 手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别
手把手教你使用LabVIEW ONNX Runtime部署 TensorRT加速,实现YOLOv5实时物体识别
前言
上一篇博客给大家介绍了LabVIEW开放神经网络交互工具包【ONNX】 ,今天我们就一起来看一下如何使用LabVIEW开放神经网络交互工具包实现TensorRT加速YOLOv5。
以下是YOLOv5的相关笔记总结,希望对大家有所帮助。
| 内容 | 地址链接 |
|---|---|
| 【YOLOv5】LabVIEW+OpenVINO让你的YOLOv5在CPU上飞起来 | https://blog.csdn.net/virobotics/article/details/124951862 |
| 【YOLOv5】LabVIEW OpenCV dnn快速实现实时物体识别(Object Detection) | https://blog.csdn.net/virobotics/article/details/124929483 |
一、TensorRT简介
TensorRT是一个高性能的深度学习推理(Inference)优化器,可以为深度学习应用提供低延迟、高吞吐率的部署推理。TensorRT可用于对超大规模数据中心、嵌入式平台或自动驾驶平台进行推理加速。TensorRT现已能支持TensorFlow、Caffe、Mxnet、Pytorch等几乎所有的深度学习框架,将TensorRT和NVIDIA的GPU结合起来,能在几乎所有的框架中进行快速和高效的部署推理。主要用来针对 NVIDIA GPU进行 高性能推理(Inference)加速。
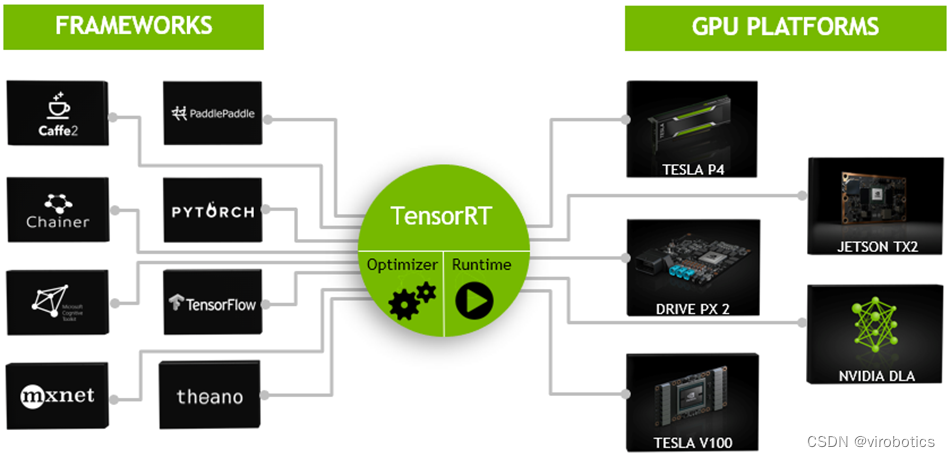
通常我们做项目,在部署过程中想要加速,无非就那么几种办法,如果我们的设备是CPU,那么可以用openvion,如果我们希望能够使用GPU,那么就可以尝试TensorRT了。那么为什么要选择TensorRT呢?因为我们目前主要使用的还是Nvidia的计算设备,TensorRT本身就是Nvidia自家的东西,那么在Nvidia端的话肯定要用Nvidia亲儿子了。
不过因为TensorRT的入门门槛略微有些高,直接劝退了想要入坑的玩家。其中一部分原因是官方文档比较杂乱;另一部分原因就是TensorRT比较底层,需要一点点C++和硬件方面的知识,学习难度会更高一点。我们做的****开放神经网络交互工具包GPU版本 , 在GPU上做推理时,ONNXRuntime可采用CUDA作为后端进行加速,要更快速可以切换到TensorRT ,虽然和纯TensorRT推理速度比还有些差距,但也十分快了。如此可以大大降低开发难度,能够更快更好的进行推理。。
二、准备工作
按照 LabVIEW开放神经网络交互工具包(ONNX)下载与超详细安装教程 安装所需软件,因本篇博客主要给大家介绍如何使用TensorRT加速YOLOv5,所以建议大家安装GPU版本的onnx工具包,否则无法实现TensorRT的加速 。
三、YOLOv5模型的获取
为方便使用, 博主已经将yolov5模型转化为onnx格式 ,可在百度网盘下载**
**链接:https://pan.baidu.com/s/15dwoBM4W-5_nlRj4G9EhRg?pwd=yiku
**提取码:yiku **
1.下载源码
将Ultralytics开源的YOLOv5代码Clone或下载到本地,可以直接点击Download ZIP进行下载,
下载地址: https://github.com/ultralytics/yolov5
2.安装模块
解压刚刚下载的zip文件,然后安装yolov5需要的模块,记住cmd的工作路径要在yolov5文件夹下:
打开cmd切换路径到yolov5文件夹下,并输入如下指令,安装yolov5需要的模块
pip install -r requirements.txt
3.下载预训练模型
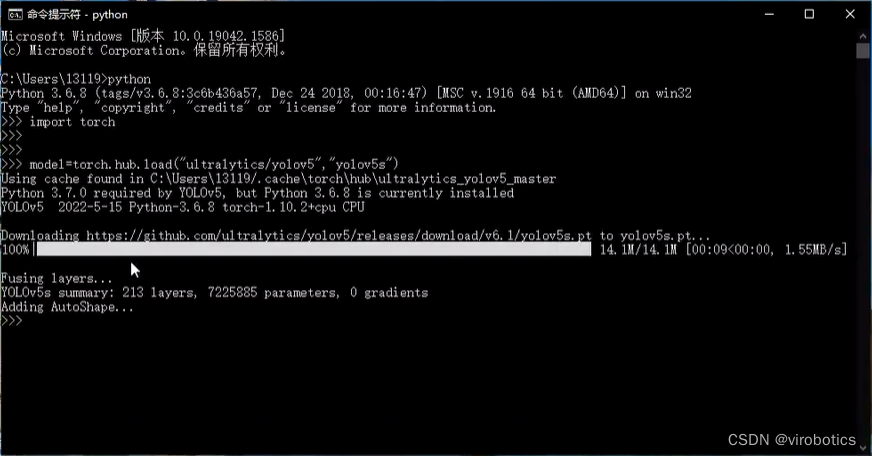
打开cmd,进入python环境,使用如下指令下载预训练模型:
import torch
# Model
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # or yolov5n - yolov5x6, custom
成功下载后如下图所示:
4.转换为onnx模型
在yolov5之前的yolov3和yolov4的官方代码都是基于darknet框架实现的,因此opencv的dnn模块做目标检测时,读取的是.cfg和.weight文件,非常方便。但是yolov5的官方代码是基于pytorch框架实现的。需要先把pytorch的训练模型.pt文件转换到.onnx文件,然后才能载入到opencv的dnn模块里。
将.pt文件转化为.onnx文件,主要是参考了nihate大佬的博客: https://blog.csdn.net/nihate/article/details/112731327
将export.py做如下修改,将def export_onnx()中的第二个try注释掉,即如下部分注释:
'''
try:
check_requirements(('onnx',))
import onnx
LOGGER.info(f'\\n{prefix} starting export with onnx {onnx.__version__}...')
f = file.with_suffix('.onnx')
print(f)
torch.onnx.export(
model,
im,
f,
verbose=False,
opset_version=opset,
training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
do_constant_folding=not train,
input_names=['images'],
output_names=['output'],
dynamic_axes={
'images': {
0: 'batch',
2: 'height',
3: 'width'}, # shape(1,3,640,640)
'output': {
0: 'batch',
1: 'anchors'} # shape(1,25200,85)
} if dynamic else None)
# Checks
model_onnx = onnx.load(f) # load onnx model
onnx.checker.check_model(model_onnx) # check onnx model
# Metadata
d = {'stride': int(max(model.stride)), 'names': model.names}
for k, v in d.items():
meta = model_onnx.metadata_props.add()
meta.key, meta.value = k, str(v)
onnx.save(model_onnx, f)'''
并新增一个函数def my_export_onnx():
def my_export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
print('anchors:', model.yaml['anchors'])
wtxt = open('class.names', 'w')
for name in model.names:
wtxt.write(name+'\\n')
wtxt.close()
# YOLOv5 ONNX export
print(im.shape)
if not dynamic:
f = os.path.splitext(file)[0] + '.onnx'
torch.onnx.export(model, im, f, verbose=False, opset_version=12, input_names=['images'], output_names=['output'])
else:
f = os.path.splitext(file)[0] + '_dynamic.onnx'
torch.onnx.export(model, im, f, verbose=False, opset_version=12, input_names=['images'],
output_names=['output'], dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
})
return f
在cmd中输入转onnx的命令(记得将export.py和pt模型放在同一路径下):
python export.py --weights yolov5s.pt --include onnx
如下图所示为转化成功界面
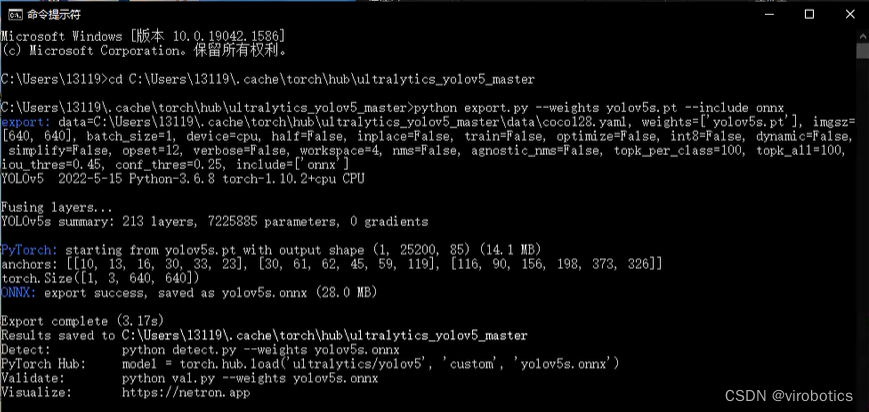
其中yolov5s可替换为yolov5m\\yolov5m\\yolov5l\\yolov5x

四、LabVIEW使用TensorRT加速YOLOv5,实现实时物体识别(yolov5_new_onnx.vi)
1.LabVIEW调用YOLOv5源码
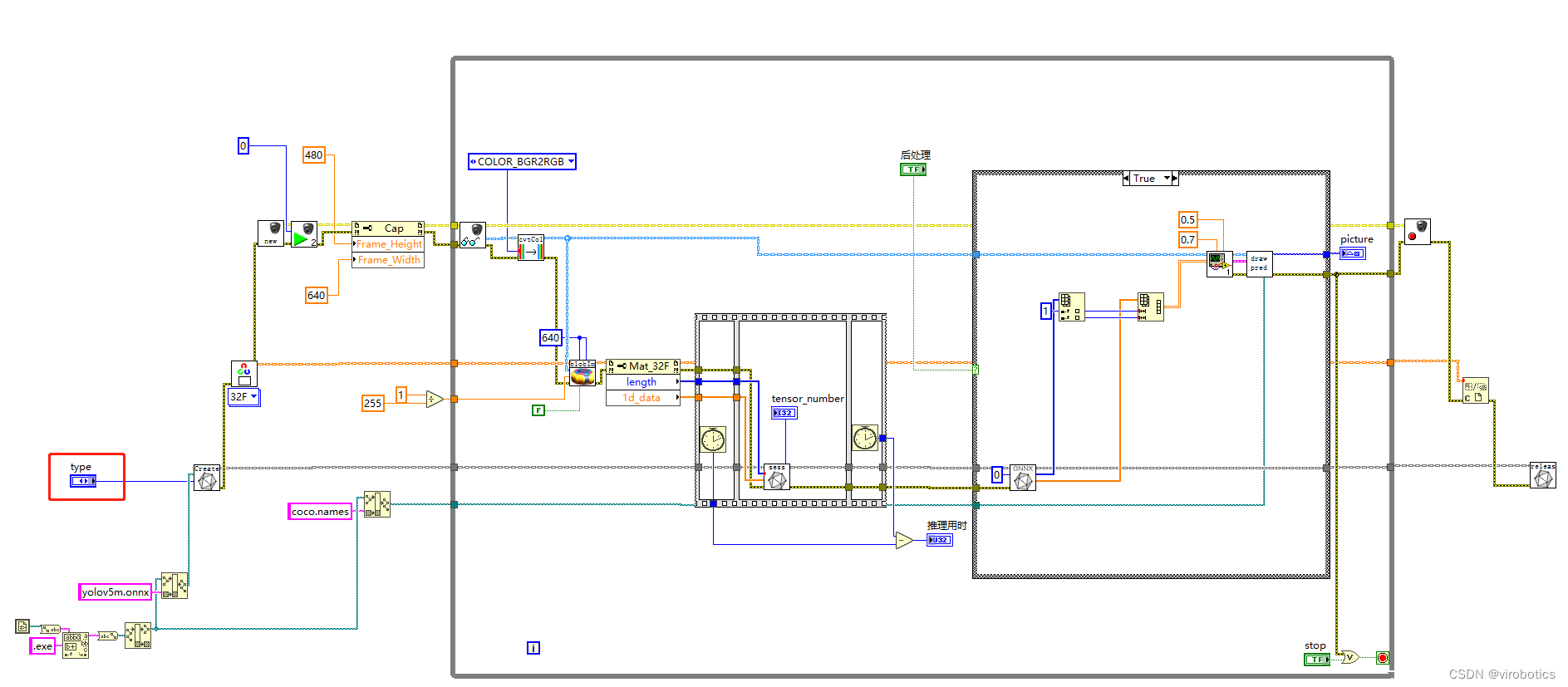
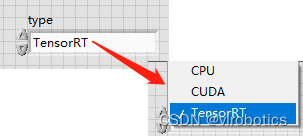
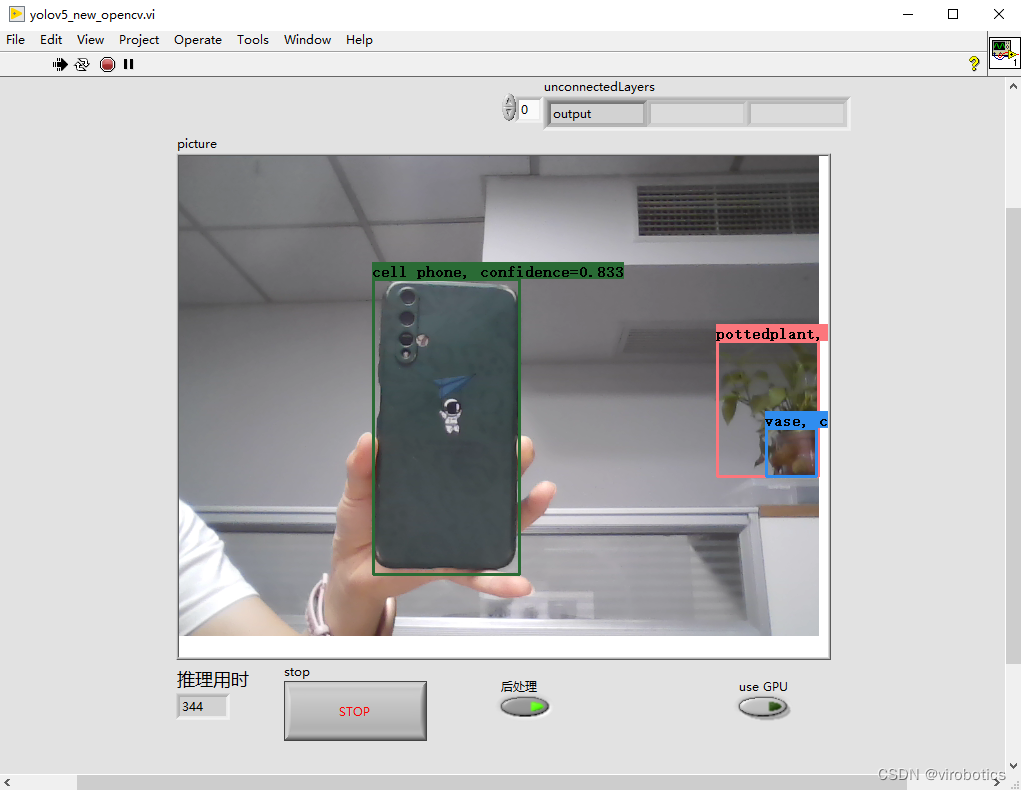
2.识别结果
选择加速方式为:TensorRT
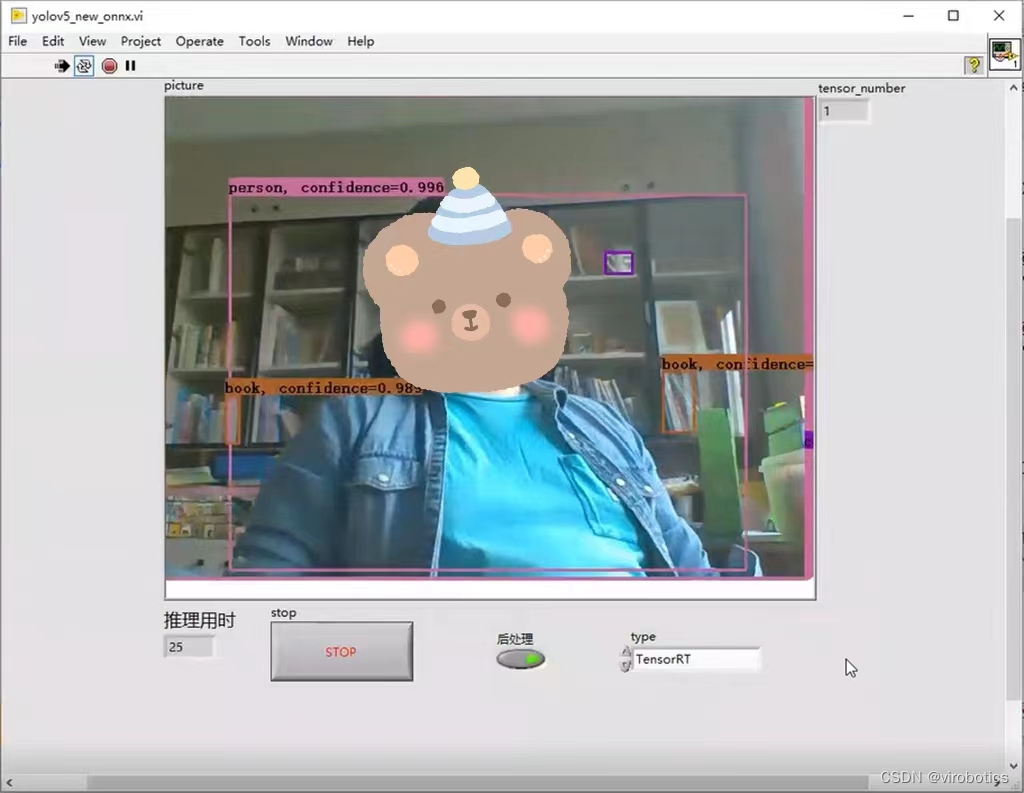
使用TensorRT加速,实时检测推理用时为****20~30ms/frame ,比单纯使用cuda加速快了30%,同时没有丢失任何的精度。博主使用的电脑显卡为1060显卡,各位如果使用30系列的显卡,速度应该会更快。**
**
可关注微信公众号:VIRobotics ,回复关键词:yolov5_onnx ,进行源码下载
五、纯CPU下opencv dnn和onnx工具包加载YOLOv5实现实时物体识别推理用时对比
1、opencv dnn cpu下YOLOv5推理速度为:300ms左右/frame
2、onnx工具包cpu下YOLOv5推理速度为:200ms左右/frame
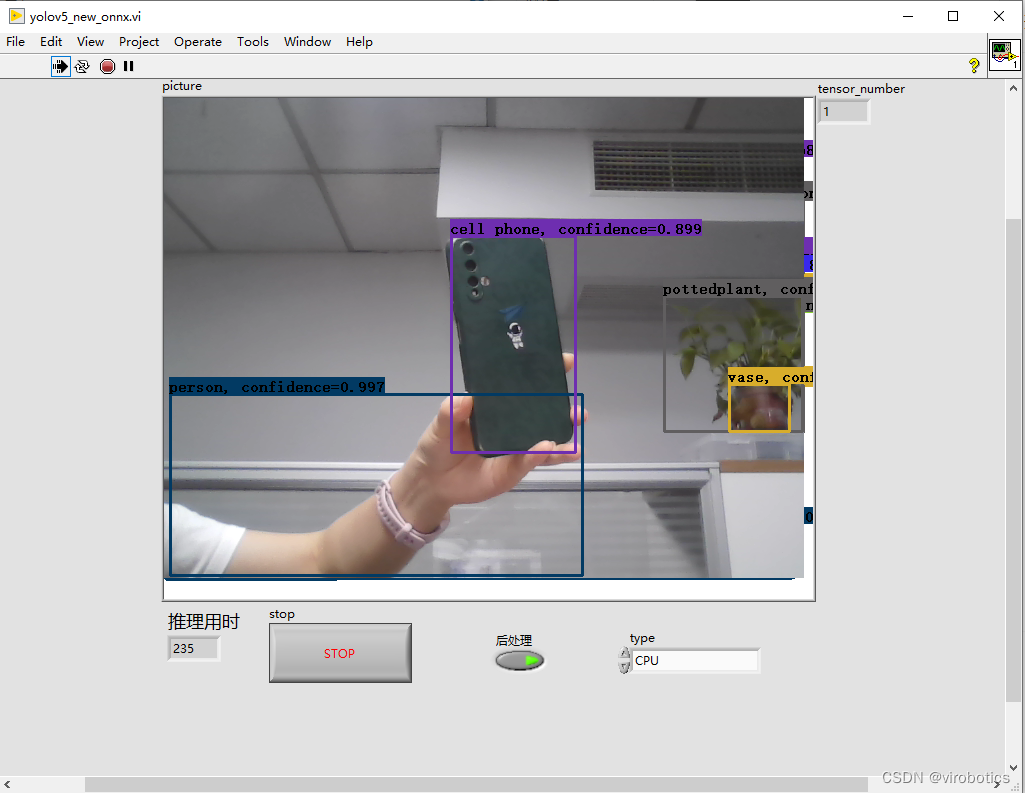
对比我们发现,同样使用cpu进行推理,onnx工具包推理速度要比opencv dnn推理速度快30%左右。
附加说明:计算机环境
- 操作系统:Windows10
- python:3.6及以上
- LabVIEW:2018及以上 64位版本
- 视觉工具包:virobotics_lib_onnx_cuda_tensorrt-1.0.0.11以上版本
总结
以上就是今天要给大家分享的内容。大家可根据链接下载相关源码与模型。
如果文章对你有帮助,欢迎关注、点赞、收藏
审核编辑 黄宇
-
LabVIEW
+关注
关注
1993文章
3669浏览量
332355 -
人工智能
+关注
关注
1804文章
48539浏览量
245565 -
目标检测
+关注
关注
0文章
222浏览量
15875 -
深度学习
+关注
关注
73文章
5552浏览量
122382
发布评论请先 登录
【YOLOv5】LabVIEW+YOLOv5快速实现实时物体识别(Object Detection)含源码
【YOLOv5】LabVIEW+TensorRT的yolov5部署实战(含源码)
yolov5转onnx在cubeAI上部署失败的原因?
yolov5转onnx在cubeAI进行部署,部署失败的原因?
【汇总篇】小草手把手教你 LabVIEW 串口仪器控制
龙哥手把手教你学视觉-深度学习YOLOV5篇
怎样使用PyTorch Hub去加载YOLOv5模型
yolov5转onnx在cubeAI进行部署的时候失败了是什么原因造成的?
yolov5模型onnx转bmodel无法识别出结果如何解决?
使用旭日X3派的BPU部署Yolov5


TwinCAT3 EtherCAT抓包 | 技术集结
在使用TwinCAT测试EtherCATEOE功能时,我们会发现正常是无法使用Wireshark去进行网络抓包抓取EtherCAT报文的,今天这篇文章就带大家来上手EtherCAT抓包方式。准备环境硬件环境:EtherKit开发板网线一根Type-CUSB线一根软件环境TwinCAT3RT-ThreadstudiowiresharkEtherCATEOE工程

EtherCAT科普系列(8):EtherCAT技术在机器视觉领域的应用
机器视觉是基于软件与硬件的组合,通过光学装置和非接触式的传感器自动地接受一个真实物体的图像,并利用软件算法处理图像以获得所需信息或用于控制机器人运动的装置。机器视觉可以赋予机器人及自动化设备获取外界信息并认知处理的能力。机器视觉系统内包含光学成像系统,可以作为自动化设备的视觉器官实现信息的输入,并借助视觉控制器代替人脑实现信息的处理与输出。从而实现赋予自动化

新品 | 26+6TOPS强悍算力!飞凌嵌入式FCU3501嵌入式控制单元发布
飞凌嵌入式FCU3501嵌入式控制单元基于瑞芯微RK3588处理器开发设计,4xCortex-A76+4xCortex-A55架构,A76主频高达2.4GHz,A55核主频高达1.8GHz,支持8K编解码,NPU算力6TOPS,支持算力卡拓展,可以插装Hailo-8 26TOPS M.2算力卡。

接口核心板必选 | 视美泰AIoT-3568SC 、 AIoT-3576SC:小身材大能量,轻松应对多场景设备扩展需求!
在智能硬件领域,「适配」是绕不开的关键词。无论是小屏设备的”寸土寸金”,还是模具开发的巨额成本,亦或是多产品线兼容的复杂需求,开发者总在寻找一款能「以不变应万变」的核心解决方案。视美泰旗下的AIoT-3568SC与AIoT-3576SC接口核心板系列,可以说是专为高灵活适配场景而生!无需为设备尺寸、模具限制或产品线差异妥协,一块核心板,即可释放无限可能。为什

3核A7+单核M0多核异构,米尔全新低功耗RK3506核心板发布
近日,米尔电子发布MYC-YR3506核心板和开发板,基于国产新一代入门级工业处理器瑞芯微RK3506,这款芯片采用三核Cortex-A7+单核Cortex-M0多核异构设计,不仅拥有丰富的工业接口、低功耗设计,还具备低延时和高实时性的特点。核心板提供RK3506B/RK3506J、商业级/工业级、512MB/256MBLPDDR3L、8GBeMMC/256
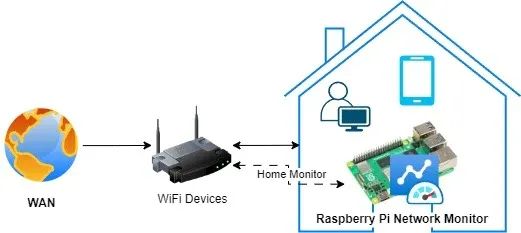
搭建树莓派网络监控系统:顶级工具与技术终极指南!
树莓派网络监控系统是一种经济高效且功能多样的解决方案,可用于监控网络性能、流量及整体运行状况。借助树莓派,我们可以搭建一个网络监控系统,实时洞察网络活动,从而帮助识别问题、优化性能并确保网络安全。安装树莓派网络监控系统有诸多益处。树莓派具备以太网接口,还内置了Wi-Fi功能,拥有足够的计算能力和内存,能够在Linux或Windows系统上运行。因此,那些为L
STM32驱动SD NAND(贴片式SD卡)全测试:GSR手环生物数据存储的擦写寿命与速度实测
在智能皮电手环及数据存储技术不断迭代的当下,主控 MCU STM32H750 与存储 SD NAND MKDV4GIL-AST 的强强联合,正引领行业进入全新发展阶段。二者凭借低功耗、高速读写与卓越稳定性的深度融合,以及高容量低成本的突出优势,成为大规模生产场景下极具竞争力的数据存储解决方案。

芯对话 | CBM16AD125Q这款ADC如何让我的性能翻倍?
综述在当今数字化时代,模数转换器(ADC)作为连接模拟世界与数字系统的关键桥梁,其技术发展对众多行业有着深远影响。从通信领域追求更高的数据传输速率与质量,到医疗影像领域渴望更精准的疾病诊断,再到工业控制领域需要适应复杂恶劣环境的稳定信号处理,ADC的性能提升成为推动这些行业进步的重要因素。行业现状分析在通信行业,5G乃至未来6G的发展,对基站信号处理提出了极
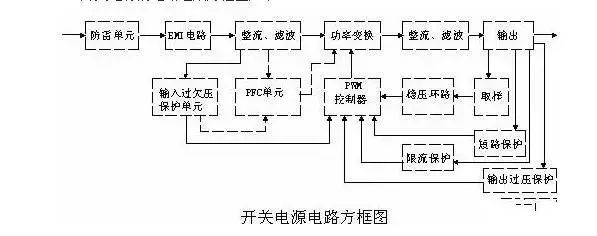
史上最全面解析:开关电源各功能电路
01开关电源的电路组成开关电源的主要电路是由输入电磁干扰滤波器(EMI)、整流滤波电路、功率变换电路、PWM控制器电路、输出整流滤波电路组成。辅助电路有输入过欠压保护电路、输出过欠压保护电路、输出过流保护电路、输出短路保护电路等。开关电源的电路组成方框图如下:02输入电路的原理及常见电路1AC输入整流滤波电路原理①防雷电路:当有雷击,产生高压经电网导入电源时
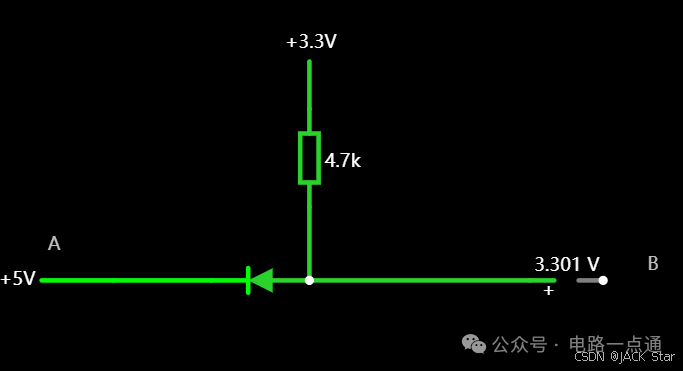
有几种电平转换电路,适用于不同的场景
一.起因一般在消费电路的元器件之间,不同的器件IO的电压是不同的,常规的有5V,3.3V,1.8V等。当器件的IO电压一样的时候,比如都是5V,都是3.3V,那么其之间可以直接通讯,比如拉中断,I2Cdata/clk脚双方直接通讯等。当器件的IO电压不一样的时候,就需要进行电平转换,不然无法实现高低电平的变化。二.电平转换电路常见的有几种电平转换电路,适用于

瑞萨RA8系列教程 | 基于 RASC 生成 Keil 工程
对于不习惯用 e2 studio 进行开发的同学,可以借助 RASC 生成 Keil 工程,然后在 Keil 环境下愉快的完成开发任务。

共赴之约 | 第二十七届中国北京国际科技产业博览会圆满落幕
作为第二十七届北京科博会的参展方,芯佰微有幸与800余家全球科技同仁共赴「科技引领创享未来」之约!文章来源:北京贸促5月11日下午,第二十七届中国北京国际科技产业博览会圆满落幕。本届北京科博会主题为“科技引领创享未来”,由北京市人民政府主办,北京市贸促会,北京市科委、中关村管委会,北京市经济和信息化局,北京市知识产权局和北辰集团共同承办。5万平方米的展览云集

道生物联与巍泰技术联合发布 RTK 无线定位系统:TurMass™ 技术与厘米级高精度定位的深度融合
道生物联与巍泰技术联合推出全新一代 RTK 无线定位系统——WTS-100(V3.0 RTK)。该系统以巍泰技术自主研发的 RTK(实时动态载波相位差分)高精度定位技术为核心,深度融合道生物联国产新兴窄带高并发 TurMass™ 无线通信技术,为室外大规模定位场景提供厘米级高精度、广覆盖、高并发、低功耗、低成本的一站式解决方案,助力行业智能化升级。

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
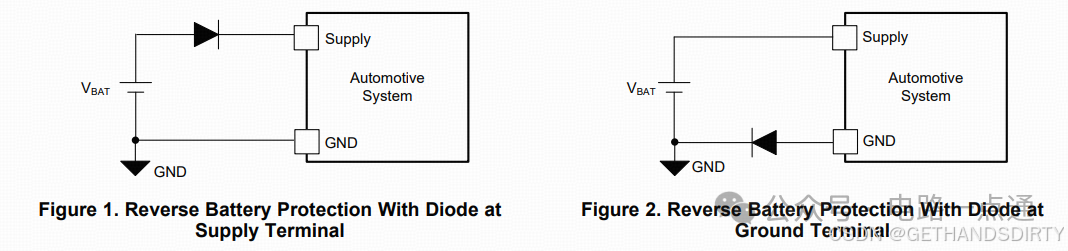
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极





 工商网监
工商网监
评论