 如何度量知识蒸馏中不同数据增强方法的好坏?
如何度量知识蒸馏中不同数据增强方法的好坏?
1. 研究背景与动机
知识蒸馏(knowledge distillation,KD)是一种通用神经网络训练方法,它使用大的teacher模型来 “教” student模型,在各种AI任务上有着广泛应用。数据增强(data augmentation,DA) 更是神经网络训练的标配技巧。
知识蒸馏按照蒸馏的位置通常分为(1)基于网络中间特征图的蒸馏,(2)基于网络输出的蒸馏。对于后者来说,近几年分类任务上KD的发展主要集中在新的损失函数,譬如ICLR’20的CRD和ECCV’20的SSKD将对比学习引入损失函数,可以从teacher模型中提取到更丰富的信息,供student模型学习,实现了当时的SOTA。
本文没有探索损失函数、蒸馏位置等传统研究问题上, 我们延用了最原始版本的KD loss (也就是Hinton等人在NIPS’14 workshop上提出KD的时候用的Cross-Entropy + KL divergence )。我们重点关注网络的输入端:如何度量不同数据增强方法在KD中的好坏?(相比之下,之前的KD paper大多关注网络的中间特征,或者输出端)。系统框图如下所示,本文的核心目标是要提出一种指标去度量图中 “Stronger DA” 的强弱程度。
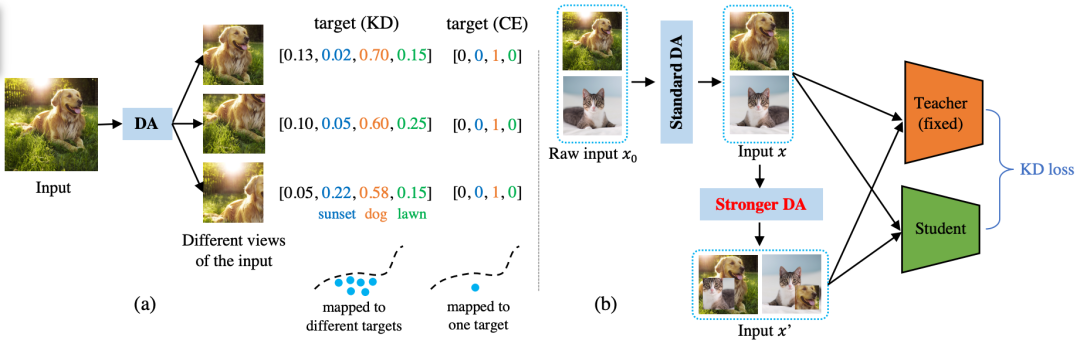
这一切起源于一个偶然的实验发现:在KD中延长迭代次数,通常可以非常明显地提升KD的性能。譬如KD实验中常用的ResNet34/ResNet18 pair, 在ImageNet-1K上,将迭代次数从100 epochs增加到200 epochs,可以将top1/top5准确率从70.66/89.88提升到71.38/90.59, 达到当时的SOTA方法CRD的性能(71.38/90.49)。这显得很迷,将最baseline的方法训练久一点就可以SOTA?经过很多实验分析我们最终发现,是数据增强在背后起作用。
直觉上的解释是:每次迭代,数据增强是随机的,得到的样本都不一样。那么,迭代次数变多,student见到的不一样的样本就越多,这可以从teacher模型中提取到更丰富的信息(跟对比学习loss似乎有着异曲同工之妙),帮助student模型学习。
很自然我们可以进一步推想:不同数据增强方法引入的数据“多样性”应该是不同的,譬如我们期待基于强化学习搜出来的AutoAugment应该要比简单的随机翻转要更具有多样性。简单地说,这篇paper就是在回答:具体怎么度量这种多样性,以及度量完之后我们怎么在实际中应用。
为什么这个问题重要?(1)理论意义:帮助我们更深地理解KD和DA,(2)实际意义:实验表明在KD中使用更强的DA总能提高性能,如果我们知道了什么因素在控制这种“强弱”,那么我们就可以缔造出更强的DA,从而坐享KD性能的提升。
2. 主要贡献和内容
文章的主要贡献是三点:
(1)我们提出了一个定理来严格回答什么样的数据增强是好的,结论是:好的数据增强方法应该降低teacher-student交叉熵的协方差。
定理的核心部分是看不同数据增强方法下训练样本之间的相关性,相关性越大意味着样本越相似,多样性就越低,student性能应该越差。这个直觉完全符合文中的证明,这是理论上的贡献。值得一提的是,相关性不是直接算原始样本之间的相关性,而是算样本经过了teacher得到的logits之间的相关性,也就是,raw data层面上样本的相关性不重要,重要的是在teacher看来这些样本有多么相似,越不相似越好。
(2)基于这个定理,提出了一个具体可用的指标(stddev of teacher’s mean probability, T. stddev),可以对每一种数据增强方法算一个数值出来, 按照这个数值排序,就知道哪种数据增强方法最好。文中测试了7种既有数据增强方法, 发现CutMix最好用。
(3)基于该定理,提出了一种新的基于信息熵筛选的数据增强方法,叫做CutMixPick,它是在CutMix的基础上挑选出熵最大的样本(熵大意味着信息量大,多样性多)进行训练。实验表明,即使是使用最普通的KD loss也可以达到SOTA KD方法(例如CRD)的水平。
3. 实验效果
文中最重要的实验是,验证提出的指标(T. Stddev)是否真的能刻画不同数据增强方法下student性能(S. test loss)的好坏,也就是二者之间的相关性如何。结果表明:相关性显著!
文章总共测试了9种数据增强方法,我们在CIFAR100,Tiny ImageNet, ImageNet100上均做了验证,相关性都很强,p-value多数情况下远小于5%的显著性界限,如下所示:
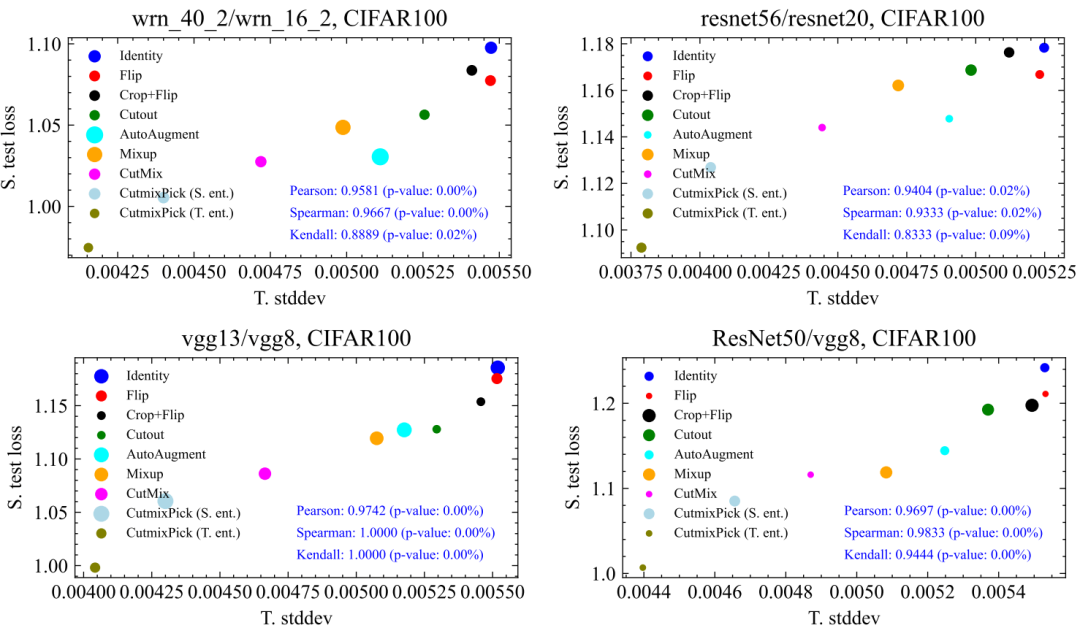
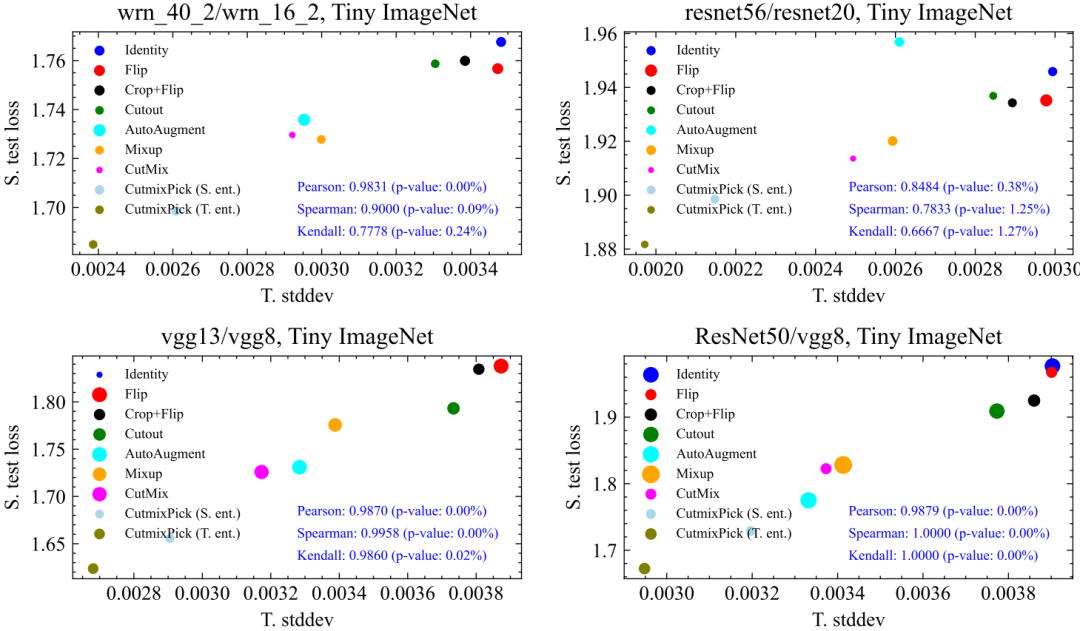
这其中最有意思的一点是,纵轴是student的性能,而横轴的指标是完全用teacher计算出来的,对于student没有任何信息,但是somehow,二者呈现出很强的相关性。这说明,KD中对DA好坏的评价很可能独立于student的。同时,对于不同teacher、数据集,DA之间的相对排序也比较稳定(譬如CutMix稳定地比Cutout要好)。这些都意味着我们在一种网络、数据集下找到的好的DA有很大概率可以迁移到其他的网络跟数据集中,大大提升了实际应用价值。
4. 总结和局限性
本文关注数据增强在知识蒸馏中的影响,在理论和实际算法方面均有贡献,主要有三点:(1) 我们对 “如何度量知识蒸馏中不同数据增强方法的好坏” 这一问题给出了严格的理论分析(答:好的数据增强方法应该最小化teacher-student交叉熵的协方差);(2)基于该理论提出了一个实际可计算的度量指标(stddev of teacher’s mean probability);(3)最后提出了一个基于信息熵筛选的新数据增强方法(CutMixPick),可以进一步提升CutMix,在KD中达到新的SOTA性能。
审核编辑:刘清
-
神经网络
+关注
关注
42文章
4798浏览量
102485 -
CRD
+关注
关注
0文章
14浏览量
4105
原文标题:NeurIPS 2022 | 如何度量知识蒸馏中不同数据增强方法的好坏?一种统计学视角
文章出处:【微信号:CVer,微信公众号:CVer】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于AHP度量模型的安全管理度量方法
基于等级保护的安全管理度量方法研究
构件内聚性度量方法研究
混杂数据的多核几何平均度量学习
内存取证的内核完整性度量方法
深度学习:知识蒸馏的全过程
基于知识蒸馏的恶意代码家族检测方法研究综述

电池修复技术:做蒸馏水的方法是怎样的
若干蒸馏方法之间的细节以及差异
关于快速知识蒸馏的视觉框架
用于NAT的选择性知识蒸馏框架
TPAMI 2023 | 用于视觉识别的相互对比学习在线知识蒸馏

任意模型都能蒸馏!华为诺亚提出异构模型的知识蒸馏方法

大连理工提出基于Wasserstein距离(WD)的知识蒸馏方法

瑞萨RA8系列教程 | 基于 RASC 生成 Keil 工程
对于不习惯用 e2 studio 进行开发的同学,可以借助 RASC 生成 Keil 工程,然后在 Keil 环境下愉快的完成开发任务。

共赴之约 | 第二十七届中国北京国际科技产业博览会圆满落幕
作为第二十七届北京科博会的参展方,芯佰微有幸与800余家全球科技同仁共赴「科技引领创享未来」之约!文章来源:北京贸促5月11日下午,第二十七届中国北京国际科技产业博览会圆满落幕。本届北京科博会主题为“科技引领创享未来”,由北京市人民政府主办,北京市贸促会,北京市科委、中关村管委会,北京市经济和信息化局,北京市知识产权局和北辰集团共同承办。5万平方米的展览云集

道生物联与巍泰技术联合发布 RTK 无线定位系统:TurMass™ 技术与厘米级高精度定位的深度融合
道生物联与巍泰技术联合推出全新一代 RTK 无线定位系统——WTS-100(V3.0 RTK)。该系统以巍泰技术自主研发的 RTK(实时动态载波相位差分)高精度定位技术为核心,深度融合道生物联国产新兴窄带高并发 TurMass™ 无线通信技术,为室外大规模定位场景提供厘米级高精度、广覆盖、高并发、低功耗、低成本的一站式解决方案,助力行业智能化升级。

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
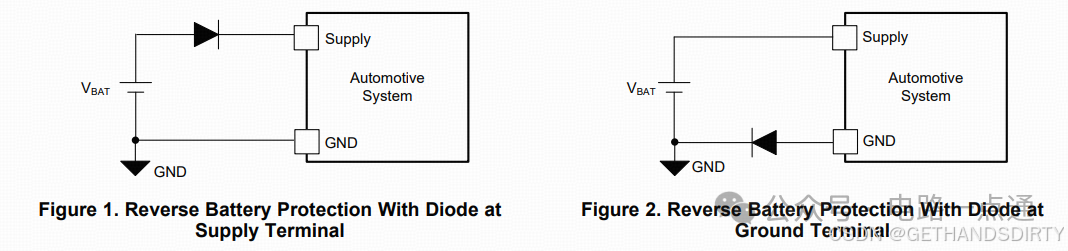
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极
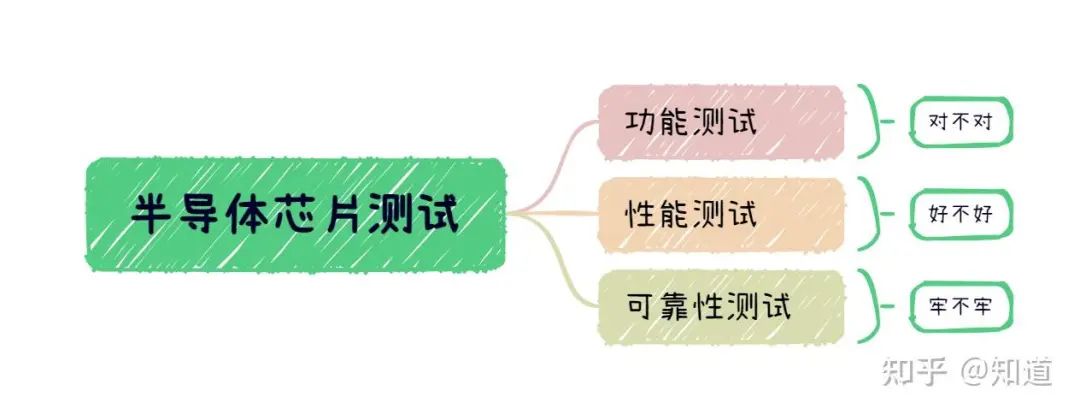
半导体芯片需要做哪些测试
首先我们需要了解芯片制造环节做⼀款芯片最基本的环节是设计->流片->封装->测试,芯片成本构成⼀般为人力成本20%,流片40%,封装35%,测试5%(对于先进工艺,流片成本可能超过60%)。测试其实是芯片各个环节中最“便宜”的一步,在这个每家公司都喊着“CostDown”的激烈市场中,人力成本逐年攀升,晶圆厂和封装厂都在乙方市场中“叱咤风云”,唯独只有测试显

解决方案 | 芯佰微赋能示波器:高速ADC、USB控制器和RS232芯片——高性能示波器的秘密武器!
示波器解决方案总述:示波器是电子技术领域中不可或缺的精密测量仪器,通过直观的波形显示,将电信号随时间的变化转化为可视化图形,使复杂的电子现象变得清晰易懂。无论是在科研探索、工业检测还是通信领域,示波器都发挥着不可替代的作用,帮助工程师和技术人员深入剖析电信号的细节,精准定位问题所在,为创新与发展提供坚实的技术支撑。一、技术瓶颈亟待突破性能指标受限:受模拟前端
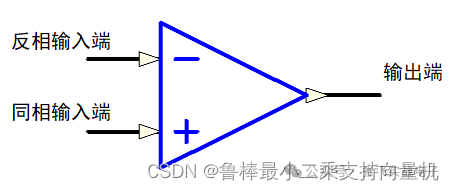
硬件设计基础----运算放大器
1什么是运算放大器运算放大器(运放)用于调节和放大模拟信号,运放是一个内含多级放大电路的集成器件,如图所示:左图为同相位,Vn端接地或稳定的电平,Vp端电平上升,则输出端Vo电平上升,Vp端电平下降,则输出端Vo电平下降;右图为反相位,Vp端接地或稳定的电平,Vn端电平上升,则输出端Vo电平下降,Vn端电平下降,则输出端Vo电平上升2运算放大器的性质理想运算

ElfBoard技术贴|如何调整eMMC存储分区
ELF 2开发板基于瑞芯微RK3588高性能处理器设计,拥有四核ARM Cortex-A76与四核ARM Cortex-A55的CPU架构,主频高达2.4GHz,内置6TOPS算力的NPU,这一设计让它能够轻松驾驭多种深度学习框架,高效处理各类复杂的AI任务。

米尔基于MYD-YG2LX系统启动时间优化应用笔记
1.概述MYD-YG2LX采用瑞萨RZ/G2L作为核心处理器,该处理器搭载双核Cortex-A55@1.2GHz+Cortex-M33@200MHz处理器,其内部集成高性能3D加速引擎Mail-G31GPU(500MHz)和视频处理单元(支持H.264硬件编解码),16位的DDR4-1600/DDR3L-1333内存控制器、千兆以太网控制器、USB、CAN、
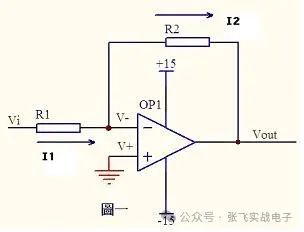
运放技术——基本电路分析
虚短和虚断的概念由于运放的电压放大倍数很大,一般通用型运算放大器的开环电压放大倍数都在80dB以上。而运放的输出电压是有限的,一般在10V~14V。因此运放的差模输入电压不足1mV,两输入端近似等电位,相当于“短路”。开环电压放大倍数越大,两输入端的电位越接近相等。“虚短”是指在分析运算放大器处于线性状态时,可把两输入端视为等电位,这一特性称为虚假短路,简称

飞凌嵌入式携手中移物联,谱写全国产化方案新生态
4月22日,飞凌嵌入式“2025嵌入式及边缘AI技术论坛”在深圳成功举办。中移物联网有限公司(以下简称“中移物联”)携OneOS操作系统与飞凌嵌入式共同推出的工业级核心板亮相会议展区,操作系统产品部高级专家严镭受邀作《OneOS工业操作系统——助力国产化智能制造》主题演讲。
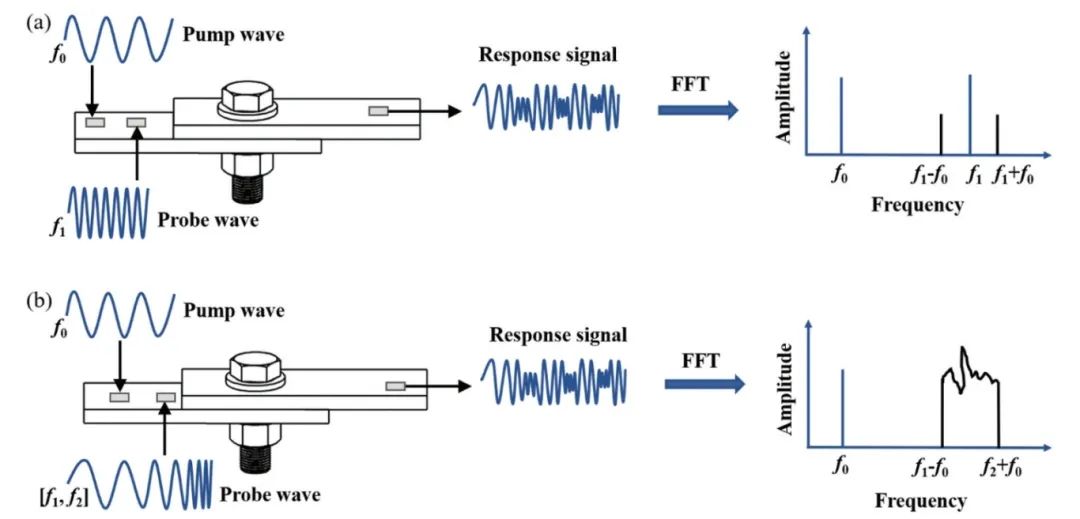
ATA-2022B高压放大器在螺栓松动检测中的应用
实验名称:ATA-2022B高压放大器在螺栓松动检测中的应用实验方向:超声检测实验设备:ATA-2022B高压放大器、函数信号发生器,压电陶瓷片,数据采集卡,示波器,PC等实验内容:本研究基于振动声调制的螺栓松动检测方法,其中低频泵浦波采用单频信号,而高频探测波采用扫频信号,利用泵浦波和探测波在接触面的振动声调制响应对螺栓的松动程度进行检测。通过螺栓松动检测
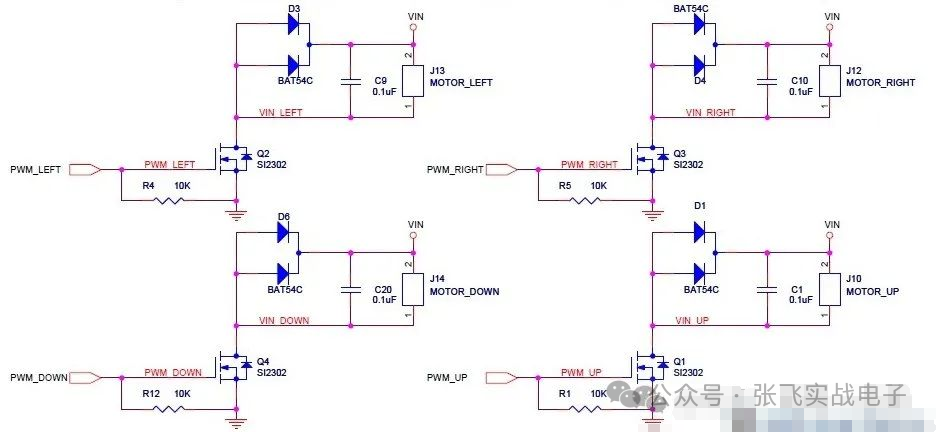
MOS管驱动电路——电机干扰与防护处理
此电路分主电路(完成功能)和保护功能电路。MOS管驱动相关知识:1、跟双极性晶体管相比,一般认为使MOS管导通不需要电流,只要GS电压(Vbe类似)高于一定的值,就可以了。MOS管和晶体管向比较c,b,e—–>d(漏),g(栅),s(源)。2、NMOS的特性,Vgs大于一定的值就会导通,适合用于源极接地时的情况(低端驱动),只要栅极电压达到4V或10V就可以
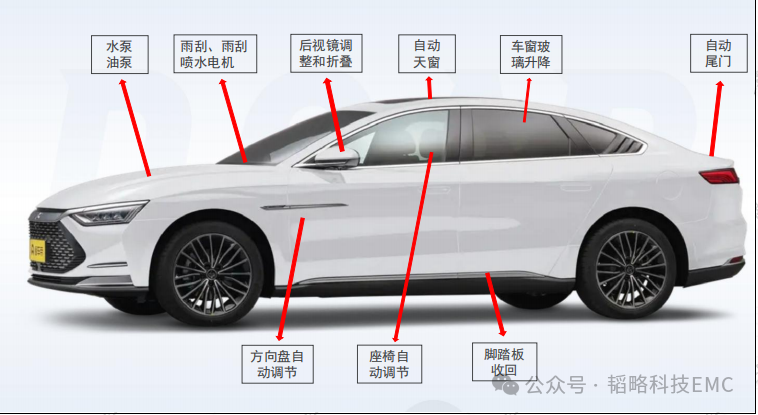
压敏(MOV)在电机上的应用剖析
一前言有刷直流电机是一种较为常见的直流电机。它的主要特点包括:1.结构相对简单,由定子、转子、电刷和换向器等组成;2.通过电刷与换向器的接触来实现电流的换向,从而使电枢绕组中的电流方向周期性改变,保证电机持续运转;3.具有调速性能较好等优点,可以通过改变电压等方式较为方便地调节转速。有刷直流电机在许多领域都有应用,比如一些电动工具、玩具、小型机械等。但它也存





 工商网监
工商网监
评论