 剖析MySQL InnoDB存储原理(下)
剖析MySQL InnoDB存储原理(下)
一、InnoDB存储引擎内存管理
1.1 概念:
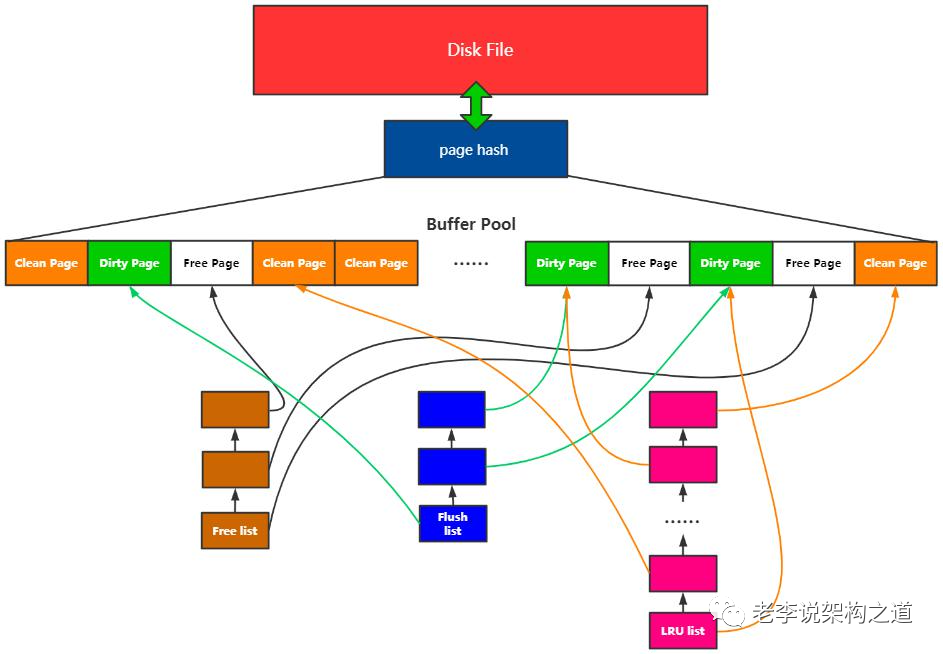
Buffer Pool:预分配的内存池;
Page:Buffer Pool的最小单位;
Free list:空闲Page组成的链表;
Flush list:脏页链表;
Page hash 表:维护内存Page和文件Page的映射关系;
这几个概念关系,如图所示:
1.2 内存的淘汰算法:LRU
分为三部分:LRU_new、LRU_old、MidPoint。如下图所描述:

1.2.1 页面装载的逻辑如图:

数据从磁盘到内存 > Free list中取 > LRU中淘汰 > LRU Flush
1.2.2 页面淘汰
LRU链表中将第一个脏页刷盘并“释放”,放到Free list中。
1.2.3 位置移动

innodb_old_blocks_time old区存活时间,大于此值,有机会进入new区
Midpoint:指向5/8位置
为了减少移动到次数和lock,思路访问时间 + 频率,避免热数据被移除,通过如下:freed_page_clock:Buffer Pool淘汰页数
移动时机:
当前freed_page_clock - 上次移动到Header时freed_page_clock >LRU_new长度1/4
2、MySQL事务管理机制原理分析
1、基本概念:
1.1 事务特性:
A(Atomicity原子性):全部成功或全部失败
I(Isolation隔离性):并行事务之间互不干扰
D(Durability持久性):事务提交后,永久生效
C(Consistency一致性):通过AID保证
1.2 并发问题:
脏读(Drity Read):读取到未提交的数据
不可重复读(Non-repeatable read):两次读取结果不同
幻读(Phantom Read):select 操作得到的结果所表征的数据状态无法支撑后续的业务操作
1.3 隔离级别
Read Uncommitted(读取未提交内容):最低隔离级别,会读取到其他事务未提交的数据,脏读;
Read Committed(读取提交内容):事务过程中可以读取到其他事务已提交的数据,不可重复读;
Repeatable Read(可重复读):每次读取相同结果集,不管其他事务是否提交,幻读;
Serializable(串行化):事务排队,隔离级别最高,性能最差;
2、事务实现原理
2.1 MVCC
Read View:活跃事务列表(还未提交的事务) 列表中最小事务ID(提交),列表中最大事务ID(未提交);具体可见性通过如下流程图所示:

2.2 MVCC如何实现
undo log:实现数据多版本,回滚,提交即清理;

redo log:实现事务持久性,记录修改,用于异常恢复,循环写文件;
Write Pos:写入位置
Chick Point:刷盘位置
Chick Point -> Write Pos:待落盘数据
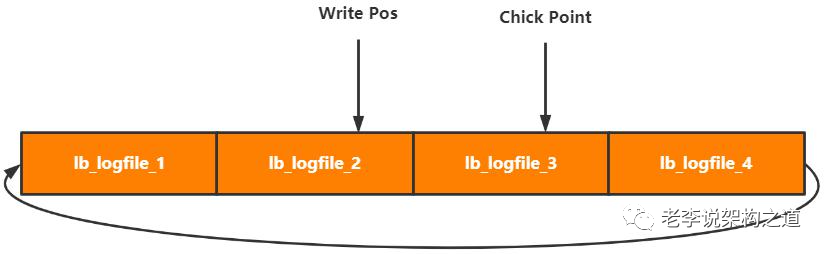
写入流程:

刷盘时机:
innodb_flush_log_at_trx_commit

3、MySQL使用及调优实践分析
3.1 索引使用技巧
联合索引:优于多列独立索引
索引顺序:选择性高的在前面
覆盖索引:二级索引存储主键值更有利
索引排序:索引同时满足查询和排序
3.2 分库分表
是否分表,建议单表不超过1KW
分表方式,取模:存储均匀&访问均匀,按时间:冷热库
分库,按业务垂直分,水平查分多个库
3.3 使用建议
数据库字符集使用utf8mb4;
VARCHAR按实际需要分配长度;
文本字段建议使用VARCHAR;
时间字段建议使用long;
bool字段建议使用tinyint;
枚举字段建议使用tinyint;
交易金额建议使用long;
禁止使用“%”前导的查询;
禁止在索引列进行数学运算,会导致索引失效;
select * from t1 where id+1 >1121 不会使用索引
select * from t1 where id >1121 - 1 会使用索引
表必须有主键,建议使用业务主键;
单张表中索引数量不超过5个;
单个索引字段数不超过5个;
字符串索引使用前缀索引,前缀长度不超过10个字符;
-
存储
+关注
关注
13文章
4483浏览量
86977 -
内存
+关注
关注
8文章
3103浏览量
74925 -
MySQL
+关注
关注
1文章
842浏览量
27424
发布评论请先 登录
深度剖析MySQL/InnoDB的并发控制和加锁技术
MySQL存储引擎中MyISAM与InnoDB优劣势比较分析
关于mysql存储引擎你知道多少
最有用的mysql问答
MySQL中的高级内容详解
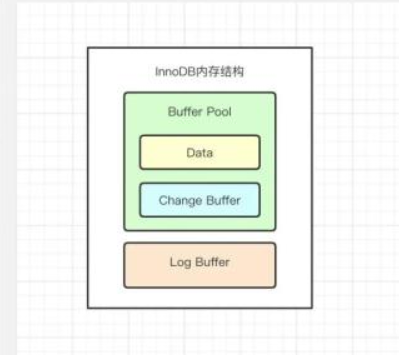
关于InnoDB的内存结构及原理详解
MySQL中的redo log是什么
innodb究竟是如何存数据的
MySQL5.6 InnoDB支持全文检索
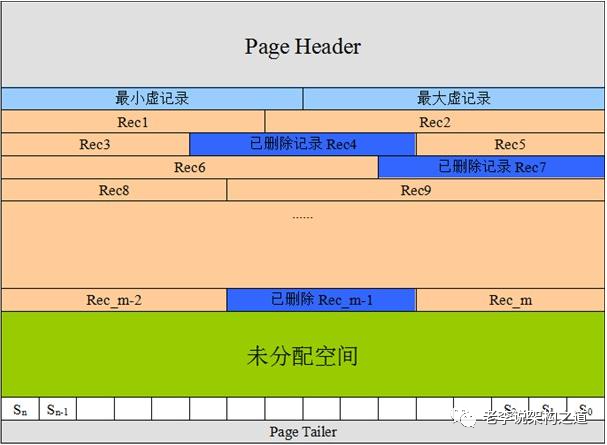
MySQL中的InnoDB是什么?
搭建树莓派网络监控系统:顶级工具与技术终极指南!
树莓派网络监控系统是一种经济高效且功能多样的解决方案,可用于监控网络性能、流量及整体运行状况。借助树莓派,我们可以搭建一个网络监控系统,实时洞察网络活动,从而帮助识别问题、优化性能并确保网络安全。安装树莓派网络监控系统有诸多益处。树莓派具备以太网接口,还内置了Wi-Fi功能,拥有足够的计算能力和内存,能够在Linux或Windows系统上运行。因此,那些为L
STM32驱动SD NAND(贴片式SD卡)全测试:GSR手环生物数据存储的擦写寿命与速度实测
在智能皮电手环及数据存储技术不断迭代的当下,主控 MCU STM32H750 与存储 SD NAND MKDV4GIL-AST 的强强联合,正引领行业进入全新发展阶段。二者凭借低功耗、高速读写与卓越稳定性的深度融合,以及高容量低成本的突出优势,成为大规模生产场景下极具竞争力的数据存储解决方案。

芯对话 | CBM16AD125Q这款ADC如何让我的性能翻倍?
综述在当今数字化时代,模数转换器(ADC)作为连接模拟世界与数字系统的关键桥梁,其技术发展对众多行业有着深远影响。从通信领域追求更高的数据传输速率与质量,到医疗影像领域渴望更精准的疾病诊断,再到工业控制领域需要适应复杂恶劣环境的稳定信号处理,ADC的性能提升成为推动这些行业进步的重要因素。行业现状分析在通信行业,5G乃至未来6G的发展,对基站信号处理提出了极
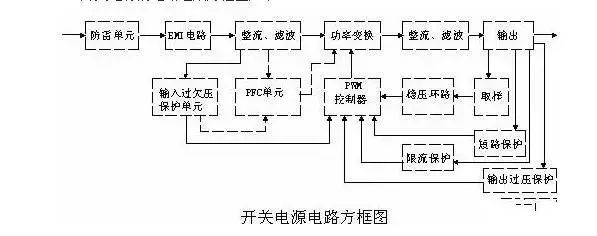
史上最全面解析:开关电源各功能电路
01开关电源的电路组成开关电源的主要电路是由输入电磁干扰滤波器(EMI)、整流滤波电路、功率变换电路、PWM控制器电路、输出整流滤波电路组成。辅助电路有输入过欠压保护电路、输出过欠压保护电路、输出过流保护电路、输出短路保护电路等。开关电源的电路组成方框图如下:02输入电路的原理及常见电路1AC输入整流滤波电路原理①防雷电路:当有雷击,产生高压经电网导入电源时
有几种电平转换电路,适用于不同的场景
一.起因一般在消费电路的元器件之间,不同的器件IO的电压是不同的,常规的有5V,3.3V,1.8V等。当器件的IO电压一样的时候,比如都是5V,都是3.3V,那么其之间可以直接通讯,比如拉中断,I2Cdata/clk脚双方直接通讯等。当器件的IO电压不一样的时候,就需要进行电平转换,不然无法实现高低电平的变化。二.电平转换电路常见的有几种电平转换电路,适用于

瑞萨RA8系列教程 | 基于 RASC 生成 Keil 工程
对于不习惯用 e2 studio 进行开发的同学,可以借助 RASC 生成 Keil 工程,然后在 Keil 环境下愉快的完成开发任务。

共赴之约 | 第二十七届中国北京国际科技产业博览会圆满落幕
作为第二十七届北京科博会的参展方,芯佰微有幸与800余家全球科技同仁共赴「科技引领创享未来」之约!文章来源:北京贸促5月11日下午,第二十七届中国北京国际科技产业博览会圆满落幕。本届北京科博会主题为“科技引领创享未来”,由北京市人民政府主办,北京市贸促会,北京市科委、中关村管委会,北京市经济和信息化局,北京市知识产权局和北辰集团共同承办。5万平方米的展览云集

道生物联与巍泰技术联合发布 RTK 无线定位系统:TurMass™ 技术与厘米级高精度定位的深度融合
道生物联与巍泰技术联合推出全新一代 RTK 无线定位系统——WTS-100(V3.0 RTK)。该系统以巍泰技术自主研发的 RTK(实时动态载波相位差分)高精度定位技术为核心,深度融合道生物联国产新兴窄带高并发 TurMass™ 无线通信技术,为室外大规模定位场景提供厘米级高精度、广覆盖、高并发、低功耗、低成本的一站式解决方案,助力行业智能化升级。

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
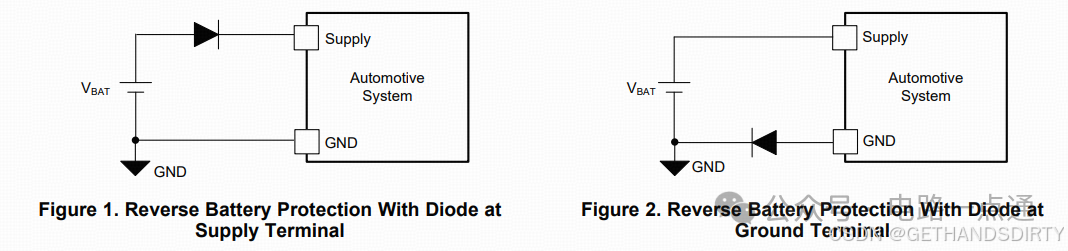
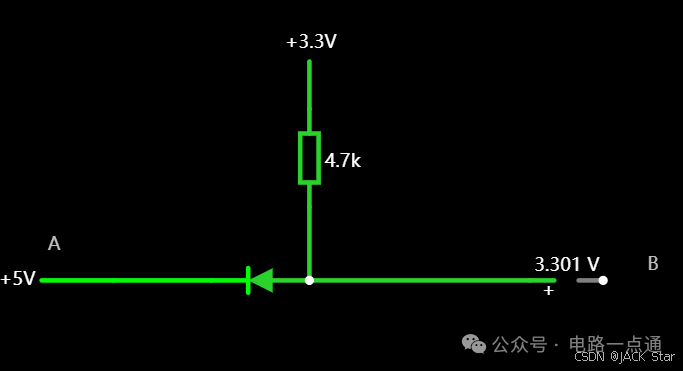
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极
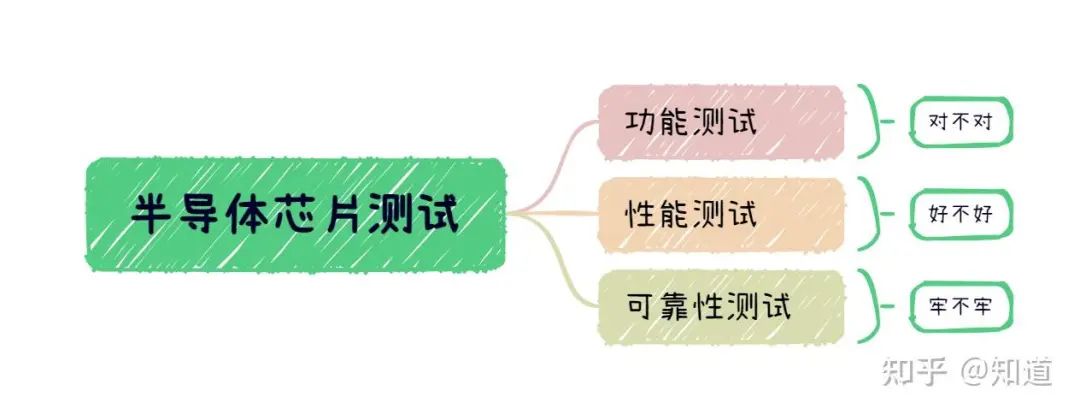
半导体芯片需要做哪些测试
首先我们需要了解芯片制造环节做⼀款芯片最基本的环节是设计->流片->封装->测试,芯片成本构成⼀般为人力成本20%,流片40%,封装35%,测试5%(对于先进工艺,流片成本可能超过60%)。测试其实是芯片各个环节中最“便宜”的一步,在这个每家公司都喊着“CostDown”的激烈市场中,人力成本逐年攀升,晶圆厂和封装厂都在乙方市场中“叱咤风云”,唯独只有测试显

解决方案 | 芯佰微赋能示波器:高速ADC、USB控制器和RS232芯片——高性能示波器的秘密武器!
示波器解决方案总述:示波器是电子技术领域中不可或缺的精密测量仪器,通过直观的波形显示,将电信号随时间的变化转化为可视化图形,使复杂的电子现象变得清晰易懂。无论是在科研探索、工业检测还是通信领域,示波器都发挥着不可替代的作用,帮助工程师和技术人员深入剖析电信号的细节,精准定位问题所在,为创新与发展提供坚实的技术支撑。一、技术瓶颈亟待突破性能指标受限:受模拟前端
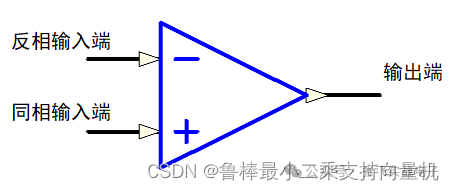
硬件设计基础----运算放大器
1什么是运算放大器运算放大器(运放)用于调节和放大模拟信号,运放是一个内含多级放大电路的集成器件,如图所示:左图为同相位,Vn端接地或稳定的电平,Vp端电平上升,则输出端Vo电平上升,Vp端电平下降,则输出端Vo电平下降;右图为反相位,Vp端接地或稳定的电平,Vn端电平上升,则输出端Vo电平下降,Vn端电平下降,则输出端Vo电平上升2运算放大器的性质理想运算

ElfBoard技术贴|如何调整eMMC存储分区
ELF 2开发板基于瑞芯微RK3588高性能处理器设计,拥有四核ARM Cortex-A76与四核ARM Cortex-A55的CPU架构,主频高达2.4GHz,内置6TOPS算力的NPU,这一设计让它能够轻松驾驭多种深度学习框架,高效处理各类复杂的AI任务。

米尔基于MYD-YG2LX系统启动时间优化应用笔记
1.概述MYD-YG2LX采用瑞萨RZ/G2L作为核心处理器,该处理器搭载双核Cortex-A55@1.2GHz+Cortex-M33@200MHz处理器,其内部集成高性能3D加速引擎Mail-G31GPU(500MHz)和视频处理单元(支持H.264硬件编解码),16位的DDR4-1600/DDR3L-1333内存控制器、千兆以太网控制器、USB、CAN、





 工商网监
工商网监
评论