 电子发烧友App
电子发烧友App


1、引言
信息化已经成为社会发展的大趋势。信息化是以数字化为背景的,而DSP技术则是数字化最重要的基本技术之一。DSP处理器是专门设计用来进行高速数字信号处理的微处理器。与许多通用的CPU和微控制器(MCU)相比,DSP处理器在结构上采用了许多的专门技术和措施来提高处理速度。DSP处理器与通用微处理器不同,它没有采用将程序代码和数据公用一个公共的存储空间和单一的地址与数据总线的冯诺依曼结构(Von Neumann Architecture),而是毫无例外的将程序代码和数据的存储空间分开,各有自己的地址与数据总线,即所谓的哈佛结构(Harvard Architecture),增大了处理器的数据交换能力。
OFDM(正交频分复用),是直接利用离散傅里叶变换(DFT),实现的一种多载波调制技术,它采用并行传输,将所传送的高速数据分解并调制到多个相互交叠并且正交的子信道中,使得每个子通道的码元宽度大于扩展延时,若在码元之间增加一定长度的保护间隔,则多径传输引起的码间串扰基本被消除。OFDM的上述特点使其特别适于在存在多径传播和有多普勒频移的移动无线传输信道中传输高速数据。目前应用于电力线通信,数字声广播(DAB)和欧洲高清晰度电视传输标准(DVB-T), 无线局域网(WLAN)等业务中。
论文在TMS320C5509DSP上根据系统的总体框图,实现OFDM基带系统的设计,并给出了具体的性能指标。
2、OFDM系统的设计实现
2.1 实现系统的任务流程图
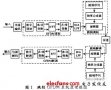
系统每帧可以传送56bits的有效信息,数据的传输速率将达到100kbit/s,并且为了减小传输过程中的信道的不理想,用了BSPK对信源进行编码映射,在传输过程中,传输的是时域的信号,但是实际有用的是这些时域信号的频谱,这些信号在时域中是无规则的随机信号,但在其频谱上的各个子载波携带着需传输的信息。现工作框图如图1:

图1. 系统的任务框图
整个系统由DSP和FPGA、D/A、A/D以及一些其他的硬件共同完成。任务流程是由DSP接受由串/并转换过后的并行数据,在DSP内进行BPSK信源编码,将0和1分别映射为0xbffd 和0x3fff两个十六进制的数,再送入IFFT单元将数据变到时域进行处理,然后把数据加上循环前缀,串行送给FPGA进行处理,由FPGA将数据发送给接收板。接收板上由FPGA接到数据进行一系列处理后,将数据又串行传给接收板的DSP。在接收板的DSP上将接受到的数据移走循环前缀,送入FFT单元将数据还原到频域,然后以0为门限进行判决,映射后得到最早的原始数据。
2.1 任务流程详解
原始数据每帧携带56bit的二进制信息(即只有0和1两种取值),在框图中D/A和A/D部分都是由专门的硬件来完成,项目选用的是ADS828e,和DAC902u。
发送部分:
信源编码部分我们采用的是BPSK,为的是进一步增大信号间的欧式距离,通过计算,我们决定选用0xbffd 和0x3fff两个16进制的数来分别代表0和1。由于FFT变换要求数据是2N个数据,所以将数据插入若干个零来补足。具体做法是,将映射后的第28个数据位置开始插入7个零。由于零频时不能有信号(为了无直流分量),在帧的开始不传信息,将第一个数插入零(不是0xbffd),把56个数变为64个数,在接收板上将把同样位置的16个数去掉。
将编码映射后的16位数进行64点的IFFT,把数据由频域变换到时域,等候下一步处理。
在OFDM系统中,为了防止多径延迟,必须加上循环前缀,而这些循环前缀又不能破坏子信道间的正交性,于是将最后16位数提到前面来形成80个数。具体做法是,在IFFT完成后,要加上循环前缀才能将数据发送给FPGA,将数据的最后16位复制到数据开头(原来的16个数不动),把数据变为80个,送给串口发送给FPGA。
在FPGA上进行FIR滤波,和一系列处理后,发送板的任务完成,接下来就将数据送给接收板。
接收部分:
由接收板上的FPGA接收到发送板送来的数据,经过一系列处理后将数据串行送给DSP等待进一步处理。
接收板的DSP接收到FPGA发过来的80个串行数据后,先将循环前缀去掉,即去掉前16位数,将80位的数据变为64位,交给下一步处理。
在把数据变回为64位后,将数据进行FFT变换,由时域变回频域,交由下一步处理。
在进行判决之前,先要把插入的16个数去掉,将64位数变为56位,然后进行判决,BPSK有一个好处就是判决时可以直接以零为门限。经过判决后,将数据还原成原来的初试值。
综上所述,在DSP部分,共有10项任务,
发送端
1.BPSK编码和插入数据(数据个数由56变为64个)
2.作N=64的IFFT变换,将频域的数据变到时域。
3.加入循环前缀(数据个数由64个变为80个),防止多径延迟。
4.通过DMA将数据送到Mcbsp发给FPGA。
接收端
5.由Mcbsp接到数据通过DMA存入数据空间(此时数据应该与第四步结束时相同)。
6.去掉循环前缀(数据个数又由80个变为64个,此时数据应该与第三步结束时相同)
7.作64点FFT变换(此时结果应该与第一步结束时相同)
8.去掉插入的数据,反映射(数据个数由64个变为56个,此时结果应该与第一步开始时相同)并解码。
2.3 DSP串口的接发配置和DMA的设置
系统实现关键在FFT的实现和DSP串口的接发配置和DMA的设置。这里详细说明串口和DMA的设计方法。
系统用Mcbsp1发送数据,用Mcbsp2来接收数据,为了不占用过多的CPU资源,用DMA的4通道来传送数据给串口,用5通道来接收数据。对于DMA和Mcbsp的使用主要是寄存器的配置问题,在这些配置当中可以对工作模式等一系列东西进行设置。现分别介绍如下:
对于Mcbsp来说,接收和发送可以配置在一起,采用了DSP自身带有的CSL库函数,它对寄存器的配置是通过结构体来定义的,可以方便的修改成自己所需要的模式。
在进行将DSP片内数据地址赋DMA中的地址时要注意,DMA中数据是以byte为单位存储的,存储的最小数据单位上byte,而片内存储区间是以word为单位的,所以将地址交过去时,要将地址右依、移1位。如:
srcAddrHi = (Uint16)(((Uint32)(dmaXmtConfig.dmacssal)) >> 15) & 0xFFFFu;
srcAddrLo = (Uint16)(((Uint32)(dmaXmtConfig.dmacssal)) << 1) & 0xFFFFu;
dstAddrHi = (Uint16)(((Uint32)(dmaXmtConfig.dmacdsal)) >> 15) &0xFFFFu;
dstAddrLo = (Uint16)(((Uint32)(dmaXmtConfig.dmacdsal)) << 1) & 0xFFFFu;
在进行中断处理是时,要注意执行的顺序,首先要保存原来的中断向量表,再清除原来的中断,然后将局部中断允许位开放(即关屏蔽位),开全局中断,最后将中断服务程序填入中断向量表。
old_intm = IRQ_globalDisable();
IRQ_clear(xmtEventId);
IRQ_enable(xmtEventId);
IRQ_setVecs(0x10000);
IRQ_plug(xmtEventId,&dmaXmtIsr);
在程序任务完成之后,还要记得还原中断,关掉Mcbsp和DMA。
MCBSP_close(hMcbspr);
DMA_close(hDmaRcv);
DMA_close(hDmaXmt);
DMA_stop(hDmaXmt);
IRQ_disable(xmtEventId);
DMA_stop(hDmaRcv);
IRQ_disable(rcvEventId);
在设定的控制字下,串口1将以CPU时钟频率的1/70发出帧定位信号,宽度为一个码元长度,上升沿有效,以帧定位信号的1/80发出时钟定位信号(因为一帧有80个元素),也是上升沿有效,发送元素是32bit的数,这是因为发散的数据是复数,分为虚部和实部,先放实部后放虚部,所以一个元素是32个bit。
串口2是接收端,接收外部帧同步信号和时钟同步信号用来同步。外部传来的各种信号和数据格式和串口1发送的相同,不过收的时钟定位信号是下降沿有效。
在DMA方面,通道4是发送通道,通道5是接收通道,同步事件分别是发送串口和接收串口,在一个数据串口接收到了后会发中断给DMA,使其接收数据或传下一个数据,所以在发端,需要手工先送一个数据过去。
3 性能分析
可靠性以外,速度是一个通信系统最重要的评估因素,而数据的处理速度在很大程度上限制了传输速度,成为了提高系统速度的瓶颈。在设计中对系统传输由于是用DMA和Mcbsp的结合使用,速度超出了其他程序的执行速度,只要传输在主函数的执行时间内完成就不会造成系统的阻塞,所以这部分只测试和评估各程序的执行速度,传输的时钟定位脉冲是对CPU时钟的35分频远远快于处理速度,忽略它的测试不会对整个测试有很大影响。
系统数据的传输速度达到100kbit/s,传输只要在上次数据处理完前完成就可以不计算传输的速度,所以按照我们的预期速度,和我们DSP的CPU时钟140MHz,可以算出所有的数据要在多少条指令周期内完成才不会对下一阶段的任务产生影响,而CCS就有专门的测试工具帮助我们测试执行的指令周期。期望的最大执行周期为140÷125×64=71680条指令周期。
由CCS自带的时间测试是以执行周期为单位的,在程序没有进行编译优化时,我们测试得各部分和主函数的执行速度如图2所示:

图2 未优化前的程序执行时间测试结果
在此结果中,我们可以看到main函数的执行时间是39786个指令周期,完全可以满足前面算出的最大指令执行周期。顺便一提,在这个测试工具中还可以看到所编译的程序代码的大小。
在由CCS自带的优化工具进行调试的优化后(即o2优化),程序代码的长度和执行时间还可以大大的缩短。其结果见图3所示:

图3 用参数o2优化后的程序测试
比较图2和图3,可以看出经过优化后的程序不仅在代码长度上减少了进40%,在执行速度上更是提高了2倍以上,有的子程序甚至提高了4-5倍。系统效率有了很大的提高,并且有较大的余量来实现其他任务。
4 结论
实现了OFDM系统基带系统的DSP实现,实现基带信号的发送与接收。考虑到物理层的时延要求和实现的复杂度,本系统采用串口和DMA结合的方法,对信号帧进行处理,将DSP核心处理单元解放出来,能完成复杂的信号处理任务。我们设计的系统数据的传输速度达到100kbit/s,如果要达到更高的传输速率,可以改用更先进的DSP型号。









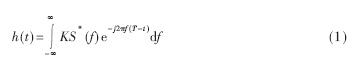





 工商网监
工商网监
评论