 浅析物理内存与虚拟内存的关系及其管理机制
浅析物理内存与虚拟内存的关系及其管理机制
本文主要介绍内存管理机制:物理内存与虚拟内存的关系,Linux内存管理机制,Python内存管理机制,Nginx内存管理机制,环形缓冲区机制,以及TC-malloc内存分配器的Andriod管理机制的简单介绍。
一。 物理内存与虚拟内存
众所周知,程序需要加载到物理内存才能运行,多核时代会出现多个进程同时操作同一物理地址的情况,进而造成混乱和程序崩溃。计算机当中很多问题的解决都是通过引入中间层,为解决物理内存使用问题,虚拟内存作为中间层进入了操作系统,从此,程序不在直接操作物理内存,只能看到虚拟内存,通过虚拟内存,非常优雅的将进程环境隔离开来,每个进程都拥有自己独立的虚拟地址空间,且所有进程地址空间范围完全一致,也给编程带来了很大的便利,同时也提高了物理内存的使用率,可同时运行更多的进程。
物理内存和虚拟内存之间的关系
虚拟内存以页为单位进行划分,每个页对应物理内存上的页框(通常大小为4KB),内存管理单元(MMU)负责将虚拟地址转换为物理地址,MMU中有一张页表来存储这些映射关系。
并非虚拟内存中所有的页都会分配对应的物理内存,为充分利用物理内存,保证尽可能多的进程运行在操作系统上,因此需要提高物理内存利用率,对于很少用到的虚拟内存页不分配对应的物理内存,只有用到的页分配物理内存。虽然从程序角度来看,虚拟内存为连续地址空间,但其实,它被分隔成多个物理内存碎片,甚至还有部分数据并不在内存中,而是在磁盘上。
当访问虚拟内存时,通过MMU寻找与之对应的物理内存,如果没有找到,操作系统会触发缺页中断,从磁盘中取得所缺的页并将其换入物理内存,并在页表中建立虚拟页与物理页的映射关系。
如果物理内存满了,操作系统会根据某种页面置换算法(比如LRU算法),将物理内存对应的页换出到磁盘,如果被换出的物理内存被修改过,则必须将其写回磁盘以更新对应的副本。
当进程创建时,内核为进程分配4G虚拟内存,此时,仅仅只是建立一个映射关系,程序的数据和代码都还在磁盘中,只有当运行时才换回物理内存。并且,通过malloc来分配动态内存时,也只分配了虚拟内存,并不会直接给物理内存,因此,理论上来说malloc可分配的内存大小应该是无限制的(实际当然会有很多算法进行限制)。
多进程使用同一物理内存图如下:
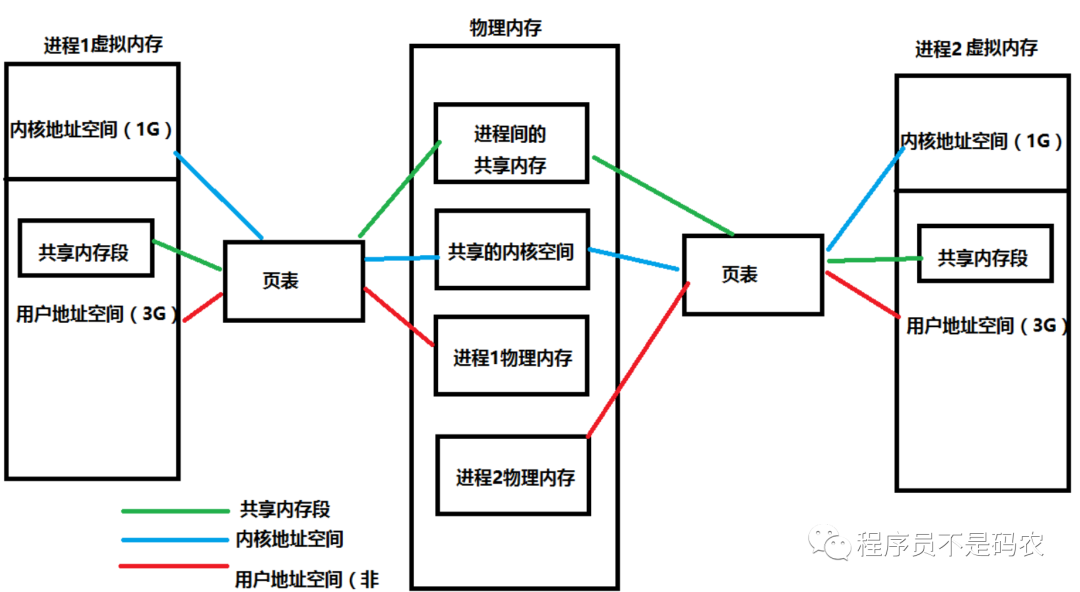
物理内存与虚拟内存关系
二。 Linux内存管理机制进程地址空间
进程地址空间分为内核空间(3G到4G)和用户空间(0到3G),如下图。
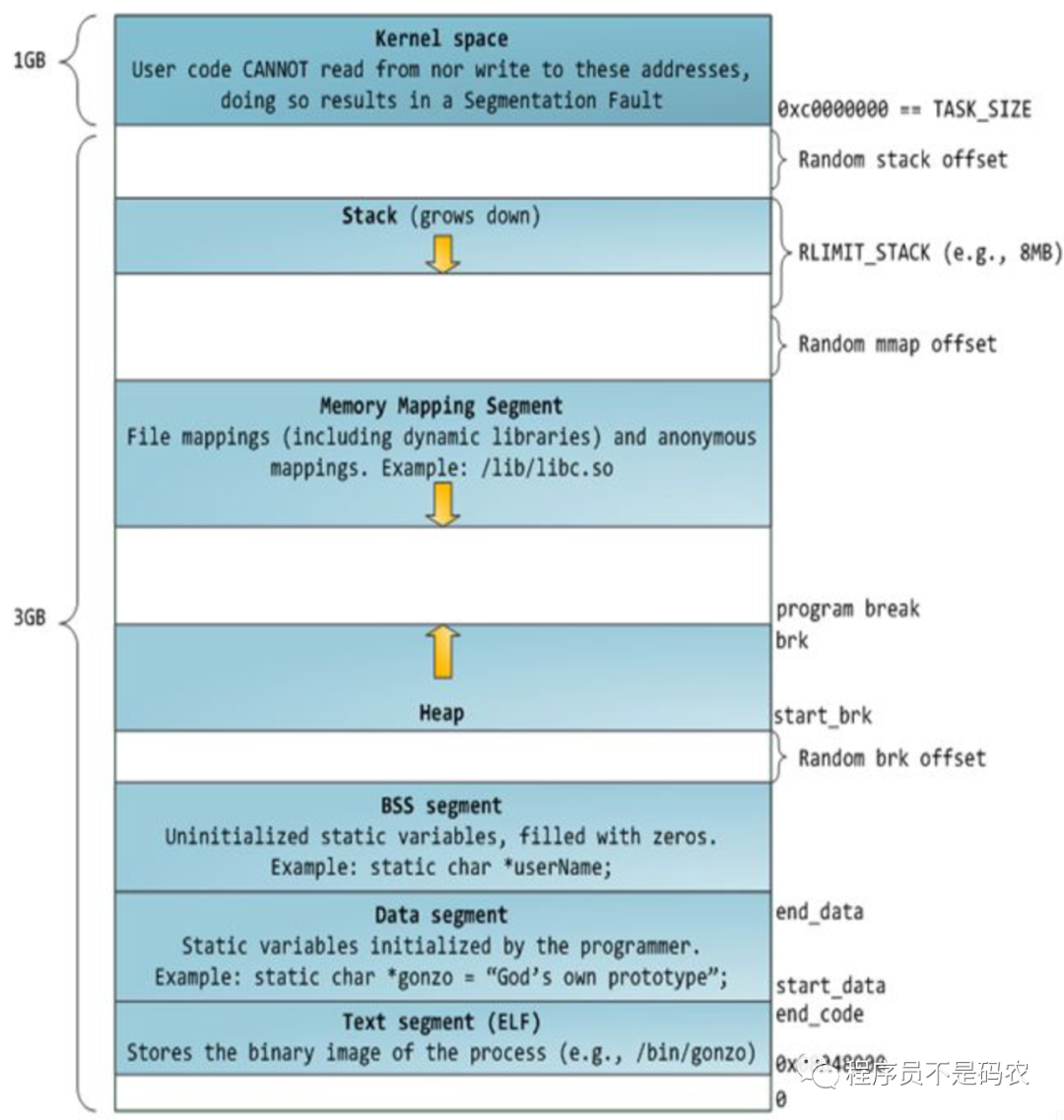
进程内存地址空间
内核通过brk和mmap来分配(虚拟)内存,malloc/free底层实现即为brk, mmap和unmmap
当malloc内存小于128k时采用brk,其通过将数据段(.data)的地址指针_edata往高地址推来分配内存,brk分配的内存需要高地址内存全部释放后才会释放,当最高地址空间空闲内存大于128K时,执行内存紧缩操作。
当malloc内存大于128K时采用mmap,其在堆栈中间的文件映射区域(Memory Mapping Segment)找空闲虚拟内存,mmap分配的内存可单独释放。
每个进程都对应一个mm_struct结构体,即唯一的进程地址空间
// include/linux/mm.h
struct vm_area_struct {
struct mm_struct * vm_mm;
};
// include/linux/sched.h
struct mm_struct {
struct vm_area_struct *mmap; // vma链表结构
struct rb_root mm_rb; // 红黑树指针
struct vm_area_struct *mmap_cache; // 指向最近找到的虚拟区间
atomic_t mm_users; // 正在使用该地址的进程数
atomic_t mm_count; // 引用计数,为0时销毁
struct list_head mmlist; // 所有mm_struct结构体都通过mmlist连接在一个双向链表中
};
linux内核用struct page结构体表示物理页:
// include/linux/mm.h
struct page {
unsigned long flags; // 页标识符
atomic_t count; // 页引用计数
struct list_head list; // 页链表
struct address_space *mapping; // 所属的inode
unsigned long index; // mapping中的偏移
struct list_head lru; // LRU最近最久未使用, struct slab结构指针链表头变量
void *virtual; // 页虚拟地址
}
内存碎片与外存碎片
内存碎片
产生原因:分配的内存空间大于请求所需的内存空间,造成内存碎片
解决办法:伙伴算法,主要包括内存分配和释放两步:
内存分配:需满足两个条件,1) 大于请求所需内存;2)为最小内存块(如64K为一页)的倍数。比如,最小内存块为64K,若分配100K内存,则应分配64*2=128K内存大小。
内存释放:包含两步,1)释放内存;2)检查是否可与相邻块合并,直到没有可合并内存块。
接下来通过一张图来详细说明伙伴算法原理(From wiki),如下:
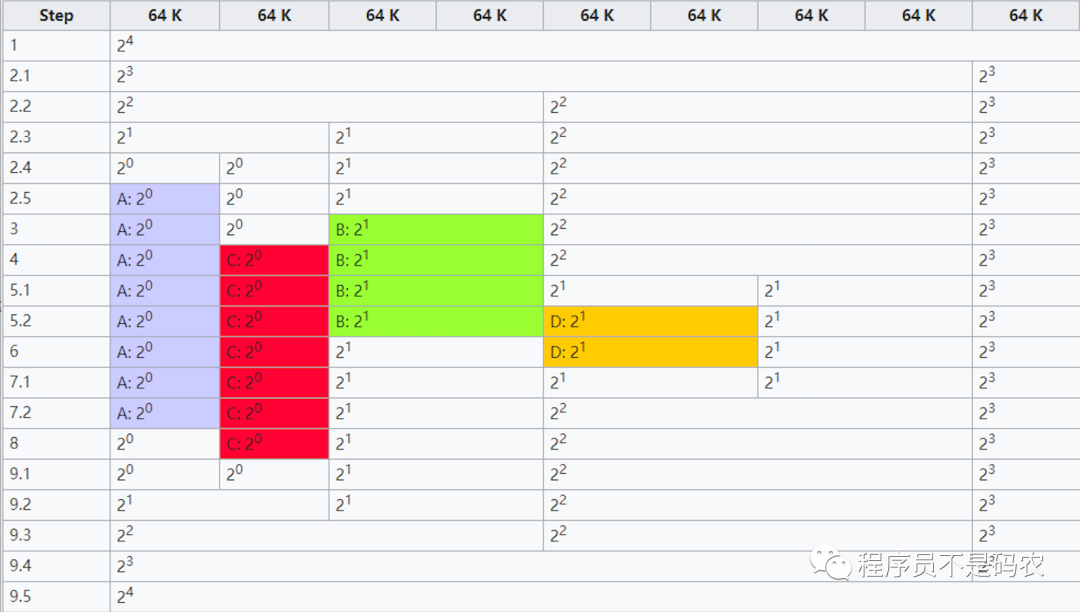
伙伴算法图解
Step步骤详解(注意最左侧Step为步骤,ABCD申请者对应不同的颜色):
初始化内存,最小内存块为64K,分配1024KB(只截取部分进行说明)
A申请34K内存,因此需64K内存块,步骤2.1 2.2 2.3 2.4都为对半操作,步骤2.5找到满足条件的块(64K),分配给A
B申请66K内存,因此需要128K内存块,有现成的直接分配
C申请35K内存,需64K内存块,直接分配
D申请67K内存,需128K内存块,步骤5.1对半操作,步骤5.2分配
释放B内存块,没有相邻内存可合并
释放D内存块,步骤7.1释放内存,步骤7.2 与相邻块进行内存合并
A释放内存,不许合并内存
C释放内存,步骤9.1释放内存,步骤9.2-9.5进行合并,整块内存恢复如初
以上为伙伴算法原理,Linux关键代码在mm/page_alloc.c中,有兴趣读者可在内核源码中阅读细节,如下:
//mm/page_alloc.c
// 块分配, removing an element from the buddy allocator
// 再zone中找到一个空闲块,order(0:单页,1:双页,2:4页 2 ^ order)
static struct page * __rmqueue(struct zone *zone, unsigned int order)
{
}
// 块释放,处理合并逻辑
static int
free_pages_bulk(struct zone *zone, int count, struct list_head *list, unsigned int order) {
}
这里简单介绍云风实现的伙伴算法,实现思路:用数组实现完全二叉树来管理内存,树节点标记使用状态,在分配和释放中通过节点的状态来进行内存块的分离与合并,如下:
// 数组实现二叉树
struct buddy {
int level; // 二叉树深度
uint8_tree[1]; // 记录二叉树用来存储内存块(节点)使用情况,柔性数组,不占内存
};
// 分配大小为s的内存
int
buddy_alloc(struct buddy * self, int s) {
// 分配大小s的内存,返回分配内存偏移量地址(首地址)
int size;
if (s == 0) {
size = 1;
} else {
// 获取大于s的最小2次幂
size = (int)next_pow_of_2(s);
}
int length = 1 《《 self-》level;
if(size 》 length)
return -1;
int index = 0;
int level = 0;
while (index 》= 0) {
//具体分配细节。..
}
return -1;
}
// 释放内存并尝试合并
void
buddy_free(struct buddy * self, int offset) {
// 释放偏移量offset开始的内存块
int left = 0;
int length = 1 《《 self-》level;
int index;
for (;;) {
switch(self-》tree[index]) {
case NODE_USED:
_combine(self, index); // 尝试合并
return;
case NODE_UNUSED:
return;
default:
// 。..
}
}
}
外存碎片
产生原因:未被分配的内存,出现大量零碎不连续小内存,无法满足较大内存申请,造成外部碎片
解决办法:采用slab分配器,处理小内存分配问题,slab分配器分配内存以字节为单位,基于伙伴系统分配的大内存进一步细分成小内存分配
slab分三种:slabs_full(完全分配的slab),slabs_partial(部分分配的slab),slabs_empty(空slab),一个slab分配满了之后就从slabs_partial删除,同时插入到slab_fulls中。
slab两个作用:1)小对象分配,不必每个小对象分配一个页,节省空间;2)内核中一些小对象创建析构频繁,slab对小对象缓存,可重复利用一些相同对象,减少内存分配次数。(应用于内核对象的缓存)。
slab分配器基于对象(内核中数据结构)进行管理,相同类型对象归为一类,每当申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元,当释放时,将其重新保存到原列表中,而不是直接返还给伙伴系统,避免内存碎片。slab分配对象时,会使用最近释放的对象的内存块,因此其驻留在cpu高速缓存中的概率会大大提高
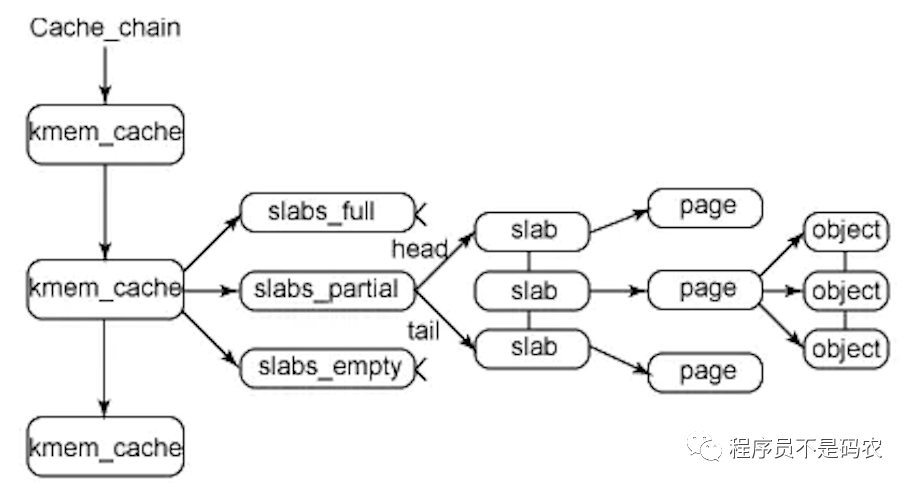
Slab分配器
三。 Python内存管理机制内存管理层次结构

Python内存层次结构
Layer 0:操作系统提供的内存管理接口,比如malloc,free,python不能干涉这一层
Layer 1:封装malloc,free等接口PyMem_API,提供统一的raw memory管理接口,为了可移植性。
Layer 2:构建了更高抽象层次的内存管理策略(GC藏身之处)
Layer 3:对象缓冲池
// 第1层 PyMem_Malloc通过一个宏PyMem_MALLOC实现
// pymem.h
PyAPI_FUNC(void *) PyMem_Malloc(size_t);
PyAPI_FUNC(void *) PyMem_Realloc(size_t);
PyAPI_FUNC(void *) PyMem_Free(size_t);
#define PyMem_MALLOC(n) ((size_t)(n) 》 (size_t)PY_SSIZE_T_MAX ? NULL
: malloc(((n) != 0) ? (n) : 1))
#define PyMem_MALLOC(n) ((size_t)(n) 》 (size_t)PY_SSIZE_T_MAX ? NULL
: realloc(((n) != 0) ? (n) : 1))
#define PyMem_FREE free
// Type-oriented memory interface 指定类型
#define PyMem_New(type, n)
( ((size_t)(n) 》 PY_SSIZE_T_MAX / sizeof(type)) ? NULL :
( (type*)PyMem_Malloc((n) * sizeof(type))) ) )
#define PyMem_NEW(type, n)
( ((size_t)(n) 》 PY_SSIZE_T_MAX / sizeof(type)) ? NULL :
( (type*)PyMem_MALLOC((n) * sizeof(type))) ) )
小块空间的内存池
Python内存池可视为一个层次结构,自下而上分为四层:block,pool,arena和内存池(概念),其中bock, pool, arena在python中都能找到实体,而内存池是由所有这些组织起来的一个概念。
Python针对小对象(小于256字节)的内存分配采用内存池来进行管理,大对象直接使用标准C的内存分配器malloc。
对小对象内存的分配器Python进行了3个等级的抽象,从上至下依次为:Arena,Pool和Block。即,Pool由Block组成,Arena由Pool组成。
Block
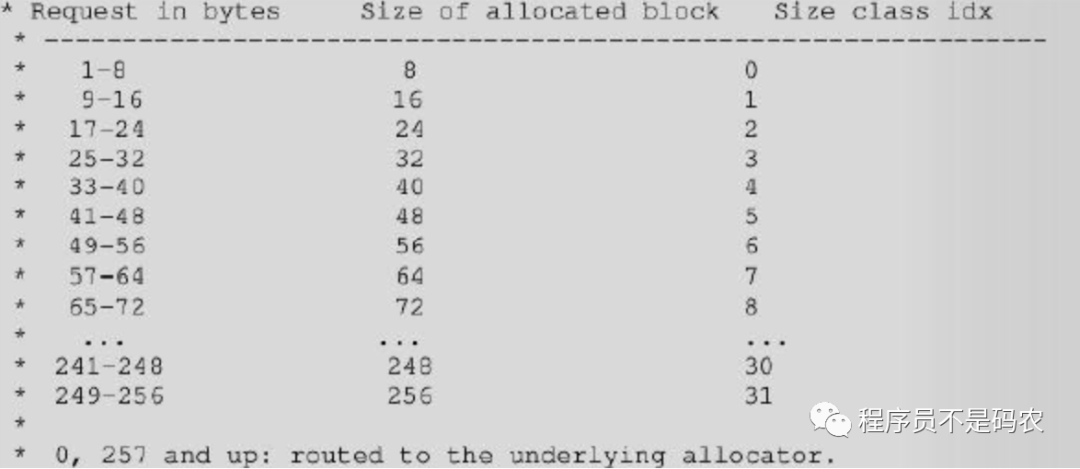
block内存大小值被称为size class, 大小为:[8, 16, 24, 32, 40, 48 。.. 256],(8*n),内存管理器的最小单元,一个Block存储一个Python对象。
// obmalloc.c
// 8字节对齐
#define ALIGNMENT 8
#define ALIGNMENT_SHIFT 3
#define ALIGNMENT_MASK (ALIGNMENT - 1)
// block大小上限为256,超过256KB,则交由第一层的内存管理机制
#define SMALL_REQUEST_THRESHOLD 256
#define NB_SMALL_SIZZE_CLASSES (SMALL_REQUEST_THREASHOLD / ALIGNMENT)
// size class index 转换到 size class
#define INDEX2SIZE(I) (((unit) (I)) + 1) 《《 ALIGMENT_SHIFT)
// sizes class 转换到size class index
size = (uint )(nbytes - 1) 》》 ALIGMENT_SHIFT;
小于256KB的小块内存分配如下图。
Block分配策略
如果申请内存大小为28字节,则PyObject_Malloc从内存池中分配32字节的block,size class index为3的pool(参考上图)。
Pool
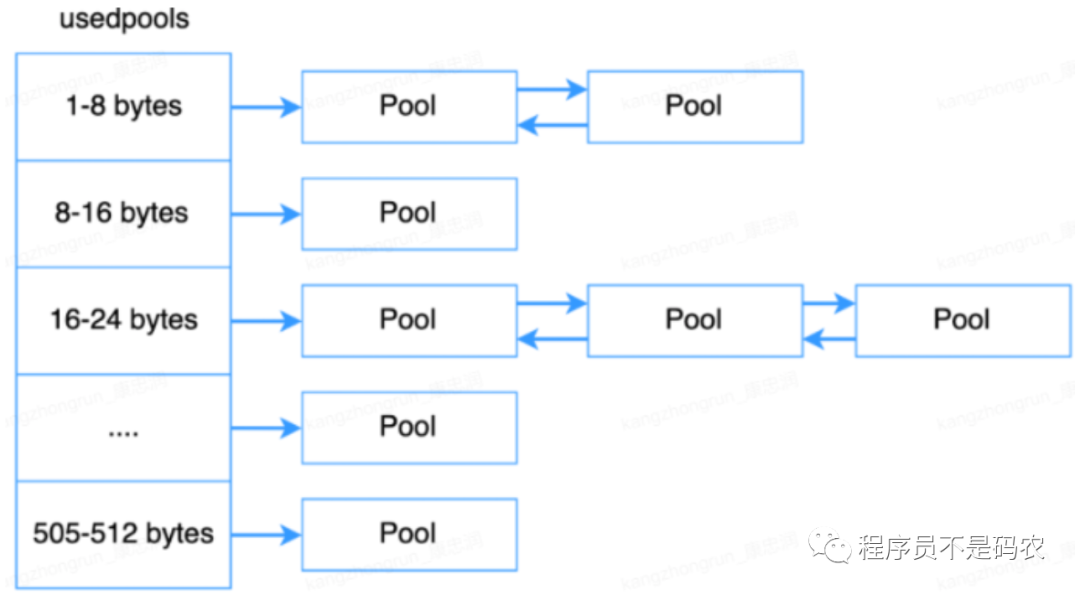
Pool为一个双向链表结构,一系列Block组成一个Pool,一个Pool中所有Block大小一样;一个Pool大小通常为4K(一个虚拟/系统内存页的大小)。
一个小对象被销毁后,其内存不会马上归还系统,而是在Pool中被管理着,用于分配给后面申请的内存对象。Pool的三种状态
used状态:Pool中至少有一个Block已被使用,且至少还有一个Block未被使用,存在usedpools数组中。
full状态:Pool中所有的block都已经被使用,这种状态的Pool在Arena中,但不再Arena的freepools链表中
empty状态:Pool中所有的Block都未被使用,处于这个状态的Pool的集合通过其pool_head中的nextpool构成一个链表,表头为arena_object中的freepools
// obmalloc.c
#define SYSTEM_PAGE_SIZE (4 * 1024)
#define SYSTEM_PAGE_SIZE_MASK (SYSTEM_PAGE_SIZE - 1)
// 一个pool大小
#define POOL_SIZE SYSTEM_PAGE_SIZE
#define POOL_SIZE_MASK SYSTEM_PAGE_SIZE_MASK
/*pool for small blocks*/
struct pool_header {
union {
block *_padding;
uint count; }ref; // 分配的block数量
block *freeblock; // 指向pool中可用block的单向链表
struct pool_header *nextpool; // 指向下一个
struct pool_header *prevpool; // 指向上一个
uint arenaindex;
// 记录pool保存的block的大小,一个pool中所有block都是szidx大小
// 和size class index联系在一起
uint szidx;
uint nextoffset;
uint maxnextoffset;
};
typedef struct pool_header *poolp;
拥有相同block大小的pool通过双向链表连接起来,python使用一个数组usedpools来管理使用中的pool
Userpools结构
以下为Python内存分配部分代码:
// obmalloc.c
typedef uchar block;
void *
PyObject_Malloc(sizes_t nbytes)
{
block *bp; // 指向从pool中取出第一块block的指针
poolp pool; // 指向一块4kb内存
poolp next;
uint size;
// 小于SMALL_REQUEST_THRESHOLD 使用Python的小块内存的内存池,否则走malloc
if ((nbytes - 1) 《 SMALL_REQUEST_THRESHOLD) {
// 根据申请内存的大小获得对应的获得size class index, 从usedpools中取pool
size = (uint)(nbytes - 1) 》》 ALIGNMENT_SHIFT;
pool = usedpools[size + size];
// 如果usedpools中有可用pool, 使用这个pool来分配block$
if (pool != pool-》nextpool) {
。..
}
}
}
Arena
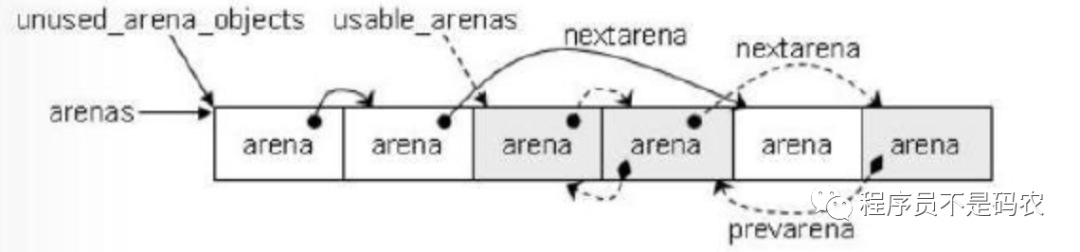
Arena是Python直接从操作系统分配和申请内存的单位,一个Arena为256KB,每个Arena包含64个Pool,Arena管理的内存是离散的,Pool管理的内存是连续的。同Pool,Arena也是一个双向链表结构。
Arena结构
Python在分配Pool的时候优先选择可用Pool数量少的Arena进行内存分配,这样做的目的是为了让Pool更为集中,避免Arena占用大量空闲内存空间,因为Python只有在Arena中所有的Pool全为空时才会释放Arena中的内存。
Python中会同时存在多个Arena,由Arenas数组统一管理。
// obmalloc.c
#define ARENA_SIZE (256 《《 10) // 256kb
// arena包含arena_object及其管理的pool集合,就如同pool和pool_header一样
struct arena_object {
uintptr_t address; // arena地址
block* pool_address; // 下一个pool地址
uint nfreepools;
uint ntotalpools;
struct pool_header* freepools; // 可用pool通过单链表连接
struct arena_object* nextarena;
struct arena_object* prearena;
};
// arenas管理着arena_object的集合
static struct arena_object* arenas = NULL;
// 未使用的arena_object链表
static struct arena_object * unused_arena_objects = NULL;
// 可用的arena_object链表
static struct arena_object * usable_arenas = NULL;
static struct arena_object * nwe_arena(void)
{
struct arena_object * arenaobj;
uint excess;
// 判断是否需要扩充“未使用的”arena_object列表
if (unused_arena_objects == NULL) {
// 确定本次需要申请的arena_object的个数,并申请内存
numarenas = maxarenas ? maxarenas 《《 1 : INITIAL_ARENA_OBJECTS;
。..
}
// 从unused_arena_objects中取出一个未使用的arena_object
arenaobj = unused_arena_objects;
unused_arena_objects = arenaobj-》nextarena;
// 建立arena_object和pool的联系
arenaobj-》address = (uptr)address;
。..
return arenaobj;
}
内存池全景图
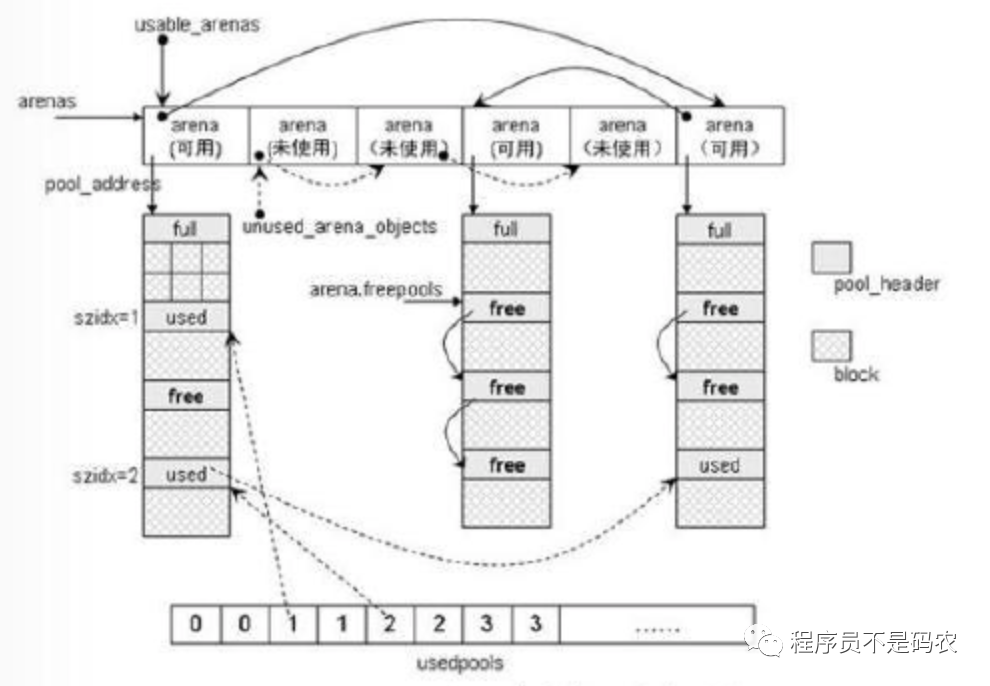
内存池全景图
四。 Nginx内存管理机制
在介绍Nginx内存管理之前,先参照Nginx实现一个简单的内存池,结构图如下:
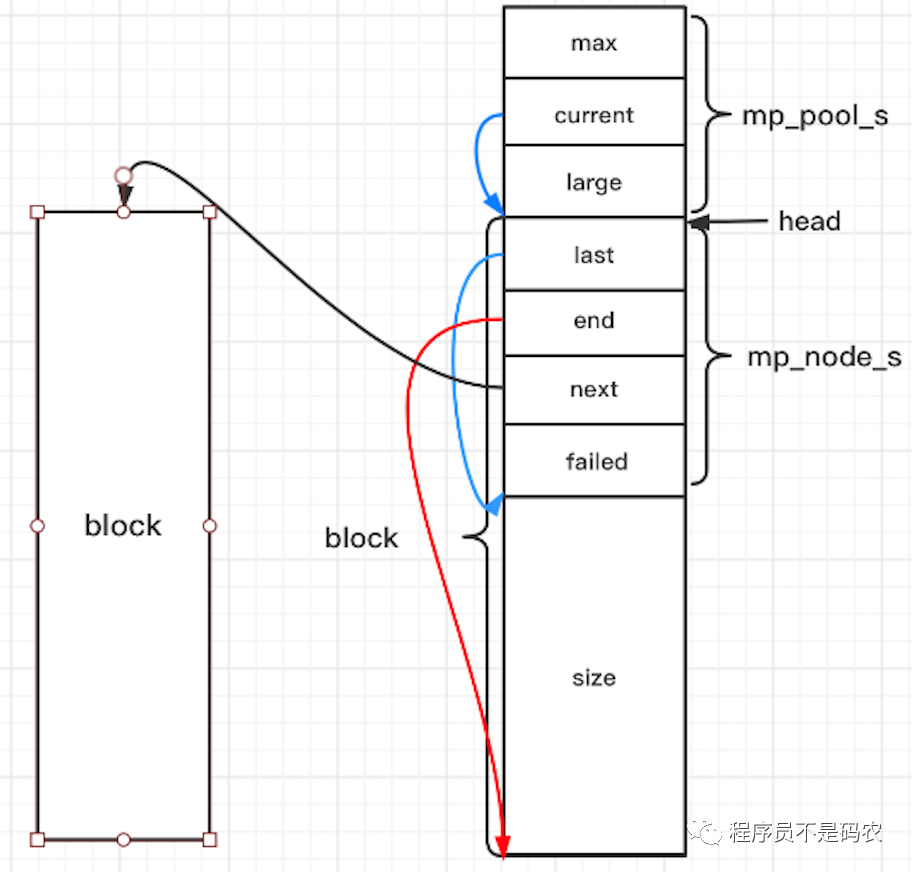
其中,mp_pool_s为内存池的结构体头,包含内存池的一些全局信息,block为小块内存块,每一个block有一个mp_node_s结构体,也即mp_pool_s通过链表将所有的block连接起来进行管理,而大块内存由mp_large_s进行分配。申明的数据结构如下:
// 结构体
// 大块内存结构体
struct mp_large_s {
struct mp_large_s *next;
void *alloc;
};
// 小块内存节点,小块内存构成一个链表
struct mp_node_s {
unsigned char *last; // 下一次内存从此分配
unsigned char *end; // 内存池结束位置
struct mp_node_s *next; // 指向下一个内存块
size_t failed; // 改内存块/node分配失败的次数
};
// 内存池结构
struct mp_pool_s {
size_t max; // 能直接从内存池中申请的最大内存,超过需要走大块内存申请逻辑
struct mp_node_s *current; // 当前分配的node
struct mp_large_s *large; // 大块内存结构体
struct mp_node_s head[0]; // 柔性数组不占用大小,其地址为紧挨着结构体的第一个node
};
// 需要实现的接口
struct mp_pool_s *mp_create_pool(size_t size); // 创建内存池
void mp_destory_pool(struct mp_pool_s *pool); // 销毁内存池
void *mp_alloc(struct mp_pool_s *pool, size_t size); // 分配内存 对齐
void mp_free(struct mp_pool_s *pool, void *p); // 释放p节点内存
接下来介绍接口实现,先介绍一个接口函数posix_memalign,函数原型如下:
int posix_memalign(void**memptr, size_t alignment, size_t size);
/* memptr: 分配好的内存空间的首地址
alignment: 对齐边界,Linux中32位系统8字节,64位系统16字节,必须为2的幂
size: 指定分配size字节大小的内存
*/
其功能类似malloc,不过其申请的内存都是对齐的。
内存池相关接口实现如下(只贴出部分代码,完整代码私信我)
// 创建并初始化内存池
struct mp_pool_s *mp_create_pool(size_t size) {
struct mp_pool_s *p;
// 分配内存池内存:mp_pool_s + mp_node_s + size
int ret = posix_memalign((void**)&p), MP_ALIGNMENT, size + sizeof(struct mp_pool_s) + sizeof(struct mp_node_s));
if (ret) { return NULL; }
// 可从内存池申请的最大内存
p-》max = (size 《 MP_MAX_ALLOC_FROM_POOL) ? size : MP_MAX_ALLOC_FROM_POOL;
p-》current = p-》head; // 当前可分配的第一个节点mp_node_s
//一些初始化工作
return p;
}
// 销毁内存池
void mp_destroy_pool(struct mp_pool_s *pool) {
struct mp_node_s *h, *n;
struct mp_large_s *l;
// 销毁大块内存
for (l = pool-》large; l; l = l-》next) { /*.。.*/}
// 销毁小块内存
h = pool-》head-》next;
while (h) {/*.。.*/}
free(pool);
}
// mp_alloc 分配内存
void *mp_alloc(struct mp_pool_s *pool, size_t size) {
if (size 《= pool-》max) { // 小块内存分配
p = pool-》current;
do {
/*.。.不断寻找下一个可用节点*/
p = p-》next; // 不够则找下一个节点
} while (p);
// 内存池中所有节点内存都不以满足分配size内存,需要再次分配一个block
return mp_alloc_block(pool, size);
}
return mp_alloc_large(pool, size); // 大块内存分配
}
// 大块节点内存释放
void mp_free(struct mp_pool_s *pool, void *p) {
struct mp_large_s *l;
for (l = pool-》large; l; l = l-》next) {
if (p == l-》alloc) {
free(l-》alloc);
//。..
}
}
}
有了上面简化版,接下来看Nginx中内存管理就比较清晰的,其原理跟上述内存池一致,先上一张图:
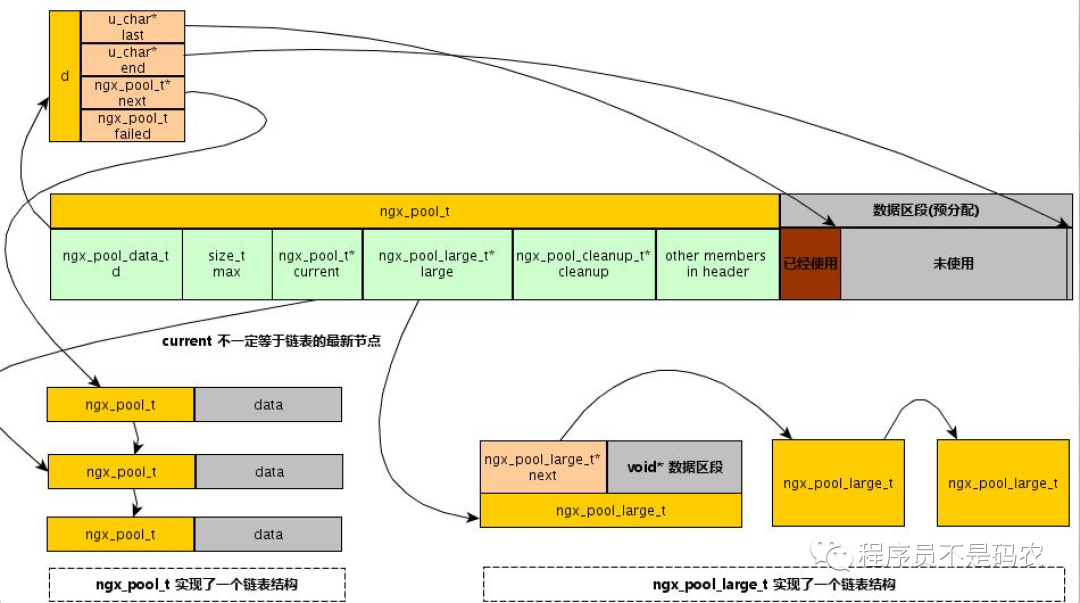
Nginx内存池结构
以下为Nginx实现,源代码主要在src/core/ngx_palloc.h/c两个文件中
// 内存块结构体,每个内存块都有,在最开头的部分,管理本块内存
typedef struct {
u_char *last; // 可用内存的起始位置,小块内存每次都从这里分配
u_char *end; // 可用内存的结束位置
ngx_pool_t *next; // 写一个内存池节点
ngx_unit_t failed; // 本节点分配失败次数,超过4次,认为本节点满,不参与分配,满的内存块也不会主动回收
}ngx_pool_data_t;
// 大块内存节点
typedef struct ngx_pool_large_s ngx_pool_large_t;
struct ngx_pool_large_s {
ngx_pool_large_t *next; // 多块大内存串成链表,方便回收利用
void *alloc; // 指向malloc分配的大块内存
};
// nginx内存池结构体
// 多个节点串成的单向链表,每个节点分配小块内存
// max,current,大块内存链表旨在头节点
// 64位系统大小位80字节,结构体没有保存内存块大小的字段,由d.end - p得到
struct ngx_pool_s {
// 本内存节点信息
ngx_pool_data_t d;
// 下面的字段旨在第一个块中有意义
size_t max; // 块最大内存
ngx_pool_t *current; // 当前使用的内存池节点
ngx_chain_t *chain;
ngx_pool_large_t *large; // 大块内存
ngx_pool_cleanup_t *cleanup; // 清理链表头指针
ngx_log_t *log;
};
// 创建内存池
ngx_pool_t *ngx_create_pool(size_t size, ngx_log_t *log);
// 销毁内存池
// 调用清理函数链表,检查大块内存链表,直接free,遍历内存池节点,逐个free
void ngx_destroy_pool(ngx_pool_t *pool);
// 重置内存池,释放内存,但不归还系统
// 之前分配的内存块依旧保留,重置空闲指针位置
void ngx_reset_pool(ngx_pool_t *pool);
// 分配内存 8字节对齐,速度快,少量浪费 》4k则直接malloc分配大块内存
void *ngx_palloc(ngx_pool_t *pool, size_t size);
void *ngx_pnalloc(ngx_pool_t *pool, size_t size); // 不对齐
void *ngx_pcalloc(ngx_pool_t *pool, size_t size); // 对齐分配,且初始化
// 大块内存free
ngx_int_t ngx_pfree(ngx_pool_t *pool, void *p);
五。 Ringbuffer环形缓冲区机制Ringbuffer的两个特性:1)先进先出;2)缓冲区用完,会回卷,丢弃久远数据,保存新数据。其结构如下图:
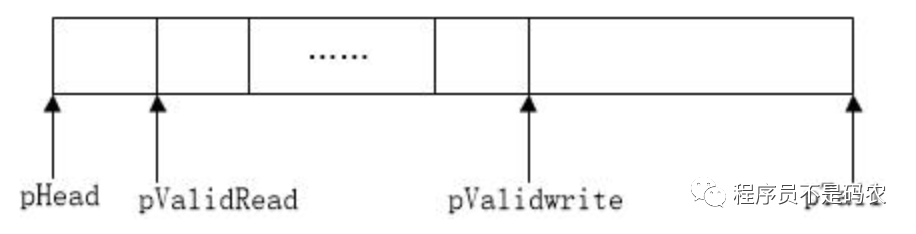
Ringbuffer结构
Ringbuffer的好处:1)减少内存分配进而减少系统调用开销;2)减少内存碎片,利于程序长期稳定运行。
应用场景:服务端程序收到多个客户端网络数据流时,可先暂存在Ringbuffer,等收到一个完整数据包时再读取。
Linux 5.1合入了一个新的异步IO框架和实现:io_uring, io_uring设计了一对共享的RingBuffer用于应用和内核之间的通信,其中,针对提交队列(SQ),应用是IO提交的生产者(producer),内核是消费者(consumer);反过来,针对完成队列(CQ),内核是完成事件的生产者,应用是消费者。
以下为一份简单Ringbuffer实现:
// ringbuffer.c
#define BUFFER_SIZE 16 // 缓冲区的长度
static u32 validLen; // 已使用的数据长度
static u8* pHead = NULL; // 环形存储区的首地址
static u8* pTail = NULL; // 环形存储区的尾地址
static u8* pValid = NULL; // 已使用的缓冲区首地址
static u8* pValidTail = NULL; // 已使用的缓冲区尾地址
// 初始化环形缓冲区
void init Ringbuffer(void) {
if (pHead == NULL) pHead = (u8*)malloc(BUFFER_SIZE);
pValid = pValidTail = pHead;
pTail = pHead + BUFFER_SIZE;
validLen = 0;
}
// 向缓冲区写入数据,buffer写入数据指针,addLen写入数据长度
int writeRingbuffer(u8* buffer, u32 addLen) {
// 将数据copy到pValidTail处
if (pValidTail + addLen 》 pTail) // ringbuffer回卷
{
int len1 = addLen - pValidTail;
int len2 = addLen - len1;
memcpy(pValidTail, buffer, len1);
memcpy(pHead, buffer + len1, len2);
pValidTail = pHead + len2; // 新的有效数据区结尾指针
} else {
memcpy(pValidTail, buffer, addLen);
pValidTail += addLen; // 新的有效数据结尾指针
}
// 重新计算已使用区的起始位置
if (validLen + addLen 》 BUFFER_SIZE) {
int moveLen = validLen + addLen - BUFFER_SIZE; // 有效指针将要移动的长度
if (pValid + moveLen 》 pTail) {
int len1 = pTail - pValid;
int len2 = moveLen - len1;
pValid = pHead + len2;
} else {
pValid = pValid + moveLen;
}
validLen = BUFFER_SIZE;
}else {
validLen += addLen;
}
return 0;
}
// 从缓冲区内取出数据,buffer读取数据的buffer,len长度
int readRingBuffer(u8* buffer, u32 len)
{
if (len 》 validLen) len = validLen;
if (pValid + len 》 pTail) { // 回卷
int len1 = pTail - pValid;
int len2 = len - len1;
memcpy(buffer, pValid, len1);
memcpy(buffer + len1, pHead, len2);
pValid = pHead + len2;
} else {
memcpy(buffer, pValid, len);
pValid = pValid + len;
}
validLen -= len;
return len;
}
六。 TCMalloc(Thread-Caching Malloc)
内存分配器以下Tcmalloc和Andriod内存管理这两部分只做简单介绍。
tcmalloc优点:内存分配效率高,运行速度快,稳定性强,能够有效降低系统负载;
应用场景:多核,高并发,多线程
tcmalloc内存申请流程:
ThreadCache对象不够,就从CentralCache中批量申请
CentralCache不够,从PageHeap申请Span
PageHeap没有适合的Page,则向操作系统申请
tcmalloc释放流程:
ThreadCache释放对象积累到一定程度,就释放给CentralCache
CentralCache中一个Span释放完全了,则把这个Span归还给PageHeap
PageHeap发现一批连续的Page都释放了,则归还给操作系统
多个连续的Page组成Span, Span 中记录起始 Page 的编号,以及 Page 数量,大对象(》32k)直接分配Span,小对象(《=32k)在Span中分配Object。以下为上述结构图解:
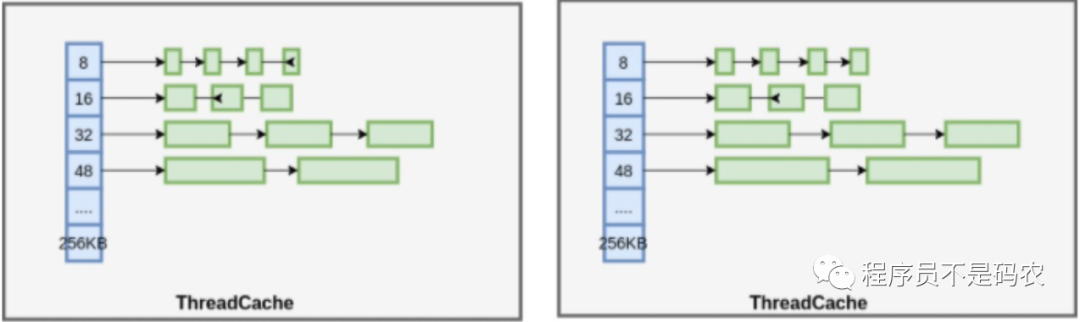
ThreadCache

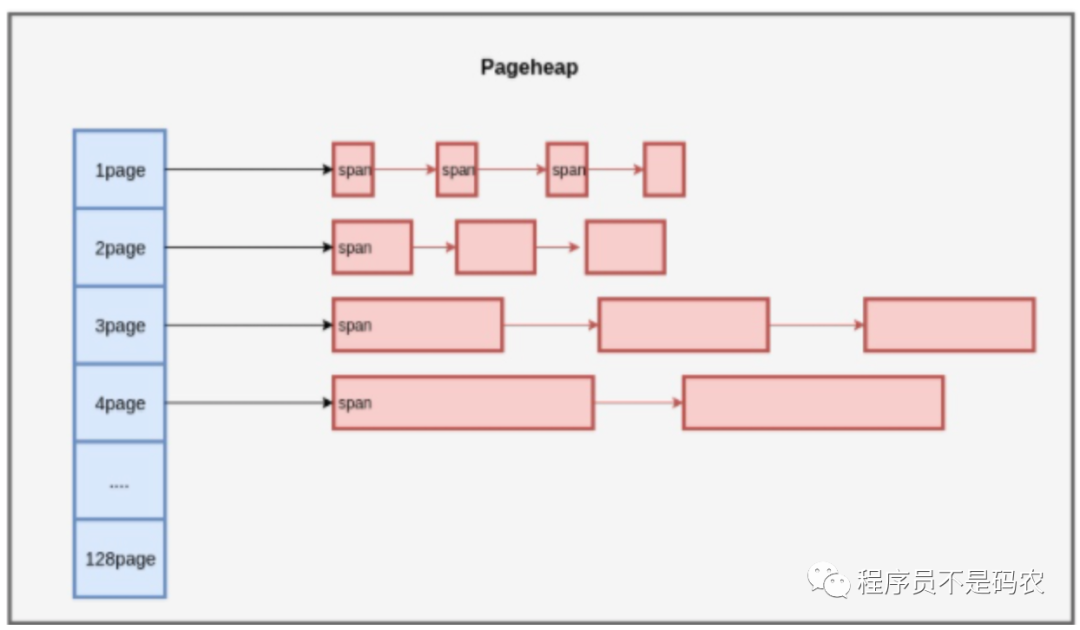
PageHeap
七。 Andriod内存管理机制
Q:Andriod的Java程序为什么容易出现OOM?
A:因为Andriod系统堆Dalvik的VM HeapSize做了硬性限制,当java进程申请的java空间超过阈值时,就会抛出OOM,这样设计的目的是为了让比较多的进程常驻内存,这样程序启动时就不用每次都重新加载到内存,能够给用户更快的响应。
Andriod系统中的应用程序基本都是Java进程。
Andriod内存管理机制
分配机制:
为每一个进程分配一个合理大小的内存块,保证每个进程能够正常运行,同时确保进程不会占用太多的内存;Andriod系统需要最大限度的让更多进程存活在内存中,以保证用户再次打开应用时减少应用的启动时间,提高用户体验。
回收机制:
当系统内存不足时,需要一个合理的回收再分配机制,以保证新的进程可以正常运行。回收时杀死那些正在占用内存的进程,OS需要提供一个合理的杀死进程机制。
编辑:lyn
-
Linux
+关注
关注
87文章
11437浏览量
212541 -
内存管理
+关注
关注
0文章
168浏览量
14447 -
python
+关注
关注
56文章
4822浏览量
86001 -
nginx
+关注
关注
0文章
163浏览量
12466
原文标题:一文浅析内存管理机制
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Linux系统中通过预留物理内存实现ARM与FPGA高效通信的方法

hyper v 内存,hyper v 内存设置的操作步骤和方法是什么?

hyper 内存,Hyper内存:如何监控与优化hyper-v虚拟机的内存使用
虚拟内存溢出该怎么处理 虚拟内存在服务器中的应用
Linux下如何管理虚拟内存 使用虚拟内存时的常见问题
虚拟内存对计算机性能的影响
什么是虚拟内存分页 Windows系统虚拟内存优化方法
虚拟内存不足如何解决 虚拟内存和物理内存的区别
虚拟内存的作用和原理 如何调整虚拟内存设置
如何优化RAM内存使用
Windows管理内存的三种主要方式
逻辑内存和物理内存的区别
把ddr内存转为固态硬盘的pcie转接卡

TwinCAT3 EtherCAT抓包 | 技术集结
在使用TwinCAT测试EtherCATEOE功能时,我们会发现正常是无法使用Wireshark去进行网络抓包抓取EtherCAT报文的,今天这篇文章就带大家来上手EtherCAT抓包方式。准备环境硬件环境:EtherKit开发板网线一根Type-CUSB线一根软件环境TwinCAT3RT-ThreadstudiowiresharkEtherCATEOE工程

EtherCAT科普系列(8):EtherCAT技术在机器视觉领域的应用
机器视觉是基于软件与硬件的组合,通过光学装置和非接触式的传感器自动地接受一个真实物体的图像,并利用软件算法处理图像以获得所需信息或用于控制机器人运动的装置。机器视觉可以赋予机器人及自动化设备获取外界信息并认知处理的能力。机器视觉系统内包含光学成像系统,可以作为自动化设备的视觉器官实现信息的输入,并借助视觉控制器代替人脑实现信息的处理与输出。从而实现赋予自动化

新品 | 26+6TOPS强悍算力!飞凌嵌入式FCU3501嵌入式控制单元发布
飞凌嵌入式FCU3501嵌入式控制单元基于瑞芯微RK3588处理器开发设计,4xCortex-A76+4xCortex-A55架构,A76主频高达2.4GHz,A55核主频高达1.8GHz,支持8K编解码,NPU算力6TOPS,支持算力卡拓展,可以插装Hailo-8 26TOPS M.2算力卡。

接口核心板必选 | 视美泰AIoT-3568SC 、 AIoT-3576SC:小身材大能量,轻松应对多场景设备扩展需求!
在智能硬件领域,「适配」是绕不开的关键词。无论是小屏设备的”寸土寸金”,还是模具开发的巨额成本,亦或是多产品线兼容的复杂需求,开发者总在寻找一款能「以不变应万变」的核心解决方案。视美泰旗下的AIoT-3568SC与AIoT-3576SC接口核心板系列,可以说是专为高灵活适配场景而生!无需为设备尺寸、模具限制或产品线差异妥协,一块核心板,即可释放无限可能。为什

3核A7+单核M0多核异构,米尔全新低功耗RK3506核心板发布
近日,米尔电子发布MYC-YR3506核心板和开发板,基于国产新一代入门级工业处理器瑞芯微RK3506,这款芯片采用三核Cortex-A7+单核Cortex-M0多核异构设计,不仅拥有丰富的工业接口、低功耗设计,还具备低延时和高实时性的特点。核心板提供RK3506B/RK3506J、商业级/工业级、512MB/256MBLPDDR3L、8GBeMMC/256
搭建树莓派网络监控系统:顶级工具与技术终极指南!
树莓派网络监控系统是一种经济高效且功能多样的解决方案,可用于监控网络性能、流量及整体运行状况。借助树莓派,我们可以搭建一个网络监控系统,实时洞察网络活动,从而帮助识别问题、优化性能并确保网络安全。安装树莓派网络监控系统有诸多益处。树莓派具备以太网接口,还内置了Wi-Fi功能,拥有足够的计算能力和内存,能够在Linux或Windows系统上运行。因此,那些为L
STM32驱动SD NAND(贴片式SD卡)全测试:GSR手环生物数据存储的擦写寿命与速度实测
在智能皮电手环及数据存储技术不断迭代的当下,主控 MCU STM32H750 与存储 SD NAND MKDV4GIL-AST 的强强联合,正引领行业进入全新发展阶段。二者凭借低功耗、高速读写与卓越稳定性的深度融合,以及高容量低成本的突出优势,成为大规模生产场景下极具竞争力的数据存储解决方案。

芯对话 | CBM16AD125Q这款ADC如何让我的性能翻倍?
综述在当今数字化时代,模数转换器(ADC)作为连接模拟世界与数字系统的关键桥梁,其技术发展对众多行业有着深远影响。从通信领域追求更高的数据传输速率与质量,到医疗影像领域渴望更精准的疾病诊断,再到工业控制领域需要适应复杂恶劣环境的稳定信号处理,ADC的性能提升成为推动这些行业进步的重要因素。行业现状分析在通信行业,5G乃至未来6G的发展,对基站信号处理提出了极
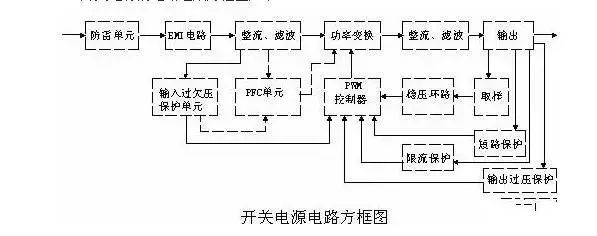
史上最全面解析:开关电源各功能电路
01开关电源的电路组成开关电源的主要电路是由输入电磁干扰滤波器(EMI)、整流滤波电路、功率变换电路、PWM控制器电路、输出整流滤波电路组成。辅助电路有输入过欠压保护电路、输出过欠压保护电路、输出过流保护电路、输出短路保护电路等。开关电源的电路组成方框图如下:02输入电路的原理及常见电路1AC输入整流滤波电路原理①防雷电路:当有雷击,产生高压经电网导入电源时
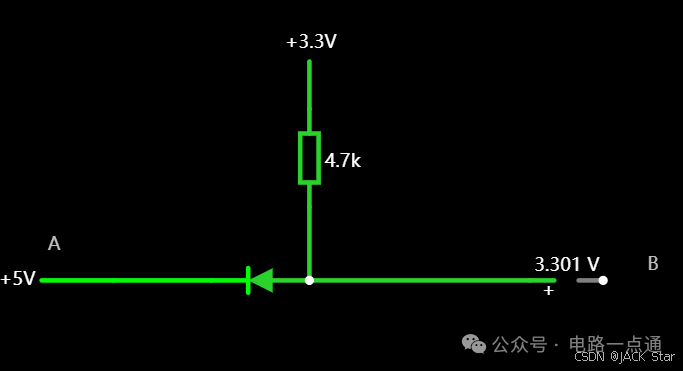
有几种电平转换电路,适用于不同的场景
一.起因一般在消费电路的元器件之间,不同的器件IO的电压是不同的,常规的有5V,3.3V,1.8V等。当器件的IO电压一样的时候,比如都是5V,都是3.3V,那么其之间可以直接通讯,比如拉中断,I2Cdata/clk脚双方直接通讯等。当器件的IO电压不一样的时候,就需要进行电平转换,不然无法实现高低电平的变化。二.电平转换电路常见的有几种电平转换电路,适用于

瑞萨RA8系列教程 | 基于 RASC 生成 Keil 工程
对于不习惯用 e2 studio 进行开发的同学,可以借助 RASC 生成 Keil 工程,然后在 Keil 环境下愉快的完成开发任务。

共赴之约 | 第二十七届中国北京国际科技产业博览会圆满落幕
作为第二十七届北京科博会的参展方,芯佰微有幸与800余家全球科技同仁共赴「科技引领创享未来」之约!文章来源:北京贸促5月11日下午,第二十七届中国北京国际科技产业博览会圆满落幕。本届北京科博会主题为“科技引领创享未来”,由北京市人民政府主办,北京市贸促会,北京市科委、中关村管委会,北京市经济和信息化局,北京市知识产权局和北辰集团共同承办。5万平方米的展览云集

道生物联与巍泰技术联合发布 RTK 无线定位系统:TurMass™ 技术与厘米级高精度定位的深度融合
道生物联与巍泰技术联合推出全新一代 RTK 无线定位系统——WTS-100(V3.0 RTK)。该系统以巍泰技术自主研发的 RTK(实时动态载波相位差分)高精度定位技术为核心,深度融合道生物联国产新兴窄带高并发 TurMass™ 无线通信技术,为室外大规模定位场景提供厘米级高精度、广覆盖、高并发、低功耗、低成本的一站式解决方案,助力行业智能化升级。

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
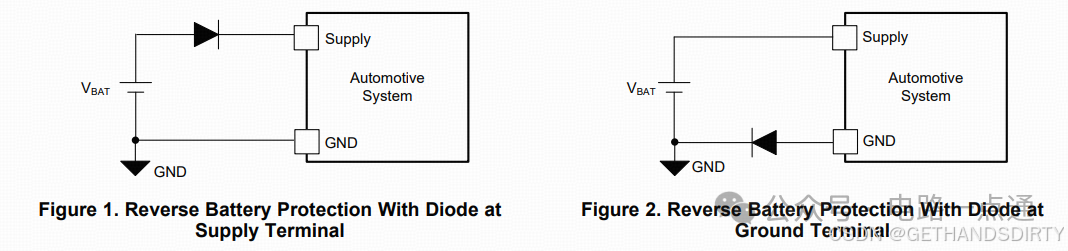
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极





 工商网监
工商网监
评论