 CPU中的特殊指令可以加速编码效率
CPU中的特殊指令可以加速编码效率
依据客户真实需求,定制下一代CPU是我们的工作之一,我们选择做视频转码的另一个原因,是为了设计更好满足音视频领域需求的下一代硬件。所以今天还会给大家介绍下一代CPU中关于编解码的特殊指令,这些特殊指令可以加速编码效率。
今天,我分享的内容分为三个章节。首先,使用英特尔丰富的工具链对视频转码进行分析。我们作为硬件厂商,本身不做音视频转码业务,但俗话说“弄斧要到班门”,所以我们首先对视频转码的一些典型场景进行了微架构层面的分析,为后面的优化做好铺垫。然后,介绍方案的核心思想,即如何重用一次编码的信息来提高二次编码的效率。之前提到,计算复杂度在转码里占了很大的成本,所以要从源头上降低计算复杂度。最后,介绍SIMD指令集。SIMD的全称是Single Instruction Multiple Data,意思是单指令多数据,表明一条指令可以同时操作多个数据。
01 视频转码分析
首先,我们对视频转码进行分析。
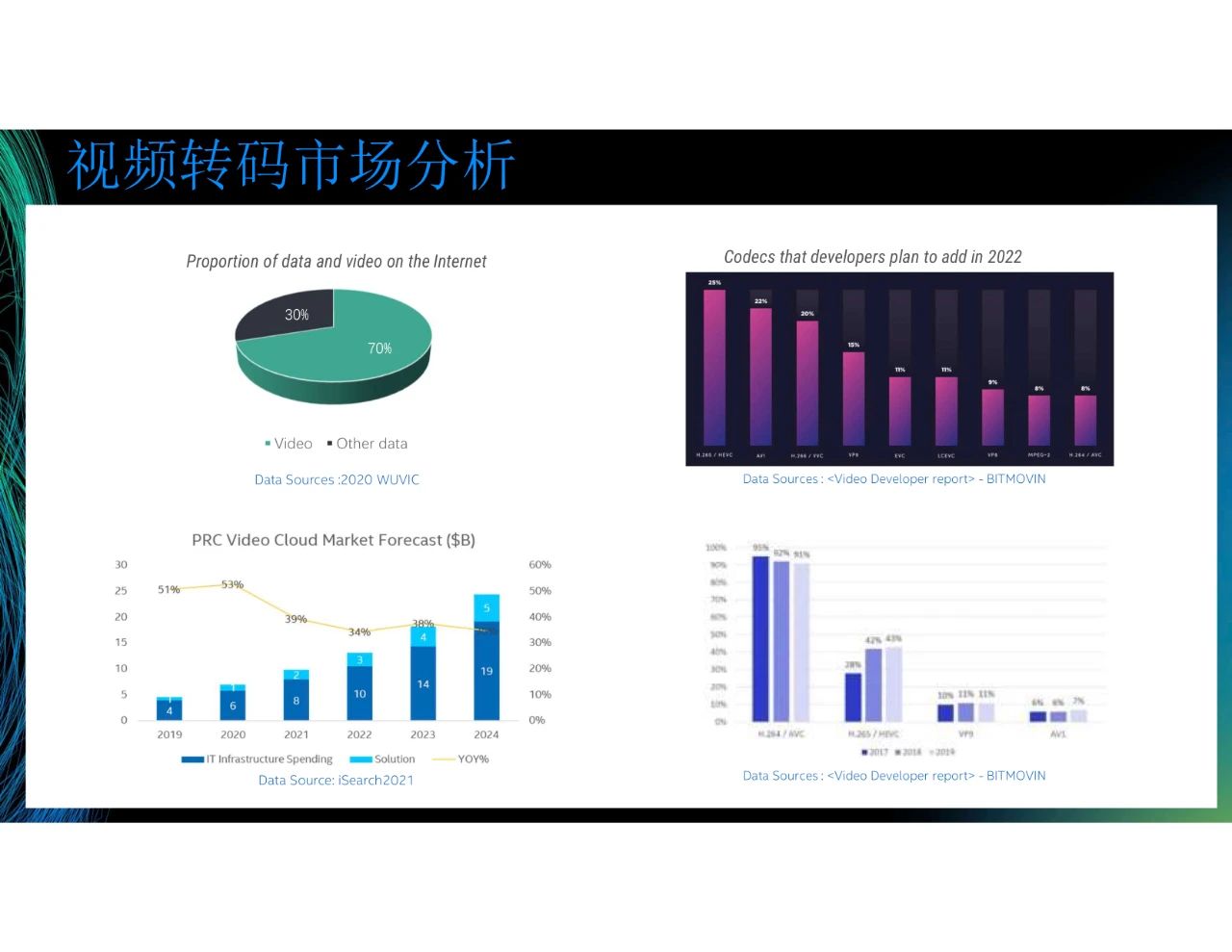
我们从相关市场获取了图中的数据。第一张图表示在2020年,视频数据在互联网数据占比70%。到现在,视频数据在互联网数据占比已超过80%。第二张图是PRC Video Cloud Market Forecast,图中呈增长趋势。虽然目前共有云市场的增速减缓,但是视频云的增长仍有很大潜力。回到转码本身,第三张图和第四张图来自Video Developer report。从第四张图可以看到,在2019年,H.264仍是主流视频编码技术,90%以上仍使用H.264。其次,较多使用的是H.265,然后是VP9和AV1,H.265也在逐渐成为一种趋势。第三张图表示视频编码器开发人员计划在2022年投入的情况。其中,投入最多的是H.265,然后是AV1,再然后是H.266,这三个协议正在成为主流编码器协议,我们后续将基于这些主流编码器进行开发。
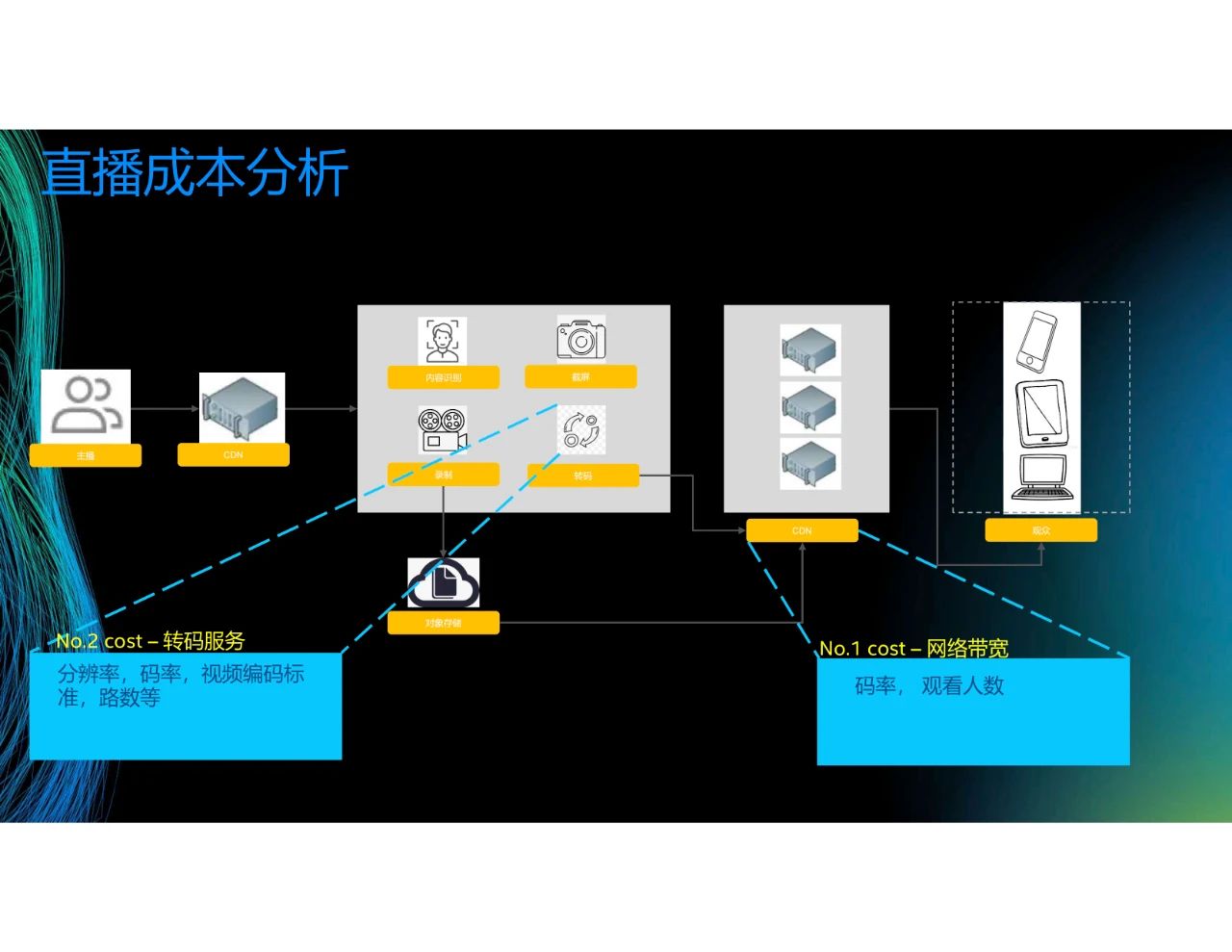
接下来进行直播成本分析。这是一张直播的结构图,主播上传内容到上行CDN,然后再发送到转码中心进行内容识别、截屏、录制和转码,接着再分发到下行CDN。这个过程中,成本最大的是网络带宽和转码服务器。之前提到,网络带宽取决于观看人数和码率。举个例子,观看2M的视频和观看500K的视频所需的网络带宽不同,1000个人同时观看视频和10个人同时观看视频所需的网络带宽也不同。转码服务取决于分辨率、码率和视频编码标准等。
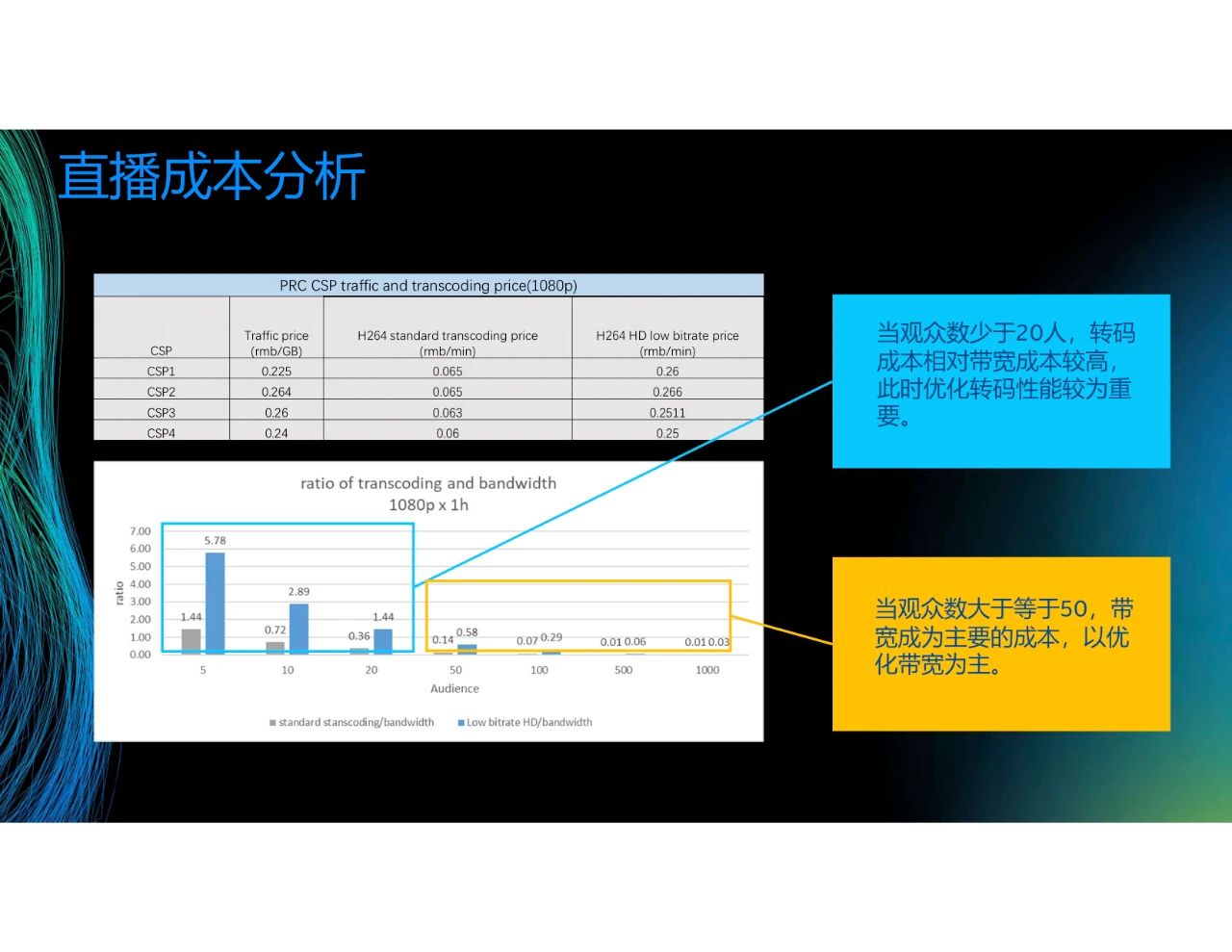
我们对头部的互联网厂商进行了分析。如第一张图所示,主要有两个成本,一个是Traffic price,即带宽成本,另一个是转码成本。第二张图表示直播一小时内,转码和带宽的比例,图的横轴是观看人数,纵轴是转码和带宽费用的比例。可以看到,当观众数大于等于50时,带宽成为主要的成本。举个例子,顶级流量主播的一场直播的带宽成本要几百万,此时转码成本只有几千块,相对带宽成本几乎可以忽略。但对于数量众多的小主播来讲,观众数可能只有十几个,此时的带宽较低,所以转码成本成为主要的成本。针对这两种情况,在带宽成本较大时,我们以优化带宽为主,在转码成本较大时,我们以优化转码速度/转码性能为主。
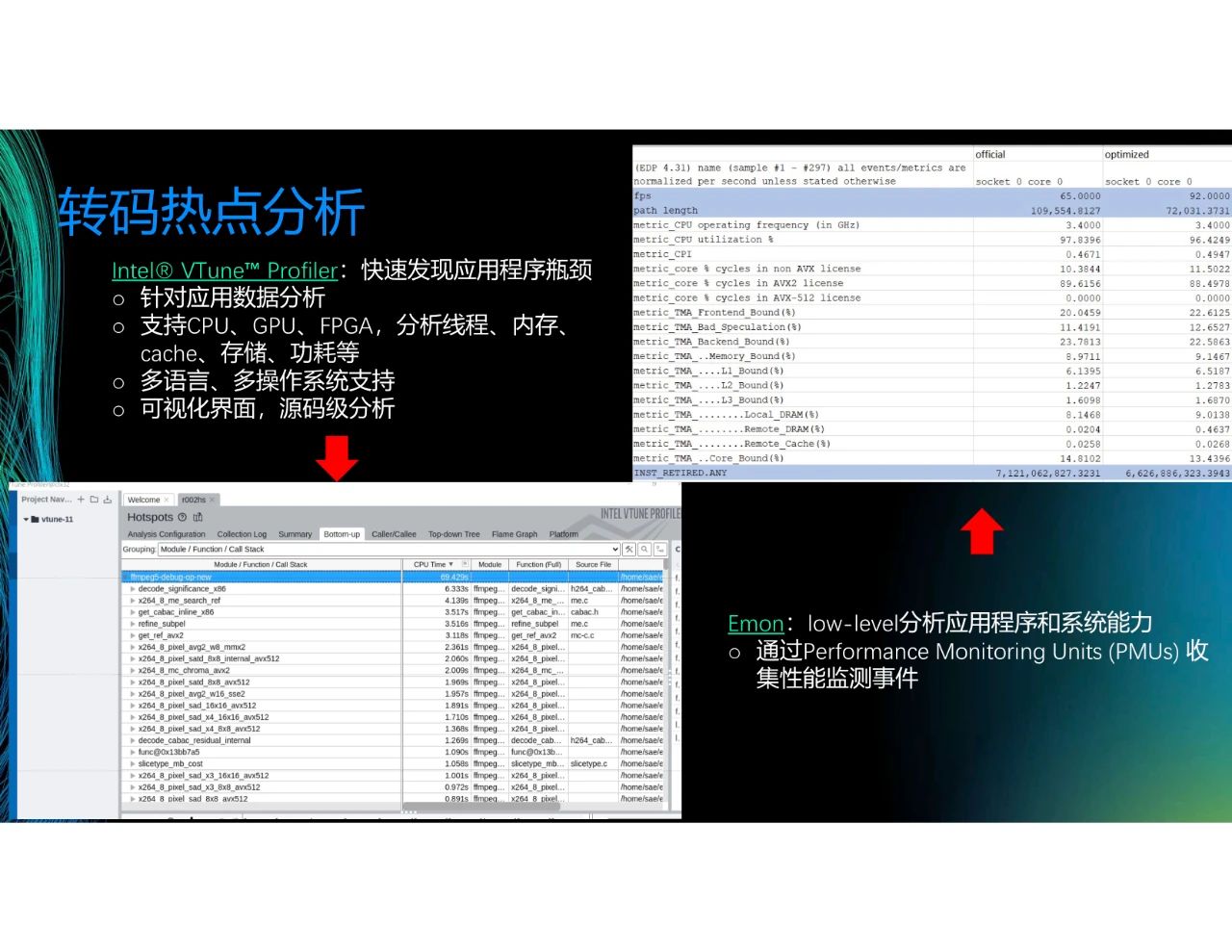
接下来,介绍几款好用的英特尔的工具。首先是V-Tune,是一个可以快速发现应用程序瓶颈的可视化的工具。左下图展示了一个例子,可以看到,我们可以知道转码里每个函数占用的CPU时间,双击就可进入code,精确定位哪行code的占比较高,所以可以清楚地知道热点函数在哪里。我们支持CPU、GPU和FPGA,也支持多语言和多操作系统。V-Tune的优点是直观,缺点是会为系统带来一定的负担。
另一个工具是Emon,其用于low-level层面的数据抓取。Emon的优点是可以直接抓取Performance Monitoring Units(PMUs),即寄存器的值,因此功率消耗较少。观察右上图,可以知道CPU的利用率、AVX指令集的使用比例,也可以知道该函数是Backend_Bound还是Frontend_Bound。因此,可以清楚知道系统的问题在哪里。
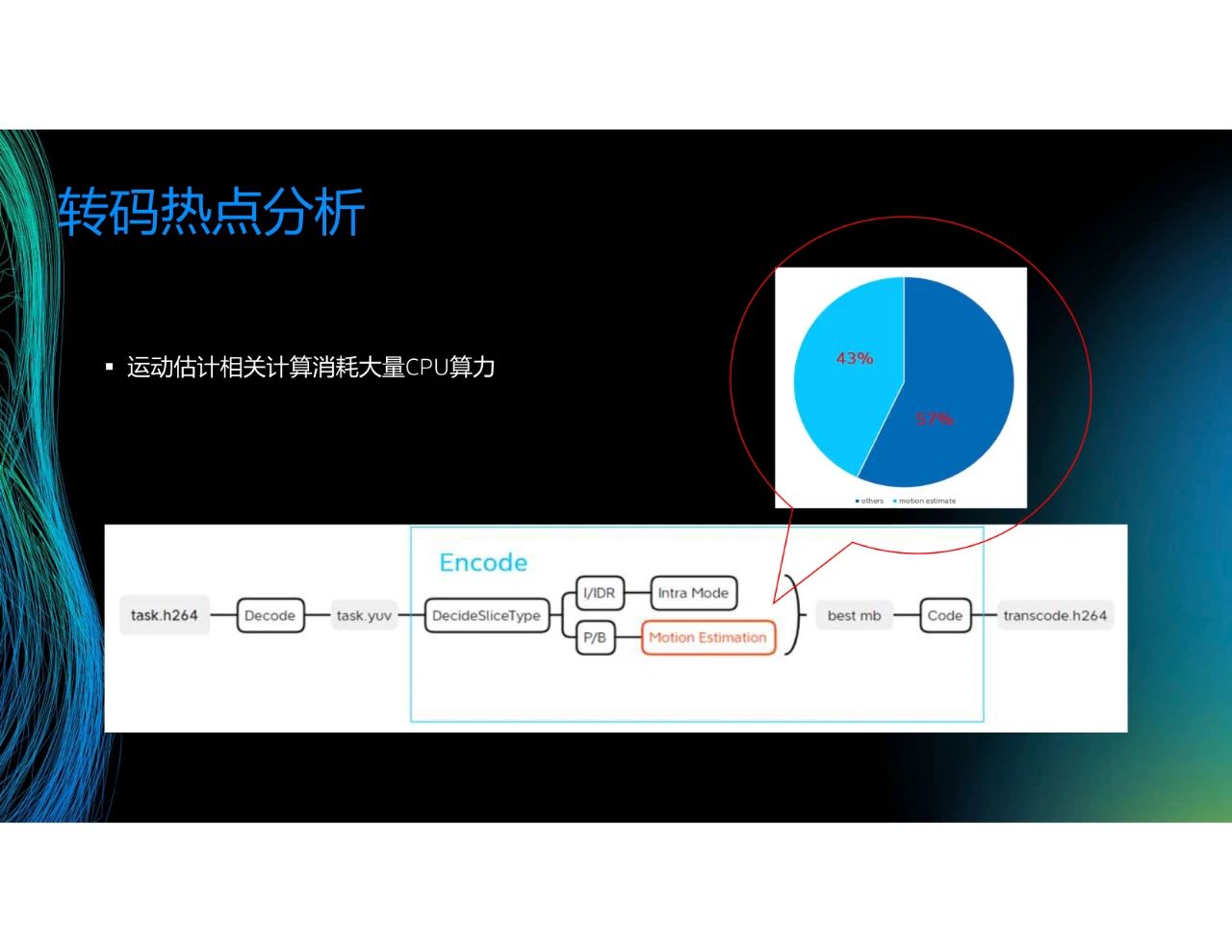
利用刚才介绍的工具,可以估计转码消耗的算力。可以看到,在某一个转码场景里,编码过程中的运动估计(Motion Estimation)占比超过40%,但不同的场景情况有所不同,举个例子,将8K的数据转换成360P的数据时,解码消耗的算力大于转码消耗的算力。在大部分情况下,若考虑帧决策等,运动估计的占比将超过50%,因此这成为了我们关注的热点。
02重用运动矢量等信息提高转码效率和质量
接下来,介绍方案的核心思想。
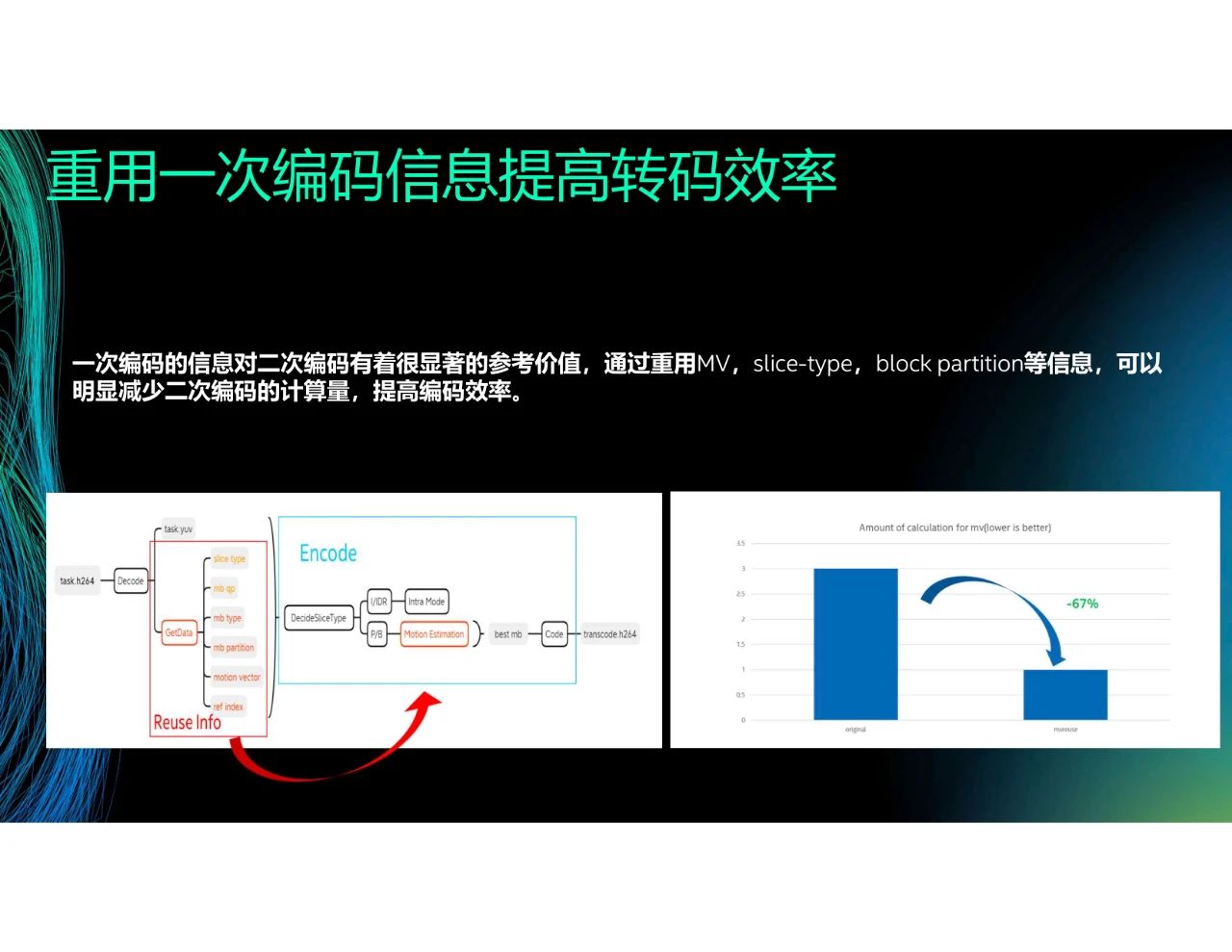
我们现在考虑转码,比如将H.264或H.265转换成H.266或AV1。在一次编码时,我们可以获得slice type、mb qp和mb partition等信息。在现在的编解码方式中,解码之后这些信息就会被舍弃。而我们的核心思想是,在二次编码中重用一次编码的信息。通过粗略计算,在大部分场景下,重用一次编码信息可以减少大约67%的运算量。
对于这种思路,大家可能有很多问题。比如,当帧率或分辨率在转码前后发生变化时,会不会出现一些新的问题。因此,虽然方案的原理比较直接,但实际应用时需要解决很多“并发症”。特别是,我们要考虑如何一方面提升转码速度,另一方面保证转码质量,否则转码质量不好,即使转码速度很快,也不能投入实用。
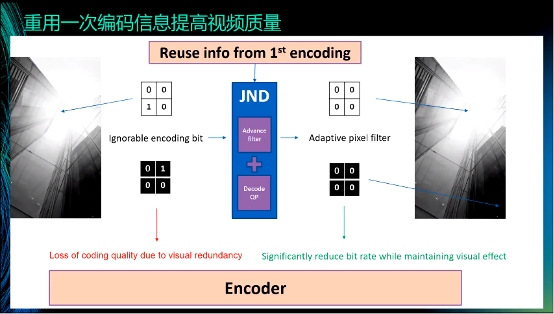
举个例子说明如何重用一次编码的信息来提高视频质量。JND是一种感知编码技术,在左上的图中,四个block中只有左下的block的值为1,其余block的值为0。但对于人眼来说,可以忽略数值1,即四个block的值可以都为0。这是JND的核心思想:过滤人眼感触不到的信息。对此,经典的方法是使用双边滤波器等进行过滤,但这些方法都是无差别的滤波,容易造成“误伤”。而现在由于掌握一次编码信息,我们知道哪些信息可以被平滑,哪些信息必须保留,通过设置权重的方式来进行“区别对待”。这样做可以带来两个好处,一是可以提高主观视觉的质量,二是在限定码率的情况下,可以将码率用在刀刃上,大幅度地提高客观质量。比如,将一个原码率是50Mbps的视频转码为2Mbps的视频,采用我们的方式就可以较大地提高质量。
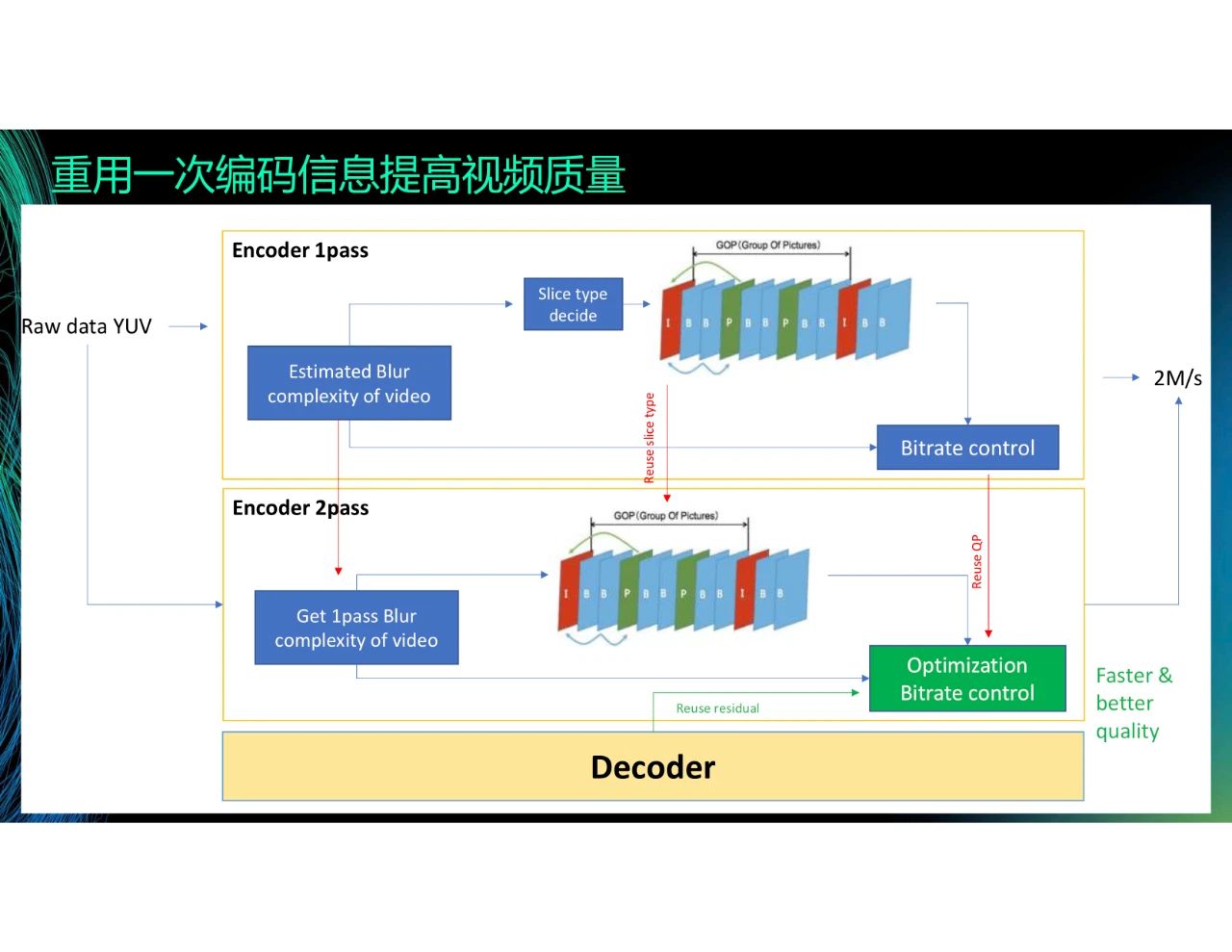
另一种方式是使用一次编码的残差。在H.264和H.265里,有two-path的算法,但这个算法通常不被使用。这是因为,虽然经过一次编码可以掌握大概的信息,并且在此基础上二次编码的结果更精准,编码质量更高且码率更低,但是这会大幅度地增加计算量,推高转码成本和延迟。为了解决这个问题,我们直接重用一次编码的信息来实现类似二次编码的效果。
03SIMD指令集加速转码热点函数
最后,介绍如何用SIMD指令集加速转码热点函数。
至强服务器平台SIMD指令集经迭代了很多代,大家比较熟知的比如AVX2,AVX512等。第二代至强可扩展平台在AVX512的基础上支持了INT8数据精度,第三代支持BF16指令集,2023年初量产的第四代平台的AI性能在BF16和INT8上较上一代提升了8倍,其中加入了AMX 指令集,也可以理解为在CPU内部有一块硬件加速器。比如INT8的算力,一颗CPU的性能接近200T,很多以前在CPU上无法完成的运算现在都成为可能。

最后介绍一个例子,说明如何使用SIMD指令集优化视频编码。在H.264中有一个大小为16×16的宏块,需要对其求和或平方和,那么如何用avx512对其进行加速呢?需要执行以下几步。首先,将16个int8的数据载入到mm128寄存器中。然后,将int8数据转换成int32,这是因为有时候运算结果为负数,而int8无法表示负数。接着,将16个int32数据水平相加,这需要消耗0.5个指令周期,而手动计算则需要8次计算,因此极大地提高了效率。最后,将16个int32平方后再水平相加。经过这样的处理,性能可提高16倍或8倍(若为一条指令则提高16倍,若为两条指令则提高8倍)。
审核编辑:刘清
-
编码器
+关注
关注
45文章
3753浏览量
136670 -
编解码
+关注
关注
1文章
143浏览量
19928 -
SIMD
+关注
关注
0文章
35浏览量
10460 -
视频转码
+关注
关注
0文章
14浏览量
7590
原文标题:基于运动矢量重用的转码优化
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
走进连接器界‘摩斯密码’特殊编码丨L、T、S解读

CPU怎么降频 bios中如何把cpu调低频率
CPU(中央处理器)的概念、结构特点和在系统中的地位

如何提高编码器的工作效率与作用
如何限制容器可以使用的CPU资源

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--了解算力芯片CPU
CPU时钟周期、机器周期和指令周期的关系
CISC(复杂指令集)与RISC(精简指令集)的区别
AGV轮毂电机中的编码器

cpu控制器负责什么运算
数控车床t指令对刀步骤
CPU中寄存器的用途
微软推进CPU指令集更新,旧版CPU或无法运行Edge浏览器

飞凌嵌入式携手中移物联,谱写全国产化方案新生态
4月22日,飞凌嵌入式“2025嵌入式及边缘AI技术论坛”在深圳成功举办。中移物联网有限公司(以下简称“中移物联”)携OneOS操作系统与飞凌嵌入式共同推出的工业级核心板亮相会议展区,操作系统产品部高级专家严镭受邀作《OneOS工业操作系统——助力国产化智能制造》主题演讲。
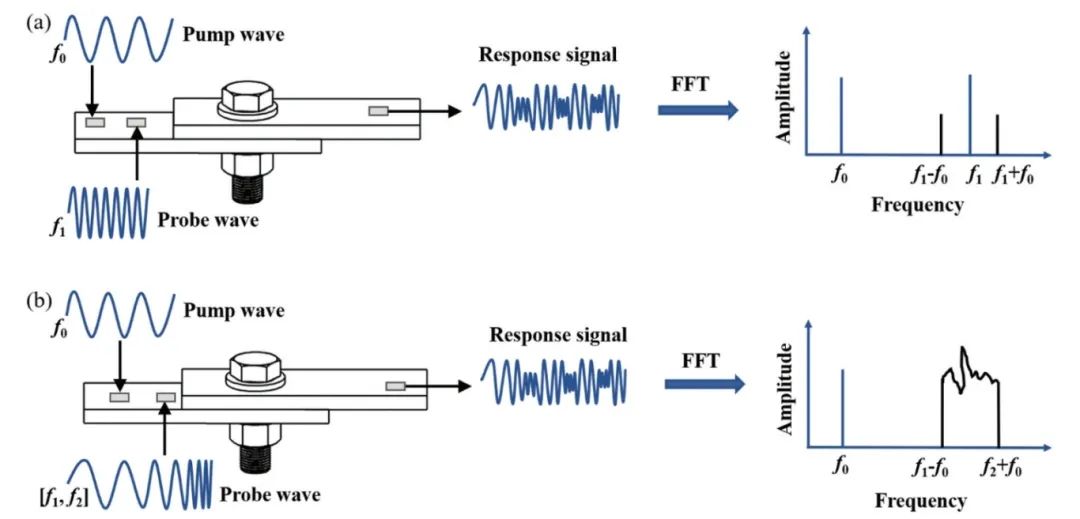
ATA-2022B高压放大器在螺栓松动检测中的应用
实验名称:ATA-2022B高压放大器在螺栓松动检测中的应用实验方向:超声检测实验设备:ATA-2022B高压放大器、函数信号发生器,压电陶瓷片,数据采集卡,示波器,PC等实验内容:本研究基于振动声调制的螺栓松动检测方法,其中低频泵浦波采用单频信号,而高频探测波采用扫频信号,利用泵浦波和探测波在接触面的振动声调制响应对螺栓的松动程度进行检测。通过螺栓松动检测
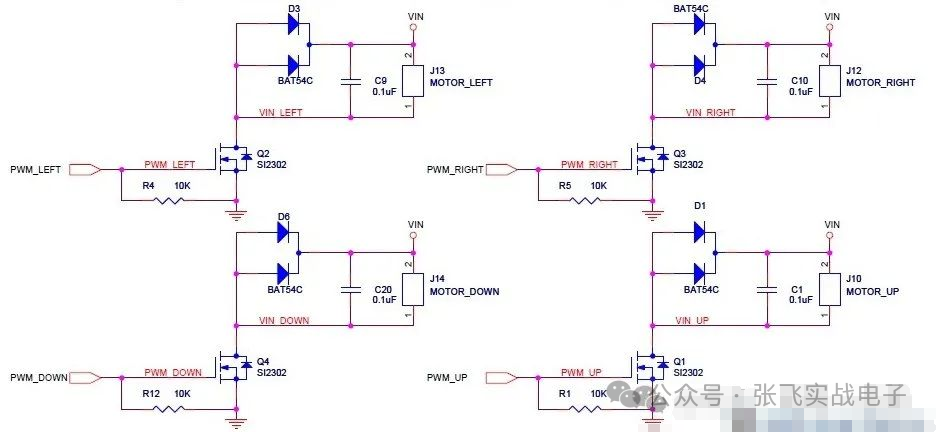
MOS管驱动电路——电机干扰与防护处理
此电路分主电路(完成功能)和保护功能电路。MOS管驱动相关知识:1、跟双极性晶体管相比,一般认为使MOS管导通不需要电流,只要GS电压(Vbe类似)高于一定的值,就可以了。MOS管和晶体管向比较c,b,e—–>d(漏),g(栅),s(源)。2、NMOS的特性,Vgs大于一定的值就会导通,适合用于源极接地时的情况(低端驱动),只要栅极电压达到4V或10V就可以
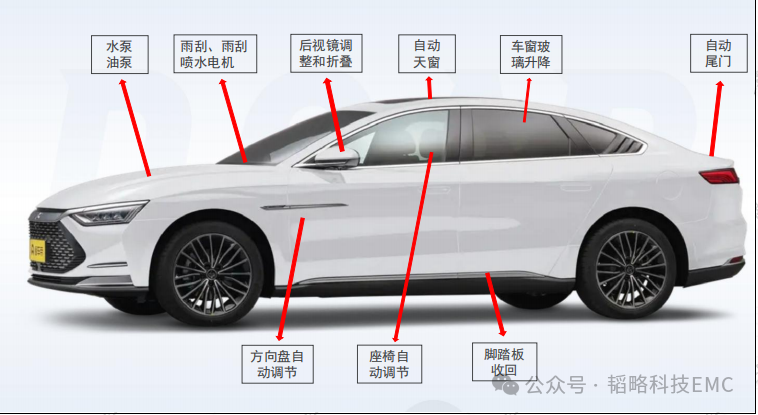
压敏(MOV)在电机上的应用剖析
一前言有刷直流电机是一种较为常见的直流电机。它的主要特点包括:1.结构相对简单,由定子、转子、电刷和换向器等组成;2.通过电刷与换向器的接触来实现电流的换向,从而使电枢绕组中的电流方向周期性改变,保证电机持续运转;3.具有调速性能较好等优点,可以通过改变电压等方式较为方便地调节转速。有刷直流电机在许多领域都有应用,比如一些电动工具、玩具、小型机械等。但它也存
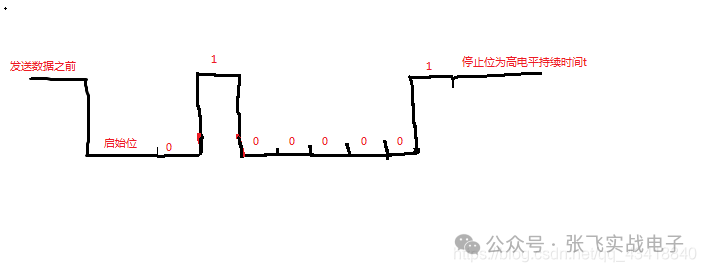
硬件原理图学习笔记
这一个星期认真学习了硬件原理图的知识,做了一些笔记,方便以后查找。硬件原理图分为三类1.管脚类(gpio)和门电路类输入输出引脚,上拉电阻,三极管与门,或门,非门上拉电阻:正向标志作用,给悬空的引脚一个确定的状态三极管:反向三极管(gpio输出高电平,NP两端导通,被控制端导通,电压为0)->NPN正向三极管(gpio输出低电平,PN两端导通,被控制端导通,

TurMass™ vs LoRa:无线通讯模块的革命性突破
TurMass™凭借其高传输速率、强大并发能力、双向传输、超强抗干扰能力、超远传输距离、全国产技术、灵活组网方案以及便捷开发等八大优势,在无线通讯领域展现出强大的竞争力。

RZT2H CR52双核BOOT流程和例程代码分析
RZT2H是多核处理器,启动时,需要一个“主核”先启动,然后主核根据规则,加载和启动其他内核。本文以T2H内部的CR52双核为例,说明T2H多核启动流程。

干簧继电器在RF信号衰减中的应用与优势
在电子测试领域,RF(射频)评估是不可或缺的一部分。无论是研发阶段的性能测试,还是生产环节的质量检测,RF测试设备都扮演着关键角色。然而,要实现精准的RF评估,测试设备需要一种特殊的电路——衰减电路。这些电路的作用是调整RF信号的强度,以便测试设备能够准确地评估RF组件和RF电路的各个方面。衰减器的挑战衰减器的核心功能是校准RF信号的强度。为了实现这一点,衰

ElfBoard嵌入式教育科普|ADC接口全面解析
当代信息技术体系中,嵌入式系统接口作为数据交互的核心基础设施,构成了设备互联的神经中枢。基于标准化通信协议与接口规范的技术架构,实现了异构设备间的高效数据交换与智能化协同作业。本文选取模数转换接口ADC作为技术解析切入点,通过系统阐释其工作机理、性能特征及重要参数,为嵌入式学习者爱好者构建全维度接口技术认知框架。

深入理解C语言:C语言循环控制
在C语言编程中,循环结构是至关重要的,它可以让程序重复执行特定的代码块,从而提高编程效率。然而,为了避免程序进入无限循环,C语言提供了多种循环控制语句,如break、continue和goto,用于改变程序的执行流程,使代码更加灵活和可控。本文将详细介绍这些语句的作用及其应用场景,并通过示例代码进行说明。Part.1break语句C语言中break语句有两种

第 21 届(顺德)家电电源与智能控制技术研讨会圆满落幕--其利天下斩获颇丰
2025年4月25日,其利天下应大比特之邀出席第21届(顺德)家电电源与智能控制技术研讨会,已圆满落幕。一、演讲回顾我司研发总监冯建武先生在研讨会上发表了主题为《重新定义风扇驱动:一套算法兼容百种电机的有效磁链观测器方案》的演讲,介绍了我司研发自适应技术算法(简称),该方案搭载有效磁链观测器,适配百种电机类型,结合FOC算法可实现免调参稳定启动、低速静音控制

来自资深工程师对ELF 2开发板的产品测评
来自资深工程师对ELF 2开发板的使用测评

飞凌嵌入式2025嵌入式及边缘AI技术论坛圆满结束
飞凌嵌入式「2025嵌入式及边缘AI技术论坛」在深圳深铁皇冠假日酒店盛大举行,此次活动邀请到了200余位嵌入式技术领域的技术专家、企业代表和工程师用户,共享嵌入式及边缘AI技术的盛宴!
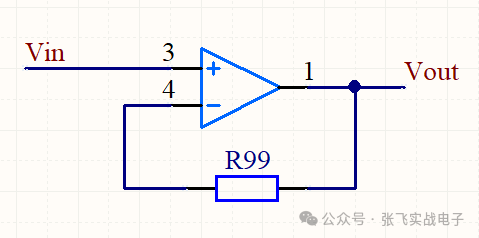
常用运放电路总结记录
一、电压跟随器电压跟随器,电路图如下:电路分析:(本文所有的运放电路分析,V+表示运放同向输入端的电压,V-表示反向输入端的电压。)1.1电压跟随器反馈电阻需不需要?在上面的电压跟随器示例中,我画上了一个反馈电阻R99,大家在学习的运放的时候,可能很多地方也会提一下这个反馈电阻,很多地方会说可加可不加,效果一样。电阻需不需要加:但是本文这里个人建议使用电压跟
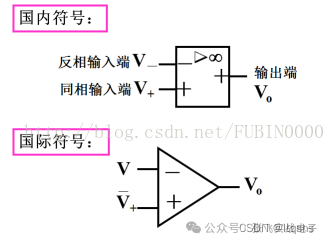
运放-运算放大器经典应用电路大全-应用电路大全-20种经典电路
20种运放典型电路总结,电路图+公式1、运放的符号表示2、集成运算放大器的技术指标(1)开环差模电压放大倍数(开环增益)大Ao(Ad)=Vo/(V±V-)=107-1012倍;(2)共模抑制比高KCMRR=100db以上;(3)输入电阻大ri>1MW,有的可达100MW以上;(4)输出电阻小ro=几W-几十W3、集成运放分析方法(V+=V-虚短,ib-=ib





 工商网监
工商网监
评论