 pandas读取csv文件有什么方法和注意点?
pandas读取csv文件有什么方法和注意点?
这篇文章介绍了利用数据分析工具pandas读取csv文件的方法和注意点,便于迅速过渡到数据处理阶段。
pandas是一个高效的数据分析工具。基于其高度抽象的数据结构DataFrame,几乎可以对数据进行任何你想要的操作。
由于现实世界中数据源的格式非常多,pandas也支持了不同数据格式的导入方法,本文介绍pandas如何从csv文件中导入数据。
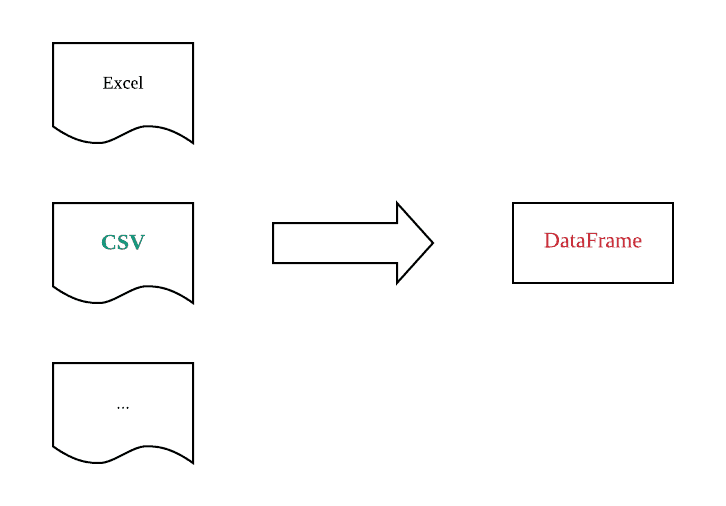
从上图可以看出,我们要做的工作就是把存储在csv格式中的数据读入并转换成DataFrame格式。pandas提供了一个非常简单的api函数来实现这个功能:read_csv()。
1. 通过read_csv接口读入csv文件中的数据
下面是一个简单的示例:
import pandas as pd
CSV_FILE_PATH ='./test.csv'
df = pd.read_csv(CSV_FILE_PATH)
print(df.head(5))
只要简单地指定csv文件的路径,便可以得到DataFrame格式的数据df。对于理想情况下的数据,导入过程就是这么简单!
下面考虑这种情况:假设csv文件头部有几个无效行,那么打印出来的结果可能如下所示:
1 2 3 4
0 datetime host hit volume
12018-07-2409:00:00 weibo.com 20 1020
22018-07-2509:00:00 qq.com no20 1028
32018-07-2619:00:00 sina.com 25 1181
42018-07-2721:00:00 sohu.com 15 4582
pandas把【1,2,3,4】这组无效数据当作了column name;而实际上,我们更偏向于将【datetime,host,hit,volume】这组数据当作column name。对于这种情况,read_csv()函数提供了一个参数:skiprows,用于指定跳过csv文件的头部的前几行。在这里,我们跳过1行即可。
import pandas as pd
CSV_FILE_PATH ='./test.csv'
df = pd.read_csv(CSV_FILE_PATH, skiprows=1)
print(df.head(5))
得到的结果如下所示:
datetime host hit volume
02018-07-2409:00:00 weibo.com 20 1020
12018-07-2509:00:00 qq.com no20 1028
22018-07-2619:00:00 sina.com 25 1181
32018-07-2721:00:00 sohu.com 15 4582
2. 处理csv文件中的无效数据
pandas可以自动推断每个column的数据类型,以方便后续对数据的处理。还以上文中的数据为例,通过如下代码:
import pandas as pd
CSV_FILE_PATH ='./test.csv'
df = pd.read_csv(CSV_FILE_PATH)
print(df.head(5))
print('datatype of column hit is: '+ str(df['hit'].dtypes))
得出的结果:
datetime host hit volume
02018-07-2409:00:00 weibo.com 20 1020
12018-07-2509:00:00 qq.com 20 1028
22018-07-2619:00:00 sina.com 25 1181
32018-07-2721:00:00 sohu.com 15 4582
datatype of column hit is: int64
pandas将hit这一列的数据类型判定为了int64,这显然方便未来我们对于该列数据的运算。但是在实际情况中,我们经常会面临数据缺失的问题,如果出现这种情况,我们往往会用一些占位符来表达。假设,我们用missing这个占位符来表示数据缺失,仍使用上述代码,来探索下会发生些什么:
datetime host hit volume
02018-07-2409:00:00 weibo.com 20 1020
12018-07-2509:00:00 qq.com 20 1028
22018-07-2619:00:00 sina.com missing missing
32018-07-2721:00:00 sohu.com 15 4582
datatype of column hit is:object
由于hit这一列中出现了missing这个字符串,pandas将hit这一列的数据类型判断成了object。这会给我们对该列数据的运算带来影响。例如,假设我们要计算hit列前两行数据的和,代码如下:
print(df['hit'][0]+ df['hit'][1])
结果是:
2020
本来我们想要的是数学运算结果,但得到的却是一个字符串拼接结果。这就是由于数据类型判断失误带来的严重影响。对于这种情况,read_csv()函数也提供了一个简单的处理方式,只需要通过na_value参数指定占位符,pandas便会在读入数据的过程中自动将这些占位符转换成NaN,从而不影响pandas对column数据类型的正确判断。示例代码:
import pandas as pd
CSV_FILE_PATH ='./test.csv'
df = pd.read_csv(CSV_FILE_PATH, skiprows=0, na_values=['missing')
print(df.head(5))
print('datatype of column hit is: '+ str(df['hit'].dtypes))
print(df['hit'][0]+ df['hit'][1])
运行结果如下:
datetime host hit volume
02018-07-2409:00:00 weibo.com 20.01020.0
12018-07-2509:00:00 qq.com 20.01028.0
22018-07-2619:00:00 sina.com NaN NaN
32018-07-2721:00:00 sohu.com 15.04582.0
datatype of column hit is: float64
40.0
可以看到,pandas将数据集中的missing单元全部转换为了NaN,并成功判断出hit这一列的数据类型。
3. 总结
通过一个简单的read_csv()函数,实际可以做到如下几件事:
通过指定的文件路径,从本地读取csv文件,并将数据转换成DataFrame格式
更正数据集的头部(column)
正确处理缺失数据
推断每一列的数据类型
当然,read_csv()函数还有一系列其他参数来应对各种情况,遇到具体问题的同学可参考其接口指南。
-
数据处理
+关注
关注
0文章
625浏览量
28980 -
数据分析
+关注
关注
2文章
1469浏览量
34738 -
csv
+关注
关注
0文章
39浏览量
5974
原文标题:干货 | pandas读取csv文件数据的方法及注意点
文章出处:【微信号:ZTEdeveloper,微信公众号:中兴开发者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
c语言读写表格(csv)文件 读取csv文件示例


labview如何读取以制表符分割的csv文件
TensorFlow csv文件读取数据(代码实现)详解
如何通过pandas读取csv文件指定的前几行?
介绍Python中常用的文件读取方法以及应用示例
如何使用Python和pandas库读取、写入文件
Python教你用 Rows 快速操作csv文件

瑞萨RA8系列教程 | 基于 RASC 生成 Keil 工程
对于不习惯用 e2 studio 进行开发的同学,可以借助 RASC 生成 Keil 工程,然后在 Keil 环境下愉快的完成开发任务。

共赴之约 | 第二十七届中国北京国际科技产业博览会圆满落幕
作为第二十七届北京科博会的参展方,芯佰微有幸与800余家全球科技同仁共赴「科技引领创享未来」之约!文章来源:北京贸促5月11日下午,第二十七届中国北京国际科技产业博览会圆满落幕。本届北京科博会主题为“科技引领创享未来”,由北京市人民政府主办,北京市贸促会,北京市科委、中关村管委会,北京市经济和信息化局,北京市知识产权局和北辰集团共同承办。5万平方米的展览云集

道生物联与巍泰技术联合发布 RTK 无线定位系统:TurMass™ 技术与厘米级高精度定位的深度融合
道生物联与巍泰技术联合推出全新一代 RTK 无线定位系统——WTS-100(V3.0 RTK)。该系统以巍泰技术自主研发的 RTK(实时动态载波相位差分)高精度定位技术为核心,深度融合道生物联国产新兴窄带高并发 TurMass™ 无线通信技术,为室外大规模定位场景提供厘米级高精度、广覆盖、高并发、低功耗、低成本的一站式解决方案,助力行业智能化升级。

智能家居中的清凉“智”选,310V无刷吊扇驱动方案--其利天下
炎炎夏日,如何营造出清凉、舒适且节能的室内环境成为了大众关注的焦点。吊扇作为一种经典的家用电器,以其大风量、长寿命、低能耗等优势,依然是众多家庭的首选。而随着智能控制技术与无刷电机技术的不断进步,吊扇正朝着智能化、高效化、低噪化的方向发展。那么接下来小编将结合目前市面上的指标,详细为大家讲解其利天下有限公司推出的无刷吊扇驱动方案。▲其利天下无刷吊扇驱动方案一
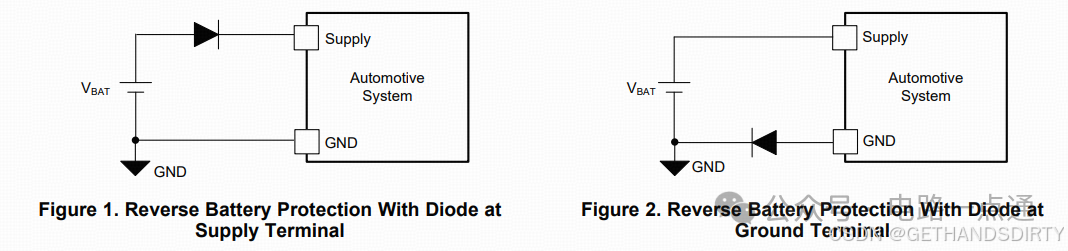
电源入口处防反接电路-汽车电子硬件电路设计
一、为什么要设计防反接电路电源入口处接线及线束制作一般人为操作,有正极和负极接反的可能性,可能会损坏电源和负载电路;汽车电子产品电性能测试标准ISO16750-2的4.7节包含了电压极性反接测试,汽车电子产品须通过该项测试。二、防反接电路设计1.基础版:二极管串联二极管是最简单的防反接电路,因为电源有电源路径(即正极)和返回路径(即负极,GND),那么用二极
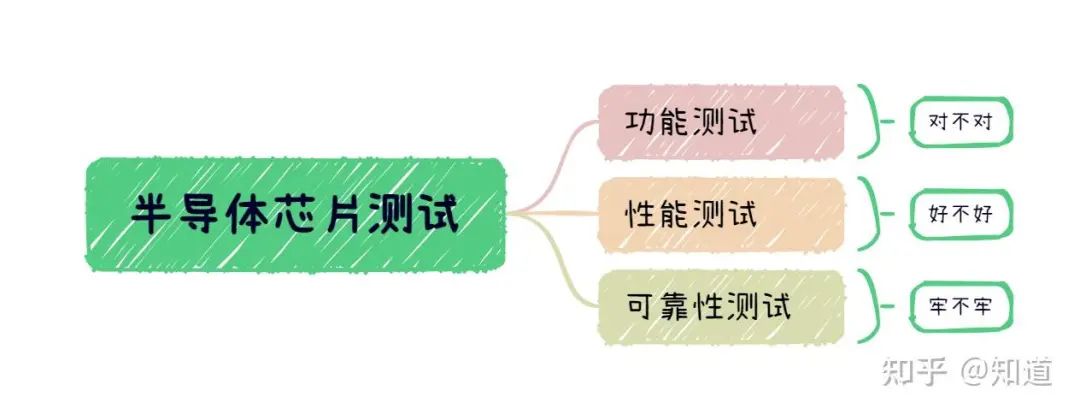
半导体芯片需要做哪些测试
首先我们需要了解芯片制造环节做⼀款芯片最基本的环节是设计->流片->封装->测试,芯片成本构成⼀般为人力成本20%,流片40%,封装35%,测试5%(对于先进工艺,流片成本可能超过60%)。测试其实是芯片各个环节中最“便宜”的一步,在这个每家公司都喊着“CostDown”的激烈市场中,人力成本逐年攀升,晶圆厂和封装厂都在乙方市场中“叱咤风云”,唯独只有测试显

解决方案 | 芯佰微赋能示波器:高速ADC、USB控制器和RS232芯片——高性能示波器的秘密武器!
示波器解决方案总述:示波器是电子技术领域中不可或缺的精密测量仪器,通过直观的波形显示,将电信号随时间的变化转化为可视化图形,使复杂的电子现象变得清晰易懂。无论是在科研探索、工业检测还是通信领域,示波器都发挥着不可替代的作用,帮助工程师和技术人员深入剖析电信号的细节,精准定位问题所在,为创新与发展提供坚实的技术支撑。一、技术瓶颈亟待突破性能指标受限:受模拟前端
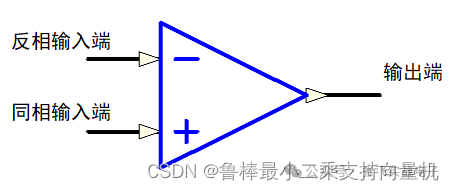
硬件设计基础----运算放大器
1什么是运算放大器运算放大器(运放)用于调节和放大模拟信号,运放是一个内含多级放大电路的集成器件,如图所示:左图为同相位,Vn端接地或稳定的电平,Vp端电平上升,则输出端Vo电平上升,Vp端电平下降,则输出端Vo电平下降;右图为反相位,Vp端接地或稳定的电平,Vn端电平上升,则输出端Vo电平下降,Vn端电平下降,则输出端Vo电平上升2运算放大器的性质理想运算

ElfBoard技术贴|如何调整eMMC存储分区
ELF 2开发板基于瑞芯微RK3588高性能处理器设计,拥有四核ARM Cortex-A76与四核ARM Cortex-A55的CPU架构,主频高达2.4GHz,内置6TOPS算力的NPU,这一设计让它能够轻松驾驭多种深度学习框架,高效处理各类复杂的AI任务。

米尔基于MYD-YG2LX系统启动时间优化应用笔记
1.概述MYD-YG2LX采用瑞萨RZ/G2L作为核心处理器,该处理器搭载双核Cortex-A55@1.2GHz+Cortex-M33@200MHz处理器,其内部集成高性能3D加速引擎Mail-G31GPU(500MHz)和视频处理单元(支持H.264硬件编解码),16位的DDR4-1600/DDR3L-1333内存控制器、千兆以太网控制器、USB、CAN、
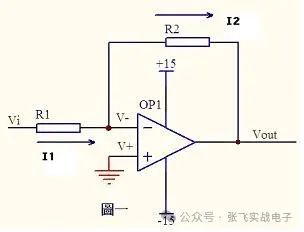
运放技术——基本电路分析
虚短和虚断的概念由于运放的电压放大倍数很大,一般通用型运算放大器的开环电压放大倍数都在80dB以上。而运放的输出电压是有限的,一般在10V~14V。因此运放的差模输入电压不足1mV,两输入端近似等电位,相当于“短路”。开环电压放大倍数越大,两输入端的电位越接近相等。“虚短”是指在分析运算放大器处于线性状态时,可把两输入端视为等电位,这一特性称为虚假短路,简称

飞凌嵌入式携手中移物联,谱写全国产化方案新生态
4月22日,飞凌嵌入式“2025嵌入式及边缘AI技术论坛”在深圳成功举办。中移物联网有限公司(以下简称“中移物联”)携OneOS操作系统与飞凌嵌入式共同推出的工业级核心板亮相会议展区,操作系统产品部高级专家严镭受邀作《OneOS工业操作系统——助力国产化智能制造》主题演讲。
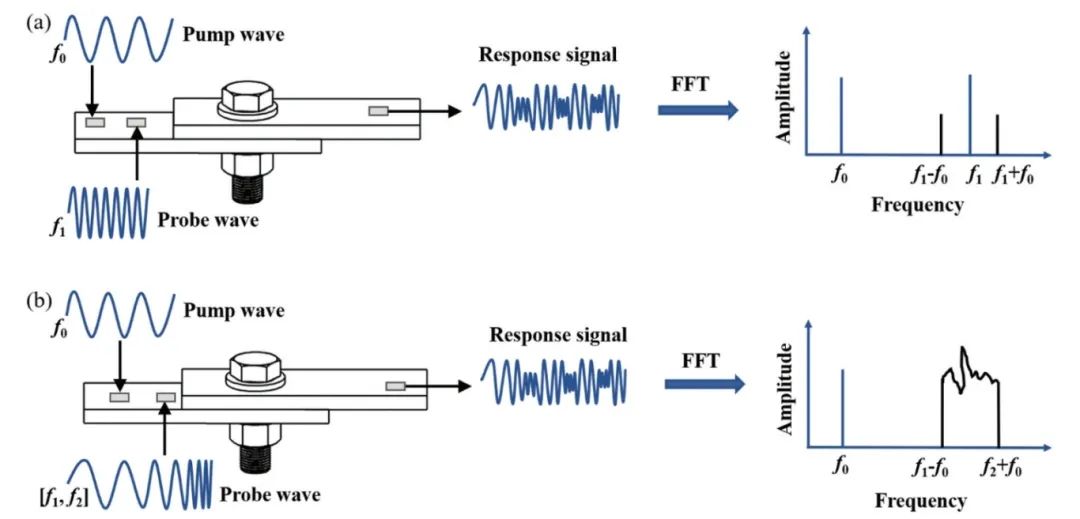
ATA-2022B高压放大器在螺栓松动检测中的应用
实验名称:ATA-2022B高压放大器在螺栓松动检测中的应用实验方向:超声检测实验设备:ATA-2022B高压放大器、函数信号发生器,压电陶瓷片,数据采集卡,示波器,PC等实验内容:本研究基于振动声调制的螺栓松动检测方法,其中低频泵浦波采用单频信号,而高频探测波采用扫频信号,利用泵浦波和探测波在接触面的振动声调制响应对螺栓的松动程度进行检测。通过螺栓松动检测
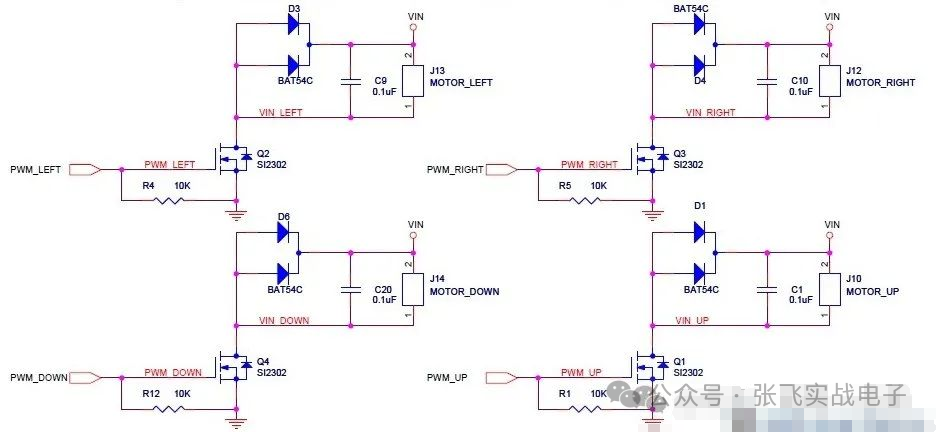
MOS管驱动电路——电机干扰与防护处理
此电路分主电路(完成功能)和保护功能电路。MOS管驱动相关知识:1、跟双极性晶体管相比,一般认为使MOS管导通不需要电流,只要GS电压(Vbe类似)高于一定的值,就可以了。MOS管和晶体管向比较c,b,e—–>d(漏),g(栅),s(源)。2、NMOS的特性,Vgs大于一定的值就会导通,适合用于源极接地时的情况(低端驱动),只要栅极电压达到4V或10V就可以
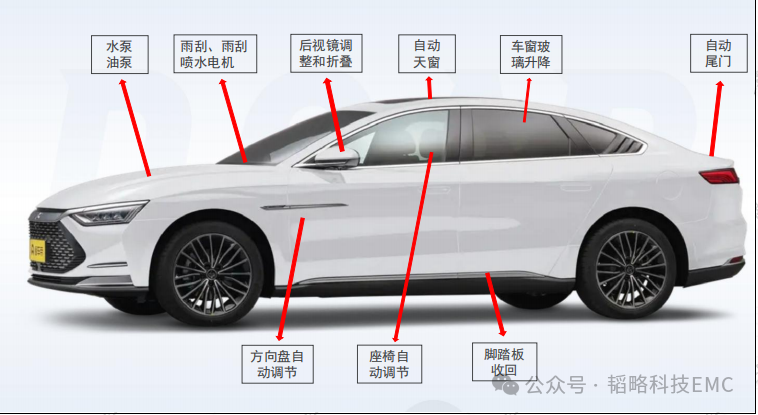
压敏(MOV)在电机上的应用剖析
一前言有刷直流电机是一种较为常见的直流电机。它的主要特点包括:1.结构相对简单,由定子、转子、电刷和换向器等组成;2.通过电刷与换向器的接触来实现电流的换向,从而使电枢绕组中的电流方向周期性改变,保证电机持续运转;3.具有调速性能较好等优点,可以通过改变电压等方式较为方便地调节转速。有刷直流电机在许多领域都有应用,比如一些电动工具、玩具、小型机械等。但它也存





 工商网监
工商网监
评论