 如何学习MR-SLAM的紧凑描述符的问题
如何学习MR-SLAM的紧凑描述符的问题
作者:K.Fire | 来源:3D视觉工坊 在公众号「3D视觉工坊」后台,回复「原论文」即可获取论文pdf。 添加微信:cv3d007,备注:SLAM,拉你入群。文末附行业细分群。
本文通过生成具有最小推理时间的紧凑且具有判别性的特征描述符来解决多机器人探索过程中保持低水平通信带宽的同时进行精确定位的问题;文中将描述符生成转化为老师-学生框架下的学习问题。首先设计一个紧凑的学生网络,通过从预训练的大型教师模型中转移知识来学习它。为了减少从教师到学生的描述符维度,文中提出了一种新的损失函数,使知识在两个不同维度的描述符之间转移。
1 前言
多机器人SLAM系统(MR-SLAM系统)相比单机器人系统最主要的限制是:通信带宽的限制。在MR-SLAM系统中,为了整合整个团队的所有轨迹,团队中的每个机器人都需要共享其关键帧数据(包括关键帧姿态和观察到的特征点),以处理机器人间的闭环和全局定位。这种类型的数据交换占用了很高的通信容量,很可能降低实时性能。
一些工程上的解决方案比如降低频率、减少关键点数量可以降低通信带宽,但会导致定位精度降低;提高精度则会导致带宽升高;如果降低描述符维度会导致匹配性能变差。
卷积神经网络(CNN)方法已经显示出对手工描述符的优越性能,但基于CNN的方法多适用于单机器人系统(SR-SLAM),高模型复杂性和描述符维度是阻碍基于学习的方法在MR-SLAM中应用的两个主要障碍。
本文提出了一个基于知识蒸馏(KD)的描述符学习框架。该框架是一个经典的师生组合,其中学生是我们要学习的紧凑模型,而教师是一个预训练的更大的网络,其预测用于监督学生的学习。为了解决老师和学生之间输出维度的不同,本文还设计了一种新的损失函数。
本文模型与传统模型的比较如下图所示:
本文主要贡献如下:
设计了一个师生模型来生成紧凑的二进制描述符。
提出了一种新的基于距离的蒸馏损失,它允许具有不同输出维度的模型之间的知识转移。
开发了一个基于新描述符模型的MR-SLAM系统作为评估平台。
2 算法框架
2.1 基于学习的描述符生成
本文类似于主流的CNN方法,通过Siamese框架结构学习描述符。它是一个双胞胎模型,在训练过程中共享相同的权重。在Siamese框架下,每个训练阶段都准备两批。批次中的每个图像块对另一个都是负的,同一时代的两个批是一一对应的。
它有两个主要的损耗用于训练:
Triplet loss:它强制匹配的对尽可能接近,而不匹配的对尽可能远。最近的方法大多遵循HardNet策略,只提取包含最小距离的负对进行训练:
为当前实值描述子,为对应的正描述子,为最接近的负描述子,n为批大小。dis计算两个描述符之间的L2距离。
Binarization loss:它旨在最小化实值描述符与对应的二进制描述符之间的差异:
B(k)为二进制描述子B的第k个值,R(k)为实值描述子R的第k个值,D为描述子的维数。
2.2 老师-学生蒸馏框架
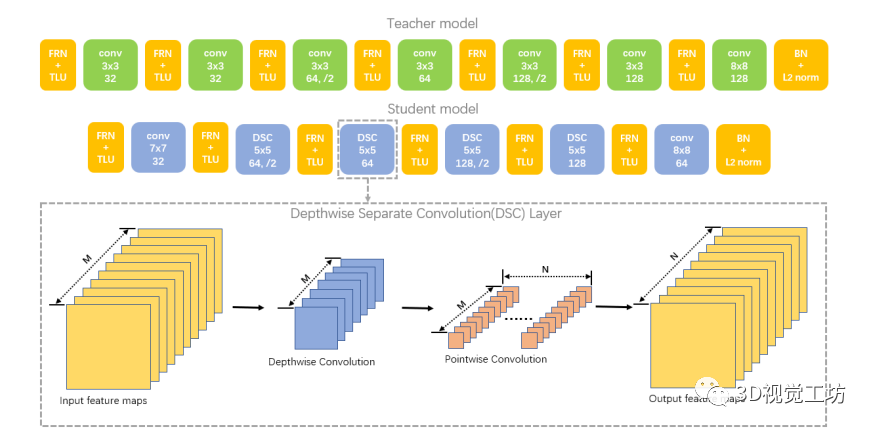
如上图所示,所有的老师卷积层之后是滤波响应归一化(FRN)和阈值线性单元(TLU)。批处理归一化(BN)和l2归一化放在最后的卷积层之后。
学生卷积层第一部分是深度卷积,它对每个输入通道应用一个卷积滤波器。第二部分是1×1卷积,称为逐点卷积。
基于该体系结构,每个模型都能够将图像补丁嵌入到实值描述符中。为了得到二进制描述符,使用以下方程对实值描述符进行二值化:
2.3 蒸馏损失函数
它由一个实值项和一个二元值项组成,它们分别强制学生模型的描述符批在实值和二元空间上具有与教师模型相似的分布。
实值项负描述符损失项:
其中是相对于当前描述符的负描述符的总数。和分别是教师和学生产生的当前重估描述符,和是相应的负描述符。此外,由于教师和学生之间的维度不同,我们增加了一个系数λr,设置为0.95来调整教师侧距离的尺度
二值项负描述符损失项:
其中λb是缩放系数,通常设置为两个模型的输出维度之间的比率:Ds/Dt。在训练阶段的到二进制描述符计算公式:
这里是防止被0整除的系数,设为1e-5。
最后,将这两个损失项合并为蒸馏损失函数:
其中是二值项的加权系数。
2.4 学生训练
第一阶段,使用学习率为0.01的ADAM优化器训练教师模型。这个过程使模型能够生成高质量的128维描述符。基本损耗函数为:
其中是控制二值化损失的加权系数。
在第二阶段,在老师的监督下训练学生模型,学习率设为0.01。因此,目标函数既包括基本损失Lbasic,也包括蒸馏损失Ldistillation,可表示为:
其中为蒸馏损失加权系数,在训练时设置为2。
4 实验与结果
4.1 特征匹配实验
使用UBC数据集:整个数据集包含大约400k个64×64个带标签的补丁,在一个子集上训练模型,并在另外两个子集上测试它。通过报告95%召回率(FPR95)的假阳性率来展示匹配性能。
采用几种方法作为基准方法。第一类是基于cnn的方法,包括HardNet、SOSNet、HyNet等。第二类方法是一些传统的方法,包括SIFT、BRIEF、LDAHash、BinBoost。还报告了每种CNN方法的参数数量和时间消耗(生成500个描述符),以可视化描述符生成效率。
此外,为了测试泛化能力,文章评估了在HPatches数据集上训练并在UBC数据集上测试的CNN方法的性能。
实验结果如下表所示:
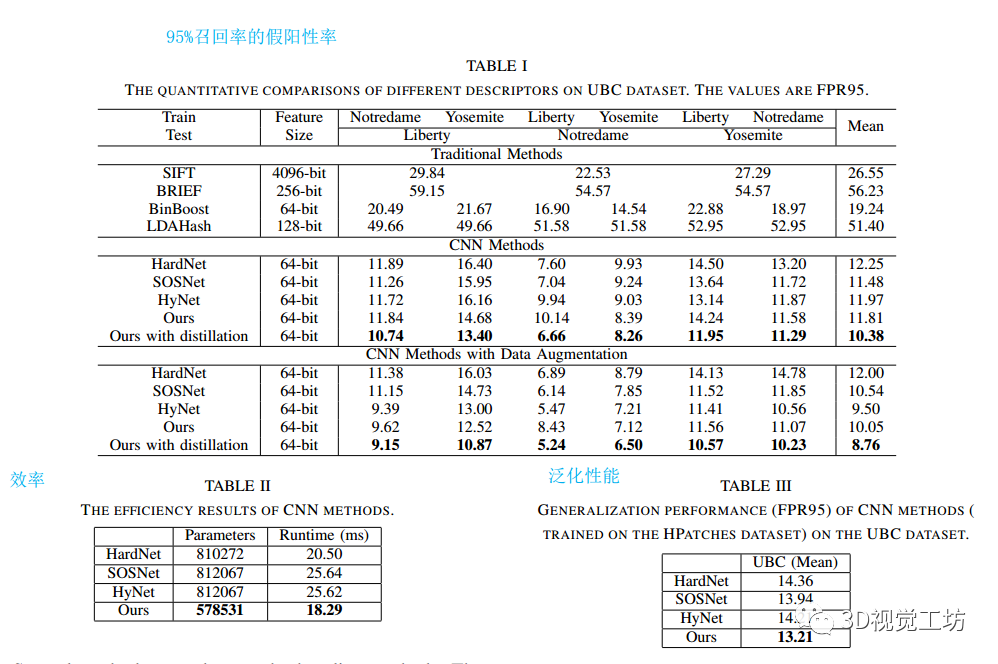
由表1可以看出,基于cnn的方法明显优于传统方法。另一方面,匹配结果表明,即使没有蒸馏,所提出的方法也可以与大多数基于cnn的方法相媲美。此外,在KD方法的帮助下,文中的网络能够优于所有基线方法。
由表2可以看出,文中的模型比基线CNN模型轻30%左右,运行速度也比基线方法快。
由表3可以看出,因为尽管在不同的数据集上训练,但它的性能与CNN方法相当。
4.2 MR-SLAM实验
MR-VINS的详细框架如下图所示:
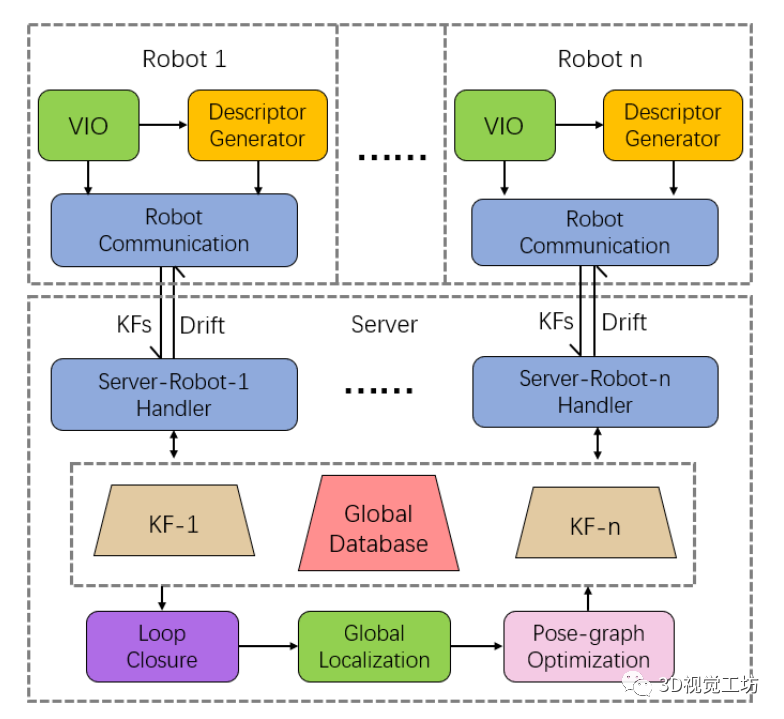
整个系统采用集中式架构,即MR-SLAM系统由多个机器人和一个中央服务器组成。将视觉惯性里程计模块放在机器人上,而将后端模块放在服务器上。在此框架的基础上,在机器人一侧添加了CNN描述符模型,主要将描述符用于循环闭合和全局定位。作者将描述符模型放在机器人通信模块之前,以便描述符可以集成到发送到服务器的关键帧消息中。
使用公共EuRoC数据集,采用定位精度和通信带宽两项指标进行评价。
SLAM精度的定量结果如下表所示。
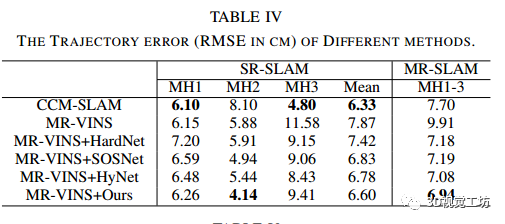
与原始MR-VINS相比,可以看出,基于cnn的方法能够提高定位性能,尤其是MR-SLAM。此外,在单机器人和多机器人任务上,文中的方法总体上达到了与CNN方法相当的精度。然而,由于SLAM的性能不仅仅取决于图像匹配,定位精度优势并不像特征匹配结果那么明显。
下表显示了不同SLAM系统的带宽。
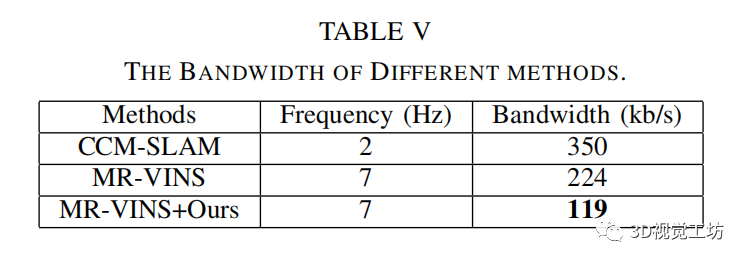
结果表明,文中的方法比原来的MR-VINS和CCM-SLAM具有更低的带宽。由于文中模型的消息频率是CCM-SLAM的3倍,所以文中模型的关键帧信息的大小比CCM-SLAM小10倍左右。窄带宽归因于文中的描述符极其紧凑的尺寸(普通BRIEF描述符的1/4)。此外,由于关键帧尺寸紧凑,就不需要在MR-SLAM任务期间专门降低关键帧频率。
5 总结
在本文中,探讨了如何学习MR-SLAM的紧凑描述符的问题。本文提出了一个师生框架,该框架利用紧凑的学生模型来估计低维描述符。由于教师和学生之间的输出维度不同,作者提出了一个基于距离的蒸馏损失函数,使知识在不同的维度描述符之间蒸馏传递。通过特征匹配实验和MR-SLAM系统的实验,验证了本文所提出算法的有效性。
-
机器人
+关注
关注
212文章
29367浏览量
211157 -
函数
+关注
关注
3文章
4366浏览量
63986 -
模型
+关注
关注
1文章
3474浏览量
49896
原文标题:比目前最先进的模型轻30%!高效多机器人SLAM蒸馏描述符!
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
USB描述符详解
UBL UBOOT 描述符
usb标准描述符之技巧
USB HID报告及报告描述符简介
Descriptor描述符解释
Linux中文件及文件描述符概述
USB设备键值表描述符说明资料免费下载
USB各描述符之间的依赖是怎么样的
Linux系统编程中的文件描述符调用
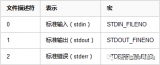
科普一下什么是USB的描述符
Gadget框架构造描述符
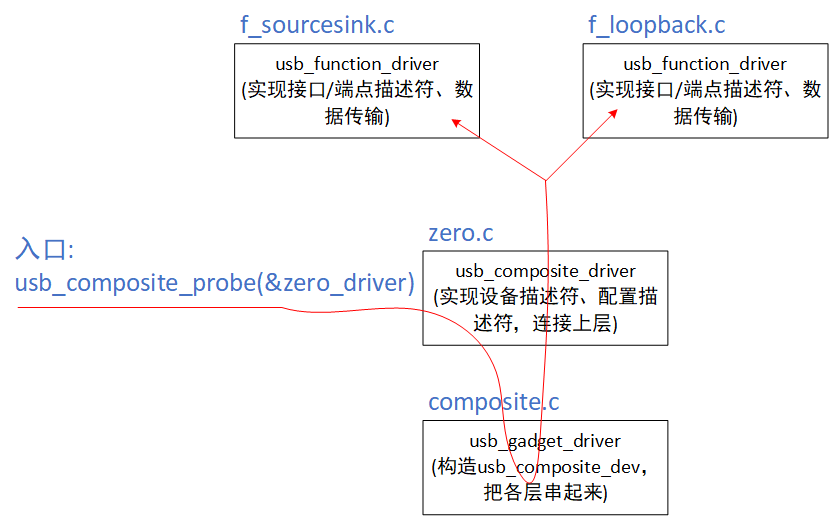
从获取描述符的角度理解Gadget框架
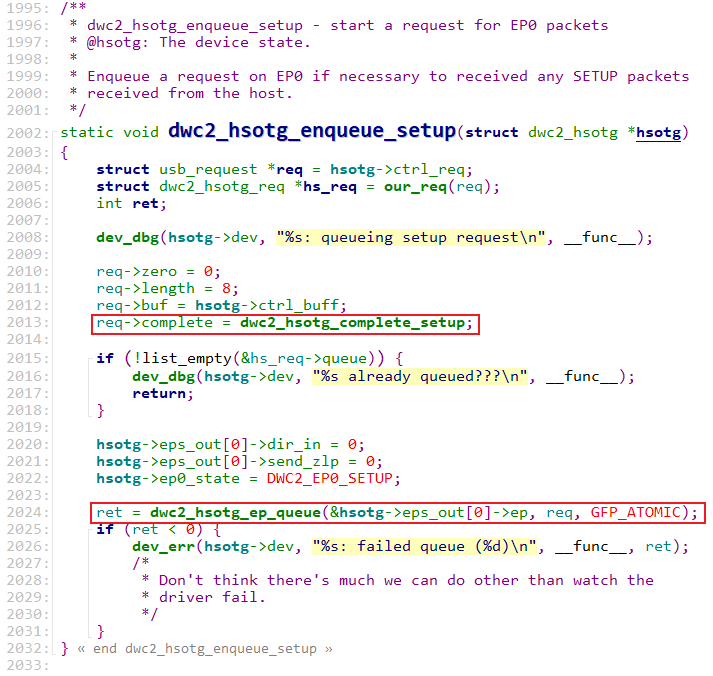
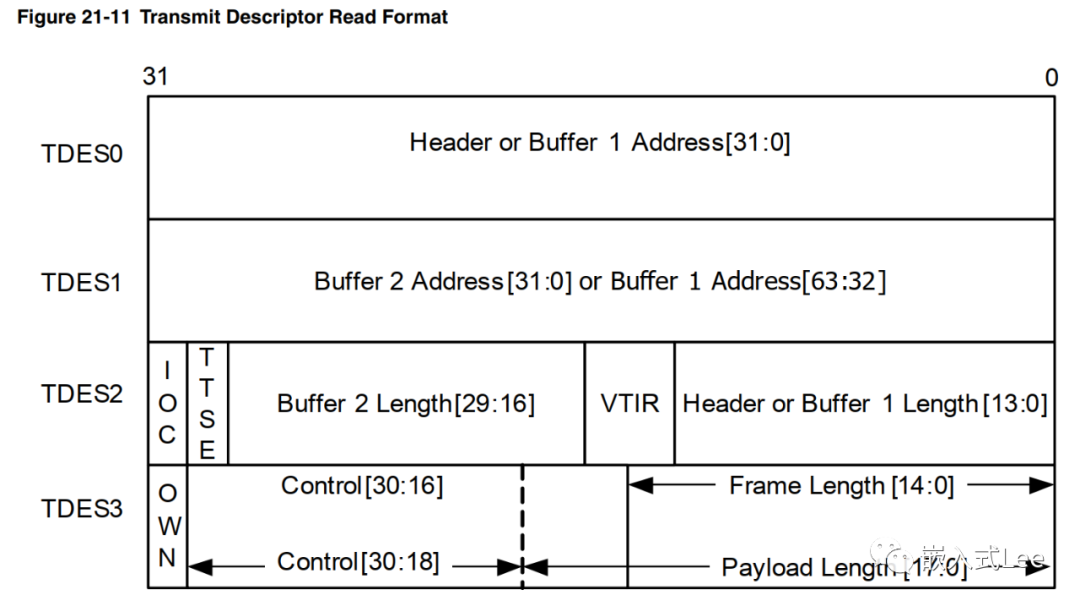
基于DWC_ether_qos的以太网驱动开发-描述符格式介绍
Python的优雅之处:Descriptor(描述符)

TwinCAT3 EtherCAT抓包 | 技术集结
在使用TwinCAT测试EtherCATEOE功能时,我们会发现正常是无法使用Wireshark去进行网络抓包抓取EtherCAT报文的,今天这篇文章就带大家来上手EtherCAT抓包方式。准备环境硬件环境:EtherKit开发板网线一根Type-CUSB线一根软件环境TwinCAT3RT-ThreadstudiowiresharkEtherCATEOE工程

EtherCAT科普系列(8):EtherCAT技术在机器视觉领域的应用
机器视觉是基于软件与硬件的组合,通过光学装置和非接触式的传感器自动地接受一个真实物体的图像,并利用软件算法处理图像以获得所需信息或用于控制机器人运动的装置。机器视觉可以赋予机器人及自动化设备获取外界信息并认知处理的能力。机器视觉系统内包含光学成像系统,可以作为自动化设备的视觉器官实现信息的输入,并借助视觉控制器代替人脑实现信息的处理与输出。从而实现赋予自动化

新品 | 26+6TOPS强悍算力!飞凌嵌入式FCU3501嵌入式控制单元发布
飞凌嵌入式FCU3501嵌入式控制单元基于瑞芯微RK3588处理器开发设计,4xCortex-A76+4xCortex-A55架构,A76主频高达2.4GHz,A55核主频高达1.8GHz,支持8K编解码,NPU算力6TOPS,支持算力卡拓展,可以插装Hailo-8 26TOPS M.2算力卡。

接口核心板必选 | 视美泰AIoT-3568SC 、 AIoT-3576SC:小身材大能量,轻松应对多场景设备扩展需求!
在智能硬件领域,「适配」是绕不开的关键词。无论是小屏设备的”寸土寸金”,还是模具开发的巨额成本,亦或是多产品线兼容的复杂需求,开发者总在寻找一款能「以不变应万变」的核心解决方案。视美泰旗下的AIoT-3568SC与AIoT-3576SC接口核心板系列,可以说是专为高灵活适配场景而生!无需为设备尺寸、模具限制或产品线差异妥协,一块核心板,即可释放无限可能。为什

3核A7+单核M0多核异构,米尔全新低功耗RK3506核心板发布
近日,米尔电子发布MYC-YR3506核心板和开发板,基于国产新一代入门级工业处理器瑞芯微RK3506,这款芯片采用三核Cortex-A7+单核Cortex-M0多核异构设计,不仅拥有丰富的工业接口、低功耗设计,还具备低延时和高实时性的特点。核心板提供RK3506B/RK3506J、商业级/工业级、512MB/256MBLPDDR3L、8GBeMMC/256
搭建树莓派网络监控系统:顶级工具与技术终极指南!
树莓派网络监控系统是一种经济高效且功能多样的解决方案,可用于监控网络性能、流量及整体运行状况。借助树莓派,我们可以搭建一个网络监控系统,实时洞察网络活动,从而帮助识别问题、优化性能并确保网络安全。安装树莓派网络监控系统有诸多益处。树莓派具备以太网接口,还内置了Wi-Fi功能,拥有足够的计算能力和内存,能够在Linux或Windows系统上运行。因此,那些为L
STM32驱动SD NAND(贴片式SD卡)全测试:GSR手环生物数据存储的擦写寿命与速度实测
在智能皮电手环及数据存储技术不断迭代的当下,主控 MCU STM32H750 与存储 SD NAND MKDV4GIL-AST 的强强联合,正引领行业进入全新发展阶段。二者凭借低功耗、高速读写与卓越稳定性的深度融合,以及高容量低成本的突出优势,成为大规模生产场景下极具竞争力的数据存储解决方案。

芯对话 | CBM16AD125Q这款ADC如何让我的性能翻倍?
综述在当今数字化时代,模数转换器(ADC)作为连接模拟世界与数字系统的关键桥梁,其技术发展对众多行业有着深远影响。从通信领域追求更高的数据传输速率与质量,到医疗影像领域渴望更精准的疾病诊断,再到工业控制领域需要适应复杂恶劣环境的稳定信号处理,ADC的性能提升成为推动这些行业进步的重要因素。行业现状分析在通信行业,5G乃至未来6G的发展,对基站信号处理提出了极
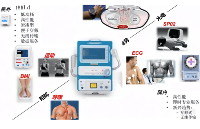
史上最全面解析:开关电源各功能电路
01开关电源的电路组成开关电源的主要电路是由输入电磁干扰滤波器(EMI)、整流滤波电路、功率变换电路、PWM控制器电路、输出整流滤波电路组成。辅助电路有输入过欠压保护电路、输出过欠压保护电路、输出过流保护电路、输出短路保护电路等。开关电源的电路组成方框图如下:02输入电路的原理及常见电路1AC输入整流滤波电路原理①防雷电路:当有雷击,产生高压经电网导入电源时
有几种电平转换电路,适用于不同的场景
一.起因一般在消费电路的元器件之间,不同的器件IO的电压是不同的,常规的有5V,3.3V,1.8V等。当器件的IO电压一样的时候,比如都是5V,都是3.3V,那么其之间可以直接通讯,比如拉中断,I2Cdata/clk脚双方直接通讯等。当器件的IO电压不一样的时候,就需要进行电平转换,不然无法实现高低电平的变化。二.电平转换电路常见的有几种电平转换电路,适用于

瑞萨RA8系列教程 | 基于 RASC 生成 Keil 工程
对于不习惯用 e2 studio 进行开发的同学,可以借助 RASC 生成 Keil 工程,然后在 Keil 环境下愉快的完成开发任务。

共赴之约 | 第二十七届中国北京国际科技产业博览会圆满落幕
作为第二十七届北京科博会的参展方,芯佰微有幸与800余家全球科技同仁共赴「科技引领创享未来」之约!文章来源:北京贸促5月11日下午,第二十七届中国北京国际科技产业博览会圆满落幕。本届北京科博会主题为“科技引领创享未来”,由北京市人民政府主办,北京市贸促会,北京市科委、中关村管委会,北京市经济和信息化局,北京市知识产权局和北辰集团共同承办。5万平方米的展览云集

道生物联与巍泰技术联合发布 RTK 无线定位系统:TurMass™ 技术与厘米级高精度定位的深度融合
道生物联与巍泰技术联合推出全新一代 RTK 无线定位系统——WTS-100(V3.0 RTK)。该系统以巍泰技术自主研发的 RTK(实时动态载波相位差分)高精度定位技术为核心,深度融合道生物联国产新兴窄带高并发 TurMass™ 无线通信技术,为室外大规模定位场景提供厘米级高精度、广覆盖、高并发、低功耗、低成本的一站式解决方案,助力行业智能化升级。

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
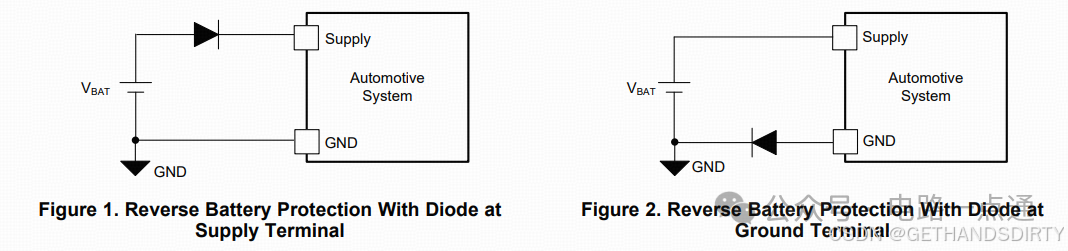
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极





 工商网监
工商网监
评论