 英伟达:5nm实验芯片用INT4达到INT8的精度
英伟达:5nm实验芯片用INT4达到INT8的精度
IEEE计算机运算研讨会。
32位与16位格式的混合精度训练,正是当前深度学习的主流。
最新的英伟达核弹GPU H100,刚刚添加上对8位浮点数格式FP8的支持。
英伟达首席科学家Bill Dally现在又表示,他们还有一个“秘密武器”:
在IEEE计算机运算研讨会上,他介绍了一种实验性5nm芯片,可以混合使用8位与4位格式,并且在4位上得到近似8位的精度。
目前这种芯片还在开发中,主要用于深度学习推理所用的INT4和INT8格式,对于如何应用在训练中也在研究了。
相关论文已发表在2022 IEEE Symposium on VLSI Technology上。

新的量化技术
降低数字格式而不造成重大精度损失,要归功于按矢量缩放量化(per-vector scaled quantization,VSQ)的技术。
具体来说,一个INT4数字只能精确表示从-8到7的16个整数。
其他数字都会四舍五入到这16个值上,中间产生的精度损失被称为量化噪声。
传统的量化方法给每个矩阵添加一个缩放因子来减少噪声,VSQ则在这基础之上给每个向量都添加缩放因子,进一步减少噪声。
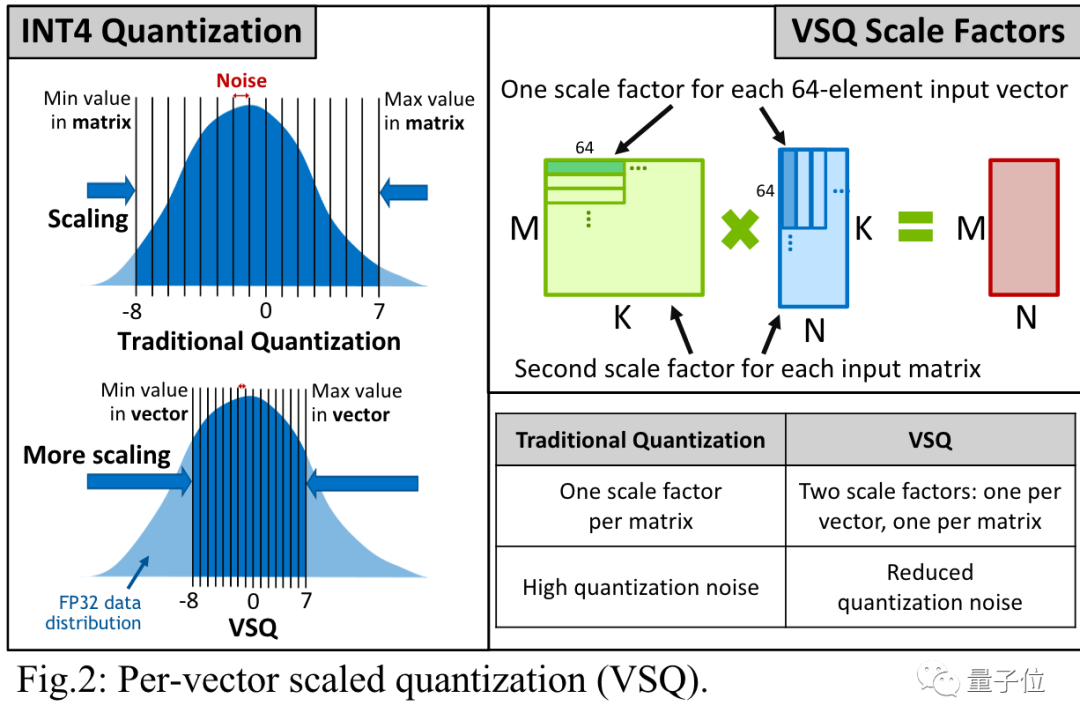
关键之处在于,缩放因子的值要匹配在神经网络中实际需要表示的数字范围。
英伟达研究人员发现,每64个数字为一组赋予独立调整过的缩放因子可以最小化量化误差。
计算缩放因子的开销可以忽略不计,从INT8降为INT4则让能量效率增加了一倍。
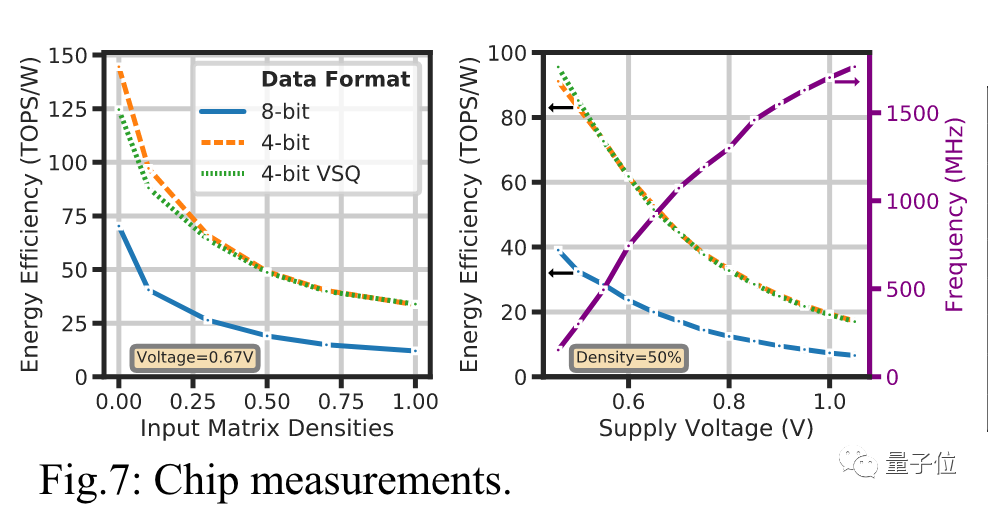
Bill Dally认为,结合上INT4计算、VSQ技术和其他优化方法后,新型芯片可以达到Hopper架构每瓦运算速度的10倍。
还有哪些降低计算量的努力
除了英伟达之外,业界还有更多降低计算量的工作也在这次IEEE研讨会上亮相。
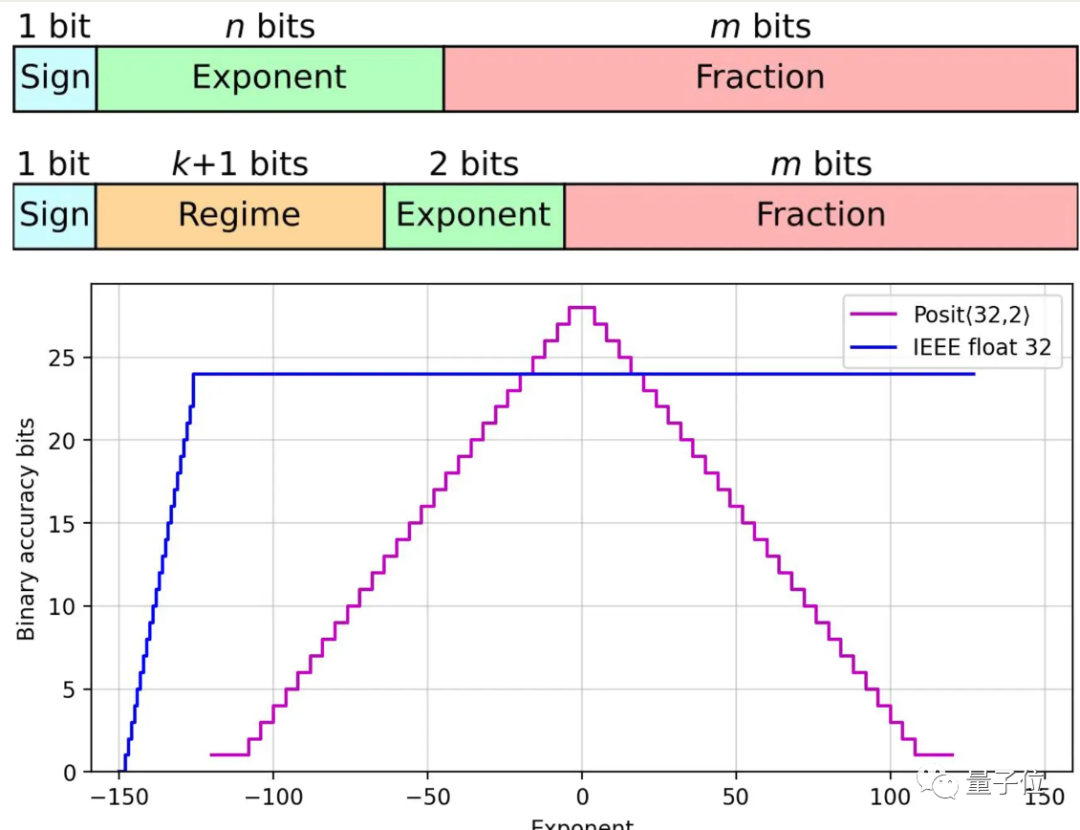
马德里康普顿斯大学的一组研究人员设计出基于Posits格式的处理器核心,与Float浮点数相比准确性提高了多达4个数量级。
Posits与Float相比,增加了一个可变长度的Regime区域,用来表示指数的指数。
对于0附近的较小数字只需要占用两个位,而这类数字正是在神经网络中大量使用的。
适用Posits格式的新硬件基于FPGA开发,研究人员发现可以用芯片的面积和功耗来提高精度,而不用增加计算时间。
ETH Zurich一个团队的研究基于RISC-V,他们把两次混合精度的积和熔加计算(fused multiply-add,FMA)放在一起平行计算。
这样可以防止两次计算之间的精度损失,还可以提高内存利用率。
FMA指的是d = a * b + c这样的操作,一般情况下输入中的a和b会使用较低精度,而c和输出的d使用较高精度。
研究人员模拟了新方法可以使计算时间减少几乎一半,同时输出精度有所提高,特别是对于大矢量的计算。
相应的硬件实现正在开发中。

巴塞罗那超算中心和英特尔团队的研究也和FMA相关,致力于神经网络训练可以完全使用BF16格式完成。
BF16格式已在DALL·E 2等大型网络训练中得到应用,不过还需要与更高精度的FP32结合,并且在两者之间来回转换。
这是因为神经网络训练中只有一部分计算不会因BF16而降低精度。
最新解决办法开发了一个扩展的格式BF16-N,将几个BF16数字组合起来表示一个数,可以在不显著牺牲精度的情况下更有效进行FMA计算
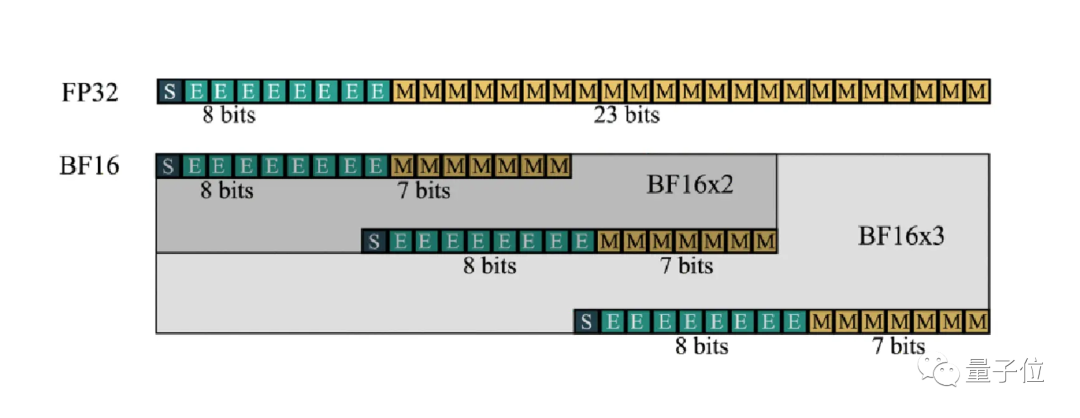
关键之处在于,FMA计算单元的面积只受尾数位影响。
比如FP32有23个尾数位,需要576个单位的面积,而BF16-2只需要192个,减少了2/3。
另外这项工作的论文题目也很有意思,BF16 is All You Need。

审核编辑 :李倩
-
芯片
+关注
关注
459文章
51940浏览量
433923 -
英伟达
+关注
关注
22文章
3900浏览量
92924
原文标题:英伟达首席科学家:5nm实验芯片用INT4达到INT8的精度
文章出处:【微信号:ICViews,微信公众号:半导体产业纵横】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
i.mx95的EIQ转换器将int8更改为uint8后出现报错怎么解决?
QuarkPi-CA2 RK3588S卡片电脑:6.0Tops NPU+8K视频编解码+接口丰富,高性能嵌入式开发!
英伟达市值一夜蒸发近2万亿 英伟达股价下跌超8%
解锁NVIDIA TensorRT-LLM的卓越性能

台积电产能爆棚:3nm与5nm工艺供不应求
英伟达超越苹果成为市值最高 英伟达取代英特尔加入道指
英伟达加速Rubin平台AI芯片推出,SK海力士提前交付HBM4存储器
AI芯片巨头英伟达涨超4% 英伟达市值暴增7500亿
esp-dl int8量化模型数据集评估精度下降的疑问求解?
触觉智能EVB3588实测运行大模型,效果nice!

进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
硬件原理图学习笔记
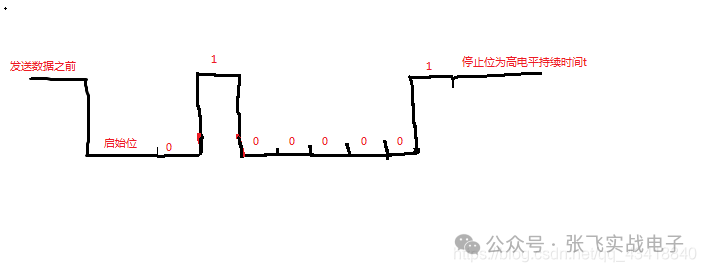
这一个星期认真学习了硬件原理图的知识,做了一些笔记,方便以后查找。硬件原理图分为三类1.管脚类(gpio)和门电路类输入输出引脚,上拉电阻,三极管与门,或门,非门上拉电阻:正向标志作用,给悬空的引脚一个确定的状态三极管:反向三极管(gpio输出高电平,NP两端导通,被控制端导通,电压为0)->NPN正向三极管(gpio输出低电平,PN两端导通,被控制端导通,

TurMass™ vs LoRa:无线通讯模块的革命性突破
TurMass™凭借其高传输速率、强大并发能力、双向传输、超强抗干扰能力、超远传输距离、全国产技术、灵活组网方案以及便捷开发等八大优势,在无线通讯领域展现出强大的竞争力。

RZT2H CR52双核BOOT流程和例程代码分析
RZT2H是多核处理器,启动时,需要一个“主核”先启动,然后主核根据规则,加载和启动其他内核。本文以T2H内部的CR52双核为例,说明T2H多核启动流程。

干簧继电器在RF信号衰减中的应用与优势
在电子测试领域,RF(射频)评估是不可或缺的一部分。无论是研发阶段的性能测试,还是生产环节的质量检测,RF测试设备都扮演着关键角色。然而,要实现精准的RF评估,测试设备需要一种特殊的电路——衰减电路。这些电路的作用是调整RF信号的强度,以便测试设备能够准确地评估RF组件和RF电路的各个方面。衰减器的挑战衰减器的核心功能是校准RF信号的强度。为了实现这一点,衰

ElfBoard嵌入式教育科普|ADC接口全面解析
当代信息技术体系中,嵌入式系统接口作为数据交互的核心基础设施,构成了设备互联的神经中枢。基于标准化通信协议与接口规范的技术架构,实现了异构设备间的高效数据交换与智能化协同作业。本文选取模数转换接口ADC作为技术解析切入点,通过系统阐释其工作机理、性能特征及重要参数,为嵌入式学习者爱好者构建全维度接口技术认知框架。

深入理解C语言:C语言循环控制
在C语言编程中,循环结构是至关重要的,它可以让程序重复执行特定的代码块,从而提高编程效率。然而,为了避免程序进入无限循环,C语言提供了多种循环控制语句,如break、continue和goto,用于改变程序的执行流程,使代码更加灵活和可控。本文将详细介绍这些语句的作用及其应用场景,并通过示例代码进行说明。Part.1break语句C语言中break语句有两种

第 21 届(顺德)家电电源与智能控制技术研讨会圆满落幕--其利天下斩获颇丰
2025年4月25日,其利天下应大比特之邀出席第21届(顺德)家电电源与智能控制技术研讨会,已圆满落幕。一、演讲回顾我司研发总监冯建武先生在研讨会上发表了主题为《重新定义风扇驱动:一套算法兼容百种电机的有效磁链观测器方案》的演讲,介绍了我司研发自适应技术算法(简称),该方案搭载有效磁链观测器,适配百种电机类型,结合FOC算法可实现免调参稳定启动、低速静音控制

来自资深工程师对ELF 2开发板的产品测评
来自资深工程师对ELF 2开发板的使用测评

飞凌嵌入式2025嵌入式及边缘AI技术论坛圆满结束
飞凌嵌入式「2025嵌入式及边缘AI技术论坛」在深圳深铁皇冠假日酒店盛大举行,此次活动邀请到了200余位嵌入式技术领域的技术专家、企业代表和工程师用户,共享嵌入式及边缘AI技术的盛宴!
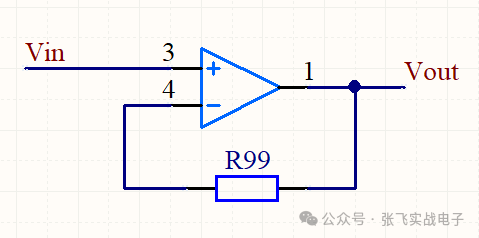
常用运放电路总结记录
一、电压跟随器电压跟随器,电路图如下:电路分析:(本文所有的运放电路分析,V+表示运放同向输入端的电压,V-表示反向输入端的电压。)1.1电压跟随器反馈电阻需不需要?在上面的电压跟随器示例中,我画上了一个反馈电阻R99,大家在学习的运放的时候,可能很多地方也会提一下这个反馈电阻,很多地方会说可加可不加,效果一样。电阻需不需要加:但是本文这里个人建议使用电压跟
运放-运算放大器经典应用电路大全-应用电路大全-20种经典电路
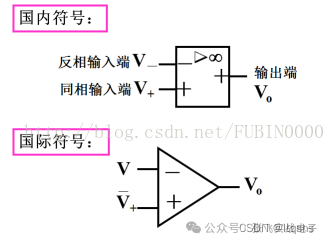
20种运放典型电路总结,电路图+公式1、运放的符号表示2、集成运算放大器的技术指标(1)开环差模电压放大倍数(开环增益)大Ao(Ad)=Vo/(V±V-)=107-1012倍;(2)共模抑制比高KCMRR=100db以上;(3)输入电阻大ri>1MW,有的可达100MW以上;(4)输出电阻小ro=几W-几十W3、集成运放分析方法(V+=V-虚短,ib-=ib

RDK X3新玩法:超沉浸下棋机器人开发日记
一、项目介绍产品中文名:超沉浸式智能移动下棋机器人产品英文名:Hackathon-TTT产品概念:本项目研发的下棋机器人,是一款能自主移动、具备语音交互并能和玩家在真实的棋盘上进行“人机博弈”的移动下棋平台,能够带给对弈者如同真人对弈的完美沉浸式体验——棋开得胜团队。该智能下棋机器人具备3个显著优点:真实棋盘棋子对弈:通过使用真实棋子、棋盘和机械臂,给对弈者

芯对话 | 微处理器监控电路革新:CBM70X系列 重构系统可靠性
总述在工业自动化、消费电子、汽车电子等领域,微处理器作为系统核心,其稳定运行依赖可靠的电源监控。据统计,65%的系统故障源于电源异常——工业控制设备因电压波动导致的停机频率每月平均达3.2次,便携式设备因电池管理不当造成的续航缩水普遍超过25%,汽车电子ECU因电源扰动引发的误判率在复杂工况下高达18%。传统监控方案的三大核心痛点极端电压适应性不足:当电压低

喜讯!米尔电子与安路科技达成IDH生态战略合作,共筑FPGA创新生态
以芯为基,智创未来。近日,领先的嵌入式模组厂商-米尔电子正式与国产FPGA企业安路科技达成IDH生态战略合作。双方将围绕安路科技飞龙SALDRAGON系列高性能FPSoC,联合开发核心板、开发板及行业解决方案,助力开发者开发成功,加速工业控制、边缘智能、汽车电子等领域的创新应用落地。米尔电子&安路科技IDH生态合作证书硬核技术+生态协同安路科技作为
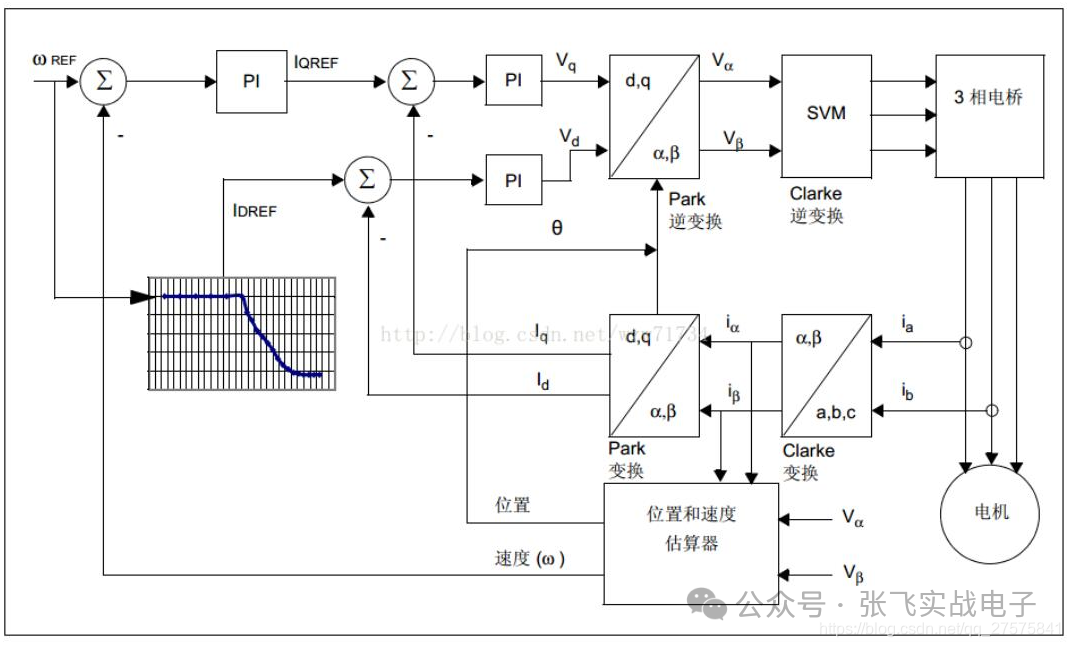
FOC控制算法详解
一、基本概念:FOC(field-orientedcontrol)为磁场导向控制,又称为矢量控制(vectorcontrol),是一种利用变频器(VFD)控制三相电机的技术,利用调整变频器的输出频率、输出电压的大小及角度,来控制电机的输出。由于处理时会将三相输出电流及电压以矢量来表示,因此称为矢量控制。二、控制原理:FOC控制的其实是电机的电磁场方向。转子的





 工商网监
工商网监
评论