 什么是集成学习算法-1
什么是集成学习算法-1
一.集成学习简介
简介:构建并结合多个学习器来完成任务
图解:
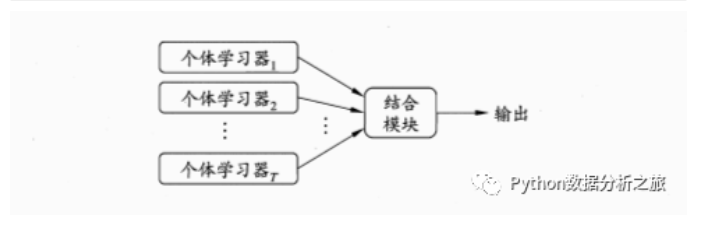
按照个体学习器划分分类:
(1)同质集成:只包含同种类型算法,比如决策树集成全是决策树
(2)异质集成:包含不同种类型算法,比如同时包含神经网络和决策树按照运行方式分类:
(1)并行运行:bagging
(2)串行运行:boosting
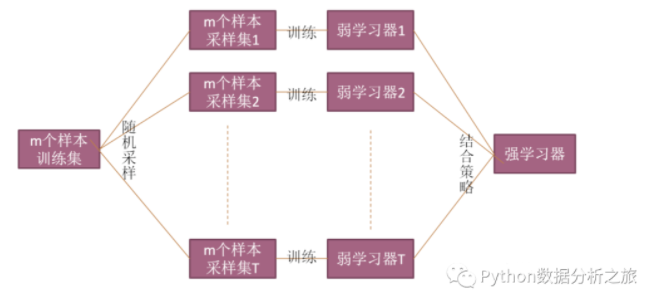
二.Bagging
简介:并行式集成学习方法
采样方法:自助采样法。假设采集m个样本,我们先采集一个样本然后将其放回初始样本,下次有可能再次采集到,如此重复采集m次即可
思想:并联形式,可以快速得到各个基础模型,它们之间互不干扰,并且使用相同参数,只是输入不同。对于回归算法求平均,对于分类算法进行投票法
代表性算法:随机森林
偏差-方差角度:由于是基于泛化性能比较强的学习器来构建很强的集成,降低方差
图解:
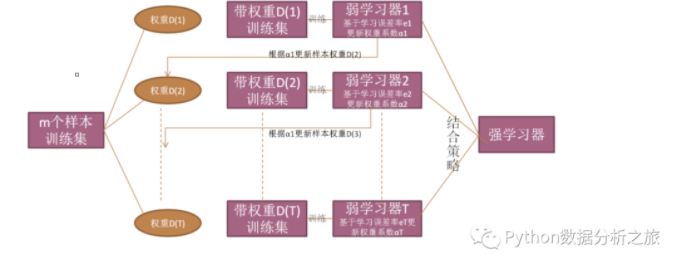
三.Boosting
简介:串行式集成学习方法
思想:对于训练集中的每个样本建立权值wi,对于分类错误样本会在下一轮的分类中获得更大的权重,也就是说每次新的计算结果都要利用上次返回的结果,如此迭代循环往复
代表性算法:AdaBoost和GBDT
偏差-方差角度:由于是基于泛化性能比较弱的学习器来构建很强的集成,降低偏差
图解:
四.Bagging与Boosting区别
1.样本选择
Bagging采取Bootstraping的是随机有放回的取样
Boosting的每一轮训练的样本是固定的,改变的是每个样本的权重
2.样本权重
Bagging采取的是均匀取样,且每个样本的权重相同
Boosting根据错误率调整样本权重,错误率越大的样本权重会变大
3.预测函数
Bagging预测函数权值相同
Boosting中误差越小的预测函数其权值越大
4.并行计算
Bagging 的各个预测函数可以并行生成
Boosting的各个预测函数必须按照顺序迭代生成
五.预测居民收入
项目背景:该数据从美国1994年人口普查数据库抽取而来,可以用来预测居民收入是否超过50K/year。该数据集类变量为年收入是否超过,属性变量包含年龄,工种,学历,职业,人种等重要信息,14个属性变量中有7个类别型变量import pandas as pd
import numpy as np
import seaborn as sns
%matplotlib inline
#读取文件
data_train=pd.read_csv('./income_census_train.csv')
#查看数据
data_train.head()
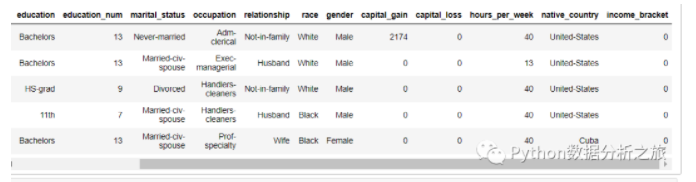
#数据查看与处理
#数值型特征的描述与相关总结
data_train.describe()
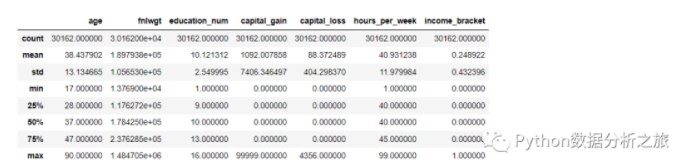
#非数值型
data_train.describe(include=['O'])

#删除序列数据
data = data_train.drop(['ID'],axis = 1)
#查看数据
data.head()
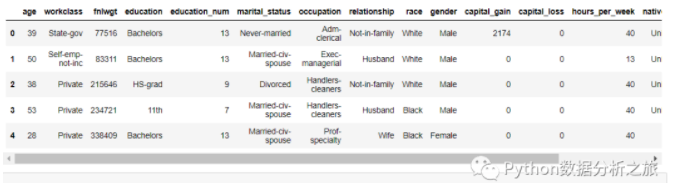
#数据转换
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# 将oject数据类型进行类别编码
for feature in data.columns:
if data[feature].dtype == 'object':
data[feature] = pd.Categorical(data[feature]).codes
#标准化处理
X = np.array(X_df)
y = np.array(y_df)
scaler = StandardScaler()
X = scaler.fit_transform(X)
fromsklearn.treeimportDecisionTreeClassifier
from pyecharts.charts import Scatter
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.charts import Page
#初始化
tree = DecisionTreeClassifier(random_state=0)
tree.fit(X, y)
#显示每个属性的相对重要性得分
relval = tree.feature_importances_
#构建数据
importances_df = pd.DataFrame({
'feature' : data.columns[:-1],
'importance' : relval
})
importances_df.sort_values(by = 'importance', ascending = False, inplace = True)
#作图
bar = Bar()
bar.add_xaxis(importances_df.feature.tolist())
bar.add_yaxis(
'importance',
importances_df.importance.tolist(),
label_opts = opts.LabelOpts(is_show = False))
bar.set_global_opts(
title_opts = opts.TitleOpts(title = '糖尿病数据各特征重要程度'),
xaxis_opts = opts.AxisOpts(axislabel_opts = opts.LabelOpts(rotate = 30)),
datazoom_opts = [opts.DataZoomOpts()]
)
bar.render('diabetes_importances_bar.html')
bar.render_notebook()
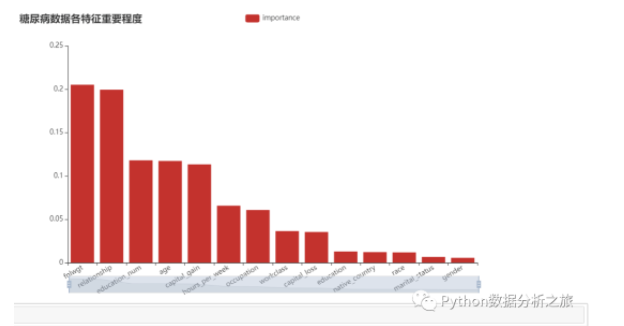
#特征筛选
from sklearn.feature_selection import RFE
# 使用决策树作为模型
lr = DecisionTreeClassifier()
names = X_df.columns.tolist()
#将所有特征排序,筛选前10个重要性较高特征
selector = RFE(lr, n_features_to_select = 10)
selector.fit(X,y.ravel())
#得到新的dataframe
X_df_new = X_df.iloc[:, selector.get_support(indices = False)]
X_df_new.columns

from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score,confusion_matrix
#标准化
X_new = scaler.fit_transform(np.array(X_df_new))
#分离数据
X_train, X_test, y_train, y_test = train_test_split(X_new,y,test_size = 0.3,random_state=0)
#随机森林分类
model_rf=RandomForestClassifier()
model_rf.fit(X_train,y_train)
#预测
model_rf.predict(X_test)
#输出准确率
print(round(accuracy_score(y_test,model_rf.predict(X_test)),2))
#总体来说不是很高,后期我们还需要再次提升

import itertools
#绘制混淆矩阵
def plot_confusion_matrix(cm, classes, title='Confusion matrix', cmap=plt.cm.Blues):
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
#设置thresh值
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
#设置布局
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
#参考链接:https://www.heywhale.com/mw/project/5bfb6342954d6e0010675425/content
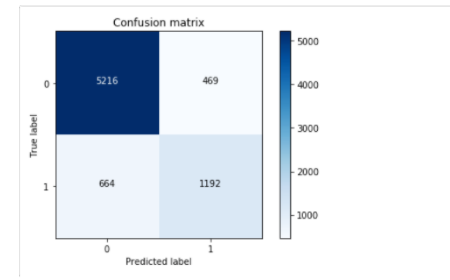
#计算矩阵
#计算矩阵
cm = confusion_matrix(y_test,model_rf.predict(X_test))
class_names = [0,1]
#绘制图形
plt.figure()
#输出混淆矩阵
plot_confusion_matrix(cm , classes=class_names, title='Confusion matrix')
#显示图形
plt.show()
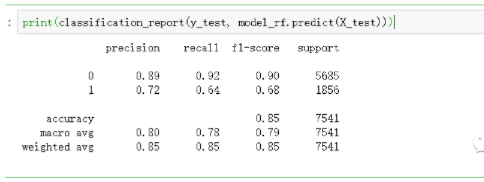
#输出预测信息,感兴趣读者可以手动验证一下
print(classification_report(y_test, model_rf.predict(X_test)))
-
集成
+关注
关注
1文章
177浏览量
30552 -
算法
+关注
关注
23文章
4687浏览量
94441 -
决策树
+关注
关注
3文章
96浏览量
13754
发布评论请先 登录
基于Qualcomm DSP的算法集成案例
基于Qualcomm DSP的算法集成系列
AI应用于医疗预测 需集成机器学习与行为算法
基于改进CNN网络与集成学习的人脸识别算法
17个机器学习的常用算法!

深度学习算法简介 深度学习算法是什么 深度学习算法有哪些
深度学习算法库框架学习
机器学习算法总结 机器学习算法是什么 机器学习算法优缺点
机器学习vsm算法
机器学习有哪些算法?机器学习分类算法有哪些?机器学习预判有哪些算法?
深度学习算法在集成电路测试中的应用

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
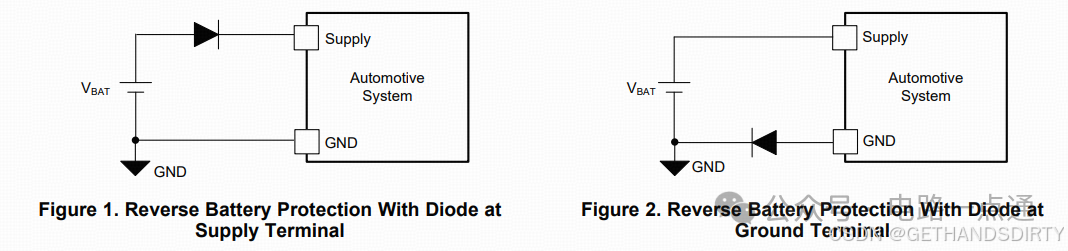
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极
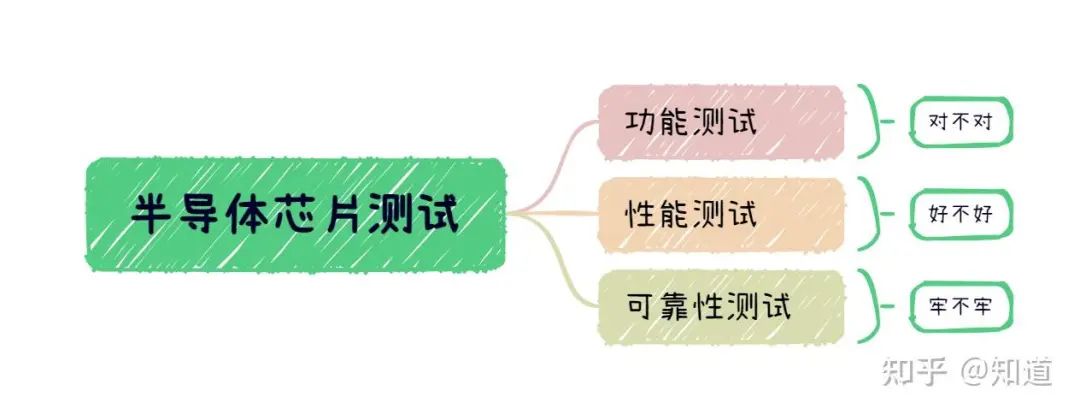
半导体芯片需要做哪些测试
首先我们需要了解芯片制造环节做⼀款芯片最基本的环节是设计->流片->封装->测试,芯片成本构成⼀般为人力成本20%,流片40%,封装35%,测试5%(对于先进工艺,流片成本可能超过60%)。测试其实是芯片各个环节中最“便宜”的一步,在这个每家公司都喊着“CostDown”的激烈市场中,人力成本逐年攀升,晶圆厂和封装厂都在乙方市场中“叱咤风云”,唯独只有测试显

解决方案 | 芯佰微赋能示波器:高速ADC、USB控制器和RS232芯片——高性能示波器的秘密武器!
示波器解决方案总述:示波器是电子技术领域中不可或缺的精密测量仪器,通过直观的波形显示,将电信号随时间的变化转化为可视化图形,使复杂的电子现象变得清晰易懂。无论是在科研探索、工业检测还是通信领域,示波器都发挥着不可替代的作用,帮助工程师和技术人员深入剖析电信号的细节,精准定位问题所在,为创新与发展提供坚实的技术支撑。一、技术瓶颈亟待突破性能指标受限:受模拟前端
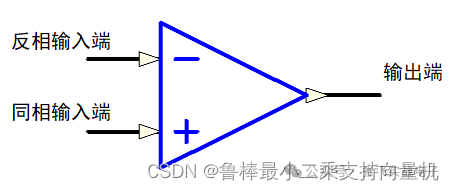
硬件设计基础----运算放大器
1什么是运算放大器运算放大器(运放)用于调节和放大模拟信号,运放是一个内含多级放大电路的集成器件,如图所示:左图为同相位,Vn端接地或稳定的电平,Vp端电平上升,则输出端Vo电平上升,Vp端电平下降,则输出端Vo电平下降;右图为反相位,Vp端接地或稳定的电平,Vn端电平上升,则输出端Vo电平下降,Vn端电平下降,则输出端Vo电平上升2运算放大器的性质理想运算

ElfBoard技术贴|如何调整eMMC存储分区
ELF 2开发板基于瑞芯微RK3588高性能处理器设计,拥有四核ARM Cortex-A76与四核ARM Cortex-A55的CPU架构,主频高达2.4GHz,内置6TOPS算力的NPU,这一设计让它能够轻松驾驭多种深度学习框架,高效处理各类复杂的AI任务。

米尔基于MYD-YG2LX系统启动时间优化应用笔记
1.概述MYD-YG2LX采用瑞萨RZ/G2L作为核心处理器,该处理器搭载双核Cortex-A55@1.2GHz+Cortex-M33@200MHz处理器,其内部集成高性能3D加速引擎Mail-G31GPU(500MHz)和视频处理单元(支持H.264硬件编解码),16位的DDR4-1600/DDR3L-1333内存控制器、千兆以太网控制器、USB、CAN、
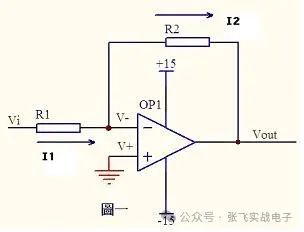
运放技术——基本电路分析
虚短和虚断的概念由于运放的电压放大倍数很大,一般通用型运算放大器的开环电压放大倍数都在80dB以上。而运放的输出电压是有限的,一般在10V~14V。因此运放的差模输入电压不足1mV,两输入端近似等电位,相当于“短路”。开环电压放大倍数越大,两输入端的电位越接近相等。“虚短”是指在分析运算放大器处于线性状态时,可把两输入端视为等电位,这一特性称为虚假短路,简称

飞凌嵌入式携手中移物联,谱写全国产化方案新生态
4月22日,飞凌嵌入式“2025嵌入式及边缘AI技术论坛”在深圳成功举办。中移物联网有限公司(以下简称“中移物联”)携OneOS操作系统与飞凌嵌入式共同推出的工业级核心板亮相会议展区,操作系统产品部高级专家严镭受邀作《OneOS工业操作系统——助力国产化智能制造》主题演讲。
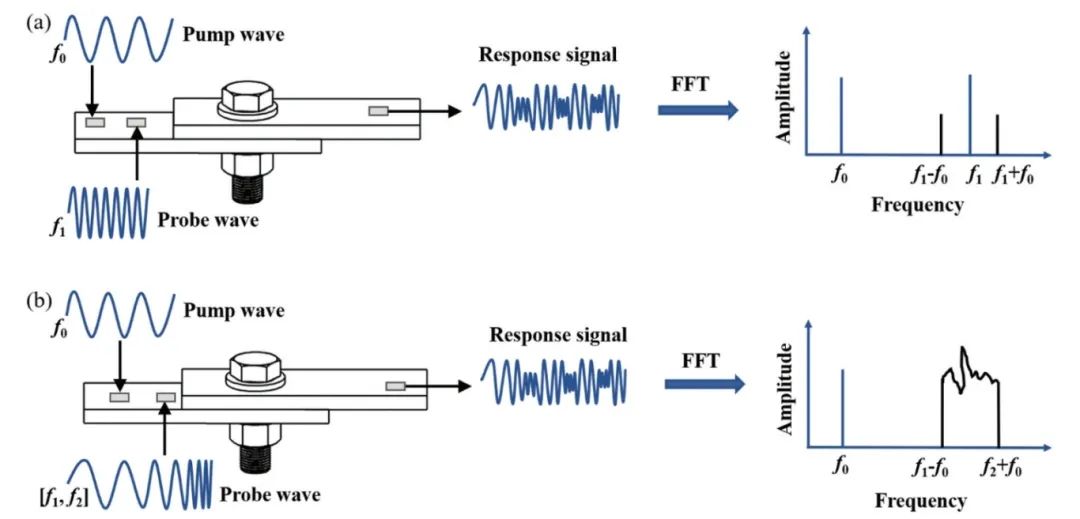
ATA-2022B高压放大器在螺栓松动检测中的应用
实验名称:ATA-2022B高压放大器在螺栓松动检测中的应用实验方向:超声检测实验设备:ATA-2022B高压放大器、函数信号发生器,压电陶瓷片,数据采集卡,示波器,PC等实验内容:本研究基于振动声调制的螺栓松动检测方法,其中低频泵浦波采用单频信号,而高频探测波采用扫频信号,利用泵浦波和探测波在接触面的振动声调制响应对螺栓的松动程度进行检测。通过螺栓松动检测
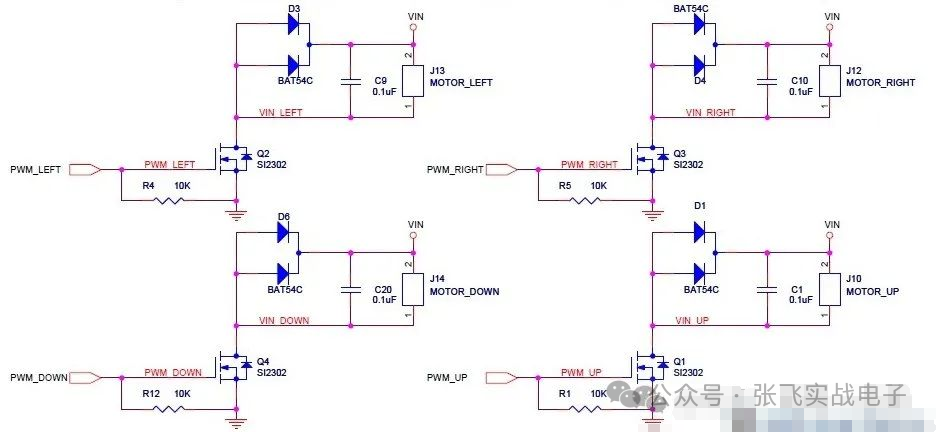
MOS管驱动电路——电机干扰与防护处理
此电路分主电路(完成功能)和保护功能电路。MOS管驱动相关知识:1、跟双极性晶体管相比,一般认为使MOS管导通不需要电流,只要GS电压(Vbe类似)高于一定的值,就可以了。MOS管和晶体管向比较c,b,e—–>d(漏),g(栅),s(源)。2、NMOS的特性,Vgs大于一定的值就会导通,适合用于源极接地时的情况(低端驱动),只要栅极电压达到4V或10V就可以
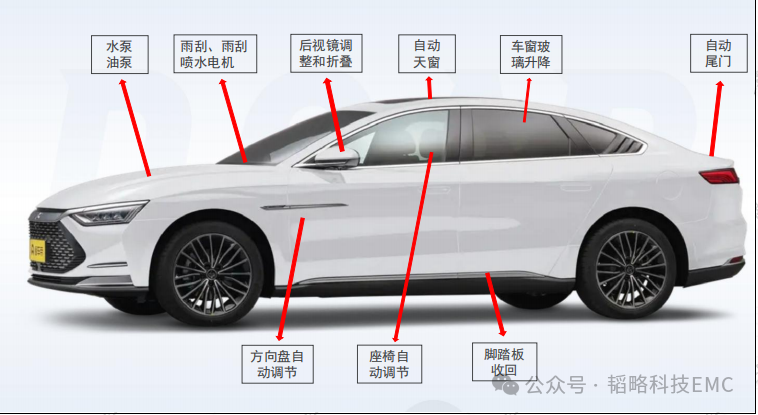
压敏(MOV)在电机上的应用剖析
一前言有刷直流电机是一种较为常见的直流电机。它的主要特点包括:1.结构相对简单,由定子、转子、电刷和换向器等组成;2.通过电刷与换向器的接触来实现电流的换向,从而使电枢绕组中的电流方向周期性改变,保证电机持续运转;3.具有调速性能较好等优点,可以通过改变电压等方式较为方便地调节转速。有刷直流电机在许多领域都有应用,比如一些电动工具、玩具、小型机械等。但它也存
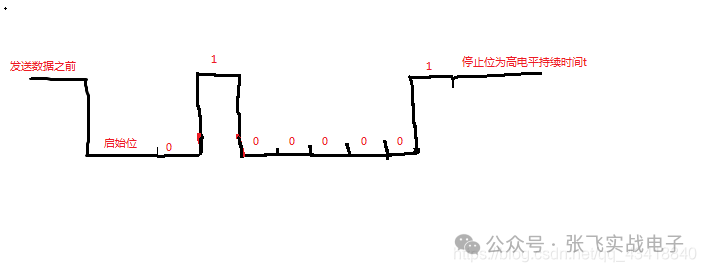
硬件原理图学习笔记
这一个星期认真学习了硬件原理图的知识,做了一些笔记,方便以后查找。硬件原理图分为三类1.管脚类(gpio)和门电路类输入输出引脚,上拉电阻,三极管与门,或门,非门上拉电阻:正向标志作用,给悬空的引脚一个确定的状态三极管:反向三极管(gpio输出高电平,NP两端导通,被控制端导通,电压为0)->NPN正向三极管(gpio输出低电平,PN两端导通,被控制端导通,

TurMass™ vs LoRa:无线通讯模块的革命性突破
TurMass™凭借其高传输速率、强大并发能力、双向传输、超强抗干扰能力、超远传输距离、全国产技术、灵活组网方案以及便捷开发等八大优势,在无线通讯领域展现出强大的竞争力。

RZT2H CR52双核BOOT流程和例程代码分析
RZT2H是多核处理器,启动时,需要一个“主核”先启动,然后主核根据规则,加载和启动其他内核。本文以T2H内部的CR52双核为例,说明T2H多核启动流程。





 工商网监
工商网监
评论