 电子发烧友App
电子发烧友App


Python Code
#Import Library
#Import other necessary libraries like pandas, numpy...
from sklearn import linear_model
import numpy as np
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
# x_train=input_variables_values_training_datasets
x_train=np.random.rand(4,4)
print(x_train)
# y_train=target_variables_values_training_datasets
y_train=np.random.rand(4,4)
print(y_train)
# x_test=input_variables_values_test_datasets
x_test=np.random.rand(4,4)
print(x_test)
# Create linear regression object
linear = linear_model.LinearRegression()
# Train the model using the training sets and check score
linear.fit(x_train, y_train)
linear.score(x_train, y_train)
#Equation coefficient and Intercept
print('Coefficient:
', linear.coef_)
print('Intercept:
', linear.intercept_)
#Predict Output
predicted= linear.predict(x_test)
print('predicted:
',predicted)
[[ 0.98267731 0.23364069 0.35133775 0.92826309]
[ 0.80538991 0.05637806 0.87662175 0.3960776 ]
[ 0.54686738 0.6816495 0.99747716 0.32531085]
[ 0.19189509 0.87105462 0.88158122 0.25056621]]
[[ 0.55541608 0.56859636 0.40616234 0.14683524]
[ 0.09937835 0.63874553 0.92062536 0.32798326]
[ 0.87174236 0.779044 0.79119392 0.06912842]
[ 0.87907434 0.53175367 0.01371655 0.11414196]]
[[ 0.37568516 0.17267374 0.51647046 0.04774661]
[ 0.38573914 0.85335136 0.11647555 0.0758696 ]
[ 0.67559384 0.57535368 0.88579261 0.26278658]
[ 0.13829782 0.28328756 0.51170484 0.04260013]]
Coefficient:
[[ 0.55158868 1.45901817 0.31224322 0.49538173]
[ 0.6995448 0.40804135 0.59938423 0.09084578]
[ 1.79010371 0.21674532 1.60972012 -0.046387 ]
[-0.31562917 -0.53767439 -0.16141312 -0.2154683 ]]
Intercept:
[-0.89705102 -0.50908061 -1.9260686 0.83934127]
predicted:
[[-0.25297601 0.13808785 -0.38696891 0.53426883]
[ 0.63472658 0.18566989 -0.86662193 0.22361739]
[ 0.72181277 0.75309881 0.82170796 0.11715048]
[-0.22656611 0.01383581 -0.79537442 0.55159912]]
R Code
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train <- input_variables_values_training_datasets
y_train <- target_variables_values_training_datasets
x_test <- input_variables_values_test_datasets
x <- cbind(x_train,y_train)
# Train the model using the training sets and check score
linear <- lm(y_train ~ ., data = x)
summary(linear)
#Predict Output
predicted= predict(linear,x_test)
2.逻辑回归
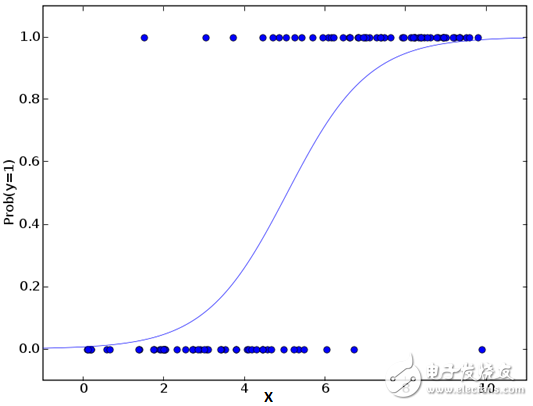
不要因为它的名字而感到困惑,逻辑回归是一个分类算法而不是回归算法。它用于基于给定的一组自变量来估计离散值(二进制值,如0/1,是/否,真/假)。简单来说,它通过将数据拟合到logit函数来预测事件发生的概率。因此,它也被称为logit回归。由于它预测概率,其输出值在0和1之间(如预期的那样)。
再次,让我们通过一个简单的例子来尝试理解这一点。
假设你的朋友给你一个难题解决。只有2个结果场景 - 你能解决和不能解决。现在想象,你正在被许多猜谜或者简单测验,来试图理解你擅长的科目。这项研究的结果将是这样的结果 - 如果给你一个10级的三角形问题,那么你有70%可能会解决这个问题。另外一个例子,如果是五级的历史问题,得到答案的概率只有30%。这就是逻辑回归为你提供的结果。
对数学而言,结果的对数几率被建模为预测变量的线性组合。
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence ln(odds) = ln(p/(1-p)) logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk
以上,p是感兴趣特征的概率。 它选择最大化观察样本值的可能性的参数,而不是最小化平方误差的总和(如在普通回归中)。
现在,你可能会问,为什么要采用log? 为了简单起见,让我们来说,这是复制阶梯函数的最好的数学方法之一。 我可以进一步详细介绍,但这将会打破这篇文章的目的。
Python Code
#Import Library
from sklearn.linear_model import LogisticRegression
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create logistic regression object
model = LogisticRegression()
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Equation coefficient and Intercept
print('Coefficient:
', model.coef_)
print('Intercept:
', model.intercept_)
#Predict Output
predicted= model.predict(x_test)














 工商网监
工商网监
评论