 大模型为什么是深度学习的未来?
大模型为什么是深度学习的未来?
人工智能 | Bard | Chat GPT
深度学习 | RLHF|ERNIE Bot
当今社会是科技的社会,是算力快速发展的时代。随着数据中心、东数西算、高性能计算、数据分析、数据挖掘的快速发展,大模型得到了快速地发展。大模型是“大算力+强算法”相结合的产物,是人工智能的发展趋势和未来。目前,大规模的生态已初具规模。其可以实现从“手工作坊”到“工厂模式”的AI转型。大模型通常在大规模无标记数据上进行训练,以学习某种特征和规则。基于大模型开发应用时,可以对大模型进行微调,或者不进行微调,就可以完成多个应用场景的任务;更重要的是,大模型具有自监督学习能力,不需要或很少需要人工标注数据进行训练,降低训练成本,从而可以加快AI产业化进程,降低AI应用门槛。
与传统机器学习相比,深度学习是从数据中学习,而大模型则是通过使用大量的模型来训练数据。深度学习可以处理任何类型的数据,例如图片、文本等等;但是这些数据很难用机器完成。大模型可以训练更多类别、多个级别的模型,因此可以处理更广泛的类型。另外:在使用大模型时,可能需要一个更全面或复杂的数学和数值计算的支持。深度学习算法不需要像大模型那样训练大量数量的模型来学习特征之间的联系。深度学习算法是基于神经元的,而大模型是利用大量参数训练神经网络。本文从大模型与深度学习方面入手,解决大模型是否是深度学习的未来的问题。
作为深度学习、人工智能领域的专家,蓝海大脑液冷工作站支持多种算力平台,通过超融合与虚拟化管理平台可实现x86、ARM以及其他芯片架构的多元异构计算资源池化,并可根据业务特点实现计算资源的随需调度和统一管理,实现异构融合。同时,提供计算密集型、计算存储均衡型、存储密集型、边缘型、AI型等多种机型,以满足不同人工智能计算场景的需求,更加灵活高效。
大模型发展现状
大模型(预训练模型、基础模型等)是“大算力+ 强算法”结合的产物。大模型通常在大规模无标注数据上进行训练,以学习某种特征。在大模型进行开发应用时,将大模型进行微调,如对某些下游任务进行小规模标注数据的二次训练或不进行微调就可以完成。迁移学习是预训练技术的主要思想,当目标场景数据不足时,先在数据量大的公开数据集上训练基于深度神经网络的AI模型,然后将其迁移到目标场景中,通过目标场景中的小数据集进行微调,使模型达到要求的性能。在这个过程中,在公开数据集上训练的深度网络模型被称为“预训练模型”。使用预训练模型极大地减少了模型在标记数据量下游工作的需要,从而解决了一些难以获得大量标记数据的新场景。
从参数规模上看,AI 大模型先后经历了预训练模型、大规模预训练模型、超大规模预训练模型三个阶段,参数量实现了从亿级到百万亿级的突破。从模态支持上看, AI 大模型从支持图片、图像、文本、语音单一模态下的单一任务,逐渐发展为支持多种模态下的多种任务。
国外超大规模预训练模型始于2018年,并在2021年进入“军备竞赛”阶段。2017年Vaswani等人提出Transformer架构,奠定了大模型领域主流算法架构的基础; Transformer提出的结构使得深度学习模型参数达到上亿规模。 2018年谷歌提出BERT大规模预训练语言模型,是一种基于Transformer的双向深层预训练模型。这极大地刺激了自然语言处理领域的发展。此后,基于BERT、ELNet、RoberTa、T5的增强模型等一大批新的预训练语言模型相继涌现,预训练技术在自然语言处理领域得到快速发展。
2019年,OpenAI将继续推出15亿参数的GPT-2,可以生成连贯的文本段落,实现早期阅读理解和机器翻译等。紧接着,英伟达推出了83亿参数的Megatron-LM,谷歌推出了110亿参数的T5,微软推出了170亿参数的Turing-NLG。 2020年,OpenAI推出GPT-3超大规模语言训练模型,参数达到1750亿,用了大约两年的时间,实现了模型规模从1亿到上千亿级的突破,并能实现作诗、聊天、生成代码等功能。此后,微软和英伟达于2020年10月联合发布了5300亿参数的Megatron Turing自然语言生成模型(MT-NLG)。2021年1月,谷歌推出的Switch Transformer模型成为历史上首个万亿级语言模型多达 1.6 万亿个参数;同年 12 月,谷歌还提出了具有 1.2 万亿参数的 GLaM 通用稀疏语言模型,在7项小样本学习领域的性能优于 GPT-3。可以看出,大型语言模型参数数量保持着指数增长势头。这样的高速发展还没有结束,2022年又有一些常规业态大模型涌现,比如Stability AI发布的文字到图像Diffusion,以及OpenAI推出的ChatGPT。

国外大模型发展历程
在国内,超大模型的研发发展异常迅速,2021年是中国AI大模型爆发的一年。 2021年,商汤科技发布了大规模模型(INTERN),拥有100亿的参数量,这是一个巨大的训练工作。在训练过程中,大约有10个以上的监控信号帮助模型适应各种不同视觉或NLP任务。截至到2021年中,商汤科技已经构建了全球最大的计算机视觉模型,其中该模型拥有超过300亿个参数;同年4月,华为云联合循环智能发布千亿参数规模的盘古NLP超大规模预训练语言模型;联合北京大学发布盘古α超大规模预训练模型,参数规模达2000亿。阿里达摩院发布270亿参数的PLUG中文预训练模型,联合清华大学发布千亿参数规模的M6中文多模态预训练模型; 7月,百度推出 ERNIE 3.0 Titan模型; 10月,浪潮信息发布预估2500亿的超大规模预训练模型“源 1.0”; 12月,百度推出了拥有2600亿尺度参数的ERNIE 3.0 Titan模型。而达摩院的M6模型的参数达到10万亿,直接将大模型的参数提升了一个量级。2022年,基于清华大学、阿里达摩院等研究成果以及超算基础实现的“脑级人工智能模型”八卦炉完成建立,其模型参数将超过174万亿。
部分中国公司虽然还没有正式推出自己的大规模模型产品,但也在积极进行研发,比如云从科技,该公司的研究团队就非常认同“预训练大模型+下游任务迁移”的技术趋势,从2020年开始,在NLP、OCR、机器视觉、语音等多个领域开展预训练大模型的实践,不仅进一步提升了企业核心算法的性能,同时也大大提升了算法的生产效率,已经在城市治理、金融、智能制造等行业应用中展现出价值。

“书生”相较于同期最强开源模型CLIP在准确率和数据使用效率上均取得大幅提升
大模型给人工智能产业带来什么
一、大模型加速AI产业化进程,降低AI应用门槛
人工智能正处于从“能用”到“好用”的应用落地阶段,但仍处于商业落地初期,主要面临场景需求碎片化、人力研发和应用计算成本高以及长尾场景数据较少导致模型训练精度不够、模型算法从实验室场景到真实场景差距大等行业问题。而大模型的出现,在增加模型通用性、降低训练研发成本等方面降低AI落地应用的门槛。
1、大模型可实现从“手工作坊”到“工厂模式”的AI转型
近十年来,通过“深度学习+大算力”获得训练模型成为实现人工智能的主流技术途径。由于深度学习、数据和算力可用这三个要素都已具备,全球掀起了“大炼模型”的热潮,也催生了一大批人工智能公司。然而,在深度学习技术出现的近10年里,AI模型基本上都是针对特定的应用场景进行训练的,即小模型属于传统的定制化、作坊式的模型开发方式。传统AI模型需要完成从研发到应用的全方位流程,包括需求定义、数据收集、模型算法设计、训练调化、应用部署和运营维护等阶段组成的整套流程。这意味着除了需要优秀的产品经理准确定义需求外,还需要AI研发人员扎实的专业知识和协同合作能力才能完成大量复杂的工作。

传统的定制化、作坊式模型开发流程
在传统模型中,研发阶段为了满足各种场景的需求,AI研发人员需要设计个性定制化的专用的神经网络模型。模型设计过程需要研究人员对网络结构和场景任务有足够的专业知识,并承担设计网络结构的试错成本和时间成本。一种降低专业人员设计门槛的思路是通过网络结构自动搜索技术路线,但这种方案需要很高的算力,不同的场景需要大量机器自动搜索最优模型,时间成本仍然很高。一个项目往往需要专家团队在现场待上几个月才能完成。其中,数据收集和模型训练评估以满足目标要求通常需要多次迭代,从而导致高昂的人力成本。
落地阶段,通过“一模一景”的车间模式开发出来的模型,并不适用于垂直行业场景的很多任务。例如,在无人驾驶汽车的全景感知领域,往往需要多行人跟踪、场景语义分割、视野目标检测等多个模型协同工作;与目标检测和分割相同的应用,在医学影像领域训练的皮肤癌检测和AI模型分割不能直接应用于监控景点中的行人车辆检测和场景分割。模型无法重复使用和积累,这也导致了AI落地的高门槛、高成本和低效率。
大模型是从庞大、多类型的场景数据中学习,总结出不同场景、不同业务的通用能力,学习出一种特征和规律,成为具有泛化能力的模型库。在基于大模型开发应用或应对新的业务场景时可以对大模型进行适配,比如对某些下游任务进行小规模标注数据二次训练,或者无需自定义任务即可完成多个应用场景,实现通用智能能力。因此,利用大模型的通用能力,可以有效应对多样化、碎片化的人工智能应用需求,为实现大规模人工智能落地应用提供可能。

AI大模型“工厂模式”的开发方式
2、大模型具有自监督学习能力,能够降低AI开发以及训练成本
传统的小模型训练过程涉及大量调参调优的手动工作,需要大量AI专业研发人员来完成;同时,模型训练对数据要求高,需要大规模的标注数据。但很多行业的数据获取困难,标注成本高,同时项目开发者需要花费大量时间收集原始数据。例如,人工智能在医疗行业的病理学、皮肤病学和放射学等医学影像密集型领域的影响不断扩大和发展,但医学影像通常涉及用户数据隐私,很难大规模获取到用于训练 AI 模型。在工业视觉瑕疵检测领域,以布匹瑕疵为例,市场上需要检测的织物种类有白坯布、色坯布、成品布、有色布、纯棉、混纺织物等缺陷种类繁多,颜色和厚度难以识别,需要在工厂长时间收集数据并不断优化算法才能做好缺陷检测。
大模型利用自监督学习功能,对输入的原始数据进行自动学习区分,合理构建适合模型学习的任务,不需要或者很少用人工标注的数据进行训练,很大程度上解决了人工标注的数据标签成本高、周期长、精确度的问题,减少了训练所需的数据量。这在很大程度上减少了收集和标记大型模型训练数据的成本,更适合小样本学习,有助于将传统有限的人工智能扩展到更多的应用场景。
我们认为,相比于传统的AI模型开发模式,大规模模型在研发过程中的流程更加标准化,在实现过程中具有更大的通用性,可以泛化到多种应用场景;并且大模型的自监督学习能力相较于传统的需要人工标注的模型训练能够显著降低研发成本,共同使得大模型对于 AI 产业具有重要意义,为解决 AI 落地难、促进 AI 产业化进程这一问题提供方向。
二、大模型带来更强大的智能能力
除通用能力强、研发过程标准化程度高外,大模型最大的优势在于“效果好”。它通过将大数据“喂”给模型来增强自学习能力,从而具有更强的智能程度。例如,在自然语言处理领域,百度、谷歌等探索巨头已经表明,基于预训练大模型的NLP技术的效果已经超越了过去最好的机器学习的能力。 OpenAI 研究表明,从 2012 年到 2018 年的六年间,在最大规模的人工智能模型训练中所使用的计算量呈指数级增长,其中有 3.5 个月内翻了一番,相比摩尔定律每 18 个月翻一番的速度快很多。下一代AI大模型的参数量级将堪比人类大脑的突触水平,可能不仅可以处理语言模型,将更是一个多模态AI模型,可以处理多任务,比如语言、视觉和声音。

弱人工智能仍属于计算机“工具”范畴,强人工智能能自适应地完成任务
深度学习平台体系架构
同时大模型的训练离不开深度学习平台架构。深度学习 (DL, Deep Learning)是机器学习 (ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能 (AI, Artificial Intelligence)。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。大模型的训练离不开深度学习平台架构。
一、深度学习平台三要素体系
针对行业应用的多样化需求,以开源开发框架为核心的深度学习平台构建了从模型开发到部署的服务体系,包括三个核心层次:开发框架、算法模型、开发工具和能力平台。在人工智能大规模产业化生产时代,深度学习技术的通用性越来越强,深度学习平台的标准化、自动化和模块化特征越来越突出,成为人工智能技术大规模、低成本融合赋能的基础。平台以成熟算法技术直接调用、个性化场景定制化开发的形式为行业提供多种创新应用,最终形成资源丰富、多方参与、协同演进的人工智能使能生态。在深度学习平台的发展演进过程中,逐渐形成了“框架-算法-工具”三个核心层次。

深度学习平台层次架构
底层是开源开发框架。作为深度学习平台的核心枢纽,开源开发框架连接GPU、ASIC等智能计算芯片,支持计算机视觉、自然语言处理、语音等各类应用。部署全流程能力,让高效开发迭代各种算法,部署大规模应用成为可能。一是通过提供编程接口API、编码语言等方式,为开发者构建编程模型和开发能力;二是依托并行训练、动静转化、内存优化等功能,实现模型编译和训练优化;三是提供硬件接入能力,通过简化底层硬件的技术细节,建立模型与算力的连接通道,解决模型适配部署难的问题。
中间层代表算法模型,深度学习平台赋予开发者行业级的建模能力。采用预训练方式,减少数据采集、标注时间和人力成本,缩短模型训练过程,实现模型快速部署,加速AI技术技能开发。根据技术路线和应用价值,可以分为三类算法模型:一类是业界已经实践过的基础算法,如VGGNet、ResNet等主流SOTA模型;二是提供自然算法语言处理、计算机视觉、多模态等领域小样本细分场景的预训练模型,快速实现算法技能迁移;三是针对特定行业场景(如工业质检、安检等)的应用模型,根据用户真实的行业落地需求推荐合适的应用。结合落地机型和硬件,并提供相关实例。
上层是套件工具和能力平台,支持各层级模型的开发和部署,满足开发者各个阶段的需求。主要功能体现在以下几个方面: 一是降低技术应用门槛,通过提供集成化、标准化的基础训练技术工具组件,支持可视化分析、预训练模型应用,降低训练和模型开发的门槛、云作业交付和其他功能;提供前沿技术研发工具,支撑联邦学习、自动机器学习、生物计算、图形神经网络等技术能力,为模型创新提供支持;三是提供图像分类、目标检测、图像分割等具体信息,满足行业实际需求面向业务场景的端到端开发包,涵盖数据增强、模块化设计、分布式训练、模型调参等流程,以及交叉部署平台,实现AI能力的快速应用;四是提供全生命周期管理,构建一体化深度学习模型开发平台,提供从数据处理、模型训练、模型管理到模型推理的全周期服务,加速人工智能技术开发和应用落地全过程,实现管控与协同。
二、深度学习平台核心作用
一是驱动核心技术迭代改进。随着深度学习技术的逐渐成熟和普及,标准化、模块化的流程工具成为开发者的共同诉求,深度学习平台应运而生。该平台通过提供包含卷积、池化、全连接、二分类、多分类、反向传播等的算法库,避免了“重复造轮子”带来的资源浪费。在更高层次上实现创新突破,实现“站在巨人的肩膀上”创新,加快人工智能技术迭代提升。
二是推动产业链上下游协同创新。操作系统作为连接PC和移动互联网时代底层硬件架构、顶层软件系统和用户交互界面的控制中心,是微软、诺基亚、苹果、谷歌等公司驱动产业生态的核心工具统治地位。在人工智能时代,深度学习平台还起到连接顶层(顶层应用)和底层(下层芯片)的作用,类比为“人工智能时代的操作系统”。深度学习平台的出现,使得各种算法能够基于现有硬件系统高效开发迭代并部署大规模应用,为深度学习的不断发展奠定了基础。
三是缩短千行百业智能化升级路径。当前,人工智能工程应用迎来了快速发展的窗口期,如何缩短人工智能算法从建模到实际生产的周期,提高应用效率成为各行业关注的核心问题。深度学习平台提供从制造到工具、技术、机制等涵盖人工智能能力产生、应用、管理全过程的实用工程解决方案,解决人工智能面临的专业人才短缺、数据成本高、建模等问题。智能升级中的企业发展难、资源效率低等问题,满足了企业AI能力建设的迫切需求,为智能升级奠定了基础。
四是承载产业生态繁荣动能。深度学习是一个典型的共创技术领域。只有构建健康完善的产业生态,才能实现繁荣和可持续发展。以深度学习平台为驱动,搭建连接产学界的沟通桥梁,通过开发者社区、赛事峰会、培训课程等方式,汇聚人才、技术、市场等行业生态资源要素。在输出技术能力、赋能产业提升的同时,不断发展运用人工智能技术的惯性思维方式,攻克各行业痛点难点,进一步带动下游需求,形成产业生态良性循环。

深度学习平台的技术创新重点
一、开源开发框架,深度学习平台的基础核心
开源开发框架作为深度学习平台的基础核心,结合编程范式、大规模分布式等关键技术,打造易用、高效、可扩展的框架引擎,解决了工业应用中的广泛问题。培训、软件适配和硬件 ,专注于提高人工智能产品以及软硬件解决方案的开发效率和易用性。
1、动静统一的编程范式大幅提升算法开发效率
动静统一的编程范式大幅提升算法开发效率。框架编程范式是开发人员用于编写 程序时把复杂问题抽象成程序代码的不同方式,主要分为命令式编程(动态图)和声明式编程(静态图)两种编程范式,其中动态图编程具备开发便捷性的特点,开发者可在调整局部代码时,即时获得执行结果,易于调试、减少时间成本,但由于缺乏全局的计算图Pass、显存等优化,如算子间融合、显存inplace等,在性能、显存等使用方面有所不足。而静态图则将用户可事先定义的全部程序代码进行全局编译优化, 在功耗、性能等方面优势显著。目前,谷歌TensorFlow、飞桨等业内主流框架纷纷布局动静统一的编程范式,同时兼容支持动态图、静态图两种编程范式,即在支持动态图高效开发训练的同时,也支持开发后一行代码转静态图训练加速和部署,大幅提升开发者算法研发准确率和生产部署效果。
2、大规模分布式训练技术有效提升巨型模型研发的承载能力
大规模分布式训练技术有效提升了超大规模模型开发的承载能力。目前算法模型规模呈指数级增长,以ERNIE3.0大模型为例,模型参数2600亿,需要存储空间3TB,计算量6.2E11 Tera FLOPs。单台服务器,以Nvidia V100为例,单卡32GB内存,125Tera FLOPS的计算能力,难以满足千亿级参数模型的训练需求,数据压力大/读写模型、存储、训练等。大规模分布式训练架构布局,将千卡算力(相当于一个国家超算中心的算力)的传递和计算纳入主流企业通用实践框架,结合平台特性和端到端特征的算力模型自适应分布式训练技术成为重要的创新方向。例如,结合算力平台的灵活资源调度管理技术、自动选择最优并行策略技术、高效计算与通信技术等。
3、统一的高速推理引擎满足端边云多场景大规模部署应用
面对多样化的部署环境,具备云端推理能力,成为开源开发框架成为业界普惠工具的重要标志。物联网智能时代,开发框架必须具备端、边、云全面支持的推理机架构,以及与训练框架集成的内部表达式和算子库,实现即时训练和最完备的模型支持。推理实现能力应跨越服务器、移动和 Web 前端,模型压缩工具可以帮助开发人员实现更小、更高性能的模型。在部署过程中,开发框架还应该提供全流程推理和场景部署工具链,以实现在硬件受限环境下的快速部署。工具或技术的蒸馏,进一步优化和支持推理引擎在服务器、移动终端/边缘终端、网页等各种硬件场景下的实现。
从生态上看,Paddle还支持采用Paddle平台上的其他框架模型,也支持将Paddle模型转换为ONNX格式进行部署,为开发者提供多样化、个性化的选择。
4、标准化的软硬件协同适配技术是打造国产化应用赋能的关键
业内领先的框架平台企业试图提供可满足多硬件接入的统一适配方案,包括统一硬件接口、算子开发映射、图引擎接入、神经网络编译器这几方面。
一是构建统一硬件接入接口,完成不同硬件抽象层接口的标准化访问管理。如飞 桨框架支持插件式硬件接入功能,实现框架和硬件的解耦,开发者只需实现标准接 口,即可在框架中注册新的硬件后端。
二是提供算子开发映射方式,通过芯片提供的编程语言编写算子Kernel或算子映 射方式接入硬件。具体可通过算子复用技术,减少算子数量;通过提供硬件Primitive开发接口,实现算子在不同硬件上复用;对于现有算子无法满足运算逻辑和性能 需求的问题,开发者可以自定义算子,无需重新编译安装飞桨框架。
三是提供图引擎接入方式,通过框架计算图和硬件图引擎之间的适配,实现硬件接入。为了更高效适配深度学习框架,硬件厂商通常会提供图引擎,如英伟达的 TensorRT、Intel的OpenVINO等,框架仅需实现模型中间表示向厂商模型中间表示 的转换即可适配。
四是打造神经网络编译器,实现自动优化的编译技术,利用基础算子自动融合优化实现复杂算子功能,降低适配成本的同时,优化性能。如百度神经网络编译器CINN具有方便接入硬件,提升计算速度的特点。对比业内的TVM ,CINN额外支持了训练功能;对比谷歌的XLA,CINN提供自动调优技术,可更好实现软硬协同,发挥硬件性能。
二、模型库建设,算法创新、沉淀与集成管理是快速赋能关键能力
模型库是深度学习平台推动AI普惠化,实现快速产业赋能的关键能力。为解决人工智能算法工程化落地过程中面临的研发门槛高、周期长等问题,深度学习平台将模型库作为平台的核心能力进行建设,开发者依托模型库,无需从头编写代码即可实现算法能力,实现应用模型的不断复用,从而促进人工智能应用多样化和规模化发展。 当前,深度学习平台均基于自身开发框架构建算法模型库,提供快速搭建人工智能应用能力,如Meta推出 ,提供算法模型库以及简易API和工作流程;蓝海大脑构建产业级模型库并提供面向场景应用的模型开发套件,实现模型直接调用及二次开发的能力,提升算法研发应用效率。
深度学习平台在前沿技术领域持续创新,沉淀先进算法能力,推动SOTA模型应用落地。一方面,深度学习平台已成为先进算法模型的重要承载体,全球来看,AI领域创新算法的提出六成以上使用国际主流开发开源框架进行验证;另一方面,学术界、产业界对先进算法的使用需求反推深度学习平台加强对SOTA模型库的能力建设,促进原创算法持续产生。当前,国际主流深度学习平台模型库不断加强对前沿算法模型的积累,将算法能力沉淀至深度学习平台模型库,为开发者提供前沿技术能力支撑。
模型库通过应用场景实践加速完善,产业赋能能力不断强化。为满足产业多样化场景需求,切实推动AI算法应用落地,模型库主要通过两个方面提升平台产业赋能能力。一是通过细化应用场景,丰富算法覆盖方向,拓展模型库能力边界。模型库基于计算机视觉、自然语言处理等基础算法,依据实际产业需求对能力应用场景进行细化,面向图像分割、车辆检测、个性化推荐等细分任务提供经过产业实践的模型。此外,通过引入预训练模型,为开发者提供灵活、可拓展的算法能力,可实现在小样本任务中的快速应用,如蓝海大脑目前支持产业级开源算法模型超500个,已在金融、能源、交通等各行各业广泛应用。二是从实际产业应用场景出发,聚焦AI工程化落地问题,通过提供轻量级、低能耗的产业级部署模型,解决实际应用场景中模型的精度与性能平衡问题。
三、工具及平台完善,覆盖数据处理、模型训练和推理部署全周期
深度学习平台围绕前沿技术开发部署新范式、数据模型全流程可视化分析管理、 企业级高精度应用构建以及全平台部署来布局相关工具组件及平台。
一是打造面向新型学习范式的系统化工具,深度学习平台面对强化学习、联邦学习、图学习、量子计算、生物计算等前沿学习范式,提供所需编译运行机制和解决方案,实现广泛的模型应用场景。
二是开发覆盖数据管理、模型开发和推理部署的全流程研发工具集,实际应用落地作为深度学习平台的出发点和落脚点,平台通过提供开发套件和工具组件,端到端 打通数据准备、模型训练与优化、多端部署能力,助力产业实践工程化高效部署。
三是提供企业级高精度应用构建和全平台部署能力,企业开发服务平台作为深度学习平台的重要出口,整合底层核心开源框架以及上层数据处理、模型开发构建、模型训练管理及端侧部署能力,辅助企业实现一站式模型定制能力。如蓝海大脑深度学习平台面向不同开发能力的企业打造零门槛深度学习平台,可结合网络结构搜索和迁移学习等技术完成语言理解、语言生成、图像分类、物体检测、图文生成等任务,支持企业实现在公有云、本地服务器、移动设备的多侧灵活安全部署。
四、专业领域延伸,围绕科学发现与量子智能持续探索
领先的深度学习平台和框架企业正围绕生物医药、量子智能等更具前瞻性的垂直专业领域加速布局,降低前沿科研开发门槛,提升应用开发效率。当前,前沿学术研究进入多学科融合和技术工具完善发展的新阶段,人工智能技术成为推动前沿科学发展的重要路线之一,取得了诸多突破和突破。在创新的同时,也对深度学习平台的工具能力提出了新的挑战。龙头企业重点关注以下方向,提升平台在专业领域的研发能力。
一是聚焦量子智能,应用量子计算,挖掘人工智能算法的应用潜力。量子计算具有传统计算无法比拟的信息承载能力和并行计算处理能力,有望解决人工智能模型参数数量增加带来的计算瓶颈问题。龙头企业提供基于深度学习平台的量子计算工具包,推动量子技术与人工智能机器学习模型的融合,支持量子电路模拟器、训练判别和生成量子模型;电路仿真等模块为开发者提供了人工智能、组合优化、量子化学等领域量子应用的研发工具,提高运营效率,降低量子应用研发门槛。
二是聚焦蛋白质结构预测、化合物性质预测等生物医学领域重点方向,构建一套生物计算和模型开发工具。人工智能与生物医学技术相结合,可以大大提高任务的准确性和效率,成为产业布局的重要方向。
总结与展望
随着深度学习技术的发展,大模型已经成为深度学习的未来。大模型是一种深度学习模型,它可以处理大量的数据,从而获得准确的预测结果。
首先,大模型可以有效地处理大量数据。传统的机器学习模型只能处理少量的数据,而大模型可以处理大量的数据,从而获得更准确的预测结果。此外,大模型可以有效地处理非结构化的数据,例如图像和视频。
其次,大模型可以提高模型的准确性。大模型可以捕捉数据之间的复杂关系,从而提高模型的准确性。此外,大模型可以更快地训练,从而更快地获得准确的预测结果。
最后,大模型可以更好地支持深度学习。深度学习需要大量的数据,大模型可以支持深度学习,从而更好地发挥深度学习的优势。
总之,大模型是深度学习的未来。它可以有效地处理大量的数据,提高模型的准确性,更快地训练,更好地支持深度学习,从而提高深度学习的效率。
审核编辑黄宇
-
人工智能
+关注
关注
1804文章
48511浏览量
245361 -
模型
+关注
关注
1文章
3471浏览量
49874 -
机器学习
+关注
关注
66文章
8482浏览量
133921 -
深度学习
+关注
关注
73文章
5549浏览量
122371 -
大模型
+关注
关注
2文章
2961浏览量
3710
发布评论请先 登录
【详解】FPGA:深度学习的未来?
为什么说FPGA是机器深度学习的未来?
labview测试tensorflow深度学习SSD模型识别物体
深度学习中过拟合/欠拟合的问题及解决方案
labview调用深度学习tensorflow模型非常简单,附上源码和模型
什么是深度学习?使用FPGA进行深度学习的好处?


深度学习中的模型权重
深度学习模型有哪些应用场景

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
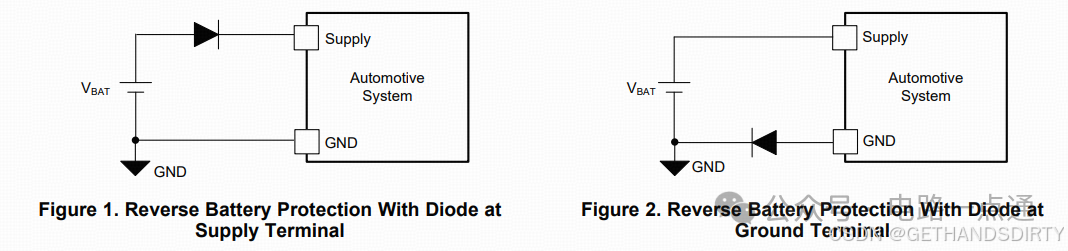
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极
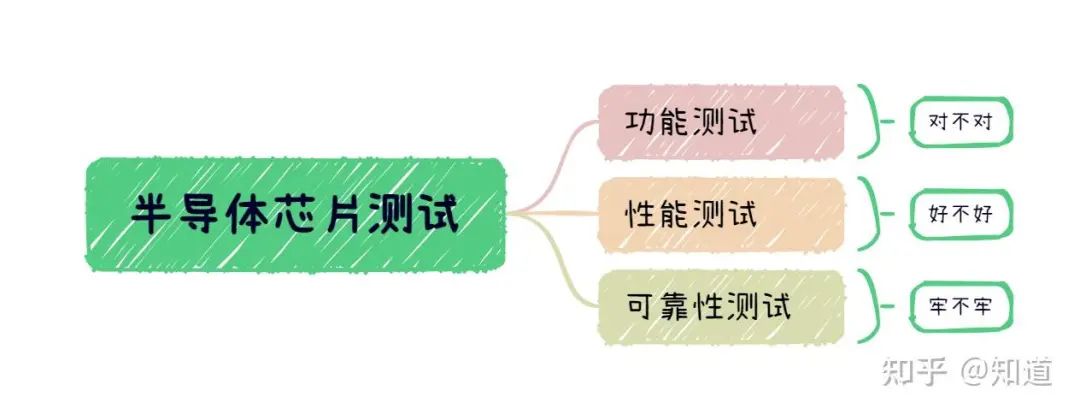
半导体芯片需要做哪些测试
首先我们需要了解芯片制造环节做⼀款芯片最基本的环节是设计->流片->封装->测试,芯片成本构成⼀般为人力成本20%,流片40%,封装35%,测试5%(对于先进工艺,流片成本可能超过60%)。测试其实是芯片各个环节中最“便宜”的一步,在这个每家公司都喊着“CostDown”的激烈市场中,人力成本逐年攀升,晶圆厂和封装厂都在乙方市场中“叱咤风云”,唯独只有测试显

解决方案 | 芯佰微赋能示波器:高速ADC、USB控制器和RS232芯片——高性能示波器的秘密武器!
示波器解决方案总述:示波器是电子技术领域中不可或缺的精密测量仪器,通过直观的波形显示,将电信号随时间的变化转化为可视化图形,使复杂的电子现象变得清晰易懂。无论是在科研探索、工业检测还是通信领域,示波器都发挥着不可替代的作用,帮助工程师和技术人员深入剖析电信号的细节,精准定位问题所在,为创新与发展提供坚实的技术支撑。一、技术瓶颈亟待突破性能指标受限:受模拟前端
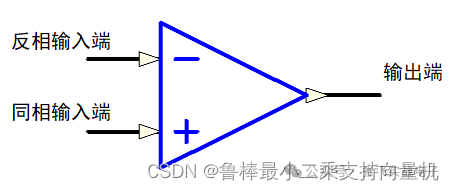
硬件设计基础----运算放大器
1什么是运算放大器运算放大器(运放)用于调节和放大模拟信号,运放是一个内含多级放大电路的集成器件,如图所示:左图为同相位,Vn端接地或稳定的电平,Vp端电平上升,则输出端Vo电平上升,Vp端电平下降,则输出端Vo电平下降;右图为反相位,Vp端接地或稳定的电平,Vn端电平上升,则输出端Vo电平下降,Vn端电平下降,则输出端Vo电平上升2运算放大器的性质理想运算

ElfBoard技术贴|如何调整eMMC存储分区
ELF 2开发板基于瑞芯微RK3588高性能处理器设计,拥有四核ARM Cortex-A76与四核ARM Cortex-A55的CPU架构,主频高达2.4GHz,内置6TOPS算力的NPU,这一设计让它能够轻松驾驭多种深度学习框架,高效处理各类复杂的AI任务。

米尔基于MYD-YG2LX系统启动时间优化应用笔记
1.概述MYD-YG2LX采用瑞萨RZ/G2L作为核心处理器,该处理器搭载双核Cortex-A55@1.2GHz+Cortex-M33@200MHz处理器,其内部集成高性能3D加速引擎Mail-G31GPU(500MHz)和视频处理单元(支持H.264硬件编解码),16位的DDR4-1600/DDR3L-1333内存控制器、千兆以太网控制器、USB、CAN、
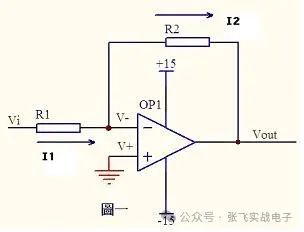
运放技术——基本电路分析
虚短和虚断的概念由于运放的电压放大倍数很大,一般通用型运算放大器的开环电压放大倍数都在80dB以上。而运放的输出电压是有限的,一般在10V~14V。因此运放的差模输入电压不足1mV,两输入端近似等电位,相当于“短路”。开环电压放大倍数越大,两输入端的电位越接近相等。“虚短”是指在分析运算放大器处于线性状态时,可把两输入端视为等电位,这一特性称为虚假短路,简称

飞凌嵌入式携手中移物联,谱写全国产化方案新生态
4月22日,飞凌嵌入式“2025嵌入式及边缘AI技术论坛”在深圳成功举办。中移物联网有限公司(以下简称“中移物联”)携OneOS操作系统与飞凌嵌入式共同推出的工业级核心板亮相会议展区,操作系统产品部高级专家严镭受邀作《OneOS工业操作系统——助力国产化智能制造》主题演讲。
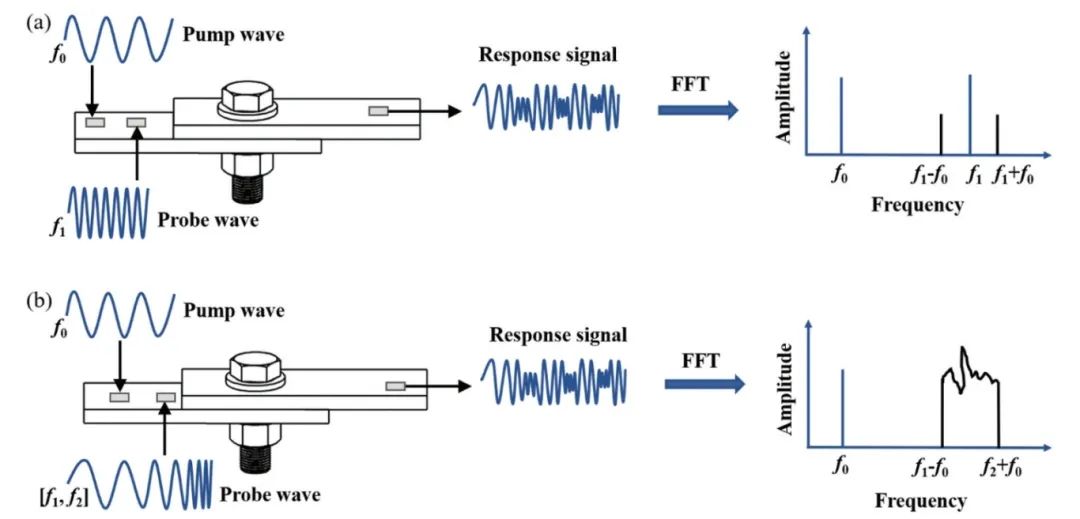
ATA-2022B高压放大器在螺栓松动检测中的应用
实验名称:ATA-2022B高压放大器在螺栓松动检测中的应用实验方向:超声检测实验设备:ATA-2022B高压放大器、函数信号发生器,压电陶瓷片,数据采集卡,示波器,PC等实验内容:本研究基于振动声调制的螺栓松动检测方法,其中低频泵浦波采用单频信号,而高频探测波采用扫频信号,利用泵浦波和探测波在接触面的振动声调制响应对螺栓的松动程度进行检测。通过螺栓松动检测
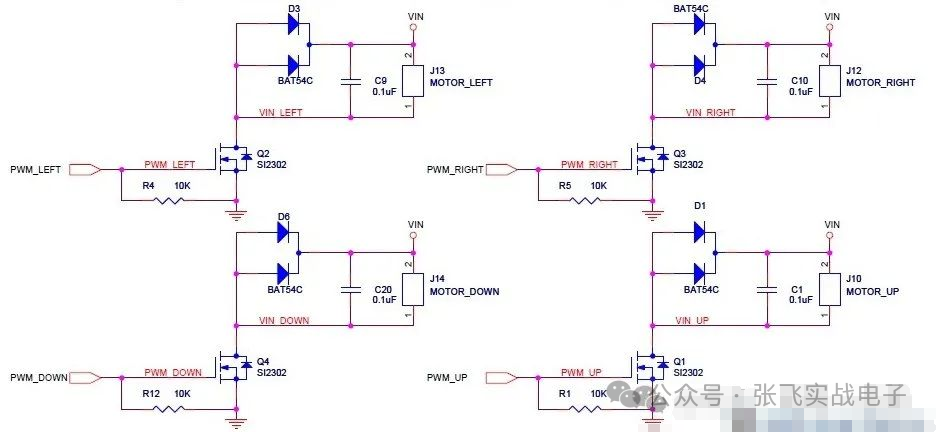
MOS管驱动电路——电机干扰与防护处理
此电路分主电路(完成功能)和保护功能电路。MOS管驱动相关知识:1、跟双极性晶体管相比,一般认为使MOS管导通不需要电流,只要GS电压(Vbe类似)高于一定的值,就可以了。MOS管和晶体管向比较c,b,e—–>d(漏),g(栅),s(源)。2、NMOS的特性,Vgs大于一定的值就会导通,适合用于源极接地时的情况(低端驱动),只要栅极电压达到4V或10V就可以
压敏(MOV)在电机上的应用剖析
一前言有刷直流电机是一种较为常见的直流电机。它的主要特点包括:1.结构相对简单,由定子、转子、电刷和换向器等组成;2.通过电刷与换向器的接触来实现电流的换向,从而使电枢绕组中的电流方向周期性改变,保证电机持续运转;3.具有调速性能较好等优点,可以通过改变电压等方式较为方便地调节转速。有刷直流电机在许多领域都有应用,比如一些电动工具、玩具、小型机械等。但它也存
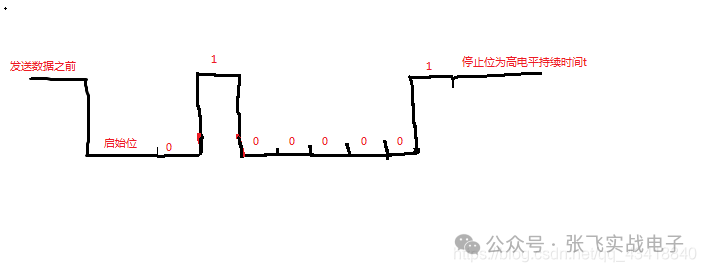
硬件原理图学习笔记
这一个星期认真学习了硬件原理图的知识,做了一些笔记,方便以后查找。硬件原理图分为三类1.管脚类(gpio)和门电路类输入输出引脚,上拉电阻,三极管与门,或门,非门上拉电阻:正向标志作用,给悬空的引脚一个确定的状态三极管:反向三极管(gpio输出高电平,NP两端导通,被控制端导通,电压为0)->NPN正向三极管(gpio输出低电平,PN两端导通,被控制端导通,

TurMass™ vs LoRa:无线通讯模块的革命性突破
TurMass™凭借其高传输速率、强大并发能力、双向传输、超强抗干扰能力、超远传输距离、全国产技术、灵活组网方案以及便捷开发等八大优势,在无线通讯领域展现出强大的竞争力。

RZT2H CR52双核BOOT流程和例程代码分析
RZT2H是多核处理器,启动时,需要一个“主核”先启动,然后主核根据规则,加载和启动其他内核。本文以T2H内部的CR52双核为例,说明T2H多核启动流程。





 工商网监
工商网监
评论