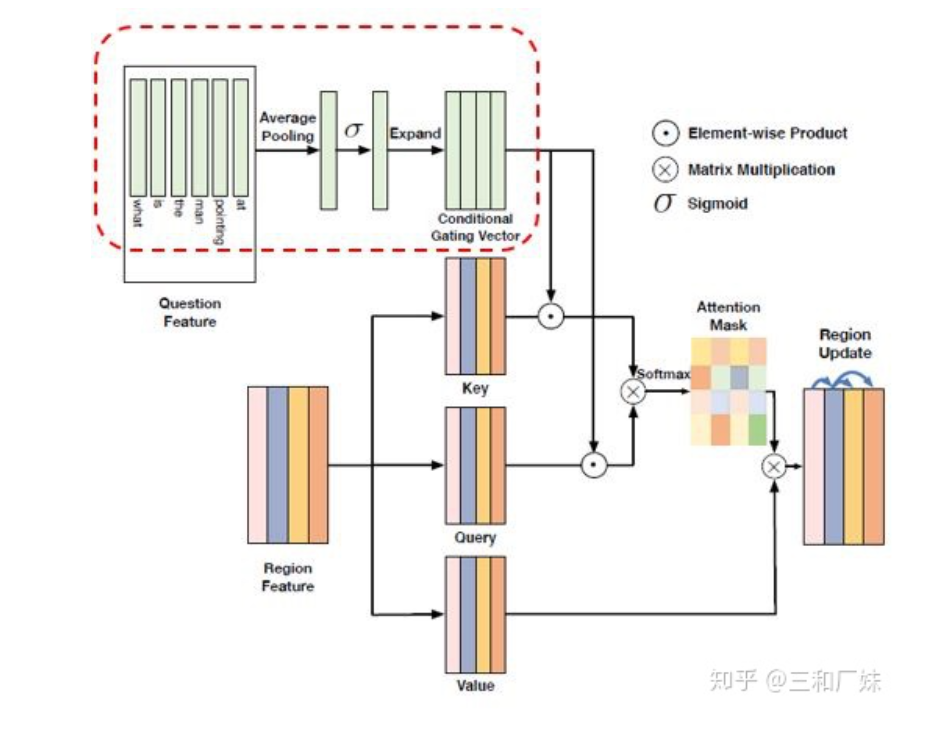
2. 花式动态attention融合 这篇[4]作者更上篇一样同时注意到了模态内和模态间的关系,即作者说的intra-modality relation(模态内部关系)和inter-modality relation(跨模态关系),但是作者更机智(个人观点)的用了attention来做各种fusion。 作者认为intra-modality relation是对inter-modality relation的补充:图像区域不应该仅获得来自问题文本的信息,而且需要与其他图像区域产生关联。 模型结构是首先各自分别对图像和文本提取特征,然后通过通过模态内部的attention建模和模态间的attention建模,这个模块堆叠多次,最后拼接后进行分类。模态间的attention是相互的(文本对图像,图像对文本),attention就是采用transform中的attention.
进行模态内关系建模的模块是Dynamic Intra-modality Attention Flow (DyIntraMAF), 文中最大的亮点是进行了 条件attention,即图像之间的attention信心建立不应该只根据图像,也要根据不同的具体问题而产生不同的关联。
这种条件attention的condition设计有点类似lstm的门机制,通过加入gating机制来控制信息,下图中图像的self attention 就是经过了text的门机制来过滤信息。最后作者做了很多ablation studies,达到了SOTA效果。
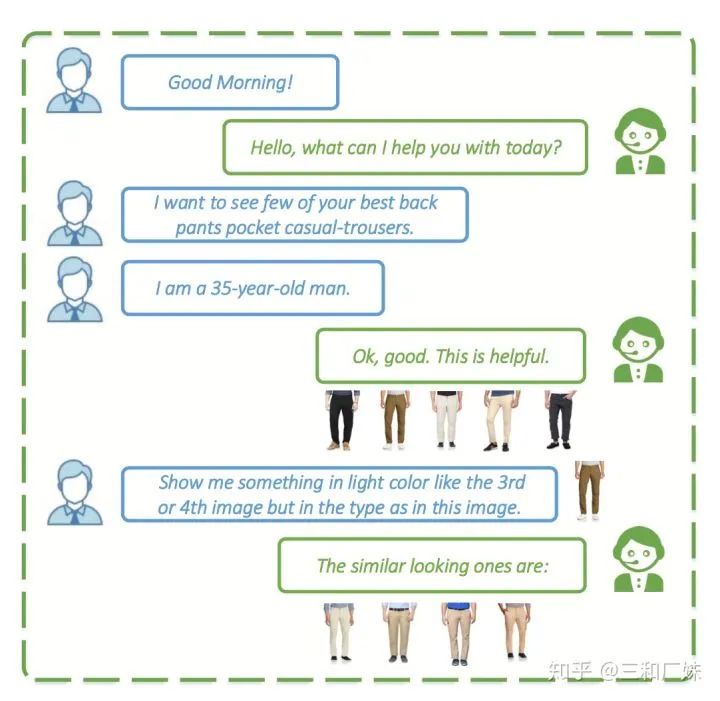
3. VQA对话系统 另外有一篇[5]个多模态的QA,这篇文章fusion 挺普通的multimodal fusion 也是普通的 billinear, 但是这个应用场景非常非常实用,我们通常用语言描述的说不清楚的时候,会有一图胜千言语感觉,而多模态就是从这个点出发,发一张图,like this, like that... 文中就是用这个做商业客服的QA
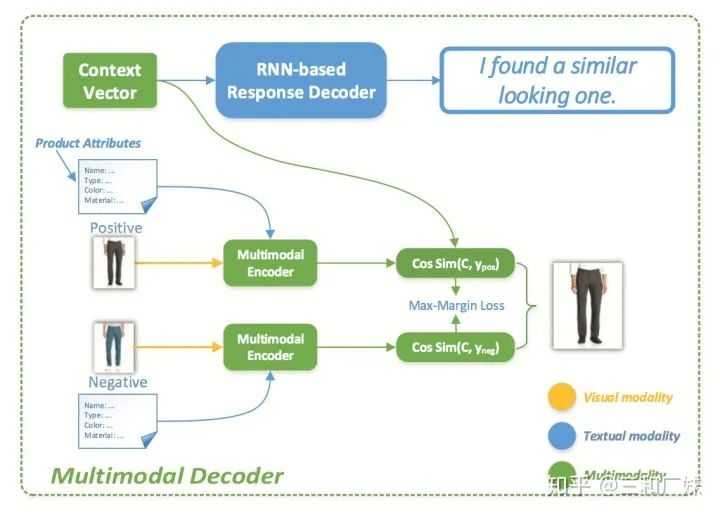
模型比较常规,encoder端,先CNN提取了图片特征,然后根据商品属性建一个属性分类树,文本常规处理,最后通过MFB融合
Decoder 时,文本RNNdecode, 但是图像居然是用求cos相似,就电商那种产品数据的量级,除非在业务上做很多前置工作,这种计算量就不现实
In all
这篇属于扩展NLP的广度,写的不深,选的论文和很随便(因为我不很了解),作为一个NLPer, 宽度上来说我觉得这也是一个方向.
原文标题:多模态中NLP与CV融合的一些方式
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
深度学习
+关注
关注
73文章
5552浏览量
122382 -
MLP
+关注
关注
0文章
57浏览量
4458
原文标题:多模态中NLP与CV融合的一些方式
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Android Studio中的Gemini支持多模态输入功能
海康威视发布多模态大模型AI融合巡检超脑
移远通信智能模组全面接入多模态AI大模型,重塑智能交互新体验

移远通信智能模组全面接入多模态AI大模型,重塑智能交互新体验

商汤“日日新”融合大模型登顶大语言与多模态双榜单
多模态交互技术解析
海康威视发布多模态大模型文搜存储系列产品

商汤日日新多模态大模型权威评测第一
一文理解多模态大语言模型——下

超声界“内卷终结者”!ZRT智锐通提供全新引擎打造多模态影像融合系统

利用OpenVINO部署Qwen2多模态模型
计算机视觉中的图像融合

慕尼黑电子展回顾:启明智显多模态硬件智能体引领科技潮流


TwinCAT3 EtherCAT抓包 | 技术集结
在使用TwinCAT测试EtherCATEOE功能时,我们会发现正常是无法使用Wireshark去进行网络抓包抓取EtherCAT报文的,今天这篇文章就带大家来上手EtherCAT抓包方式。准备环境硬件环境:EtherKit开发板网线一根Type-CUSB线一根软件环境TwinCAT3RT-ThreadstudiowiresharkEtherCATEOE工程

EtherCAT科普系列(8):EtherCAT技术在机器视觉领域的应用
机器视觉是基于软件与硬件的组合,通过光学装置和非接触式的传感器自动地接受一个真实物体的图像,并利用软件算法处理图像以获得所需信息或用于控制机器人运动的装置。机器视觉可以赋予机器人及自动化设备获取外界信息并认知处理的能力。机器视觉系统内包含光学成像系统,可以作为自动化设备的视觉器官实现信息的输入,并借助视觉控制器代替人脑实现信息的处理与输出。从而实现赋予自动化

新品 | 26+6TOPS强悍算力!飞凌嵌入式FCU3501嵌入式控制单元发布
飞凌嵌入式FCU3501嵌入式控制单元基于瑞芯微RK3588处理器开发设计,4xCortex-A76+4xCortex-A55架构,A76主频高达2.4GHz,A55核主频高达1.8GHz,支持8K编解码,NPU算力6TOPS,支持算力卡拓展,可以插装Hailo-8 26TOPS M.2算力卡。

接口核心板必选 | 视美泰AIoT-3568SC 、 AIoT-3576SC:小身材大能量,轻松应对多场景设备扩展需求!
在智能硬件领域,「适配」是绕不开的关键词。无论是小屏设备的”寸土寸金”,还是模具开发的巨额成本,亦或是多产品线兼容的复杂需求,开发者总在寻找一款能「以不变应万变」的核心解决方案。视美泰旗下的AIoT-3568SC与AIoT-3576SC接口核心板系列,可以说是专为高灵活适配场景而生!无需为设备尺寸、模具限制或产品线差异妥协,一块核心板,即可释放无限可能。为什

3核A7+单核M0多核异构,米尔全新低功耗RK3506核心板发布
近日,米尔电子发布MYC-YR3506核心板和开发板,基于国产新一代入门级工业处理器瑞芯微RK3506,这款芯片采用三核Cortex-A7+单核Cortex-M0多核异构设计,不仅拥有丰富的工业接口、低功耗设计,还具备低延时和高实时性的特点。核心板提供RK3506B/RK3506J、商业级/工业级、512MB/256MBLPDDR3L、8GBeMMC/256
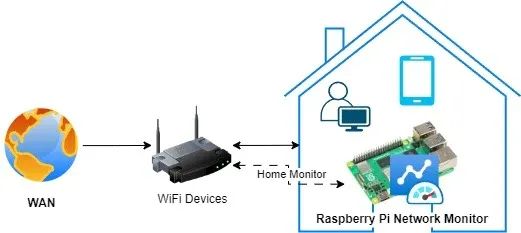
搭建树莓派网络监控系统:顶级工具与技术终极指南!
树莓派网络监控系统是一种经济高效且功能多样的解决方案,可用于监控网络性能、流量及整体运行状况。借助树莓派,我们可以搭建一个网络监控系统,实时洞察网络活动,从而帮助识别问题、优化性能并确保网络安全。安装树莓派网络监控系统有诸多益处。树莓派具备以太网接口,还内置了Wi-Fi功能,拥有足够的计算能力和内存,能够在Linux或Windows系统上运行。因此,那些为L
STM32驱动SD NAND(贴片式SD卡)全测试:GSR手环生物数据存储的擦写寿命与速度实测
在智能皮电手环及数据存储技术不断迭代的当下,主控 MCU STM32H750 与存储 SD NAND MKDV4GIL-AST 的强强联合,正引领行业进入全新发展阶段。二者凭借低功耗、高速读写与卓越稳定性的深度融合,以及高容量低成本的突出优势,成为大规模生产场景下极具竞争力的数据存储解决方案。

芯对话 | CBM16AD125Q这款ADC如何让我的性能翻倍?
综述在当今数字化时代,模数转换器(ADC)作为连接模拟世界与数字系统的关键桥梁,其技术发展对众多行业有着深远影响。从通信领域追求更高的数据传输速率与质量,到医疗影像领域渴望更精准的疾病诊断,再到工业控制领域需要适应复杂恶劣环境的稳定信号处理,ADC的性能提升成为推动这些行业进步的重要因素。行业现状分析在通信行业,5G乃至未来6G的发展,对基站信号处理提出了极
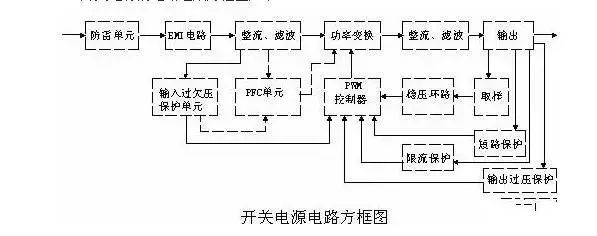
史上最全面解析:开关电源各功能电路
01开关电源的电路组成开关电源的主要电路是由输入电磁干扰滤波器(EMI)、整流滤波电路、功率变换电路、PWM控制器电路、输出整流滤波电路组成。辅助电路有输入过欠压保护电路、输出过欠压保护电路、输出过流保护电路、输出短路保护电路等。开关电源的电路组成方框图如下:02输入电路的原理及常见电路1AC输入整流滤波电路原理①防雷电路:当有雷击,产生高压经电网导入电源时
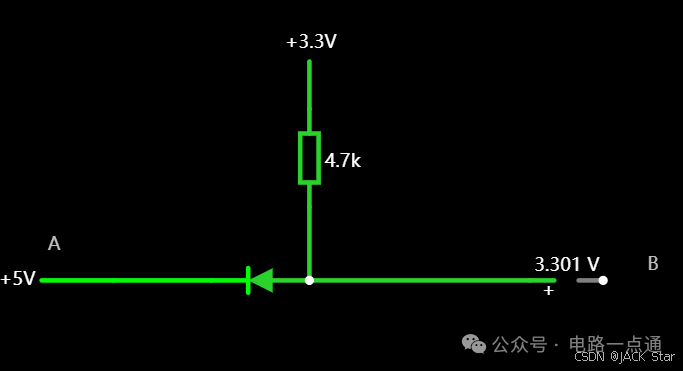
有几种电平转换电路,适用于不同的场景
一.起因一般在消费电路的元器件之间,不同的器件IO的电压是不同的,常规的有5V,3.3V,1.8V等。当器件的IO电压一样的时候,比如都是5V,都是3.3V,那么其之间可以直接通讯,比如拉中断,I2Cdata/clk脚双方直接通讯等。当器件的IO电压不一样的时候,就需要进行电平转换,不然无法实现高低电平的变化。二.电平转换电路常见的有几种电平转换电路,适用于

瑞萨RA8系列教程 | 基于 RASC 生成 Keil 工程
对于不习惯用 e2 studio 进行开发的同学,可以借助 RASC 生成 Keil 工程,然后在 Keil 环境下愉快的完成开发任务。

共赴之约 | 第二十七届中国北京国际科技产业博览会圆满落幕
作为第二十七届北京科博会的参展方,芯佰微有幸与800余家全球科技同仁共赴「科技引领创享未来」之约!文章来源:北京贸促5月11日下午,第二十七届中国北京国际科技产业博览会圆满落幕。本届北京科博会主题为“科技引领创享未来”,由北京市人民政府主办,北京市贸促会,北京市科委、中关村管委会,北京市经济和信息化局,北京市知识产权局和北辰集团共同承办。5万平方米的展览云集

道生物联与巍泰技术联合发布 RTK 无线定位系统:TurMass™ 技术与厘米级高精度定位的深度融合
道生物联与巍泰技术联合推出全新一代 RTK 无线定位系统——WTS-100(V3.0 RTK)。该系统以巍泰技术自主研发的 RTK(实时动态载波相位差分)高精度定位技术为核心,深度融合道生物联国产新兴窄带高并发 TurMass™ 无线通信技术,为室外大规模定位场景提供厘米级高精度、广覆盖、高并发、低功耗、低成本的一站式解决方案,助力行业智能化升级。

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
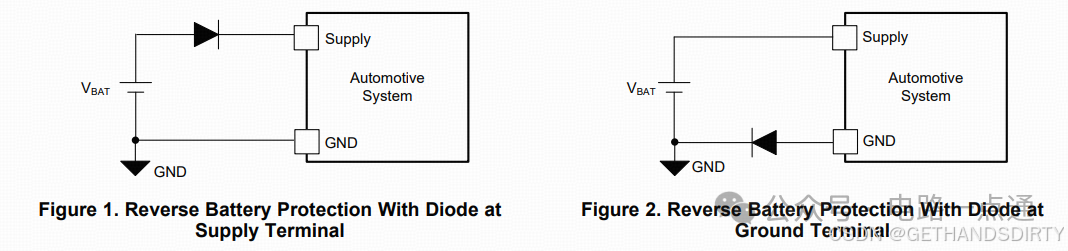
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极





 工商网监
工商网监
评论